1 identify #
不能以数字开头,不能使用关键字和保留字。raw indentify 以 r# 开头,后面可以使用关键字作为 indentify。
- foo
- _identifier
- r#true
- Москва
- 東京
2 comment #
常规注释(不显示在 cargo doc 中):
//:单行注释;/* */: 块注释;
cargo doc 注释:
- INNER LINE DOC:
//! - INNER BLOCK DOC:
/*! */ - OUTER LINE DOC:
/// - OUTER BLOCK DOC:
/** */
INNER 是 module/crate 级别的注释,等效于 #![doc=“comment”] 。OUTER 是紧接着的 item 的注释,等效于 #[doc=“comment”] 。
// https://doc.rust-lang.org/reference/comments.html
//! A doc comment that applies to the implicit anonymous module of this crate
pub mod outer_module {
//! - Inner line doc
//!! - Still an inner line doc (but with a bang at the beginning)
/*! - Inner block doc */
/*!! - Still an inner block doc (but with a bang at the beginning) */
// - Only a comment
/// - Outer line doc (exactly 3 slashes)
//// - Only a comment
/* - Only a comment */
/** - Outer block doc (exactly) 2 asterisks */
/*** - Only a comment */
pub mod inner_module {}
pub mod nested_comments {
/* In Rust /* we can /* nest comments */ */ */
// All three types of block comments can contain or be nested inside any other type:
/* /* */ /** */ /*! */ */
/*! /* */ /** */ /*! */ */
/** /* */ /** */ /*! */ */
pub mod dummy_item {}
}
pub mod degenerate_cases {
// empty inner line doc
//!
// empty inner block doc
/*!*/
// empty line comment
//
// empty outer line doc
///
// empty block comment
/**/
pub mod dummy_item {}
// empty 2-asterisk block isn't a doc block, it is a block comment
/***/
}
/* The next one isn't allowed because outer doc comments
require an item that will receive the doc */
/// Where is my item?
#[warn(dead_code)]
pub fn test(){}
}
3 type #
- 基础类型:Boolean, Numeric, Textual, Never;
- 序列类型:Tuple, Array, Slice;
- 用户自定义类型:Struct, Enum, Union;
- 函数类型:Functions, Closures;
- 指针类型:References, Raw pointers, Function pointers;
- Trait 类型:Trait objects, impl Trait
栈变量类型:原始值, array/struct/tuple/enum/union
堆变量类型:
- 字符串:String
- 容器:Vec/HashMap/HashSet
- Slice
- 智能指针:Box/Rc/Arc/Cell/RefCell
type alias 并没有引入新类型,所以可以按照本来的方式使用别名,提升代码的可读性。
type Thunk = Box<dyn Fn() + Send + 'static>;
let f: Thunk = Box::new(|| println!("hi"));
fn takes_long_type(f: Thunk) {
// --snip--
}
fn returns_long_type() -> Thunk {
// --snip--
}
type Result<T> = std::result::Result<T, std::io::Error>;
type Meters = u32;
let x: u32 = 5;
let y: Meters = 5;
println!("x + y = {}", x + y); // Meters 是 u32 的 alias,具有 u32 的所有操作。
4 variable #
使用 let 关键字声明变量, 默认不可变(immutable),使用 mut 关键字来声明可变变量。
fn main() {
let _immutable_binding = 1;
let mut mutable_binding = 1;
println!("Before mutation: {}", mutable_binding);
mutable_binding += 1;
println!("After mutation: {}", mutable_binding);
// Error! Cannot assign a new value to an immutable variable
_immutable_binding += 1;
}
Rust 是强类型静态语言,但一般情况下可以省略变量类型,由编译器根据当前赋值或后续操作、赋值等情况,对变量的类型进行自动推导:
// 由编译器根据 expresion 结果或者后续对 var 的使用方式进行推导。
let var = expression;
fn main() {
let elem = 5u8; // 对于数值类型,可以指定类型后缀
// Vec 是泛型类型,元素类型由 Rust 推导。
// 等效于 let mut vec Vec<_> = Vec::new();
let mut vec = Vec::new();
vec.push(elem);
println!("{:?}", vec);
}
变量必须被声明并且初始化后才能使用,声明和初始化可以分开:
fn main() {
// 先声明变量,但未初始化。
let a_binding;
{
let x = 2;
a_binding = x * x; // 变量被首次初始化后,后续才可以开始使用。
}
println!("a binding: {}", a_binding);
let another_binding;
// 变量声明后未初始化,使用时报错。
// println!("another binding: {}", another_binding);
// 变量被初始化后可以使用。
another_binding = 1;
println!("another binding: {}", another_binding);
// 使用复杂的条件判断来初始化变量。
let name;
if user.has_nickname() {
name = user.nickname();
} else {
name = generate_unique_name();
user.register(&name);
}
}
Rust block 可以返回值, 可用于初始化复杂的变量值:
let msg = {
let dandelion_control = puffball.open();
dandelion_control.release_all_seeds(launch_codes);
// 表达式结尾没有分号,结果作为 block 的返回值。
dandelion_control.get_status()
};
// match/if/loop 等语句均有返回值,返回值的类型必须一致。
let display_name = match post.author() {
Some(author) => author.name(),
None => {
let network_info = post.get_network_metadata()?;
let ip = network_info.client_address();
ip.to_string()
}
};
// 如果 if 表达式结果没有用于赋值, 则 block 不能有返回值:
let suggested_pet = if with_wings { Pet::Buzzard } else { Pet::Hyena }; // OK
if preferences.changed() {
page.compute_size() // oops, missing semicolon
}
// error[E0308]: mismatched types
// 22 | page.compute_size() // oops, missing semicolon
// | ^^^^^^^^^^^^^^^^^^^- help: try adding a semicolon:
// `;`
// ||
// | expected (), found tuple |
// = note: expected unit type `()`
// found tuple `(u32, u32)`
Rust 变量默认 都需要被使用 ,否则编译器警告,可以在变量名前加 _ 来表明该变量可能不被使用:
fn main() {
let an_integer = 1u32;
let a_boolean = true;
let unit = ();
println!("A boolean: {:?}", a_boolean);
println!("Meet the unit value: {:?}", unit);
// The compiler warns about unused variable bindings; these warnings can
// be silenced by prefixing the variable name with an underscore
let _unused_variable = 3u32;
}
变量名是 block scope 有效:
- 变量可以被 shadow,shadow 并不会 drop 前面变量的值,shadow 可以为同名变量指定不同的可变性和变量值类型。
- 如果 shadow 使用
同名的变量名,则非 mut 变量可以将前面同名的 mut 变量 freezing,即不可修改。
fn main() {
// 未使用变量遮蔽的情况.
for line_result in file.lines() {
let line = line_result?;
// ...
}
// 同名变量 shadow,可以减少一个变量定义.
for line in file.lines() {
let line = line?;
// ...
}
let x = 5;
let x = x + 1; // shadow 上一个变量 x
{
let x = x * 2; // shadow 上一个变量 x. 变量名是 block 作用域.
println!("The value of x in the inner scope is: {}", x);
}
println!("The value of x is: {}", x); // shadow 并不会 drop 对象, 所以 x 可以继续使用.
let shadowed_binding = 1;
{
println!("before being shadowed: {}", shadowed_binding);
let shadowed_binding = "abc"; // shadow 新变量的类型可以不同.
println!("shadowed in inner block: {}", shadowed_binding);
}
println!("outside inner block: {}", shadowed_binding);
// This binding *shadows* the previous binding
let shadowed_binding = 2;
println!("shadowed in outer block: {}", shadowed_binding);
// freezing
let mut _mutable_integer = 7i32;
{
let _mutable_integer = _mutable_integer;
// Error! `_mutable_integer` is frozen in this scope
_mutable_integer = 50;
// `_mutable_integer` goes out of scope
}
// Ok! `_mutable_integer` is not frozen in this scope
_mutable_integer = 3;
}
Rust 表达式默认不对变量做自动类型转换, 在表达式中不同类型需要使用 as 运算符进行转换. 但是在变量赋值, 函数传参 等场景, Rust 会隐式的做类型转换(type coercion):
#![allow(overflowing_literals)]
fn main() {
let decimal = 65.4321_f32;
// Error! No implicit conversion
let integer: u8 = decimal;
// Explicit conversion
let integer = decimal as u8;
let character = integer as char;
// Error! There are limitations in conversion rules. A float cannot be directly converted to a
// char.
let character = decimal as char;
println!("Casting: {} -> {} -> {}", decimal, integer, character);
// when casting any value to an unsigned type, T,
// T::MAX + 1 is added or subtracted until the value
// fits into the new type
// 1000 already fits in a u16
println!("1000 as a u16 is: {}", 1000 as u16);
// 1000 - 256 - 256 - 256 = 232
// Under the hood, the first 8 least significant bits (LSB) are kept,
// while the rest towards the most significant bit (MSB) get truncated.
println!("1000 as a u8 is : {}", 1000 as u8);
// -1 + 256 = 255
println!(" -1 as a u8 is : {}", (-1i8) as u8);
// For positive numbers, this is the same as the modulus
println!("1000 mod 256 is : {}", 1000 % 256);
// When casting to a signed type, the (bitwise) result is the same as
// first casting to the corresponding unsigned type. If the most significant
// bit of that value is 1, then the value is negative.
// Unless it already fits, of course.
println!(" 128 as a i16 is: {}", 128 as i16);
// In boundary case 128 value in 8-bit two's complement representation is -128
println!(" 128 as a i8 is : {}", 128 as i8);
// repeating the example above
// 1000 as u8 -> 232
println!("1000 as a u8 is : {}", 1000 as u8);
// and the value of 232 in 8-bit two's complement representation is -24
println!(" 232 as a i8 is : {}", 232 as i8);
// Since Rust 1.45, the `as` keyword performs a *saturating cast*
// when casting from float to int. If the floating point value exceeds
// the upper bound or is less than the lower bound, the returned value
// will be equal to the bound crossed.
// 300.0 as u8 is 255
println!(" 300.0 as u8 is : {}", 300.0_f32 as u8);
// -100.0 as u8 is 0
println!("-100.0 as u8 is : {}", -100.0_f32 as u8);
// nan as u8 is 0
println!(" nan as u8 is : {}", f32::NAN as u8);
// This behavior incurs a small runtime cost and can be avoided with unsafe methods, however the
// results might overflow and return **unsound values**. Use these methods wisely:
unsafe {
// 300.0 as u8 is 44
println!(" 300.0 as u8 is : {}", 300.0_f32.to_int_unchecked::<u8>());
// -100.0 as u8 is 156
println!("-100.0 as u8 is : {}", (-100.0_f32).to_int_unchecked::<u8>());
// nan as u8 is 0
println!(" nan as u8 is : {}", f32::NAN.to_int_unchecked::<u8>());
}
}
5 scalar #
Scalar 类型如下:
- signed integers
- i8, i16, i32, i64, i128, isize (pointer size),默认为 i32;
- unsigned integers
- u8, u16, u32, u64, u128, usize (pointer size)
- floating point
- f32, f64, 默认为 f64;
- char
- Unicode 字符,如 ‘a’, ‘α’ and ‘∞’ (占用 4 byte, UTF-32)
- bool
- true/false, 占用 1 byte;
- the unit type ()
- 只有一个空值 ();
- Never
- !
对于数值变量,没有指定类型时默认为 i32 和 f64。字面量可以加类型后缀, 如 23u8, 12.3f64,数字/类型后缀之间可以加下划线, 如 2_3_u8 等效于 23u8。
- 可以使用 0b/0o/0x 表示整型(只能使用小写字母前缀)。
fn main() {
let remainder = 43.0 % 5.0; // 浮点取模运算, 截断除法
let logical: bool = true;
let a_float: f64 = 1.0;
let an_integer = 5i32;
let default_float = 3.0; // f64
let default_integer = 7; // i32
// 类型推导(从后续的赋值语句推导出类型为 i64)。
let mut inferred_type = 12;
inferred_type = 4294967296i64;
let mut mutable = 12;
mutable = 21;
// Error! The type of a variable can't be changed.
//mutable = true;
// Variables can be overwritten with shadowing.
let mutable = true;
}
整数溢出:执行 debug 构建的二进制时 Rust 检查整数溢出并导致 panic。执行 release 构建的二进制时溢出不会被检查,并可能导致 “环绕” 行为。
fn main() {
let x: u8 = 255;
// 使用 wrapping_add 可以防止 panic
let y: u8 = x.wrapping_add(1);
println!("y: {}", y);
// 输出: y: 0
}
Rust 不会为原始类型做隐式的转换,需要使用 as 表达式来显式转换。as 是后缀运算符,优先级非常高。类型转换时,浮点数转换为整数时小数部分将被截断(不进行四舍五入)。
fn main() {
let decimal = 97.123_f32;
let integer: u8 = decimal as u8;
let c1: char = decimal as char;
let c2 = integer as char;
let integer: u32 = 5;
let float: f64 = 3.0;
let int_to_float = integer as f64; // 5.0
// 浮点数转换为整数,小数部分被截断
let float_to_int = float as u32; // 3
}
as 只能用于 primitive 或者 type coercion 类型的转换.
- type coerce: </Users/alizj/.rustup/toolchains/stable-aarch64-apple-darwin/share/doc/rust/html/reference/type-coercions.html>
- </Users/alizj/.rustup/toolchains/stable-aarch64-apple-darwin/share/doc/rust/html/reference/expressions/operator-expr.html#type-cast-expressions>
// `as` expression can only be used to convert between primitive types or to coerce to a specific trait object
// let val: Box<dyn Any + 'a> = *val as Box<dyn Any + 'a>;
let circle = Box::new(circle) as Box<dyn Circle>; // circle 可以 usized 协变到 dyn Circle,所以 OK;
let nonsense = circle.radius() * circle.area();
let a = *const [u16] as *const [u8]
复杂类型转换需要使用 From/Into/TryFrom/TryInto/AsRef/AsMut trait 来进行类型转换, 需要先导入这些trait 才能调用对应的方法.
from() 则通常用于无风险的转换,它不会产生错误。try_from() 方法会返回一个 Result 类型,当转换失败时(例如,因为类型溢出或数据丢失),它会返回一个错误。
use std::convert::TryInto; // 导入转换 Trait
fn main() {
let decimal = 65.4321_f64;
// 然后才能使用 TryInto trait 的 try_into 方法进行安全转换
let integer: u8 = decimal.try_into().unwrap_or_default(); // 出错时返回缺省值 0
// 使用 from 方法进行安全转换
let integer_from = u8::from(42); // 因为 42 可以安全地转换为 `u8`
let string_from = String::from("just for test");
// 字符串的 parse::<T>() 方法可以转换为数值
let i77 = "123".parse::<i32>().unwrap();
let i77: i32 = "123".parse().unwrap();
println!("Safe casting: {} -> {}", decimal, integer);
println!("From casting: {}", integer_from);
}
单元类型 Unit Type:() 既是类型也是唯一值。主要作为函数的返回类型,表明该函数不返回任何数据:
fn main() {
println!("{:p}, {:p}", &(), &()); // 打印地址相同, 说明是唯一类型值
print_message();
// 显式使用单元类型和单元值
let my_unit: () = ();
// 函数参数接受单元类型值
take_unit(());
// 泛型类型也可以使用单元类型, 常用于不需要返回实际值的 Ok.
let result: Result<(), &str> = Ok(());
match result {
Ok(_) => println!("Operation was successful."),
Err(e) => println!("Error occurred: {}", e),
}
}
fn print_message() {
println!("Hello, world!");
// 这个函数隐式返回单元类型 `()`
}
fn take_unit(_unit: ()) {
println!("This function takes a unit type.");
}
6 textual #
textual 类型:char/str/String/OsStr/OsString/CStr/CString/Path/PathBuf
char 是固定 4 bytes 的 Unicode 字符码点(UTF-32), 可以使用 as 在 u8/u32 相互转换。使用 as 将 char 转换为整型的字符码点, 使用 std::char::from_u32() 将码点转换为 char.
fn main() {
let emoji: char = '😂';
let chinese_character: char = '中';
let word = "Rust语言";
for ch in word.chars() {
println!("{}", ch);
}
// 将字符转换为对应的 Unicode 代码点
let unicode_codepoint = '🦀' as u32;
println!("The Unicode code point of '🦀' is: U+{:X}", unicode_codepoint);
let character_from_codepoint = std::char::from_u32(unicode_codepoint).unwrap_or_default();
println!("The character from code point U+{:X} is: '{}'", unicode_codepoint, character_from_codepoint);
}
str 是原始类型,对应一块 [u8] 连续内存区域,保存的是字符串的 UTF-8 编码值。str 编译时大小未知,一般不能直接作为变量类型使用,而是使用借用类型 &str 或智能指针 Box<str> 类型:
- &str 是 fat pointer,包括指向内存区域的地址的指针和字符的数量(长度);
use std::slice;
use std::str;
let story = "Once upon a time...";
let ptr = story.as_ptr(); // 指向内存区域的 *const u8
let len = story.len();
assert_eq!(19, len);
let s = unsafe {
// First, we build a &[u8]...
let slice = slice::from_raw_parts(ptr, len);
// ... and then convert that slice into a string slice
str::from_utf8(slice)
};
assert_eq!(s, Ok(story));
// 使用智能指针保存 str
let boxed: Box<str> = Box::from("hello");
assert_eq!(Cow::from("eggplant"), Cow::Borrowed("eggplant"));
let shared: Rc<str> = Rc::from("statue");
// 从 &str 创建 Vec<u8>
assert_eq!(Vec::from("123"), vec![b'1', b'2', b'3']);
Rust 字符串字面量类型是 &‘static str:
fn main() {
let hello_world = "Hello, World!";
// 等效于
let hello_world: &'static str = "Hello, world!";
//let s: str = "hello, world"; // 错误,str 不能直接作为类型
let s: &str = "hello, world"; // OK
// 在堆上分配字符串内存,s 拥有该对象
let s: Box<str> = "hello, world".into();
greetings(&s); // Box<str> 实现了 Deref<Target=str>, 所以 &Box<str> 等效于 &str
// 使用 &'static str 可以避免为 struct 指定 lifetime 参数
struct Anime { name: &'static str, bechdel_pass: bool };
let aria = Anime { name: "Aria: The Animation", bechdel_pass: true };
// &str 不能自动协变到 &[u8], 可以使用 as_bytes() 转换为 &[u8]
let bytes = "bors".as_bytes();
assert_eq!(b"bors", bytes);
}
fn greetings(s: &str) {
println!("{}",s);
}
其他:
- char 是固定的 4 bytes 长度的 Unicode 码点;
- b’x’: byte char,只能是 ASCII,字符 x 的 UTF-8 编码值(u8 类型), 如 104 == b’h’;
- b"xyz": byte string,只能是 ASCII,&[u8; N] 数组借用类型,如 &[‘x’, ‘y’, ‘z’];
- r###"\a\b\c"###: raw string,不对字符串内容转义,r 后面的 # 数量可变, 但只能使用连续的 # 字符;
- br##"\a\b\c\t\n"##: raw byte string,只能是 ASCII,类型为 &[u8, 10], 不对字符串转义,必须是 br 而不能是 rb;
- c"hello":C string,以 NULL 结尾的 C 字符串。
- cr#“hello”#:raw C string,以 NULL 结尾的 C 原生字符串。
byte string 的类型是 &[u8; N],可以当作 &[u8] 使用:
let method = b"GET";
assert_eq!(method, &[b'G', b'E', b'T']);
字符串可以包含换行, 转义字符(如 \x23, \u{211D}), 默认左对齐, 行尾如果是 \ 字符, 则删除换行符:
- 转义字符包括:\xaF, \n, \r, \t, \\, \0, \’, \", \u{0}, \u{00}, …, \u{000000},不包括二进制和八进制。
let s1 = String::from("hello,");
println!("#{:20.20}#", s1); // 字符串显示默认左对齐(数字是右对齐),显示: #hello, #
println!("{}", "a\t
b \
c d
ef
");
String 和 &str 的 Index 操作返回 &str, 但是需要保证 &s[i..j] 的 i..j 是有效的字符边界,否则 panic,可以使用 non-panicking 版本 get();
- s[i] 是禁止的,因为 String/&str 是 UTF-8 编码,返回 &u8 可能是无意义的;
let s = String::from("hello world");
let hello = &s[0..5]; // &str 类型
println!("{}", hello);
let s = "hello";
// println!("The first letter of s is {}", s[0]); // 错误,不支持 s[0];
// 可以使用 as_bytes() 方法将 String/&str 转换为 &[u8], 然后再 index 某个 u8:
let s = "hello";
assert_eq!(s.as_bytes()[0], 104);
assert_eq!(s.as_bytes()[0], b'h');
let s = "💖💖💖💖💖";
assert_eq!(s.as_bytes()[0], 240);
内存布局:
- String:指向堆内存的指针,内存的长度(bytes),内存的容量(bytes)。
- &str:指向 slice 内存的指针,slice 的长度(bytes)
str 和 String 都是 严格遵守 UTF-8 编码的 ,但是对于一些操作系统文件名或路径,可以不是 UTF-8 编码的字符串,所以 Rust 引入了 std::ffi::OsStr/OsString 类型:
- OsStr 是 unsized type,一般需要和 & 和 Box 使用,不可以改变,类似于 str;
- OsString 是 sized type,是 OsStr 的 Owned 类型,可以修改,类似于 String;
- OsString 实现了 Deref<target = OsStr>, 所以 &OsString 可以使用 &OsStr 定义的所有方法。
use std::ffi::OsStr;
let os_str = OsStr::new("foo");
OsStr 的方法:
- pub fn as_encoded_bytes(&self) -> &[u8]
- pub fn into_os_string(self: Box<OsStr>) -> OsString
- pub fn make_ascii_lowercase(&mut self)
- pub fn to_os_string(&self) -> OsString
- pub fn to_str(&self) -> Option<&str>
- pub fn to_string_lossy(&self) -> Cow<’_, str>
OsStr/OsString 都不是 NULL 终止的字符串, std::ffi::CStr 和 std::ffi::CString 是 C 风格的 NULL 终止的字符串。
CStr 也有字面量形式:
- c"hello":以 NULL 结尾的 C 原生字符串。
- cr#“hello”#:以 NULL 结尾的 C 原生字符串。
use std::ffi::CString;
use std::os::raw::c_char;
fn main() {
let s = String::from("Hello, world!");
let cs = CString::new(s).unwrap();
let p = cs.as_ptr() as *const c_char;
println!("Address: {:?}", p);
}
6.1 str 方法 #
- len() : 返回 bytes 数量。
- is_empty()
- is_char_boundary()
- as_bytes() -> &[u8]
- as_ptr()/as_mut_ptr():返回 raw pointer: *const 和 *mut
- get()/get_mut():
安全返回子串; - chars()/bytes():返回 char 和 byte 的迭代器;
- split_whitespace(): 返回空白字符分割的子串迭代器,连续的空白字符等效为一个;
- lines(): 返回行迭代器,行尾不包括换行;
- contains()/starts_with()/ends_with(): 检查 pattern,
pattern 支持多种类型; - find()/rfind(): 返回匹配 pattern 的 index;
- match()/rmatch(): 返回匹配 pattern 的子串迭代器;
- trim_XX()/strip_XX(): 删除空格、删除前后缀;
- parse<T>: 将字符串转换为 T 类型,T 必须要实现 FromStr trait;
- replace(): 将 pattern 替换为子串;
- into_string()/to_string(): 将 &str 转换为 String;
// 返回字符串的 bytes(而非字符)长度
pub const fn len(&self) -> usize
let len = "foo".len();
assert_eq!(3, len); // 字节长度
assert_eq!("ƒoo".chars().count(), 3); // 字符数量
pub const fn is_empty(&self) -> bool
pub fn is_char_boundary(&self, index: usize) -> bool
// Finds the closest x not exceeding index where is_char_boundary(x) is true.
pub fn floor_char_boundary(&self, index: usize) -> usize
#![feature(round_char_boundary)]
let s = "❤️🧡💛💚💙💜";
assert_eq!(s.len(), 26);
assert!(!s.is_char_boundary(13));
let closest = s.floor_char_boundary(13);
assert_eq!(closest, 10);
assert_eq!(&s[..closest], "❤️🧡");
pub fn ceil_char_boundary(&self, index: usize) -> usize
// 转换为 slice 借用
pub const fn as_bytes(&self) -> &[u8]
let bytes = "bors".as_bytes();
assert_eq!(b"bors", bytes);
pub unsafe fn as_bytes_mut(&mut self) -> &mut [u8]
let mut s = String::from("Hello");
let bytes = unsafe { s.as_bytes_mut() };
assert_eq!(b"Hello", bytes);
pub const fn as_ptr(&self) -> *const u8
pub fn as_mut_ptr(&mut self) -> *mut u8
let s = "Hello";
let ptr = s.as_ptr();
// 安全返回一个子字符串 &str,如果不在字符串边界,返回 None
pub fn get<I>(&self, i: I) -> Option<&<I as SliceIndex<str>>::Output> where I: SliceIndex<str>,
pub fn get_mut<I>( &mut self, i: I) -> Option<&mut <I as SliceIndex<str>>::Output> where I: SliceIndex<str>,
let v = String::from("🗻∈🌏");
assert_eq!(Some("🗻"), v.get(0..4));
// indices not on UTF-8 sequence boundaries
assert!(v.get(1..).is_none());
assert!(v.get(..8).is_none());
// out of bounds
assert!(v.get(..42).is_none());
// 返回一个子字符串 &str,调用者确保传入的 index 范围是有效的。
pub unsafe fn get_unchecked<I>(&self, i: I) -> &<I as SliceIndex<str>>::Output where I: SliceIndex<str>,
pub unsafe fn get_unchecked_mut<I>( &mut self, i: I ) -> &mut <I as SliceIndex<str>>::Output where I: SliceIndex<str>,
// 分割字符串
pub fn split_at(&self, mid: usize) -> (&str, &str)
pub fn split_at_mut(&mut self, mid: usize) -> (&mut str, &mut str)
pub fn split_at_checked(&self, mid: usize) -> Option<(&str, &str)>
pub fn split_at_mut_checked( &mut self, mid: usize ) -> Option<(&mut str, &mut str)>
// 返回字符串的 char 或 byte 迭代器
pub fn chars(&self) -> Chars<'_> ⓘ
pub fn char_indices(&self) -> CharIndices<'_>
pub fn bytes(&self) -> Bytes<'_>
// 返回空白字符分割的子字符串迭代器
pub fn split_whitespace(&self) -> SplitWhitespace<'_>
pub fn split_ascii_whitespace(&self) -> SplitAsciiWhitespace<'_>
let mut iter = " Mary had\ta\u{2009}little \n\t lamb".split_whitespace();
assert_eq!(Some("Mary"), iter.next());
assert_eq!(Some("had"), iter.next());
assert_eq!(Some("a"), iter.next());
assert_eq!(Some("little"), iter.next()); // 多个连续空白字符视为一个
assert_eq!(Some("lamb"), iter.next());
assert_eq!(None, iter.next());
assert_eq!("".split_whitespace().next(), None);
assert_eq!(" ".split_whitespace().next(), None);
// 返回行迭代器,如果是空行则返回空字符串,不包括行尾的换行
pub fn lines(&self) -> Lines<'_>
pub fn lines_any(&self) -> LinesAny<'_>
let text = "foo\nbar\n\r\nbaz";
let mut lines = text.lines();
assert_eq!(Some("foo"), lines.next());
assert_eq!(Some("bar"), lines.next());
assert_eq!(Some(""), lines.next());
assert_eq!(Some("baz"), lines.next());
assert_eq!(None, lines.next());
pub fn encode_utf16(&self) -> EncodeUtf16<'_> ⓘ
// 是否包含 pattern
pub fn contains<'a, P>(&'a self, pat: P) -> bool where P: Pattern<'a>,
// 是否以 pattern 开始或结束
pub fn starts_with<'a, P>(&'a self, pat: P) -> bool where P: Pattern<'a>,
pub fn ends_with<'a, P>(&'a self, pat: P) -> bool where P: Pattern<'a>, <P as Pattern<'a>>::Searcher: ReverseSearcher<'a>,
// find 返回匹配 pattern 的 index,如果为找到则返回 None
pub fn find<'a, P>(&'a self, pat: P) -> Option<usize> where P: Pattern<'a>,
pub fn rfind<'a, P>(&'a self, pat: P) -> Option<usize> where P: Pattern<'a>, <P as Pattern<'a>>::Searcher: ReverseSearcher<'a>,
// 拆分字符串为可迭代的子串 &str
pub fn split<'a, P>(&'a self, pat: P) -> Split<'a, P> where P: Pattern<'a>,
pub fn split_inclusive<'a, P>(&'a self, pat: P) -> SplitInclusive<'a, P> where P: Pattern<'a>,
pub fn rsplit<'a, P>(&'a self, pat: P) -> RSplit<'a, P> where P: Pattern<'a>, <P as Pattern<'a>>::Searcher: ReverseSearcher<'a>,
pub fn split_terminator<'a, P>(&'a self, pat: P) -> SplitTerminator<'a, P> where P: Pattern<'a>,
pub fn rsplit_terminator<'a, P>(&'a self, pat: P) -> RSplitTerminator<'a, P> where P: Pattern<'a>, <P as Pattern<'a>>::Searcher: ReverseSearcher<'a>,
pub fn splitn<'a, P>(&'a self, n: usize, pat: P) -> SplitN<'a, P> where P: Pattern<'a>,
pub fn rsplitn<'a, P>(&'a self, n: usize, pat: P) -> RSplitN<'a, P> where P: Pattern<'a>, <P as Pattern<'a>>::Searcher: ReverseSearcher<'a>,
pub fn split_once<'a, P>(&'a self, delimiter: P) -> Option<(&'a str, &'a str)> where P: Pattern<'a>,
pub fn rsplit_once<'a, P>(&'a self, delimiter: P) -> Option<(&'a str, &'a str)> where P: Pattern<'a>, <P as Pattern<'a>>::Searcher: ReverseSearcher<'a>,
let v: Vec<&str> = "Mary had a little lamb".split(' ').collect();
assert_eq!(v, ["Mary", "had", "a", "little", "lamb"]);
let v: Vec<&str> = "".split('X').collect();
assert_eq!(v, [""]);
let v: Vec<&str> = "lionXXtigerXleopard".split('X').collect();
assert_eq!(v, ["lion", "", "tiger", "leopard"]);
// 返回匹配 pattern 的子字符串迭代器
pub fn matches<'a, P>(&'a self, pat: P) -> Matches<'a, P> where P: Pattern<'a>,
pub fn rmatches<'a, P>(&'a self, pat: P) -> RMatches<'a, P> where P: Pattern<'a>, <P as Pattern<'a>>::Searcher: ReverseSearcher<'a>,
pub fn match_indices<'a, P>(&'a self, pat: P) -> MatchIndices<'a, P> where P: Pattern<'a>,
pub fn rmatch_indices<'a, P>(&'a self, pat: P) -> RMatchIndices<'a, P> where P: Pattern<'a>, <P as Pattern<'a>>::Searcher: ReverseSearcher<'a>,
let v: Vec<&str> = "abcXXXabcYYYabc".matches("abc").collect();
assert_eq!(v, ["abc", "abc", "abc"]);
let v: Vec<&str> = "1abc2abc3".matches(char::is_numeric).collect();
assert_eq!(v, ["1", "2", "3"]);
// 删除(执行多次)start/end 两端的空格或两端匹配的 pattern
pub fn trim(&self) -> &str
pub fn trim_start(&self) -> &str
pub fn trim_end(&self) -> &str
pub fn trim_matches<'a, P>(&'a self, pat: P) -> &'a str where P: Pattern<'a>, <P as Pattern<'a>>::Searcher: DoubleEndedSearcher<'a>,
pub fn trim_start_matches<'a, P>(&'a self, pat: P) -> &'a str where P: Pattern<'a>,
pub fn trim_end_matches<'a, P>(&'a self, pat: P) -> &'a str where P: Pattern<'a>, <P as Pattern<'a>>::Searcher: ReverseSearcher<'a>,
// 删除开头的前缀,不像 trim_start_matches 那样删除多次,而是最多删除一次
pub fn strip_prefix<'a, P>(&'a self, prefix: P) -> Option<&'a str> where P: Pattern<'a>,
pub fn strip_suffix<'a, P>(&'a self, suffix: P) -> Option<&'a str> where P: Pattern<'a>, <P as Pattern<'a>>::Searcher: ReverseSearcher<'a>,
// 将字符串转换为其他类型 F,F 类型需要实现 FromStr trait。Rust 的基本类型都实现了该 trait。
pub fn parse<F>(&self) -> Result<F, <F as FromStr>::Err> where F: FromStr,
pub const fn is_ascii(&self) -> bool
pub const fn as_ascii(&self) -> Option<&[AsciiChar]>
pub fn eq_ignore_ascii_case(&self, other: &str) -> bool
pub fn make_ascii_uppercase(&mut self)
pub fn make_ascii_lowercase(&mut self)
pub const fn trim_ascii_start(&self) -> &str
pub const fn trim_ascii_end(&self) -> &str
pub const fn trim_ascii(&self) -> &str
pub fn escape_debug(&self) -> EscapeDebug<'_>
pub fn escape_default(&self) -> EscapeDefault<'_>
pub fn escape_unicode(&self) -> EscapeUnicode<'_>
impl str
pub fn into_boxed_bytes(self: Box<str>) -> Box<[u8]>
// 替换
pub fn replace<'a, P>(&'a self, from: P, to: &str) -> String where P: Pattern<'a>,
pub fn replacen<'a, P>(&'a self, pat: P, to: &str, count: usize) -> String where P: Pattern<'a>,
pub fn to_lowercase(&self) -> String
pub fn to_uppercase(&self) -> String
// &str 转为 String
pub fn into_string(self: Box<str>) -> String
pub fn repeat(&self, n: usize) -> String
pub fn to_ascii_uppercase(&self) -> String
pub fn to_ascii_lowercase(&self) -> String
find/match/trim() 方法的 Pattern 参数类型:
| Pattern type | Match condition |
|---|---|
| &str | is substring |
| char | is contained in string |
| &[char] | any char in slice is contained in string |
| F: FnMut(char) -> bool | F returns true for a char in string |
| &&str | is substring |
| &String | is substring |
// &str
assert_eq!("abaaa".find("ba"), Some(1));
assert_eq!("abaaa".find("bac"), None);
// char
assert_eq!("abaaa".find('a'), Some(0));
assert_eq!("abaaa".find('b'), Some(1));
assert_eq!("abaaa".find('c'), None);
// &[char; N]
assert_eq!("ab".find(&['b', 'a']), Some(0));
assert_eq!("abaaa".find(&['a', 'z']), Some(0));
assert_eq!("abaaa".find(&['c', 'd']), None);
// &[char]
assert_eq!("ab".find(&['b', 'a'][..]), Some(0));
assert_eq!("abaaa".find(&['a', 'z'][..]), Some(0));
assert_eq!("abaaa".find(&['c', 'd'][..]), None);
// FnMut(char) -> bool
assert_eq!("abcdef_z".find(|ch| ch > 'd' && ch < 'y'), Some(4));
assert_eq!("abcddd_z".find(|ch| ch > 'd' && ch < 'y'), None);
FromStr trait: 从 &str 来生成各种类型的值,Rust 基本类型,如整数、浮点数、bool、char、String、 PathBuf、IpAddr、SocketAddr、Ipv4Addr、Ipv6Addr 都实现了该 trait。
- 被泛型方法 &str.parse::<T>() 方法隐式调用。
- 使用 &str.parse() 方法时一般需要指定目标对象类型,否则编译器可能不知道该调用那个类型的 FromStr trait 实现而报错:
pub trait FromStr: Sized {
type Err;
// Required method
fn from_str(s: &str) -> Result<Self, Self::Err>;
}
pub fn parse<F>(&self) -> Result<F, <F as FromStr>::Err> where F: FromStr,
let four: u32 = "4".parse().unwrap();
assert_eq!(4, four);
let four = "4".parse::<u32>();
assert_eq!(Ok(4), four);
// Error
let nope = "j".parse::<u32>();
assert!(nope.is_err());
6.2 String #
&str 和 String 间转换:
- String -> &str: String.as_str();
- String::from(“Sunfei”) 或 “Sunface”.to_string()
创建 String:
- &str.to_string()
- &str.to_owned()
- format!()
- Array/slice/Vec 的 .concat() 和 .join()
- String::from()/String::from_utf8()
let error_message = "too many pets".to_string();
assert_eq!(format!("{}°{:02}′{:02}′′N", 24, 5, 23), "24°05′23′′N".to_string());
let bits = vec!["veni", "vidi", "vici"];
assert_eq!(bits.concat(), "venividivici");
assert_eq!(bits.join(", "), "veni, vidi, vici");
let hello = String::from("Hello, world!");
let mut hello = String::from("Hello, ");
// push 字符
hello.push('w');
// push 字面量
hello.push_str("orld!");
// some bytes, in a vector
let sparkle_heart = vec![240, 159, 146, 150];
// We know these bytes are valid, so we'll use `unwrap()`.
let sparkle_heart = String::from_utf8(sparkle_heart).unwrap();
assert_eq!("💖", sparkle_heart);
let s = "hello";
let third_character = s.chars().nth(2);
assert_eq!(third_character, Some('l'));
let noodles = "noodles".to_string();
let oodles = &noodles[1..]; // String/str 的 slice 操作返回 &str
String 类型实现了 Defref<Target = str>, 所以:
- String 类型可以使用 str 定义的所有方法;
- 在需要 &str 类型的地方可以传入 &String;
String 可以 +/+= &str, 但是不支持 &str 之间的 +/+= 以及 &str + String 的操作:
let mut ss = String::from("abcd");
ss += " def"; // OK: String + &str
// " def" + ss; // `+` cannot be used to concatenate a `&str` with a `String`
" def".to_owned() + &ss; // OK
let s1 = String::from("hello,");
let s2 = String::from("world!");
let s3 = s1 + &s2; // let s3 = s1.clone() +&s2;
assert_eq!(s3, "hello,world!");
//println!("{}", s1); // s1 已经在上面的 + 操作被 move, 导致继续使用 s1 出错。
String 的底层表示是 Vec<u8>, 所以它的栈内存布局包括三部分,可以使用 as_ptr()/len()/capacity() 来获取它们的值:
- 指向堆连续内存的地址;
- 内存 byte 长度;
- 内存 byte 容量;
use std::mem;
let story = String::from("Once upon a time...");
// Prevent automatically dropping the String's data
let mut story = mem::ManuallyDrop::new(story);
let ptr = story.as_mut_ptr();
let len = story.len();
let capacity = story.capacity();
assert_eq!(19, len);
// We can re-build a String out of ptr, len, and capacity. This is all unsafe because we are
// responsible for making sure the components are valid:
let s = unsafe { String::from_raw_parts(ptr, len, capacity) } ;
assert_eq!(String::from("Once upon a time..."), s);
String 方法:
- new()/with_capacity()
- len()/capacity()/is_empty()
- from_utf8_XX()
- into_raw_parts()/from_raw_parts()
- into_bytes()/into_boxed_str()/as_bytes()/as_str()/as_mut_str()
- push()/push_str()
- reserve()/shrink_to()/truncate()/clear()
- pop()/remove()/retaion()/insert()/insert_str()/drain()/clear()
impl String
// 空 String
pub const fn new() -> String
// 指定初始容量的空 String
pub fn with_capacity(capacity: usize) -> String
// 从 Vec<u8> 创建 String
pub fn from_utf8(vec: Vec<u8>) -> Result<String, FromUtf8Error>
pub unsafe fn from_utf8_unchecked(bytes: Vec<u8>) -> String
// 从 &[u8] 创建 String
pub fn from_utf8_lossy(v: &[u8]) -> Cow<'_, str>
pub fn from_utf16(v: &[u16]) -> Result<String, FromUtf16Error>
pub fn from_utf16_lossy(v: &[u16]) -> String
pub fn from_utf16le(v: &[u8]) -> Result<String, FromUtf16Error>
pub fn from_utf16le_lossy(v: &[u8]) -> String
pub fn from_utf16be(v: &[u8]) -> Result<String, FromUtf16Error>
pub fn from_utf16be_lossy(v: &[u8]) -> String
// raw pointer 互操作
pub fn into_raw_parts(self) -> (*mut u8, usize, usize)
pub unsafe fn from_raw_parts(buf: *mut u8, length: usize, capacity: usize ) -> String
// 转换为 Vec<u8>, &[u8], &str
pub fn into_bytes(self) -> Vec<u8>
pub unsafe fn as_mut_vec(&mut self) -> &mut Vec<u8>
pub fn into_boxed_str(self) -> Box<str>
pub fn as_bytes(&self) -> &[u8]
pub fn as_str(&self) -> &str
pub fn as_mut_str(&mut self) -> &mut str
// 添加或指定位置插入 char 或 &str
pub fn push(&mut self, ch: char)
pub fn push_str(&mut self, string: &str)
pub fn extend_from_within<R>(&mut self, src: R) where R: RangeBounds<usize>,
pub fn insert(&mut self, idx: usize, ch: char)
pub fn insert_str(&mut self, idx: usize, string: &str)
// 返回容量和长度
pub fn capacity(&self) -> usize
pub fn len(&self) -> usize
pub fn is_empty(&self) -> bool
// 修改长度
pub fn reserve(&mut self, additional: usize)
pub fn reserve_exact(&mut self, additional: usize)
pub fn try_reserve(&mut self, additional: usize) -> Result<(), TryReserveError>
pub fn try_reserve_exact( &mut self, additional: usize) -> Result<(), TryReserveError>
pub fn shrink_to_fit(&mut self)
pub fn shrink_to(&mut self, min_capacity: usize)
pub fn truncate(&mut self, new_len: usize)
pub fn clear(&mut self)
// 删除某个字符 char
pub fn pop(&mut self) -> Option<char>
pub fn remove(&mut self, idx: usize) -> char
pub fn remove_matches<P, 'a>(&'a mut self, pat: P) where P: for<'x> Pattern<'x>,
// 只保留 f 返回 true 的字符
pub fn retain<F>(&mut self, f: F) where F: FnMut(char) -> bool,
let mut s = String::from("f_o_ob_ar");
s.retain(|c| c != '_');
assert_eq!(s, "foobar");
pub fn split_off(&mut self, at: usize) -> String
// 删除指定范围的字符,返回删除字符串的迭代器
pub fn drain<R>(&mut self, range: R) -> Drain<'_> where R: RangeBounds<usize>,
let mut s = String::from("α is alpha, β is beta");
let beta_offset = s.find('β').unwrap_or(s.len());
// Remove the range up until the β from the string
let t: String = s.drain(..beta_offset).collect();
assert_eq!(t, "α is alpha, ");
assert_eq!(s, "β is beta");
// A full range clears the string, like `clear()` does
s.drain(..);
assert_eq!(s, "");
pub fn replace_range<R>(&mut self, range: R, replace_with: &str) where R: RangeBounds<usize>,
pub fn leak<'a>(self) -> &'a mut str
在 push 或 insert 时,String 自动调整容量:
let mut s = String::new();
println!("{}", s.capacity());
for _ in 0..5 {
s.push_str("hello");
println!("{}", s.capacity());
}
// 如果一次分配好容量,则后续可能不会自动临时调大
let mut s = String::with_capacity(25);
println!("{}", s.capacity());
for _ in 0..5 {
s.push_str("hello");
println!("{}", s.capacity());
}
6.3 [u8] 方法 #
String 和 &str 的 as_bytes() 方法返回 &[u8].
b"xxx" 的类型是 &[u8; N] 数组引用,可以自动被 unsized coercion 到 &[u8]:
impl [u8]
// 检查 [u8] 各元素是否是 ascii
pub const fn is_ascii(&self) -> bool
pub const fn as_ascii(&self) -> Option<&[AsciiChar]>
pub const unsafe fn as_ascii_unchecked(&self) -> &[AsciiChar]
pub fn eq_ignore_ascii_case(&self, other: &[u8]) -> bool
pub fn make_ascii_uppercase(&mut self)
pub fn make_ascii_lowercase(&mut self)
pub fn escape_ascii(&self) -> EscapeAscii<'_>
let s = b"0\t\r\n'\"\\\x9d";
let escaped = s.escape_ascii().to_string();
assert_eq!(escaped, "0\\t\\r\\n\\'\\\"\\\\\\x9d");
pub const fn trim_ascii_start(&self) -> &[u8]
#![feature(byte_slice_trim_ascii)]
assert_eq!(b" \t hello world\n".trim_ascii_start(), b"hello world\n");
assert_eq!(b" ".trim_ascii_start(), b"");
assert_eq!(b"".trim_ascii_start(), b"");
pub const fn trim_ascii_end(&self) -> &[u8]
pub const fn trim_ascii(&self) -> &[u8]
[u8] 的 as_ascii() 返回 [AsciiChar] 类型:
impl [AsciiChar]
pub const fn as_str(&self) -> &str
pub const fn as_bytes(&self) -> &[u8]
7 array #
array 是同类型元素的和固定长度的,在栈上分配的连续内存空间,用 [T; N] 表示,N 必须是编译时常量:
fn init_arr(n: i32) {
let arr = [1; n]; // 错误, n 不是编译时常量.
}
创建 array:
// 声明一个有 5 个 i32 整数的数组
let numbers: [i32; 5] = [1, 2, 3, 4, 5];
// 声明一个有 5 个元素都是 0 的数组. 表达式右侧 [Value; N] 的 Value 必须实现 Copy
let zeroes: [i32; 5] = [0; 5];
let mut values: [i32; 3] = [10, 20, 30];
values[1] = 25;
println!("values: {:?}", values);
println!("The array has {} elements.", values.len());
Rust 数组和集合的元素索引都从 0 开始, 必须 < len(), 否则会 panic,但是可以通过 get(i) 返回的 Option<&T> 来判断 index 对应的元素是否存在。
array 的 slice 操作 a[start..end] 返回一个 dynamic size 的 slice 类型 [T],故一般使用 &[T] 或 Box<[T]>:
- slice 操作返回的 &a[start..ennd] 不需要拷贝堆内存, 它们不拥有任何数据,而只是借用数组或其他集合中的数据。
let arr = [1, 2, 3, 4, 5];
// 创建一个包含整个数组的 slice
let slice_whole = &arr[..];
// 创建一个包含数组中一部分元素的 slice
let slice_part = &arr[1..4];
let a = [1, 2, 3, 4, 5];
// a[1..3] 返回的类型为 [i32], &a[1..3] 返回的类型为 &[i32]
let slice = &a[1..3];
// &[i32] 可以直接和 &[i32; 2] 类型比较
assert_eq!(slice, &[2, 3]);
// 一个接受切片作为参数的函数
fn sum(slice: &[i32]) -> i32 {
let mut total = 0;
for i in slice {
total += i;
}
total
}
fn main() {
let arr = [1, 2, 3, 4, 5];
let result = sum(&arr[1..4]); // 只计算数组一部分的和
println!("The sum of the part of the array is: {}", result);
}
[T] 和 array 的相互转换:[T] 是 dynamic size, 不能反向 coerce 到 array, 但是可以使用 slice.try_into().unwrap() 或 <ArrayType>::try_from(slice).unwrap() 来在相同长度的 slice 和 array 之间转换:
let bytes: [u8; 3] = [1, 0, 2];
// &bytes[0..2] 返回 slice
// <[u8; 2]>::try_from(&bytes[0..2]) 是从 slice 生成 array
assert_eq!(1, u16::from_le_bytes(<[u8; 2]>::try_from(&bytes[0..2]).unwrap()));
// bytes[1..3] 返回 slice, 用来生成 array
assert_eq!(512, u16::from_le_bytes(bytes[1..3].try_into().unwrap()));
let mut bytes: [u8; 3] = [1, 0, 2];
let bytes_head: [u8; 2] = <[u8; 2]>::try_from(&mut bytes[0..2]).unwrap();
assert_eq!(1, u16::from_le_bytes(bytes_head));
let bytes_tail: [u8; 2] = (&mut bytes[1..3]).try_into().unwrap();
assert_eq!(512, u16::from_le_bytes(bytes_tail));
array 支持 for-in 迭代,结果为数组元素 T:
- slice 操作 &a[m..n], 结果为切片引用 &[T],它也支持迭代,但迭代结果为 &T;
fn main() {
let mut numbers: [i32; 5] = [1, 2, 3, 4, 5];
for number in numbers { // numbers.iter()/numbers.iter_mut()/numbers.into_iter()
println!("number: {}", number);
}
}
Rust 不允许 Array/Vec/HashMap/HashSet 中的元素被 partial move 出来(全部 move 出来是 OK 的),所以如果 array 元素不支持 Copy,则 index 操作后再赋值转移会失败:
- 但是允许 struct/tuple/union 中的 field 被部分 move 出来。
- 解决办法是使用 std::mem::replace() 来用其同类型对象来替换:
- Slice patterns can match both arrays of fixed size and slices of dynamic size.
fn move_away(_: String) { /* Do interesting things. */ }
// 全部 move 出来,OK!
let [john, roa] = ["John".to_string(), "Roa".to_string()];
move_away(john);
move_away(roa);
// 有问题代码:
struct Buffer<T> { buf: Vec<T> }
impl<T> Buffer<T> {
fn replace_index(&mut self, i: usize, v: T) -> T {
// error: cannot move out of dereference of `&mut`-pointer
let t = self.buf[i]; // 失败
self.buf[i] = v;
t
}
}
// std::mem::replace 对 &mut 对象替换, 返回替换前的对象
use std::mem;
impl<T> Buffer<T> {
fn replace_index(&mut self, i: usize, v: T) -> T {
mem::replace(&mut self.buf[i], v)
}
}
let mut buffer = Buffer { buf: vec![0, 1] };
assert_eq!(buffer.buf[0], 0);
assert_eq!(buffer.replace_index(0, 2), 0);
assert_eq!(buffer.buf[0], 2);
array 没有实现 Display,但是如果元素类型实现了 Debug 则数组也实现 Debug:
println!("numbers: {:?}", numbers);
println!("zeroes: {:?}", zeroes);
如果 array 元素类型实现了如下 trait,则 array 也实现了对应 trait:
- Copy,Clone
- Debug( array 没有实现 Display)
- IntoIterator (implemented for [T; N], &[T; N] and &mut [T; N])
- PartialEq, PartialOrd, Eq, Ord
- Hash
- AsRef, AsMut
- Borrow, BorrowMut
array [T; N] 可以被 type coerce 到 slice 类型 [T]:
- &[T; N ] 可以被隐式自动转换为 &[T],所以
array 可以调用 slice 的方法。 - array 并没有实现 Deref trait,所以上面的自动转换不是 Deref 的行为;
// 左边是类型, 右边是初始化表达式!
let mut array: [i32; 3] = [0; 3];
// coercing an array to a slice
let str_slice: &[&str] = &["one", "two", "three"];
// numbers 是 &[i32; 3] 类型,函数传参时被自动转换为 &[i32] 类型
let numbers = &[0, 1, 2];
print_type_of(&numbers);
// 数组 [i32; 3] 可以被 type coerce 到 [T], 所以 &[i32; 3] 可以被赋值给 &[i32]
let numbers: &[i32] = &[0, 1, 2];
print_type_of(&numbers);
// number 虽然前面没有加 &, 但是它本身是 &[i32] 类型, 所以迭代后元素 n 是 &32 类型.
for n in numbers {
print_type_of(&n); // n 是 &32 类型
}
fn print_type_of<T>(v: &T) -> String {
format!("{}", std::any::type_name_of_val(v))
}
// i32,切片引用支持 index 操作,返回元素本身, 必须实现 Copy, 否则报错。
print_type_of(&numbers[0]);
arrary 类型 [T; N] 可以 type coerce 到 [T], 进而 type coerce 到 Box<[T]>:
// A heap-allocated array, coerced to a slice
let boxed_array: Box<[i32]> = Box::new([1, 2, 3]);
8 slice #
slice 代表一块连续的内存区域,用 [T] 表示,它是编译时大小未知的类型。作为变量/函数输入/输出参数类型来使用时, 一般使用具体固定大小的 &[T] 或 Box<[T]> 类型:
- 虽然编译时大小未知,但是 .len() 方法返回 slice 的元素数量;
- &[T] 固定大小为 2 usize 的 fat pointer,包含指向内存区域的指针和元素数量;
let pointer_size = std::mem::size_of::<&u8>();
assert_eq!(2 * pointer_size, std::mem::size_of::<&[u8]>());
assert_eq!(2 * pointer_size, std::mem::size_of::<*const [u8]>());
assert_eq!(2 * pointer_size, std::mem::size_of::<Box<[u8]>>());
assert_eq!(2 * pointer_size, std::mem::size_of::<Rc<[u8]>>());
创建 slice &[T]:
- 对 array/Vec/String/&str 的 range index 操作返回 [T], 如 &v[0..2],&v[1..],&v[..] 等;
- Vec[T] 实现了 Deref<Target=[T]>,所以 &Vec<T> 可以被隐式转换为 &[T],在需要 &[T] 类型的地方可以传入 &Vec<T> 类型,Vec 对象也可以调用 slice [T] 的方法;
- &vec 返回 &Vec<i32> 类型,而 &vec[n..m] 返回 &[i32];
- array [T; N] 可以被 type coercing 到 [T], 所以 &[T; N] 可以被隐式转换为 &[T],这样 array 对象也可以调用 slice [T] 的方法;
// slicing a Vec
let vec = vec![1, 2, 3];
let int_slice = &vec[..]; // &vec 返回的是 &Vec<i32> 类型而非 &[i32]
let int_slice: &[i32] = &vec; // 由于 Vec[T] 实现了 Deref<Target=[T]>,所以 &Vec<i32> 可以被转换为 &[i32] 类型
// coercing an array to a slice
let str_slice: &[&str] = &["one", "two", "three"];
let mut x = [1, 2, 3];
let x = &mut x[..]; // Take a full slice of `x`.
x[1] = 7;
assert_eq!(x, &[1, 7, 3]);
// 由于数组 [i32; 3] 可以被 coerce 到 unsize 的 [T], 所以 &[i32; 3] 可以被赋值给 &[i32]
let numbers: &[i32] = &[0, 1, 2];
print_type_of(&numbers); // &[i32],数组引用类型可以被自动转换为切片引用类型
for n in numbers {
print_type_of(&n); // &i32,迭代切片引用,返回元素的引用
}
print_type_of(&numbers[0]); // i32,切片引用的支持 index 操作,返回元素本身
fn read_slice(slice: &[usize]) {
// ...
}
let v = vec![0, 1];
read_slice(&v); // Deref 自动转换
let u: &[usize] = &v; // Deref 自动转换
// or like this:
let u: &[_] = &v;
// 其他例子
#![allow(unused)]
fn print_type_of<T>(_: &T) {
println!("{}", std::any::type_name::<T>())
}
fn main() {
let x = [1_u32, 2, 3]; // [u32;3],数组类型
let x2 = &x; // &[u32; 3] ,数组引用类型
let x3 = &x[..]; // &[u32],切片引用类型
let x4 = &x[1..]; // &[u32],切片引用类型
let y = vec![1_u32, 2, 3]; // Vec<u32>,向量类型
let y2 = &y; // &Vec<u32>,向量引用
let y3 = &y[..]; // &[u32],切片引用
// u32,切片引用的支持 index 操作,返回元素本身
y3[1];
print_type_of(&y3[1]); // u32
let numbers = &[0, 1, 2];
print_type_of(&numbers); // &[i32; 3],数组引用类型
let numbers: &[i32] = &[0, 1, 2];
print_type_of(&numbers); // &[i32],数组引用类型可以被自动转换为切片引用类型
for n in numbers {
print_type_of(&n); // &i32,迭代切片引用,返回元素的引用
}
print_type_of(&numbers[0]); // i32,切片引用的支持 index 操作,返回元素本身
}
slice.to_vec() 方法将 slice 内容 clone 到一个新的 Vec 中.
s[i] 返回的 s 的元素值,而非它的引用,所以支持将 x[i] 作为左值:
let mut x = [1, 2, 3];
let x = &mut x[..]; // Take a full slice of `x`.
x[1] = 7; // x[1] 的类型是 mut i32, 所以可以进行修改.
for-in 迭代 &[T] 时返回 &T 元素:
let numbers: &[i32] = &[0, 1, 2]; // &[0, 1, 2] 的类型是 &[i32; 3] 被 rust 自动转换为 &[i32]
for n in numbers { // n 是 &i32 类型
println!("{n} is a number!");
}
let mut scores: &mut [i32] = &mut [7, 8, 9];
for score in scores { // score 是 &mut i32 类型.
*score += 1;
}
对 array/slice 进行 index 操作时,如果超过了 length,则会 panic。解决办法是使用安全的 .get() 方法,它返回一个 Option,get() 方法的参数是 SliceIndex<[T]>,Range<usize>/RangeFull/RangeFrom<usize> 等均实现了该 trait:
// Arrays can be safely accessed using `.get`, which returns an `Option`. This can be matched as
// shown below, or used with `.expect()` if you would like the program to exit with a nice message
// instead of happily continue.
for i in 0..xs.len() + 1 { // Oops, one element too far!
match xs.get(i) {
Some(xval) => println!("{}: {}", i, xval),
None => println!("Slow down! {} is too far!", i),
}
}
let v = [10, 40, 30];
assert_eq!(Some(&40), v.get(1));
assert_eq!(Some(&[10, 40][..]), v.get(0..2));
assert_eq!(None, v.get(3));
assert_eq!(None, v.get(0..4));
数组 slice 的 flatten:
impl<T, const N: usize> [[T; N]]
pub const fn flatten(&self) -> &[T]
#![feature(slice_flatten)]
assert_eq!([[1, 2, 3], [4, 5, 6]].flatten(), &[1, 2, 3, 4, 5, 6]);
assert_eq!(
[[1, 2, 3], [4, 5, 6]].flatten(),
[[1, 2], [3, 4], [5, 6]].flatten(),
);
let slice_of_empty_arrays: &[[i32; 0]] = &[[], [], [], [], []];
assert!(slice_of_empty_arrays.flatten().is_empty());
let empty_slice_of_arrays: &[[u32; 10]] = &[];
assert!(empty_slice_of_arrays.flatten().is_empty());
slice [T] 方法:由于 array/Vec 可以被 type coerse 到 [T], 所以 array/Vec 也可以调用 slice 的方法。
- 不能直接迭代 slice, 而是调用它的 iter() 或 iter_mut() 方法返回的迭代器;
impl<T> [T]
// 返回元素数量
pub const fn len(&self) -> usize
pub const fn is_empty(&self) -> bool
// slice 有可能为空,所以 first/last 都返回 Option
pub const fn first(&self) -> Option<&T>
pub fn first_mut(&mut self) -> Option<&mut T>
pub const fn last(&self) -> Option<&T>
pub fn last_mut(&mut self) -> Option<&mut T>
// 拆分 slice
pub const fn split_first(&self) -> Option<(&T, &[T])>
pub fn split_first_mut(&mut self) -> Option<(&mut T, &mut [T])>
pub const fn split_last(&self) -> Option<(&T, &[T])>
pub fn split_last_mut(&mut self) -> Option<(&mut T, &mut [T])>
// x 是 &[i32; 3] 类型,但是可以被 type coerce 到 &[i32] 类型,所以可以调用 slice [T] 的方法。
let x = &[0, 1, 2];
if let Some((first, elements)) = x.split_first() {
assert_eq!(first, &0);
assert_eq!(elements, &[1, 2]);
}
// 返回第一个 N 个元素的数组,如果元素少于 N 则返回 None
//
// 由于数组长度必须是编译时常量,所以 N 是通过常量泛型参数传入的。
pub const fn first_chunk<const N: usize>(&self) -> Option<&[T; N]>
pub fn first_chunk_mut<const N: usize>(&mut self) -> Option<&mut [T; N]>
pub fn last_chunk<const N: usize>(&self) -> Option<&[T; N]>
pub fn last_chunk_mut<const N: usize>(&mut self) -> Option<&mut [T; N]>
let u = [10, 40, 30];
assert_eq!(Some(&[10, 40]), u.first_chunk::<2>()); // 2 是泛型常量,使用类似于泛型函数的比目鱼语法
let v: &[i32] = &[10];
assert_eq!(None, v.first_chunk::<2>());
let w: &[i32] = &[];
assert_eq!(Some(&[]), w.first_chunk::<0>());
// 返回第一个或最后一个 chunk 数组和剩下的 slice,如果元素少于 N 则返回 None
pub const fn split_first_chunk<const N: usize>(&self) -> Option<(&[T; N], &[T])>
pub fn split_first_chunk_mut<const N: usize>( &mut self ) -> Option<(&mut [T; N], &mut [T])>
pub const fn split_last_chunk<const N: usize>(&self) -> Option<(&[T], &[T; N])>
pub fn split_last_chunk_mut<const N: usize>( &mut self ) -> Option<(&mut [T], &mut [T; N])>
let x = &[0, 1, 2];
if let Some((first, elements)) = x.split_first_chunk::<2>() {
assert_eq!(first, &[0, 1]);
assert_eq!(elements, &[2]);
}
assert_eq!(None, x.split_first_chunk::<4>());
// 安全的返回 slice 中元素(s[index] 当 index 不在范围时会 panic )
pub fn get<I>(&self, index: I) -> Option<&<I as SliceIndex<[T]>>::Output> where I: SliceIndex<[T]>
pub fn get_mut<I>( &mut self, index: I ) -> Option<&mut <I as SliceIndex<[T]>>::Output> where I: SliceIndex<[T]>
pub unsafe fn get_unchecked<I>( &self, index: I ) -> &<I as SliceIndex<[T]>>::Output where I: SliceIndex<[T]>
pub unsafe fn get_unchecked_mut<I>( &mut self, index: I ) -> &mut <I as SliceIndex<[T]>>::Output where I: SliceIndex<[T]>
let v = [10, 40, 30];
assert_eq!(Some(&40), v.get(1));
assert_eq!(Some(&[10, 40][..]), v.get(0..2));
assert_eq!(None, v.get(3));
assert_eq!(None, v.get(0..4));
// 创建裸指针
pub const fn as_ptr(&self) -> *const T
pub const fn as_mut_ptr(&mut self) -> *mut T
let x = &[1, 2, 4];
let x_ptr = x.as_ptr();
unsafe {
for i in 0..x.len() {
assert_eq!(x.get_unchecked(i), &*x_ptr.add(i));
}
}
let x = &mut [1, 2, 4];
let x_ptr = x.as_mut_ptr();
unsafe {
for i in 0..x.len() {
*x_ptr.add(i) += 2;
}
}
assert_eq!(x, &[3, 4, 6]);
// 返回包含所有元素的原始指针的区间(因为 slice 内存空间连续)
pub const fn as_ptr_range(&self) -> Range<*const T>
pub const fn as_mut_ptr_range(&mut self) -> Range<*mut T>
let a = [1, 2, 3];
let x = &a[1] as *const _;
let y = &5 as *const _;
assert!(a.as_ptr_range().contains(&x));
assert!(!a.as_ptr_range().contains(&y));
// 交换两个位置的值
pub fn swap(&mut self, a: usize, b: usize)
pub unsafe fn swap_unchecked(&mut self, a: usize, b: usize)
let mut v = ["a", "b", "c", "d", "e"];
v.swap(2, 4);
assert!(v == ["a", "b", "e", "d", "c"]);
// 反转 slice 元素
pub fn reverse(&mut self)
// 返回可迭代对象
pub fn iter(&self) -> Iter<'_, T>
pub fn iter_mut(&mut self) -> IterMut<'_, T>
// 可重叠,如果元素数量比窗口小,则返回 None
pub fn windows(&self, size: usize) -> Windows<'_, T>
let slice = ['l', 'o', 'r', 'e', 'm'];
let mut iter = slice.windows(3);
assert_eq!(iter.next().unwrap(), &['l', 'o', 'r']);
assert_eq!(iter.next().unwrap(), &['o', 'r', 'e']);
assert_eq!(iter.next().unwrap(), &['r', 'e', 'm']);
assert!(iter.next().is_none());
let slice = ['f', 'o', 'o'];
let mut iter = slice.windows(4);
assert!(iter.next().is_none());
// 不重叠的分组迭代,每次迭代返回一个切片 &[T]
pub fn chunks(&self, chunk_size: usize) -> Chunks<'_, T>
pub fn chunks_mut(&mut self, chunk_size: usize) -> ChunksMut<'_, T>
pub fn chunks_exact(&self, chunk_size: usize) -> ChunksExact<'_, T>
pub fn chunks_exact_mut(&mut self, chunk_size: usize) -> ChunksExactMut<'_, T>
pub const unsafe fn as_chunks_unchecked<const N: usize>(&self) -> &[[T; N]]
pub fn rchunks(&self, chunk_size: usize) -> RChunks<'_, T>
pub fn rchunks_mut(&mut self, chunk_size: usize) -> RChunksMut<'_, T>
pub fn rchunks_exact(&self, chunk_size: usize) -> RChunksExact<'_, T>
pub fn rchunks_exact_mut(&mut self, chunk_size: usize) -> RChunksExactMut<'_, T>
let slice = ['l', 'o', 'r', 'e', 'm'];
let mut iter = slice.chunks(2);
assert_eq!(iter.next().unwrap(), &['l', 'o']);
assert_eq!(iter.next().unwrap(), &['r', 'e']);
assert_eq!(iter.next().unwrap(), &['m']);
assert!(iter.next().is_none());
let slice = ['l', 'o', 'r', 'e', 'm'];
let mut iter = slice.chunks_exact(2);
assert_eq!(iter.next().unwrap(), &['l', 'o']);
assert_eq!(iter.next().unwrap(), &['r', 'e']);
// 如果最后一波元素少与数量,则返回 None,可以使用 remainer() 方法来获取它们
assert!(iter.next().is_none());
assert_eq!(iter.remainder(), &['m']);
// 分为 N 个元素数组的 slice 和最后剩下的元素 slice
pub const fn as_chunks<const N: usize>(&self) -> (&[[T; N]], &[T])
pub const fn as_rchunks<const N: usize>(&self) -> (&[T], &[[T; N]])
pub const unsafe fn as_chunks_unchecked_mut<const N: usize>( &mut self ) -> &mut [[T; N]]
pub const fn as_chunks_mut<const N: usize>( &mut self ) -> (&mut [[T; N]], &mut [T])
pub const fn as_rchunks_mut<const N: usize>( &mut self) -> (&mut [T], &mut [[T; N]])
#![feature(slice_as_chunks)]
let slice = ['l', 'o', 'r', 'e', 'm'];
let (chunks, remainder) = slice.as_chunks();
assert_eq!(chunks, &[['l', 'o'], ['r', 'e']]);
assert_eq!(remainder, &['m']);
#![feature(slice_as_chunks)]
let slice = ['R', 'u', 's', 't'];
let (chunks, []) = slice.as_chunks::<2>() else { // 使用 let-else 来匹配剩下元素的列表
panic!("slice didn't have even length")
};
assert_eq!(chunks, &[['R', 'u'], ['s', 't']]);
// chunks_exact 的泛型常量版本,即数组的长度是通过泛型常量参数来指定的
pub fn array_chunks<const N: usize>(&self) -> ArrayChunks<'_, T, N>
pub fn array_chunks_mut<const N: usize>(&mut self) -> ArrayChunksMut<'_, T, N>
pub fn array_windows<const N: usize>(&self) -> ArrayWindows<'_, T, N>
#![feature(array_chunks)]
let slice = ['l', 'o', 'r', 'e', 'm'];
let mut iter = slice.array_chunks();
assert_eq!(iter.next().unwrap(), &['l', 'o']);
assert_eq!(iter.next().unwrap(), &['r', 'e']);
assert!(iter.next().is_none());
assert_eq!(iter.remainder(), &['m']);
//使用 pred 来分割 slice(不重合的分割),pred 返回 true 时对应连续的元素属于一个 slice
pub fn chunk_by<F>(&self, pred: F) -> ChunkBy<'_, T, F> where F: FnMut(&T, &T) -> bool
pub fn chunk_by_mut<F>(&mut self, pred: F) -> ChunkByMut<'_, T, F> where F: FnMut(&T, &T) -> pub
let slice = &[1, 1, 1, 3, 3, 2, 2, 2];
let mut iter = slice.chunk_by(|a, b| a == b);
assert_eq!(iter.next(), Some(&[1, 1, 1][..]));
assert_eq!(iter.next(), Some(&[3, 3][..]));
assert_eq!(iter.next(), Some(&[2, 2, 2][..]));
assert_eq!(iter.next(), None);
// 在指定的 index 位置拆分 slice
bool const fn split_at(&self, mid: usize) -> (&[T], &[T])
pub fn split_at_mut(&mut self, mid: usize) -> (&mut [T], &mut [T])
pub const unsafe fn split_at_unchecked(&self, mid: usize) -> (&[T], &[T])
pub unsafe fn split_at_mut_unchecked( &mut self, mid: usize ) -> (&mut [T], &mut [T])
pub fn split_at_checked(&self, mid: usize) -> Option<(&[T], &[T])>
pub fn split_at_mut_checked( &mut self, mid: usize ) -> Option<(&mut [T], &mut [T])>
let v = [1, 2, 3, 4, 5, 6];
{
let (left, right) = v.split_at(0);
assert_eq!(left, []);
assert_eq!(right, [1, 2, 3, 4, 5, 6]);
}
{
let (left, right) = v.split_at(2);
assert_eq!(left, [1, 2]);
assert_eq!(right, [3, 4, 5, 6]);
}
{
let (left, right) = v.split_at(6);
assert_eq!(left, [1, 2, 3, 4, 5, 6]);
assert_eq!(right, []);
}
// 使用指定的 pred 分割 slice,可能会导致空 slice
pub fn split<F>(&self, pred: F) -> Split<'_, T, F> where F: FnMut(&T) -> bool
pub fn split_mut<F>(&mut self, pred: F) -> SplitMut<'_, T, F> where F: FnMut(&T) -> bool
pub fn split_inclusive<F>(&self, pred: F) -> SplitInclusive<'_, T, F> where F: FnMut(&T) -> bool
pub fn split_inclusive_mut<F>(&mut self, pred: F) -> SplitInclusiveMut<'_, T, F> where F: FnMut(&T) -> bool
pub fn rsplit<F>(&self, pred: F) -> RSplit<'_, T, F> where F: FnMut(&T) -> bool
pub fn rsplit_mut<F>(&mut self, pred: F) -> RSplitMut<'_, T, F> where F: FnMut(&T) -> bool
pub fn splitn<F>(&self, n: usize, pred: F) -> SplitN<'_, T, F> where F: FnMut(&T) -> bool
pub fn splitn_mut<F>(&mut self, n: usize, pred: F) -> SplitNMut<'_, T, F> where F: FnMut(&T) -> bool
pub fn rsplitn<F>(&self, n: usize, pred: F) -> RSplitN<'_, T, F> where F: FnMut(&T) -> bool
pub fn rsplitn_mut<F>(&mut self, n: usize, pred: F) -> RSplitNMut<'_, T, F> where F: FnMut(&T) -> bool
pub fn split_once<F>(&self, pred: F) -> Option<(&[T], &[T])> where F: FnMut(&T) -> bool
pub fn rsplit_once<F>(&self, pred: F) -> Option<(&[T], &[T])> where F: FnMut(&T) -> bool
let slice = [10, 6, 33, 20];
let mut iter = slice.split(|num| num % 3 == 0);
assert_eq!(iter.next().unwrap(), &[10]);
assert_eq!(iter.next().unwrap(), &[]);
assert_eq!(iter.next().unwrap(), &[20]);
assert!(iter.next().is_none());
let slice = [10, 40, 33];
let mut iter = slice.split(|num| num % 3 == 0);
assert_eq!(iter.next().unwrap(), &[10, 40]);
assert_eq!(iter.next().unwrap(), &[]); // 结尾空 slice
assert!(iter.next().is_none());
let slice = [10, 40, 33, 20];
let mut iter = slice.split_inclusive(|num| num % 3 == 0);
assert_eq!(iter.next().unwrap(), &[10, 40, 33]);
assert_eq!(iter.next().unwrap(), &[20]);
assert!(iter.next().is_none());
let v = [10, 40, 30, 20, 60, 50];
for group in v.splitn(2, |num| *num % 3 == 0) {
println!("{group:?}");
}
#![feature(slice_split_once)]
let s = [1, 2, 3, 2, 4];
assert_eq!(s.split_once(|&x| x == 2), Some((
&[1][..],
&[3, 2, 4][..]
)));
assert_eq!(s.split_once(|&x| x == 0), None);
// 是否包含引用值
pub fn contains(&self, x: &T) -> bool where T: PartialEq
let v = [10, 40, 30];
assert!(v.contains(&30));
assert!(!v.contains(&50));
// 是否以指定 slice 开始或结尾
pub fn starts_with(&self, needle: &[T]) -> bool where T: PartialEq
pub fn ends_with(&self, needle: &[T]) -> bool where T: PartialEq
let v = [10, 40, 30];
assert!(v.starts_with(&[10]));
assert!(v.starts_with(&[10, 40]));
assert!(!v.starts_with(&[50]));
assert!(!v.starts_with(&[10, 50]));
// 删除开始或结尾的 slice
pub fn strip_prefix<P>(&self, prefix: &P) -> Option<&[T]> where P: SlicePattern<Item = T> + ?Sized, T: PartialEq
pub fn strip_suffix<P>(&self, suffix: &P) -> Option<&[T]> where P: SlicePattern<Item = T> + ?Sized, T: PartialEq
let v = &[10, 40, 30];
assert_eq!(v.strip_prefix(&[10]), Some(&[40, 30][..]));
assert_eq!(v.strip_prefix(&[10, 40]), Some(&[30][..]));
assert_eq!(v.strip_prefix(&[50]), None);
assert_eq!(v.strip_prefix(&[10, 50]), None);
let prefix : &str = "he";
assert_eq!(b"hello".strip_prefix(prefix.as_bytes()), Some(b"llo".as_ref()));
pub fn binary_search(&self, x: &T) -> Result<usize, usize> where T: Ord
pub fn binary_search_by<'a, F>(&'a self, f: F) -> Result<usize, usize> where F: FnMut(&'a T) -> Ordering
pub fn binary_search_by_key<'a, B, F>(&'a self, b: &B,f:F) -> Result<usize, usize> where F: FnMut(&'a T) -> B,B: Ord
// 对 slice 进行排序,unstable 表示不保证重复元素的顺序
pub fn sort_unstable(&mut self) where T: Ord
pub fn sort_unstable_by<F>(&mut self, compare: F) where F: FnMut(&T, &T) -> Ordering
pub fn sort_unstable_by_key<K, F>(&mut self, f: F) where F: FnMut(&T) -> K, K: Ord
pub fn select_nth_unstable( &mut self, index: usize) -> (&mut [T], &mut T, &mut [T]) where T: Ord
pub fn select_nth_unstable_by<F>( &mut self, index: usize, compare: F) -> (&mut [T], &mut T, &mut [T]) where F: FnMut(&T, &T) -> Ordering
pub fn select_nth_unstable_by_key<K, F>( &mut self, index: usize, f: F ) -> (&mut [T], &mut T, &mut [T]) where F: FnMut(&T) -> K, K: Ord
let mut v = [-5, 4, 1, -3, 2];
v.sort_unstable();
assert!(v == [-5, -3, 1, 2, 4]);
// 返回两个 slice,分别是没有重复的元素,重复的元素(没有顺序)
pub fn partition_dedup(&mut self) -> (&mut [T], &mut [T]) where T: PartialEq
pub fn partition_dedup_by<F>(&mut self, same_bucket: F) -> (&mut [T], &mut [T]) where F: FnMut(&mut T, &mut T) -> bool
pub fn partition_dedup_by_key<K, F>(&mut self, key: F) -> (&mut [T], &mut [T]) where F: FnMut(&mut T) -> K, K: PartialEq
#![feature(slice_partition_dedup)]
let mut slice = [1, 2, 2, 3, 3, 2, 1, 1];
let (dedup, duplicates) = slice.partition_dedup();
assert_eq!(dedup, [1, 2, 3, 2, 1]);
assert_eq!(duplicates, [2, 3, 1]);
// 向左轮转两个元素
pub fn rotate_left(&mut self, mid: usize)
pub fn rotate_right(&mut self, k: usize)
let mut a = ['a', 'b', 'c', 'd', 'e', 'f'];
a.rotate_left(2);
assert_eq!(a, ['c', 'd', 'e', 'f', 'a', 'b']);
// 使用指定值填充整个 slice
pub fn fill(&mut self, value: T) where T: Clone
// 使用指定函数返回值填充整个 slice
pub fn fill_with<F>(&mut self, f: F) where F: FnMut() -> T
let mut buf = vec![0; 10];
buf.fill(1);
assert_eq!(buf, vec![1; 10]);
// 从 src clone 元素到 self,src 和 self 的长度必须一致,否则 panic
pub fn clone_from_slice(&mut self, src: &[T]) where T: Clone
pub fn copy_from_slice(&mut self, src: &[T]) where T: Copy
let src = [1, 2, 3, 4];
let mut dst = [0, 0];
// Because the slices have to be the same length, we slice the source slice from four elements to
// two. It will panic if we don't do this.
dst.clone_from_slice(&src[2..]);
assert_eq!(src, [1, 2, 3, 4]);
assert_eq!(dst, [3, 4]);
// 使用 memmove 将 src 的范围元素移动到 dest 开始的位置,两者可以有重复
pub fn copy_within<R>(&mut self, src: R, dest: usize) where R: RangeBounds<usize>, T: Copy
let mut bytes = *b"Hello, World!";
bytes.copy_within(1..5, 8);
assert_eq!(&bytes, b"Hello, Wello!");
// 交换内容,两个 slice 的长度必须一致
pub fn swap_with_slice(&mut self, other: &mut [T])
let mut slice1 = [0, 0];
let mut slice2 = [1, 2, 3, 4];
slice1.swap_with_slice(&mut slice2[2..]);
assert_eq!(slice1, [3, 4]);
assert_eq!(slice2, [1, 2, 0, 0]);
pub unsafe fn align_to<U>(&self) -> (&[T], &[U], &[T])
pub unsafe fn align_to_mut<U>(&mut self) -> (&mut [T], &mut [U], &mut [T])
pub fn as_simd<const LANES: usize>(&self) -> (&[T], &[Simd<T, LANES>], &[T]) where Simd<T, LANES>: AsRef<[T; LANES]>, T: SimdElement, LaneCount<LANES>: SupportedLaneCount
pub fn as_simd_mut<const LANES: usize>( &mut self ) -> (&mut [T], &mut [Simd<T, LANES>], &mut [T]) where Simd<T, LANES>: AsMut<[T; LANES]>, T: SimdElement, LaneCount<LANES>: SupportedLaneCount
pub fn is_sorted(&self) -> bool where T: PartialOrd
pub fn is_sorted_by<'a, F>(&'a self, compare: F) -> bool where F: FnMut(&'a T, &'a T) -> bool
pub fn is_sorted_by_key<'a, F, K>(&'a self, f: F) -> bool where F: FnMut(&'a T) -> K, K: PartialOrd
// 返回 pred 返回 true 的 index
pub fn partition_point<P>(&self, pred: P) -> usize where P: FnMut(&T) -> bool
let v = [1, 2, 3, 3, 5, 6, 7];
let i = v.partition_point(|&x| x < 5);
assert_eq!(i, 4);
assert!(v[..i].iter().all(|&x| x < 5));
assert!(v[i..].iter().all(|&x| !(x < 5)));
let a = [2, 4, 8];
assert_eq!(a.partition_point(|x| x < &100), a.len());
let a: [i32; 0] = [];
assert_eq!(a.partition_point(|x| x < &100), 0);
// 从 self 拿出 range 元素并返回,self 是剩下的元素
pub fn take<R, 'a>(self: &mut &'a [T], range: R) -> Option<&'a [T]> where R: OneSidedRange<usize>
pub fn take_mut<R, 'a>(self: &mut &'a mut [T], range: R) -> Option<&'a mut [T]> where R: OneSidedRange<usize>
pub fn take_first<'a>(self: &mut &'a [T]) -> Option<&'a T>
pub fn take_first_mut<'a>(self: &mut &'a mut [T]) -> Option<&'a mut T>
pub fn take_last<'a>(self: &mut &'a [T]) -> Option<&'a T>
pub fn take_last_mut<'a>(self: &mut &'a mut [T]) -> Option<&'a mut T>
#![feature(slice_take)]
let mut slice: &[_] = &['a', 'b', 'c', 'd'];
let mut first_three = slice.take(..3).unwrap();
assert_eq!(slice, &['d']);
assert_eq!(first_three, &['a', 'b', 'c']);
#![feature(slice_take)]
let mut slice: &[_] = &['a', 'b', 'c', 'd'];
let mut tail = slice.take(2..).unwrap();
assert_eq!(slice, &['a', 'b']);
assert_eq!(tail, &['c', 'd']);
#![feature(slice_take)]
let mut slice: &[_] = &['a', 'b', 'c'];
let first = slice.take_first().unwrap();
assert_eq!(slice, &['b', 'c']);
assert_eq!(first, &'a');
pub unsafe fn get_many_unchecked_mut<const N: usize>( &mut self, indices: [usize; N] ) -> [&mut T; N]
pub fn get_many_mut<const N: usize>( &mut self, indices: [usize; N] ) -> Result<[&mut T; N], GetManyMutError<N>>
#![feature(get_many_mut)]
let v = &mut [1, 2, 3];
if let Ok([a, b]) = v.get_many_mut([0, 2]) {
*a = 413;
*b = 612;
}
assert_eq!(v, &[413, 2, 612]);
// 其它 [T] 方法
impl<T> [T]
pub fn sort(&mut self) where T: Ord
let mut v = [-5, 4, 1, -3, 2];
v.sort();
assert!(v == [-5, -3, 1, 2, 4]);
pub fn sort_by<F>(&mut self, compare: F) where F: FnMut(&T, &T) -> Ordering
pub fn sort_by_key<K, F>(&mut self, f: F) where F: FnMut(&T) -> K, K: Ord
pub fn sort_by_cached_key<K, F>(&mut self, f: F) where F: FnMut(&T) -> K, K: Ord
let mut v = [-5i32, 4, 1, -3, 2];
v.sort_by_key(|k| k.abs());
assert!(v == [1, 2, -3, 4, -5]);
// 从 slice 生成 Vec
pub fn to_vec(&self) -> Vec<T> where T: Clone
pub fn to_vec_in<A>(&self, alloc: A) -> Vec<T, A> where A: Allocator, T: Clone
let s = [10, 40, 30];
let x = s.to_vec();
// Here, `s` and `x` can be modified independently.
pub fn into_vec<A>(self: Box<[T], A>) -> Vec<T, A> where A: Allocator
let s: Box<[i32]> = Box::new([10, 40, 30]);
let x = s.into_vec();
// `s` cannot be used anymore because it has been converted into `x`.
assert_eq!(x, vec![10, 40, 30]);
pub fn repeat(&self, n: usize) -> Vec<T> where T: Copy
assert_eq!([1, 2].repeat(3), vec![1, 2, 1, 2, 1, 2]);
// 将 slice 打平为一个值 Self::Output
pub fn concat<Item>(&self) -> <[T] as Concat<Item>>::Output where [T]: Concat<Item>, Item: ?Sized
assert_eq!(["hello", "world"].concat(), "helloworld");
assert_eq!([[1, 2], [3, 4]].concat(), [1, 2, 3, 4]);
// 使用指定分隔符打平 slice
pub fn join<Separator>( &self, sep: Separator) -> <[T] as Join<Separator>>::Output where [T]: Join<Separator>
assert_eq!(["hello", "world"].join(" "), "hello world");
assert_eq!([[1, 2], [3, 4]].join(&0), [1, 2, 0, 3, 4]);
assert_eq!([[1, 2], [3, 4]].join(&[0, 0][..]), [1, 2, 0, 0, 3, 4]);
9 tuple #
tuple 是固定大小和可以保存不同数据类型的类型,用 (T1, T2, T3) 表示。 可以使用 pattern match 进行析构,这使得元组非常灵活和强大,非常适合于存储和传递一组异构数据。元组也可以作为函数的返回值, 或者将数据组织成单个复合类型。
fn main() {
let _t0: (u8,i16) = (0, -1);
let _t1: (u8, (i16, u32)) = (0, (-1, 1));
let t: (u8, u16, i64, &str, String) = (1u8, 2u16, 3i64, "hello", String::from(", world"));
println!("Success!");
}
// 函数接受一个元组作为参数,并返回一个元组
fn swap(tup: (i32, f64)) -> (f64, i32) {
// 返回一个新的元组,元素顺序与输入相反
(tup.1, tup.0)
}
let input_tup = (123, 4.56);
let output_tup = swap(input_tup);
// 创建一个嵌套的元组结构
let nested_tup = (1, (2, 3), 4);
// 访问嵌套元组中的元素
let (a, (b, c), d) = nested_tup;
// 创建一个零元素的元组,也称为单元类型。
let unit = ();
单个元素类型时,元素后需要加逗号,如 (T,) ,以免和函数参数混淆。多个元素时,最后一个元素后可选的加逗号。
空 tuple () 也称为 unit type, 只有唯一的空值 ()。
tuple 拥有其中的各元素对象, 和 struct 一样, 允许部分元素被 move 走, 但是后续不能再访问已经 move 的元素:
- array/Vec/slice 等集合不允许元素被 move 走,具体参考: 2
使用 index 访问各元素, 如 t.0, t.1 等.
析构 tuple: enum 类型是在枚举 variant 值外部而非内部类匹配 & 或 &mut 的, 对于 tuple 类型也是在 tuple 外部匹配 & 或 &mut 的:
let x: &Option<i32> = &Some(3);
// OK: 等效为 Some(ref y), y 的类型是 &i32
if let Some(y) = x {}
// OK: 在 variant 外指定 &,y 的类型是 i32
if let &Some(y) = x {}
// ERROR: 不能在 variant 内指定 &,expected `i32`, found `&_`
if let Some(&y) = x {}
let (a, b ) = &(1, 2); // a 和 b 都是 &i32 类型
println!("Results: {a} {b}");
let &(c, d ) = &(1, 2); // c 和 d 都是 i32 类型
println!("Results: {c} {d}");
let (&c, d ) = &(1, 2); // 错误
let (ref c, d ) = &(1, 2); // OK
// 另一个例子
enum MyEnum {
A { name: String, x: u8 },
B { name: String },
}
fn a_to_b(e: &mut MyEnum) {
if let MyEnum::A {
name, // name 和 x 都是析构后的变量名,可以在后面的 block 中使用。name 是 &mut String 类型。
x: 0,
} = e {
*e = MyEnum::B {
name: std::mem::take(name), // take 参数类型是 &mut T, 而 name 类型是 &mut String 故满足
}
}
// if let &mut MyEnum::A {
// name, // OK: name 是 String 类型
// x: 0,
// } = e
}
过长的 tuple 不能被格式化输出:
fn main() {
let too_long_tuple = (1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12); // 最多 12 个元素才能被格式化
println!("too long tuple: {:?}", too_long_tuple);
}
array 可以转换为相同长度的 tuple:
let array: [u32; 3] = [1, 2, 3];
let tuple: (u32, u32, u32) = array.into();
10 pointer #
Rust 提供如下几种指针类型:
- 引用(Reference): &T 和 &mut T
- 裸指针(Raw Pointer): *const T 和 *mut T,需要在 unsafe 中解引用;
- 智能指针(Smart Pointer): 如 Box<T>, Rc<T>, Arc<T> 和 RefCell<T> 等。
fn main() {
let x = 5;
let y = &x; // 不可变引用
let mut z = 10;
let w = &mut z; // 可变引用,借用的值必须是 mut 类型
*w += 1; // 解引用来修改值
println!("x: {}, y: {}, z: {}, w: {}", x, y, z, w);
}
裸指针(Raw Pointer)可以是不可变 (*const T) 或可变 (*mut T),它们与 C 语言中的指针相似,但它们的使用不受安全检查,使用裸指针时需要 unsafe 代码块。
fn main() {
let mut x = 10;
let ptr_x = &mut x as *mut i32; // 将借用转换为可变裸指针
unsafe {
// 在 unsafe 代码块中使用裸指针
*ptr_x += 10;
println!("x: {}", *ptr_x);
}
}
智能指针是实现了 Deref 和 Drop trait 的类型,用于额外的元数据和功能。Box 是最简单的智能指针,用来分配堆上的值。
fn main() {
let b = Box::new(5); // 在堆上分配一个i32值
println!("b: {}", b);
let rc = Rc::new(5); // 创建一个引用计数指针
let rc_clone = rc.clone(); // 增加引用计数
println!("rc: {}, rc_clone: {}", rc, rc_clone);
}
指针内存布局:
- 普通引用和裸指针:占用一个机器字,一般是 isize 大小;
- 切片引用 &[T], 字符串引用 &str:占用两个机器字,分别保存内存区域指针+元素数量;
- Box<T>: 占用一个机器字,保存内存区域指针;
- Box<dyn Trait> 或 &dyn Trait: 占用两个机器字,保存实际对象的内存指针,以及该对象实现的各种方法的 vtable 指针;
Rust 的 type coercion 为引用和 raw pointer 提供了隐式自动转换(也可以使用 as 运算符来对 type coercion 显式转换): https://doc.rust-lang.org/stable/reference/type-coercions.html
- &mut T to &T <- 可变引用可以转换为不可变引用
- *mut T to *const T <– 可变 raw pointer 可以转换为不可变 raw pointer
- &T to *const T <– 不可变引用 可以转换为 不可变 raw pointer
- &mut T to *mut T <– 可变引用 可以转换为 可变 raw pointer
// 以下是编译器支持的 type coercion, 适用于同种类型 T 的指针转换
// [T; n] 可以 unsize type coerce 到 [T]
let arry = [1, 2, 3];
let usz: &[i32] = &arry;
// &mut T -> &T
let r: &i32 = &mut 1i32;
// &T -> *const T
let rp: *const i32 = &1i32;
// &mut T -> *const T 或 *mut T
let r: *const i32 = &mut 1i32;
let r: *mut i32 = &mut 1i32;
// *mut T -> *const T
// 可以使用 as 运算符, 对支持 type coercion 的变量类型进行转换.
let rp: *const i32 = &mut 1i32 as *mut i32 as *const i32;
// 以下是 CoerceUnsized trait 实现的 type coercion 的转换, 将 T 指针转换为 U 指针, U 需要是 unsized type.
// &T -> &U
let u: &dyn std::fmt::Display = &123i32;
// &mut T -> &U
let u: &dyn std::fmt::Display = &mut 123i32;
// &mut T -> &mut U
let u: &mut dyn std::fmt::Display = &mut 123i32;
// &T -> *const U
let u: *const dyn std::fmt::Display = &123i32;
// &mut T -> *const U
let u: *const dyn std::fmt::Display = &mut 123i32;
// &mut T -> *mut U
let u: *mut dyn std::fmt::Display = &mut 123i32;
// Box<T> -> Box<U>
let b1 = Box::new(123i32); // i32 -> dyn std::fmt::Display
let b2: Box<dyn std::fmt::Display> = b1;
// Rc<T> -> Rc<U>
let r1 = Rc::new(123i32);
let r2: Rc<dyn std::fmt::Display> = r1;
11 struct #
struct/enum/union 是 Rust 的三种自定义类型。自定义类型名必须是 CamelCase,否则编译时警告。
struct 三种类型:
- unit struct,不含任何 field;
- tuple struct,只有一个元素 T 的 struct 称为 newtype;
- C-like struct;
#![allow(dead_code)]
#[derive(Debug)]
struct Person {
name: String,
age: u8,
}
struct Unit;
struct Pair(i32, f32);
struct Point {
x: f32,
y: f32,
}
// 实例化
let _unit = Unit; // 对于 unit struct,只有唯一的一个对象。
let pair = Pair(1, 0.1); // 初始化 tuple struct 时,类似于函数调用。
let Pair(integer, decimal) = pair; // 解构 struct,注意前面的 Pair 不能省。
初始化 struct 对象时, 必须列出每一个 field,与 field 同名的变量赋值可以使用简写形式,可以使用某个 struct 对象展开来快速创建一个新的 struct 对象, 但它必须位于新 struct 初始化的最后一项且结尾不能有逗号。
fn main() {
struct Person {
name: String,
age: u8,
hobby: String,
}
let age = 30;
let p = Person { // Error:missing field `hobby` in initializer of `Person`
name: String::from("sunface"),
age, // 与 field 同名的变量赋值, 可以使用简写形式。
};
println!("Success!");
}
// 同名的 field 可以简写。
let name = String::from("Peter");
let age = 27;
let peter = Person { name, age };
// newtype idiom, 一般为其他类型添加方法
struct Years(i64);
struct Days(i64);
impl Years {
pub fn to_days(&self) -> Days {
Days(self.0 * 365)
}
}
impl Days {
/// truncates partial years
pub fn to_years(&self) -> Years {
Years(self.0 / 365)
}
}
fn old_enough(age: &Years) -> bool {
age.0 >= 18
}
fn main() {
let age = Years(5);
let age_days = age.to_days();
println!("Old enough {}", old_enough(&age));
println!("Old enough {}", old_enough(&age_days.to_years()));
// println!("Old enough {}", old_enough(&age_days));
}
// 使用 struct 对象初始化另一个 struct 对象。
#[derive(Debug)]
struct User {
active: bool,
username: String,
email: String,
sign_in_count: u64,
}
fn main() {
let u1 = User {
email: String::from("[email protected]"),
username: String::from("sunface"),
active: true,
sign_in_count: 1,
};
let u2 = set_email(u1);
println!("Success! {u2:?}");
}
fn set_email(u: User) -> User {
User {
email: String::from("[email protected]"),
..u // u 必须位于最后, 且结尾不能有逗号
}
}
// Make a new point by using struct update syntax to use the fields of our other one
let bottom_right = Point { x: 5.2, ..point };
无 field 的 struct MyStruct; 等效于 struct MyStruct {}; :
struct Cookie;
let c = [Cookie, Cookie {}, Cookie, Cookie {}];
// 等效于
struct Cookie {}
const Cookie: Cookie = Cookie {};
let c = [Cookie, Cookie {}, Cookie, Cookie {}];
struct 会 owner 对应的 field value, 所以 field 一般使用 owned 类型而非 &T/&mut T 类型(‘static 除外), 因为后者需要声明生命周期参数。struct 包含引用类型成员时需要明确指定 lifetime。嵌套带声明周期的struct 时,外层 struct 也必须声明生命周期:
- ‘a: ‘b 表示 ‘a 的 lifetime 至少要比 ‘b 长。
- T: ‘a 表示 T 的生命周期要比 ‘a 长.
struct S {
r: &i32 // r 是引用类型,但是没有指定 lifetime,编译失败。
}
let s;
{
let x = 10;
s = S { r: &x };
}
assert_eq!(*s.r, 10); // bad: reads from dropped `x`
// 正确
struct S {
r: &'static i32
}
// 正确
struct S<'a> {
r: &'a i32 // r 引用对象的声明周期至少要比 struct S 大。
}
// 正确,多个 lifetime 参数
struct S<'a, 'b> {
x: &'a i32,
y: &'b i32
}
// 函数
fn f<'a, 'b>(r: &'a i32, s: &'b i32) -> &'a i32 { r } // looser
// 错误
struct D {
s: S
}
// 正确
struct D<'a> {
s: S<'a>
}
struct 整体和各 field 需要单独设置 public (enum 是整体 public 即可), 没有设置 public 的 filed 默认是私有的, 其他 moudule 不能访问.
struct 默认没有实现 Copy/Clone 以及 Debug, 可以通过 derive 宏来让编译器自动生成.
- 不能通过 derive 属性来生成 Display trait, 需要手动实现该 trait.
struct 的各 field 可以被单独借用,在被 Destructure 时,如果 filed 没有实现 Copy,这可能会被 partial move, move 的 field 后续不能再访问:
- enum 也可以被 partial move;
- array/tuple/vec 元素不能被 partial move, 但可以整体或全部没 move 出来(如迭代)。
fn main() {
#[derive(Debug)]
struct Person {
name: String,
age: Box<u8>,
}
let person = Person {
name: String::from("Alice"),
age: Box::new(20),
};
// `name` is moved out of person, but `age` is referenced
let Person { name, ref age } = person; // struct 可以作为 pattern match 来进行解构
println!("The person's age is {}", age);
println!("The person's name is {}", name);
// Error! borrow of partially moved value: `person` partial move occurs
//println!("The person struct is {:?}", person);
// `person` cannot be used but `person.age` can be used as it is not moved
println!("The person's age from person struct is {}", person.age);
}
12 enum #
enum variant 和 struct 类似,有 3 种类型:
- enum Quit;
- enum Quit {x: y, xx:yy};
- enum Quit (i32, String);
enum Number {
Zero, // tag 默认在上一个基础上递增,第一个 tag 为 0。
One,
Two,
}
enum Number1 {
Zero = 0,
One,
Two,
}
// C-like enum
enum Number2 {
Zero = 0.0,
One = 1.0,
Two = 2.0,
}
// enum variant 可以包含数据。
enum Message {
Quit,
Move { x: i32, y: i32 },
Write(String),
ChangeColor(i32, i32, i32),
}
// 不允许多个 field 使用相同的 tag 值(但是 C 允许)。
enum SharedDiscriminantError2 {
Zero, // 0
One, // 1
OneToo = 1 // 1 (collision with previous!)
}
特殊的空 enum (无 variant)不能作为 value 使用, 主要的使用场景是作为不可能发生错误的 Result,如标准库类型 std::convert::Infallible:
// std::convert::Infallible
pub enum Infallible {}
impl<T, U> TryFrom<U> for T where U: Into<T> {
type Error = Infallible;
fn try_from(value: U) -> Result<Self, Infallible> {
Ok(U::into(value)) // Never returns `Err`
}
}
// 另一个例子
enum ZeroVariants {}
let x: ZeroVariants = panic!();
let y: u32 = x; // mismatched type error
enum variant 的数据可以用在 pattern match 中:
// Create an `enum` to classify a web event. Note how both names and type information together
// specify the variant: `PageLoad != PageUnload` and `KeyPress(char) != Paste(String)`. Each is
// different and independent.
enum WebEvent {
// An `enum` variant may either be `unit-like`,
PageLoad,
PageUnload,
// like tuple structs,
KeyPress(char),
Paste(String),
// or c-like structures.
Click { x: i64, y: i64 },
}
// A function which takes a `WebEvent` enum as an argument and returns nothing.
fn inspect(event: WebEvent) {
match event {
WebEvent::PageLoad => println!("page loaded"),
WebEvent::PageUnload => println!("page unloaded"),
// Destructure `c` from inside the `enum` variant.
WebEvent::KeyPress(c) => println!("pressed '{}'.", c),
WebEvent::Paste(s) => println!("pasted \"{}\".", s),
// Destructure `Click` into `x` and `y`.
WebEvent::Click { x, y } => {
println!("clicked at x={}, y={}.", x, y);
},
}
}
fn main() {
// 创建一个 enum variant 时需要指定对应的类型值(tuple、struct)
let pressed = WebEvent::KeyPress('x');
// `to_owned()` creates an owned `String` from a string slice.
let pasted = WebEvent::Paste("my text".to_owned());
let click = WebEvent::Click { x: 20, y: 80 };
let load = WebEvent::PageLoad;
let unload = WebEvent::PageUnload;
inspect(pressed);
inspect(pasted);
inspect(click);
inspect(load);
inspect(unload);
}
enum 的各 variant 都是 enum 类型, 所以可以用在 array 中:
enum Message {
Quit,
Move { x: i32, y: i32 },
Write(String),
ChangeColor(i32, i32, i32),
}
fn main() {
let msgs: [Message; 3] = [
Message::Quit,
Message::Move{x:1, y:3},
Message::ChangeColor(255,255,0)
];
for msg in msgs {
show_message(msg)
}
}
fn show_message(msg: Message) {
println!("{}", msg);
}
enum variant 可以包含 tag 表达式,使用 enum::variant as i32/u32 来获得 tag 值:
// An attribute to hide warnings for unused code.
#![allow(dead_code)]
// enum with implicit discriminator (starts at 0)
enum Number {
Zero, // 默认从 0 开始递增,未指定时在上一个基础上递增。
One,
Two,
}
// enum with explicit discriminator
enum Color {
Red = 0xff0000,
Green = 0x00ff00,
Blue // 上一基础上自动递增,所以为 0x00ff01
}
fn main() {
// `enums` can be cast as integers.
println!("zero is {}", Number::Zero as i32);
println!("one is {}", Number::One as i32);
println!("roses are #{:06x}", Color::Red as i32);
println!("violets are #{:06x}", Color::Blue as i32);
}
如果 enum 名称太长,可以用 type alias 来简化:
enum VeryVerboseEnumOfThingsToDoWithNumbers {
Add,
Subtract,
}
// Creates a type alias
type Operations = VeryVerboseEnumOfThingsToDoWithNumbers;
fn main() {
// We can refer to each variant via its alias, not its long and inconvenient name.
let x = Operations::Add; // 使用简化的 enum 类型别名来访问 variant
}
// 最常见的场景是方法中的 Self 类型其实也是 type alias
enum VeryVerboseEnumOfThingsToDoWithNumbers {
Add,
Subtract,
}
impl VeryVerboseEnumOfThingsToDoWithNumbers {
fn run(&self, x: i32, y: i32) -> i32 {
match self {
Self::Add => x + y,
Self::Subtract => x - y,
}
}
}
enum 的 variant 可以使用 use 按需或一次性导入,这样不需要每次指定 enum::variant 的 enum:: 部分:
#![allow(dead_code)]
enum Status {
Rich,
Poor,
}
enum Work {
Civilian,
Soldier,
}
fn main() {
// Explicitly `use` each name so they are available without manual scoping.
use crate::Status::{Poor, Rich};
// Automatically `use` each name inside `Work`.
use crate::Work::*;
// Equivalent to `Status::Poor`.
let status = Poor;
// Equivalent to `Work::Civilian`.
let work = Civilian;
match status {
// Note the lack of scoping because of the explicit `use` above.
Rich => println!("The rich have lots of money!"),
Poor => println!("The poor have no money..."),
}
match work {
// Note again the lack of scoping.
Civilian => println!("Civilians work!"),
Soldier => println!("Soldiers fight!"),
}
}
enum 只需为整体指定 pub 可见性即可,各 variant 的可见性继承自整体。(struct 需要为每个 field 指定可见性)。
析构 enum:对于 enum 类型是在枚举 variant 值外部而非内部类匹配 & 或 &mut 的:
let x: &Option<i32> = &Some(3);
// OK: 等效为 Some(ref y), y 的类型是 &i32
if let Some(y) = x {}
// OK: 在 variant 外指定 &,y 的类型是 i32
if let &Some(y) = x {}
// ERROR: 不能在 variant 内指定 &,expected `i32`, found `&_`
if let Some(&y) = x {}
let (a, b ) = &(1, 2); // a 和 b 都是 &i32 类型
println!("Results: {a} {b}");
let &(c, d ) = &(1, 2); // c 和 d 都是 i32 类型
println!("Results: {c} {d}");
let (&c, d ) = &(1, 2); // 报错
let (ref c, d ) = &(1, 2); // OK
// 另一个例子
enum MyEnum {
A { name: String, x: u8 },
B { name: String },
}
fn a_to_b(e: &mut MyEnum) {
if let MyEnum::A {
name, // name 和 x 都是析构后的变量名,可以在后面的 block 中使用。name 是 &mut String 类型。
x: 0,
} = e {
*e = MyEnum::B {
name: std::mem::take(name), // take 参数类型是 &mut T, 而 name 类型是 &mut String 故满足
}
}
// if let &mut MyEnum::A {
// name, // OK: name 是 String 类型
// x: 0,
// } = e
}
enum 的内存布局包括:tag 字段 和能容纳所有 variant 的内存,其中 tag 是 Rust 内部用来区分 variant 的。
13 panic/error/Option/Result #
panic 是最简单的异常处理机制,它打印 error message,然后开始 unwinding stack,最后退出当前 thread。 unwinding stack 过程中,Rust 会回溯调用栈,drop 所有的对象和资源。
- 如果是 main thread panic,则整个程序退出,否则,如果是子线程 panic,则终止该子线程,程序不退出。
- 使用
RUST_BACKTRACE=1 cargo run来打印 stack 详情;
fn drink(beverage: &str) {
// You shouldn't drink too much sugary beverages.
if beverage == "lemonade" { panic!("AAAaaaaa!!!!"); }
println!("Some refreshing {} is all I need.", beverage);
}
fn main() {
drink("water");
drink("lemonade");
drink("still water");
}
注意:如果 panic 是 FFI 调用的外部库函数导致的,则 Rust 不会进行 unwinding,而是直接 panic。
panic 时是 unwind(默认)还是 abort,可以配置:
- 在 .cargo/config.toml 的 profile 中配置为 abort:
- 通过 cargo build 或 rustc 的 -C panic=abort/unwind 参数来配置: rustc lemonade.rs -C panic=abort
[profile.dev]
opt-level = 0
debug = true
split-debuginfo = '...' # Platform-specific.
strip = "none"
debug-assertions = true
overflow-checks = true
lto = false
panic = 'unwind' # unwind 或 abort
incremental = true
codegen-units = 256
rpath = false
代码可以使用 #[cfg(panic = “xx”)] 来进行条件编译,或使用 cfg!() 来进行条件判断;
// 根据 panic 设置进行条件编译
#[cfg(panic = "unwind")]
fn ah() {
println!("Spit it out!!!!");
}
#[cfg(not(panic = "unwind"))]
fn ah() {
println!("This is not your party. Run!!!!");
}
fn drink(beverage: &str) {
if beverage == "lemonade" {
ah();
} else {
println!("Some refreshing {} is all I need.", beverage);
}
}
fn main() {
drink("water");
drink("lemonade");
}
fn drink(beverage: &str) {
// You shouldn't drink too much sugary beverages.
if beverage == "lemonade" {
if cfg!(panic = "abort") {
println!("This is not your party. Run!!!!");
} else {
println!("Spit it out!!!!");
}
} else {
println!("Some refreshing {} is all I need.", beverage);
}
}
fn main() {
drink("water");
drink("lemonade");
}
Option/Result 是 enum 类型,支持迭代(实现了 IntoIterator),效果就如一个或 0 个元素。可以使用 ? 来进行 unpacking,? 可以用于方法调用等表达式中间来使用。
fn next_birthday(current_age: Option<u8>) -> Option<String> {
// If `current_age` is `None`, this returns `None`. If `current_age` is `Some`, the inner `u8`
// value + 1 gets assigned to `next_age`
let next_age: u8 = current_age? + 1; // unpacing Some 值或提前返回 None
Some(format!("Next year I will be {}", next_age))
}
struct Person {
job: Option<Job>,
}
#[derive(Clone, Copy)]
struct Job {
phone_number: Option<PhoneNumber>,
}
#[derive(Clone, Copy)]
struct PhoneNumber {
area_code: Option<u8>,
number: u32,
}
impl Person {
// Gets the area code of the phone number of the person's job, if it exists.
fn work_phone_area_code(&self) -> Option<u8> {
// This would need many nested `match` statements without the `?` operator.
// It would take a lot more code - try writing it yourself and see which
// is easier.
self.job?.phone_number?.area_code
}
}
fn main() {
let p = Person {
job: Some(Job {
phone_number: Some(PhoneNumber {
area_code: Some(61),
number: 439222222,
}),
}),
};
assert_eq!(p.work_phone_area_code(), Some(61));
}
13.1 Option #
Option 的方法:
- XX_or(): 为 None 时使用传入的值;
- XX_or_else(): 为 None 时使用传入的闭包函数;
- XX_or_default() : 为 None 时使用对象的缺省值;
impl<T> Option<T>
// 下面两个方法不消耗 Option
pub const fn is_some(&self) -> bool
pub const fn is_none(&self) -> bool
pub fn is_some_and(self, f: impl FnOnce(T) -> bool) -> bool
let x: Option<u32> = Some(2);
assert_eq!(x.is_some_and(|x| x > 1), true);
let x: Option<u32> = Some(0);
assert_eq!(x.is_some_and(|x| x > 1), false);
// 从 &Option<T> 转换为 Option<&T>,这样后续处理时不转移 T 所有权
pub const fn as_ref(&self) -> Option<&T>
pub fn as_mut(&mut self) -> Option<&mut T>
let text: Option<String> = Some("Hello, world!".to_string());
let text_length: Option<usize> = text.as_ref().map(|s| s.len());
println!("still can print text: {text:?}");
let mut x = Some(2);
match x.as_mut() {
Some(v) => *v = 42,
None => {},
}
assert_eq!(x, Some(42));
pub fn as_pin_ref(self: Pin<&Option<T>>) -> Option<Pin<&T>>
pub fn as_pin_mut(self: Pin<&mut Option<T>>) -> Option<Pin<&mut T>>
// 返回一个 slice,包含对应的 Some 元素,如果为 None 则返回空 slice
pub fn as_slice(&self) -> &[T]
pub fn as_mut_slice(&mut self) -> &mut [T]
assert_eq!(
[Some(1234).as_slice(), None.as_slice()],
[&[1234][..], &[][..]],
);
// 返回 Some 值,如果是 None 则 panic 并打印 msg(不支持格式化)
pub fn expect(self, msg: &str) -> T
let x = Some("value");
assert_eq!(x.expect("fruits are healthy"), "value");
// 返回 Some 值,如果是 None 则 panic
pub fn unwrap(self) -> T
pub fn unwrap_or(self, default: T) -> T
pub fn unwrap_or_else<F>(self, f: F) -> T where F: FnOnce() -> T
pub fn unwrap_or_default(self) -> T where T: Default
pub unsafe fn unwrap_unchecked(self) -> T
// 将 Option<T> 转换为 Option<U>, 如果为 None 则返回 None
pub fn map<U, F>(self, f: F) -> Option<U> where F: FnOnce(T) -> U
let maybe_some_string = Some(String::from("Hello, World!"));
let maybe_some_len = maybe_some_string.map(|s| s.len());
assert_eq!(maybe_some_len, Some(13));
let x: Option<&str> = None;
assert_eq!(x.map(|s| s.len()), None);
pub fn inspect<F>(self, f: F) -> Option<T> where F: FnOnce(&T)
let v = vec![1, 2, 3, 4, 5];
let x: Option<&usize> = v.get(3).inspect(|x| println!("got: {x}")); // prints "got: 4"
let x: Option<&usize> = v.get(5).inspect(|x| println!("got: {x}")); // prints nothing
// 如果为 None 则返回 default 值, 否则对 Some 值执行 f 函数
pub fn map_or<U, F>(self, default: U, f: F) -> U where F: FnOnce(T) -> U
pub fn map_or_else<U, D, F>(self, default: D, f: F) -> U where D: FnOnce() -> U, F: FnOnce(T) -> U
let x = Some("foo");
assert_eq!(x.map_or(42, |v| v.len()), 3);
let x: Option<&str> = None;
assert_eq!(x.map_or(42, |v| v.len()), 42);
// 将 Option 转换为 Result: 将 Some(v) -> Ok(v), None -> Err(err)
pub fn ok_or<E>(self, err: E) -> Result<T, E>
pub fn ok_or_else<E, F>(self, err: F) -> Result<T, E> where F: FnOnce() -> E
let x = Some("foo");
assert_eq!(x.ok_or(0), Ok("foo"));
let x: Option<&str> = None;
assert_eq!(x.ok_or(0), Err(0));
pub fn as_deref(&self) -> Option<&<T as Deref>::Target> where T: Deref
pub fn as_deref_mut(&mut self) -> Option<&mut <T as Deref>::Target> where T: DerefMut
pub fn iter(&self) -> Iter<'_, T>
pub fn iter_mut(&mut self) -> IterMut<'_, T>
let x = Some(4);
assert_eq!(x.iter().next(), Some(&4));
let x: Option<u32> = None;
assert_eq!(x.iter().next(), None);
// 如果 self 是 None 则返回 None, 否则返回 optb
pub fn and<U>(self, optb: Option<U>) -> Option<U>
let x = Some(2);
let y: Option<&str> = None;
assert_eq!(x.and(y), None);
let x: Option<u32> = None;
let y = Some("foo");
assert_eq!(x.and(y), None);
let x = Some(2);
let y = Some("foo");
assert_eq!(x.and(y), Some("foo"));
let x: Option<u32> = None;
let y: Option<&str> = None;
assert_eq!(x.and(y), None);
// 如果 self 是 None 则返回 None, 否则返回 f 函数的结果
pub fn and_then<U, F>(self, f: F) -> Option<U> where F: FnOnce(T) -> Option<U>
fn sq_then_to_string(x: u32) -> Option<String> {
x.checked_mul(x).map(|sq| sq.to_string())
}
assert_eq!(Some(2).and_then(sq_then_to_string), Some(4.to_string()));
assert_eq!(Some(1_000_000).and_then(sq_then_to_string), None); // overflowed!
assert_eq!(None.and_then(sq_then_to_string), None);
// 如果 self 是 None 则返回 None, 否则如果 predicate 返回 true 则返回 Some 值;
pub fn filter<P>(self, predicate: P) -> Option<T> where P: FnOnce(&T) -> bool
fn is_even(n: &i32) -> bool { n % 2 == 0 }
assert_eq!(None.filter(is_even), None);
assert_eq!(Some(3).filter(is_even), None);
assert_eq!(Some(4).filter(is_even), Some(4));
pub fn or(self, optb: Option<T>) -> Option<T>
pub fn or_else<F>(self, f: F) -> Option<T> where F: FnOnce() -> Option<T>
pub fn xor(self, optb: Option<T>) -> Option<T>
let x = Some(2);
let y = None;
let x = None;
let y = Some(100);
assert_eq!(x.or(y), Some(100));
let x = Some(2);
let y = Some(100);
assert_eq!(x.or(y), Some(2));
let x: Option<u32> = None;
let y = None;
assert_eq!(x.or(y), None);
// 将 value 插入 Option 返回他的 &mut, Option 原来值被 dropped
pub fn insert(&mut self, value: T) -> &mut T
let mut opt = None;
let val = opt.insert(1);
assert_eq!(*val, 1);
assert_eq!(opt.unwrap(), 1);
let val = opt.insert(2);
assert_eq!(*val, 2);
*val = 3;
assert_eq!(opt.unwrap(), 3);
// 返回 Some 值的 &mut, 否则插入 value 值并返回他的 &mut
pub fn get_or_insert(&mut self, value: T) -> &mut T
pub fn get_or_insert_default(&mut self) -> &mut T where T: Default
pub fn get_or_insert_with<F>(&mut self, f: F) -> &mut T where F: FnOnce() -> T
let mut x = None;
{
let y: &mut u32 = x.get_or_insert(5);
assert_eq!(y, &5);
*y = 7;
}
assert_eq!(x, Some(7));
// 从 self 中获取 Some 值, 将 self 设为 None
pub fn take(&mut self) -> Option<T>
let mut x = Some(2);
let y = x.take();
assert_eq!(x, None);
assert_eq!(y, Some(2));
let mut x: Option<u32> = None;
let y = x.take();
assert_eq!(x, None);
assert_eq!(y, None);
// 当 predicate 返回 ture 时 take Some 的值,将 self 设置为 None
pub fn take_if<P>(&mut self, predicate: P) -> Option<T> where P: FnOnce(&mut T) -> bool
// 用 value 替换 self 值, 返回 self 以前的值
pub fn replace(&mut self, value: T) -> Option<T>
let mut x = Some(2);
let old = x.replace(5);
assert_eq!(x, Some(5));
assert_eq!(old, Some(2));
let mut x = None;
let old = x.replace(3);
assert_eq!(x, Some(3));
assert_eq!(old, None);
// 如果 self 是 Some(s) 且 other 也是 Some(o),则返回 Some((s, o)), 否则返回 None
pub fn zip_with<U, F, R>(self, other: Option<U>, f: F) -> Option<R> where F: FnOnce(T, U) -> R
pub fn zip<U>(self, other: Option<U>) -> Option<(T, U)>
let x = Some(1);
let y = Some("hi");
let z = None::<u8>;
assert_eq!(x.zip(y), Some((1, "hi")));
assert_eq!(x.zip(z), None);
// 从 Option<&T> 生成 Option<T>
impl<T> Option<&T>
pub fn copied(self) -> Option<T> where T: Copy
pub fn cloned(self) -> Option<T> where T: Clone
13.2 Result #
支持 map/and_then 等方法:
use std::num::ParseIntError;
// As with `Option`, we can use combinators such as `map()`. This function is otherwise identical
// to the one above and reads: Multiply if both values can be parsed from str, otherwise pass on the
// error.
fn multiply(first_number_str: &str, second_number_str: &str) -> Result<i32, ParseIntError> {
first_number_str.parse::<i32>().and_then(|first_number| {
second_number_str.parse::<i32>().map(|second_number| first_number * second_number)
})
}
fn print(result: Result<i32, ParseIntError>) {
match result {
Ok(n) => println!("n is {}", n),
Err(e) => println!("Error: {}", e),
}
}
fn main() {
// This still presents a reasonable answer.
let twenty = multiply("10", "2");
print(twenty);
// The following now provides a much more helpful error message.
let tt = multiply("t", "2");
print(tt);
}
在 match 表达式中可以提前返回 Err(e):
use std::num::ParseIntError;
fn multiply(first_number_str: &str, second_number_str: &str) -> Result<i32, ParseIntError> {
let first_number = match first_number_str.parse::<i32>() {
Ok(first_number) => first_number,
Err(e) => return Err(e),
};
let second_number = match second_number_str.parse::<i32>() {
Ok(second_number) => second_number,
Err(e) => return Err(e),
};
Ok(first_number * second_number)
}
fn print(result: Result<i32, ParseIntError>) {
match result {
Ok(n) => println!("n is {}", n),
Err(e) => println!("Error: {}", e),
}
}
fn main() {
print(multiply("10", "2"));
print(multiply("t", "2"));
}
Result 别名: 简化 Error 类型:
use std::fmt;
type Result<T> = std::result::Result<T, DoubleError>;
// Define our error types. These may be customized for our error handling cases.
// Now we will be able to write our own errors, defer to an underlying error
// implementation, or do something in between.
#[derive(Debug, Clone)]
struct DoubleError;
// Generation of an error is completely separate from how it is displayed.
// There's no need to be concerned about cluttering complex logic with the display style.
//
// Note that we don't store any extra info about the errors. This means we can't state
// which string failed to parse without modifying our types to carry that information.
impl fmt::Display for DoubleError {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
write!(f, "invalid first item to double")
}
}
fn double_first(vec: Vec<&str>) -> Result<i32> {
vec.first()
// Change the error to our new type.
.ok_or(DoubleError)
.and_then(|s| {
s.parse::<i32>()
// Update to the new error type here also.
.map_err(|_| DoubleError)
.map(|i| 2 * i)
})
}
fn print(result: Result<i32>) {
match result {
Ok(n) => println!("The first doubled is {}", n),
Err(e) => println!("Error: {}", e),
}
}
fn main() {
let numbers = vec!["42", "93", "18"];
let empty = vec![];
let strings = vec!["tofu", "93", "18"];
print(double_first(numbers));
print(double_first(empty));
print(double_first(strings));
}
如果一个表达式返回 Result, 则忽略返回值时编译器会警告, 可以赋值给 let _ = xxx 来消除警告.
13.3 Error #
Rust 标准库提供了 std::error::Error trait,标准库中绝大部分错误类型,如 std::io::Error, std::fmt::Error 类型都实现了该 trait。而且标准库为 std::error::Error 实现了到 Box<dyn Error + ‘a> 和 Box<dyn Error + Sync + Send + ‘a> 的 From trait 转换实现. 所以实现了 std::error:Error trait 的错误类型都可以使用 ? 转换到 Box<dyn Error + ‘a>和 Box<dyn Error + Sync + Send + ‘a> 类型:
impl<'a, E> From<E> for Box<dyn Error + 'a> where E: Error + 'a,
impl<'a, E> From<E> for Box<dyn Error + Sync + Send + 'a> where E: Error + Send + Sync + 'a,
最佳实践:函数返回的 Error 类型使用 Box<std::error::Error + Send + Sync + ‘static> :
- 加 Send + Sync + ‘static 后可以让 trait object 来跨线程返回, 例如在 aysnc spawn 场景中;
- 标准库的其他 error 类型都实现了到 std::error::Error 和上面 trait object 的转换;
标准库为实现 std::error::Error trait 的类型都实现了 ToString、Display 和 Debug trait, 可以用 println!() 直接打印:
println!("error querying the weather: {}", err);
println!("error querying the weather: {:?}", err);
use std::error;
use std::fmt;
// Change the alias to use `Box<dyn error::Error>`.
type Result<T> = std::result::Result<T, Box<dyn error::Error>>;
#[derive(Debug, Clone)]
struct EmptyVec; // 自定义 error 类型
impl fmt::Display for EmptyVec {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
write!(f, "invalid first item to double")
}
}
impl error::Error for EmptyVec {} // std::error::Error 是 marker trait
fn double_first(vec: Vec<&str>) -> Result<i32> {
vec.first()
.ok_or_else(|| EmptyVec.into()) // Converts to Box
.and_then(|s| {
s.parse::<i32>()
.map_err(|e| e.into()) // Converts to Box
.map(|i| 2 * i)
})
}
// // The same structure as before but rather than chain all `Results`
// // and `Options` along, we `?` to get the inner value out immediately.
// fn double_first(vec: Vec<&str>) -> Result<i32> {
// let first = vec.first().ok_or(EmptyVec)?;
// let parsed = first.parse::<i32>()?;
// Ok(2 * parsed)
// }
fn print(result: Result<i32>) {
match result {
Ok(n) => println!("The first doubled is {}", n),
Err(e) => println!("Error: {}", e),
}
}
fn main() {
let numbers = vec!["42", "93", "18"];
let empty = vec![];
let strings = vec!["tofu", "93", "18"];
print(double_first(numbers));
print(double_first(empty));
print(double_first(strings));
}
自定义 Error 类型, 提供更丰富/个性化的上下文和出错信息:
- 实现 fmt::Display 的 fmt() 方法;
- 实现 std::error::Error trait( Error trait 都有默认实现,可以只是标记实现)。
- 实现 From<XX> trait, 将其他类型错误 XX 转换为自定义类型错误。如果转换不一定成功,可以使用 TryFrom<XX> trait, 它返回一个 Result 来指示是否转换成功。
use std::error;
use std::error::Error;
use std::num::ParseIntError;
use std::fmt;
type Result<T> = std::result::Result<T, DoubleError>;
#[derive(Debug)]
enum DoubleError {
EmptyVec,
// We will defer to the parse error implementation for their error. Supplying extra info
// requires adding more data to the type.
Parse(ParseIntError),
}
impl fmt::Display for DoubleError {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
match *self {
DoubleError::EmptyVec =>
write!(f, "please use a vector with at least one element"),
// The wrapped error contains additional information and is available via the source()
// method.
DoubleError::Parse(..) =>
write!(f, "the provided string could not be parsed as int"),
}
}
}
impl error::Error for DoubleError {
fn source(&self) -> Option<&(dyn error::Error + 'static)> {
match *self {
DoubleError::EmptyVec => None,
// The cause is the underlying implementation error type. Is implicitly cast to the
// trait object `&error::Error`. This works because the underlying type already
// implements the `Error` trait.
DoubleError::Parse(ref e) => Some(e),
}
}
}
// Implement the conversion from `ParseIntError` to `DoubleError`. This will be automatically
// called by `?` if a `ParseIntError` needs to be converted into a `DoubleError`.
impl From<ParseIntError> for DoubleError {
fn from(err: ParseIntError) -> DoubleError {
DoubleError::Parse(err)
}
}
fn double_first(vec: Vec<&str>) -> Result<i32> {
let first = vec.first().ok_or(DoubleError::EmptyVec)?;
// Here we implicitly use the `ParseIntError` implementation of `From` (which we defined above)
// in order to create a `DoubleError`.
let parsed = first.parse::<i32>()?;
Ok(2 * parsed)
}
fn print(result: Result<i32>) {
match result {
Ok(n) => println!("The first doubled is {}", n),
Err(e) => {
println!("Error: {}", e);
if let Some(source) = e.source() {
println!(" Caused by: {}", source);
}
},
}
}
fn main() {
let numbers = vec!["42", "93", "18"];
let empty = vec![];
let strings = vec!["tofu", "93", "18"];
print(double_first(numbers));
print(double_first(empty));
print(double_first(strings));
}
thiserror crate 为自定义 Error 类型提供了基于宏的声明式实现:
// https://github.com/Abraxas-365/langchain-rust/blob/main/src/agent/error.rs
use thiserror::Error;
use crate::{chain::ChainError, language_models::LLMError, prompt::PromptError};
#[derive(Error, Debug)]
pub enum AgentError {
#[error("LLM error: {0}")]
LLMError(#[from] LLMError),
#[error("Chain error: {0}")]
ChainError(#[from] ChainError),
#[error("Prompt error: {0}")]
PromptError(#[from] PromptError),
#[error("Tool error: {0}")]
ToolError(String),
#[error("Missing Object On Builder: {0}")]
MissingObject(String),
#[error("Missing input variable: {0}")]
MissingInputVariable(String),
#[error("Serde json error: {0}")]
SerdeJsonError(#[from] serde_json::Error),
#[error("Error: {0}")]
OtherError(String),
}
14 const/static/lazy_static! #
Rust 支持两种 const 常量,可以在全局,函数,block 等 scope 中声明,全局常量需要使用 全大写名称 ,否则编译器警告;
- const:不可变值;
- static:可能可变的(static mut),需要在 unsafe 中读写 static mut 值;
// Globals are declared outside all other scopes.
const THRESHOLD: i32 = 10; // 全局常量
static LANGUAGE: &str = "Rust"; // 全局常量,默认带 'static
// 全局 static 可变变量, 需要在 unsafe 代码中访问
static mut stat_mut = "abc";
fn is_big(n: i32) -> bool {
n > THRESHOLD
}
fn main() {
let n = 16;
println!("This is {}", LANGUAGE);
println!("The threshold is {}", THRESHOLD);
println!("{} is {}", n, if is_big(n) { "big" } else { "small" });
// Error! Cannot modify a `const`.
THRESHOLD = 5;
}
// static 变量也可以定义在函数中,和 C 的 static 变量类似,在函数返回时变量仍有效,在程序整个生命周
// 期均有效。
fn computation() -> &'static DeepThought {
// n.b. static items do not call [`Drop`] on program termination, so if
// [`DeepThought`] impls Drop, that will not be used for this instance.
static COMPUTATION: OnceLock<DeepThought> = OnceLock::new();
COMPUTATION.get_or_init(|| DeepThought::new())
}
对 const/static 变量的初始化, 只能使用 const 函数/tuple 类型。
为了克服上面的 const/static 变量初始化的局限性,可以使用 lazy_static! 宏定义静态变量,可以使用任何表达式进行初始化,表达式会在变量第一次解引用时运行,值会被存储在变量中以便后续使用。
use std::sync::Mutex;
lazy_static! {
static ref HOSTNAME: Mutex<String> = Mutex::new(String::new()); // 任意初始化表达式
}
const/static 默认具有 ‘static lifetime., 不可修改的,所以一般使用支持内部可变性的 Mutex/AtomicXX 来作为全局对象的类型:
const BIT1: u32 = 1 << 0;
const BIT2: u32 = 1 << 1;
const BITS: [u32; 2] = [BIT1, BIT2];
const STRING: &'static str = "bitstring";
struct BitsNStrings<'a> {
mybits: [u32; 2],
mystring: &'a str,
}
const BITS_N_STRINGS: BitsNStrings<'static> = BitsNStrings {
mybits: BITS,
mystring: STRING,
};
use std::sync::Mutex;
use std::sync::atomic::AtomicUsize;
static MY_GLOBAL: Vec<usize> = Vec::new(); // OK, 但是不可修改。
static PACKETS_SERVED: AtomicUsize = AtomicUsize::new(0); // ok, 可以修改
static HOSTNAME: Mutex<String> = Mutex::new(String::new()); // ok, 可以修改
fn main() {
let mut name = HOSTNAME.lock().unwrap();
name.push_str("localhost");
println!("Results: {name}");
}
15 refer/borrow #
RAII:Rust 中每一个资源或对象只能有一个 Owner 变量,在 Owner 离开作用域 scope 时,它的 Drop trait 被调用来释放资源。
Rust 对象都有唯一的所有权,所有权可以通过赋值表达式、函数传参、函数返回、添加到 struct/tuple 和集合等来转移所有权, 原来的变量变成 未初始化状态, 不能再使用, 可以避免 dangling pointers。一般情况下堆上分配的对象,例如 String/Vec 没有实现 Copy。自定义类型,如 struct/enum/union 也没有实现 Copy。这种转移 Move 的方式,在性能上和安全性上都是非常有效的(避免了栈和堆内存拷贝),Rust 编译器也会对转移的变量进行错误检查。
// 所有权转移,所以可以从栈上返回对象:
fn new_person() -> Person {
let person = Person {
name : String::from("Hao Chen"),
age : 44,
sex : Sex::Male,
email: String::from("[email protected]"),
};
return person;
}
fn main() {
let p = new_person();
}
fn create_box() {
// Allocate an integer on the heap
let _box1 = Box::new(3i32);
// `_box1` is destroyed here, and memory gets freed
}
fn main() {
// Allocate an integer on the heap
let _box2 = Box::new(5i32);
// A nested scope:
{
// Allocate an integer on the heap
let _box3 = Box::new(4i32);
// `_box3` is destroyed here, and memory gets freed
}
// Creating lots of boxes just for fun
// There's no need to manually free memory!
for _ in 0u32..1_000 {
create_box();
}
// `_box2` is destroyed here, and memory gets freed
}
为了不获得对象所有权的情况下来使用对象,Rust 通过借用操作(borrow/mut borrow)来获得对象的引用。或者通过引用计数类型,如 Rc/Arc 来 clone 对象(不会拷贝堆数据)。
Rust borrow checker 对所有权和借用进行检查,违反时编译报错:
- 对象可以多次共享借用,但是只能一次可变借用。
- 可变借用的对象本身必须是可变的,即只能对 mut 对象进行 &mut 可变借用,或从已有 &mut 借用生成新的 &mut 借用;
- &mut T 可以自动协变(coerced into)到 &T 类型,所以在需要 &T 的地方可以传入 &mut T 类型值,但是反过来不行。
- 如果函数的参数类型是 trait bound,则不会进行 &mut T 到 &T 的协变,必须传入 &T 变量。
- 对象在存在借用的情况下,
不能被修改或 move;《==借用冻结
use std::str::FromStr;
fn main() {
let mut a = 123;
let ar = &a;
a = 456; // Error:cannot assign to `a` because it is borrowed,借用冻结
println!("{ar}")
let mut s = String::from_str("new string").unwrap();
let sm = &mut s; // s 本身必须是 mut 类型才能被 &mut,在有 &mut 的情况下,原始值 s 不能再被访问。
// println!("Result: {s} {sm}"); // cannot borrow `s` as immutable because it is also borrowed as mutable
println!("Result: {sm}"); // OK
let s2 = &mut String::from_str("new string").unwrap();
// let sm2 = &mut s2; // s2 不是 mut 类型,不能被 &mut;
s2.push_str(" abc"); // s2 虽然不是 mut 类型,但本身是 &mut,所以可以修改;
println!("s2: {s2}");
let s3 = s2; // s3 也是 &mut 类型, 也可以修改
s3.push_str(" def");
println!("s3: {s3}");
// let s4 = *s3; // cannot move out of `*s3` which is behind a mutable reference
// 在已经 &mut T 的情况下,原始值不能再被访问(不能被 move 和修改):
let mut s = String::from_str("new string").unwrap();
let sm = &mut s; // s 本身必须是 mut 类型,才能被 &mut;
s.push_str("abc"); // Error: 在 sm 后续继续使用的情况下,原来的 s 不能再使用。
// 不能同时使用 s 和 sm。
println!("Result: {s} {sm}"); // cannot borrow `s` as immutable because it is also borrowed as mutable
struct MyStruct(u8, String);
let mut ms = MyStruct(3, "test".to_string());
let msm = &mut ms;
let msm2 = &mut msm.1; // 可以从 &mut 创建出另一个 &mut
msm2.push_str(" def");
}
在转移对象的所有权时可以改变它的可变性(因为转移到的变量 owned 该对象):
fn main() {
let immutable_box = Box::new(5u32);
println!("immutable_box contains {}", immutable_box);
// Mutability error
//*immutable_box = 4;
// *Move* the box, changing the ownership (and mutability)
let mut mutable_box = immutable_box;
println!("mutable_box contains {}", mutable_box);
// Modify the contents of the box
*mutable_box = 4;
println!("mutable_box now contains {}", mutable_box);
}
不支持通过借用(无论是可变还是共享借用)来对对象的所有权进行转移,例如 let v2 = *V ,解决办法:
- V 如果实现 Copy/Clone trait,则可以调用对应的方法;
- 使用 std::mem::replace(&dest, src) 将 src 值替换 dest,同时返回 dest 的值:
struct Buffer {
buffer : String,
}
struct Render {
current_buffer : Buffer,
next_buffer : Buffer,
}
impl Render {
fn update_buffer(& mut self, buf : String) {
// error[E0507]: cannot move out of `self.next_buffer` which is behind a mutable reference
// move occurs because `self.next_buffer` has type `Buffer`, which does not implement the
// `Copy` trait
self.current_buffer = self.next_buffer;
self.next_buffer = Buffer{ buffer: buf};
}
}
// OK 的例子,这里没有使用 &/&mut, 而是直接使用对象的变量 p 来转移 move 对象,这是 OK 的。
#[derive(Debug)]
struct Person {
name: String,
email: String,
}
fn main() {
let mut p = Person{name: "zzz".to_string(), email: "fff".to_string()};
let _name = p.name; // struct 允许部分 move
println!("{} {}", _name, p.email); // 可以访问没有 move 的 struct 成员
println!("{:?}", p); //不允许访问部分 move 的 struct 整体
p.name = "Hao Chen".to_string();
println!("{:?}", p); // OK
}
// OK 的例子,使用 std::mem::replace() 替换
fn update_buffer(& mut self, buf : String) {
self.current_buffer = std::mem::replace(&mut self.next_buffer, Buffer{buffer : buf});
}
// OK 的例子:也可以使用 std::ptr::read/write 来临时转义借用对象的内容
//
// ptr::read(src: *const T) -> T会从src指针处获取要复制的内容(假定是T类型实例),然后通过**”浅复制
// “**的方式,复制一份新实例,并返回。
//
// ptr::read(src: *const Buffer)会从src指针copy Buffer结构体内容 到tmp(*mut Buffer)处;而Buffer内部
// buffer是String类型,非copy类型,此时tmp内的buffer与src内
unsafe {
// result 中的 buffer(String),实际上跟dest中的buffer指向共同一块区域
let result = ::std::ptr::read(dest);
::std::ptr::write(dest, src);
result
}
Reborrow:如果以前的 &mut 变量 r 不再使用,则可以使用 &*r 来获取新的 reborrow;
- 如果借用后续不再使用,则允许再次借用,该特性称为 NLL: Non-Lexical Lifetime
#[derive(Debug)]
struct Point {
x: i32,
y: i32,
}
impl Point {
fn move_to(&mut self, x: i32, y: i32) {
self.x = x;
self.y = y;
}
}
fn main() {
let mut p = Point { x: 0, y: 0 };
let r = &mut p;
// let p2 = *r // 错误:Point 未实现 Copy,不能通过 *r 来进行转移值
let rr: &Point = &*r; // reborrow
println!("{:?}", rr); // Reborrow ends here, NLL introduced
// Reborrow is over, we can continue using `r` now
r.move_to(10, 10);
println!("{:?}", r);
}
Rust borrow checker 将变量视为所有权树的根,所以如果要修改对象的成员(如 struct field)、成员的子对象等状态,一般是使用 &mut self,这样可以将 &mut 引用从对象的根传递到 最内层对象 。这里的修改包括 3
方面:
- 对对象本身进行修改;
- 对对象的成员进行修改;
- 调用对象或成员的方法,这些方法会改变对象的状态和内部字段等。
Rust 提供了 内部可变性 机制,来让使用共享借用 &self 的方法修改 Cell/RefCell/Mutex/Rwlock 等对象的内部状态。
let data = Arc::new(Mutex::new(0)); // data 不可变。
let mut data = data.lock().unwrap(); // MutextGuard 支持内部可变性,故可以获得 mut data。
*data += 1;
在解构 struct/tuple 对象时, 可以 by-move(默认)或 by-refer(需要添加 ref/ref mut):
- ref/ref mut 表示获得对象的借用,在表达式左侧使用 ref/ref mut 相当于表达式右侧的 &/&mut 操作,对应的变量是 &/&mut 类型。
- by-move 可能造成 struct/tuple 的 field 被
partial move,这些 field 后续不能再访问,但是未被 partial move 的字段还是可以访问的; - Vec/Array 等
容器类型不支持元素的 partial move, 元素需要实现 Copy 或者被 std::mem::replace。
// https://practice.course.rs/ownership/ownership.html
fn main() {
#[derive(Debug)]
struct Person {
name: String,
age: Box<u8>,
}
let person = Person {
name: String::from("Alice"),
age: Box::new(20),
};
// `name` is moved out of person, but `age` is referenced
let Person { name, ref age } = person;
println!("The person's age is {}", age);
println!("The person's name is {}", name);
// Error! borrow of partially moved value: `person` partial move occurs
//println!("The person struct is {:?}", person);
// `person` cannot be used but `person.age` can be used as it is not moved
println!("The person's age from person struct is {}", person.age);
}
// Vec/array 中的元素不支持 partial-move
struct Person { name: Option<String>, birth: i32 }
let mut composers = Vec::new();
composers.push(Person { name: Some("Palestrina".to_string()), birth: 1525 });
// 编译出错
let first_name = composers[0].name;
变量声明时 mut 的位置差异:
let mut data1: Vec<i32> = vec![1, 2]; vs let data2: &mut Vec<i32> = &mut vec![1, 2];
- data1 作为一个 mut 变量, 值是可变的, 支持 data1.push(2), 也支持 &mut data1;
- data2 不是 mut 变量, 所以不能修改 data2 本身, 但是 &mut 类型, 所以借用的值是可变的, 支持 data2.push(2), 但是不支持 &mut data2;
解引用操作符 * 用于返回引用类型对象的值。由于 Rust 编译器会自动解引用和生成引用,所以实际很少直接通过 * 操作符来显式解引用:
- 通过 . 操作符访问对象的成员时,Rust 自动解引用:
ref.filed 等效于 (*ref).field; - 通过 . 操作符调用方法时,如果方法的第一个参数式 &self 或 &mut self, 则
自动借用对象来生成引用,然后传递给对应的方法:v.sort() 等效为 (&v).sort(),称为 methdo call deref coercion.
// 使用 . 访问引用对象成员时,自动解引用
struct Anime { name: &'static str, bechdel_pass: bool };
let aria = Anime { name: "Aria: The Animation", bechdel_pass: true };
let anime_ref = &aria;
assert_eq!(anime_ref.name, "Aria: The Animation");
// Equivalent to the above, but with the dereference written out:
assert_eq!((*anime_ref).name, "Aria: The Animation");
// 对象方法是 &self 或 &mut self 时自动生成对象的引用
let mut v = vec![1973, 1968];
v.sort(); // implicitly borrows a mutable reference to v
(&mut v).sort(); // equivalent, but more verbose
// 但是直接使用 ref 变量时,需要手动解引用
let x = 5;
let y = &x;
assert_eq!(5, *y); // y 需要解引用
其他自动解引用场景(都支持 多级自动解引用 ):
- 比较操作,所以默认情况下比较的是引用的值,而非引用本身(指针)。
- index 操作符。
- 算术运算操作;
- println!()/assert* 等宏函数自动解引用传入的引用参数:
struct Point { x: i32, y: i32 }
let point = Point { x: 1000, y: 729 }; let r: &Point = &point;
let rr: &&Point = &r;
let rrr: &&&Point = &rr;
assert_eq!(rrr.y, 729); // . 操作支持多级解引用
let x = 10; let y = 10;
let rx = &x; let ry = &y;
let rrx = ℞ let rry = &ry;
assert!(rrx <= rry); // 比较操作也自动多级解引用
assert!(rrx == rry);
fn factorial(n: usize) -> usize {
(1..n+1).product()
}
let r = &factorial(6);
assert_eq!(r + &1009, 1729); // 算术运算自动解引用。
let v1: Vec<i32> = vec![1, 2, 3];
v1.iter().map(|x| x + 1); // 算术运算自动解引用
Rust 引用操作可以是任意表达式,如字面量,Rust 会自动进行转换(coercion) Type coercions - The Rust Reference
r + &1009;
let _: &i8 = &mut 42;
fn bar(_: &i8) { }
fn main() {
bar(&mut 42);
let x = 5;
let y = &x;
assert_eq!(5, y);
println!("Success!");
}
对于 T,&T,&mut T,Box<T> 在进行 Display 时显示的都是 T 的值。&T, &mut T, Box<T> 实际是指针类型,可以使用 p 修饰符来 显示它们的地址而非值 :
- Rc::clone() 由于不会发生内存拷贝,而只是增加了引用计数,所以产生的对象与以前的对象是
相同的地址。 - 如果要比较引用地址本身,需要使用 std::ptr::eq 函数,使用 {:p} 来打印指针地址:
use std::rc::Rc;
fn main() {
let mut t = 123;
let tp = &mut t;
let tpp = &tp; // 从 &mut T 变量中可以再借用出共享引用 &T
println!("{:p} {:p}", tp, tpp); // tp 和 tpp 是两个不同类型的变量,所以地址不一致
let rc = Rc::new(String::from("abc"));
let rc2 = rc.clone();
// rc: abc, rc2: abc, rc pointer:0x600001bdc2b0, rc2 pointer 0x600001bdc2b0
// 可见 rc 和 rc2 内存的地址都是一样的,说明 Rc clone 没有发生堆内存拷贝。
println!("rc: {}, rc2: {}, rc pointer:{:p}, rc2 pointer {:p}", rc, rc2, rc, rc2);
}
use std::ptr;
let five = 5;
let other_five = 5;
let five_ref = &five;
let same_five_ref = &five;
let other_five_ref = &other_five;
assert!(five_ref == same_five_ref); // 比较操作时,自动多级解引用,所以比较的是值。
assert!(five_ref == other_five_ref);
assert!(std::ptr::eq(five_ref, same_five_ref)); // std::ptr::eq 比较地址
assert!(!std::ptr::eq(five_ref, other_five_ref));
16 lifetime #
Rust 给每一个 引用类型 对象设置一个 lifetime(自动或手动),如函数的输入和输出参数,函数内的变量,全局变量,struct/enum 成员等。设置 lifetime 的目的是指导 Rust borrow checker 对程序各部分借用的对象的引用的生命周期进行检查,发现异常时编译报错。
let b = &'a dyn MyTrait + Send + 'static; // error: expected expression, found keyword `dyn`
let b = &'a(dyn MyTrait + Send + 'static); // error: borrow expressions cannot be annotated with lifetimes
lifetime 只是一个编译时的注解, 没有运行时代表 ,也不能在表达式中使用。lifetime 表达的是一个 相对的概念 和约束, Rust borrow checker 根据 lifetime anno 来检查引用是否有效:
- <T: ‘b> :表示 T 的引用的生命周期比 ‘b 长。
- &‘b T 隐式表示 T: ‘b, 即 T 的生命周期要比 ‘b 长。
- <T: Trait + ‘b> :表示 T 要实现 Trait 且 T 的生命周期比 ‘b 长。
- struct foo<‘a: ‘b, ‘b,T: ‘b> (val1: &‘a String, val2: &‘a String, val3: &‘b String, val4: &T):
- <‘a: ‘b, ‘b>:表示 ‘a 的生命周期比 ‘b 长;
- val1 和 val2 的生命周期一样长, 且比 val3 的生命周期长;
- val4 的生命周期要比 ‘b 长,即 val4 的生命周期要比 val3 长;
- foo 对象的生命周期不能长于 ‘a 和 ‘b;
- 注意上面 ‘a 和 ‘b 的顺序和语法,错误的情况:<‘a, ‘b, ‘a: ‘b>;
- fn print_refs<‘a: ‘b, ‘b>(x: &‘a i32, y: &‘b i32) -> &‘b String
- 函数执行期间 ‘a, ‘b 的引用要一直有效,即 ‘a 和 ‘b 的生命周期比函数长;
- ‘a: ‘b 表示 ‘a 的生命周期比 ‘b 长,所以 x 的生命周期要比 y 长;
- 返回值的生命周期要和 y 一样长;
lifetime 作为泛型参数时,必须位于其他泛型参数之前,比如 <‘a, T, T2>:
fn add_ref<'a, 'b, T>(a: &'a mut T, b: &'b T) -> &'a T
where
T: std::ops::Add<T, Output = T> + Copy,
{
*a = *a + *b;
a // OK
// b // Error: b 的声明周期是 'b 与返回值的声明 'a 不一致。function was supposed to return data with lifetime `'b` but it is returning data with lifetime `'a`
}
#[derive(Debug)]
struct Ref<'a, T: 'a>(&'a T); // 等效于 struct Ref<'a, T: 'a>(&T);
// `Ref` contains a reference to a generic type `T` that has an unknown lifetime `'a`. `T` is
// bounded such that any *references* in `T` must outlive `'a`. Additionally, the lifetime of `Ref`
// may not exceed `'a`.
// Here a reference to `T` is taken where `T` implements `Debug` and all *references* in `T` outlive
// `'a`. In addition, `'a` must outlive the function.
fn print_ref<'a, T>(t: &'a T) where T: Debug + 'a { // 等效于 fn print_ref<'a, T>(t: &T) where T: Debug + 'a {
println!("`print_ref`: t is {:?}", t);
}
fn main() {
let x = 7;
let ref_x = Ref(&x);
print_ref(&ref_x);
print(ref_x);
}
如果泛型类型需要 lifetime 参数,但是在实现某个 Trait 时该 Trait 的方法并不需要该 lifetime 参数或则编译器可以自动推断,则可以使用 <’_>:
impl<'a> Reader for BufReader<'a> {
// 'a is not used in the following methods
}
// can be written as :
impl Reader for BufReader<'_> {
}
// lifetime elision
impl <T> Vec<T> {
pub fn iter(&self) -> Iter<'_, T> {
// [...]
}
}
struct/enum 的 lifetime:
- 如果 struct/enum 有 ref 成员,则必须要为 struct/enum 指定 lifetime 参数;
- struct/enum 对象的 lifetime 要比指定的所有 lifetime 参数
短. - 特殊的 struct MyStruct<‘static> 则 MyStruct 对象的 lifetime 可以任意长(因为 ‘static 是在程序整个运行期间都有效)。
// A type `Borrowed` which houses a reference to an `i32`. The reference to `i32` must outlive
// `Borrowed`.
#[derive(Debug)]
struct Borrowed<'a>(&'a i32);
// Similarly, both references here must outlive this structure.
#[derive(Debug)]
struct NamedBorrowed<'a> {
x: &'a i32,
y: &'a i32,
}
// An enum which is either an `i32` or a reference to one.
#[derive(Debug)]
enum Either<'a> {
Num(i32),
Ref(&'a i32),
}
fn main() {
let x = 18;
let y = 15;
let single = Borrowed(&x);
let double = NamedBorrowed { x: &x, y: &y };
let reference = Either::Ref(&x);
let number = Either::Num(y);
println!("x is borrowed in {:?}", single);
println!("x and y are borrowed in {:?}", double);
println!("x is borrowed in {:?}", reference);
println!("y is *not* borrowed in {:?}", number);
}
函数 lifetime:
- 所有 ref 必须有 lifetime anno, 如果没有明确指定,Rust 编译器自动加 lifetime anno,规则参考: 16.3
- 所有返回值的 ref 的 lifetime 必须和
某些输入的值的 lifetime 一致或者是 ‘static; - 如果自动推断后还是不能确定返回值 ref 和输入值 lifetime 的关系,则编译报错,需要手动加 lifetime:
// `print_refs` takes two references to `i32` which have different lifetimes `'a` and `'b`. These
// two lifetimes must both be at least as long as the function `print_refs`.
fn print_refs<'a, 'b>(x: &'a i32, y: &'b i32) {
println!("x is {} and y is {}", x, y);
}
// A function which takes no arguments, but has a lifetime parameter `'a`.
fn failed_borrow<'a>() {
let _x = 12;
// ERROR: `_x` does not live long enough
let _y: &'a i32 = &_x;
// Attempting to use the lifetime `'a` as an explicit type annotation inside the function will
// fail because the lifetime of `&_x` is shorter than that of `_y`. A short lifetime cannot be
// coerced into a longer one.
}
fn main() {
// Create variables to be borrowed below.
let (four, nine) = (4, 9);
// Borrows (`&`) of both variables are passed into the function.
print_refs(&four, &nine);
// Any input which is borrowed must outlive the borrower. In other words, the lifetime of
// `four` and `nine` must be longer than that of `print_refs`.
failed_borrow();
// `failed_borrow` contains no references to force `'a` to be longer than the lifetime of the
// function, but `'a` is longer. Because the lifetime is never constrained, it defaults to
// `'static`.
}
// One input reference with lifetime `'a` which must live at least as long as the function.
fn print_one<'a>(x: &'a i32) {
println!("`print_one`: x is {}", x);
}
// Mutable references are possible with lifetimes as well.
fn add_one<'a>(x: &'a mut i32) {
*x += 1;
}
// Multiple elements with different lifetimes. In this case, it would be fine for both to have the
// same lifetime `'a`, but in more complex cases, different lifetimes may be required.
fn print_multi<'a, 'b>(x: &'a i32, y: &'b i32) {
println!("`print_multi`: x is {}, y is {}", x, y);
}
// Returning references that have been passed in is acceptable. However, the correct lifetime must
// be returned.
fn pass_x<'a, 'b>(x: &'a i32, _: &'b i32) -> &'a i32 { x }
// 要求返回值的 lifetime 和 'a 一样长, 'a 等效于 'static, 而函数内的 ref 在函数返回即失效,所以不能编译.
//fn invalid_output<'a>() -> &'a String { &String::from("foo") }
// The above is invalid: `'a` must live longer than the function.
// Here, `&String::from("foo")` would create a `String`, followed by a
// reference. Then the data is dropped upon exiting the scope, leaving
// a reference to invalid data to be returned.
fn main() {
let x = 7;
let y = 9;
print_one(&x);
print_multi(&x, &y);
let z = pass_x(&x, &y);
print_one(z);
let mut t = 3;
add_one(&mut t);
print_one(&t);
}
// 错误的情况,编译器不能推断出返回值引用的 lifetime 关系。
fn order_string(s1 : &str, s2 : &str) -> (&str, &str) {
if s1.len() < s2.len() {
return (s1, s2);
}
return (s2, s1);
}
闭包 lifetime:闭包函数返回引用时可能会遇到 lifetime 问题( 16.3 并不适合闭包),解决办法:
- 使用 nightly toolchain 和开启 #![feature(closure_lifetime_binder)],这样可以为闭包函数指定 for <‘a> 语法的 lifetime: https://github.com/rust-lang/rust/issues/97362
- 或者,定义一个 helper 函数,该函数可以指定闭包输入、输出参数所需的 lifetime,然后内部调用闭包;
- 或者,将闭包转换为 fn 函数指针,函数指针支持使用 for<‘a> 来定义高阶函数; https://stackoverflow.com/a/60906558
fn fn_elision(x: &i32) -> &i32 { x } // OK
let closure_elision = |x: &i32| -> &i32 { x }; // Error
| let closure = |x: &i32| -> &i32 { x }; // fails
| - - ^ returning this value requires that `'1` must outlive `'2`
| | |
| | let's call the lifetime of this reference `'2`
| let's call the lifetime of this reference `'1`
// 解决办法1:
fn main() {
// let clouse_test = |input: &String| input; // error: lifetime may not live long enough
//let clouse_test = |input: &String| -> &String {input}; // error: lifetime may not live long enough
// let clouse_test = |input: &'a String| ->&'a String {input}; // error[E0261]: use of undeclared lifetime name `'a`
// 需要使用 nightly toolchain 和开启 #![feature(closure_lifetime_binder)]
let clouse_test = for <'a> |input: &'a String| ->&'a String {input};
println!("Results:")
}
// 解决办法2:
fn testStr<'a> (input: &'a String) -> &'a String {
let closure_test = |input: &'a String | -> &'a String {input}; // 闭包使用外围 helper 函数定义的 lifetime
return closure_test(input);
}
fn main() {
// let clouse_test = |input: &String| input; // error: lifetime may not live long enough
//let clouse_test = |input: &String| -> &String {input}; // error: lifetime may not live long enough
// let clouse_test = |input: &'a String| ->&'a String {input}; // error[E0261]: use of undeclared lifetime name `'a`
// let clouse_test = for <'a> |input: &'a String| ->&'a String {input};
println!("Results:{}", testStr(&"asdfab".to_string()));
}
// 解决办法3:
// 将闭包转换为 fn 函数指针,函数指针支持使用 for<'a> 来定义高阶函数,而且编译期间大小是已知的。
// 但是不能使用 Fn/FnMut/FnOnce 等 trait 类型。
let test_fn: for<'a> fn(&'a _) -> &'a _ = |p: &String| p;
println!("Results:{}", test_fn(&"asdfab".to_string()));
// 其他例子:https://github.com/rust-lang/rust/pull/56746/files
#![allow(unused)]
fn willy_no_annot<'w>(p: &'w str, q: &str) -> &'w str {
let free_dumb = |_x| { p }; // no type annotation at all
let hello = format!("Hello");
free_dumb(&hello)
}
fn willy_ret_type_annot<'w>(p: &'w str, q: &str) -> &'w str {
let free_dumb = |_x| -> &str { p }; // type annotation on the return type
let hello = format!("Hello");
free_dumb(&hello)
}
fn willy_ret_region_annot<'w>(p: &'w str, q: &str) -> &'w str {
let free_dumb = |_x| -> &'w str { p }; // type+region annotation on return type
let hello = format!("Hello");
free_dumb(&hello)
}
fn willy_arg_type_ret_type_annot<'w>(p: &'w str, q: &str) -> &'w str {
let free_dumb = |_x: &str| -> &str { p }; // type annotation on arg and return types
let hello = format!("Hello");
free_dumb(&hello)
}
fn willy_arg_type_ret_region_annot<'w>(p: &'w str, q: &str) -> &'w str {
let free_dumb = |_x: &str| -> &'w str { p }; // fully annotated
let hello = format!("Hello");
free_dumb(&hello)
}
fn main() {
let world = format!("World");
let w1: &str = {
let hello = format!("He11o");
willy_no_annot(&world, &hello)
};
let w2: &str = {
let hello = format!("He22o");
willy_ret_type_annot(&world, &hello)
};
let w3: &str = {
let hello = format!("He33o");
willy_ret_region_annot(&world, &hello)
};
let w4: &str = {
let hello = format!("He44o");
willy_arg_type_ret_type_annot(&world, &hello)
};
let w5: &str = {
let hello = format!("He55o");
willy_arg_type_ret_region_annot(&world, &hello)
};
assert_eq!((w1, w2, w3, w4, w5),
("World","World","World","World","World"));
}
}
lifetime 之间存在 subtype 的关系(类似的还有 HRTB 声明的 lifetime 是其它任意 lifetime 的子类型):更长的 lifetime 是更短 lifetime 的子类型,所以更长的 lifetime 可以被 coerced 到短一些的 lifetime:
- ‘a: ‘b 表示 ‘a lifetime 至少要比 ‘b 长,这样在返回 ‘b 的引用时,可以返回 ‘a 的 lifetime 对象;
- ‘static 可以被 coerced 到任意的其他 lifetime ‘a;
fn choose_first<'a: 'b, 'b>(first: &'a i32, _: &'b i32) -> &'b i32 {
first
}
fn main() {
let first = 2; // Longer lifetime
{
let second = 3; // Shorter lifetime
println!("The product is {}", multiply(&first, &second));
println!("{} is the first", choose_first(&first, &second));
};
}
// 另一个例子
trait MyTrait<'a> {
fn say_hello(&'a self) -> &'a String;
}
struct MyStruct(String);
impl<'a> MyTrait<'a> for MyStruct {
fn say_hello(&'a self) -> &'a String {
println!("hello {}", self.0);
&self.0
}
}
// 更复杂的例子:
fn printf_hello<'a, 'b>(say_hello: Option<&'a (dyn MyTrait<'a> + Send + 'b)>) -> Option<&'b String> where 'a: 'b,
{
let hello = if let Some(my_trait) = say_hello {
my_trait.say_hello()
} else {
return None;
};
Some(hello)
}
隐式 liftime bound 的场景: &‘a T 隐式表示 T: ‘a, 即 T 的生命周期比 ‘a 长;
fn requires_t_outlives_a_not_implied<'a, T: 'a>() {}
fn requires_t_outlives_a<'a, T>(x: &'a T) {
// This compiles, because `T: 'a` is implied by the reference type `&'a T`.
requires_t_outlives_a_not_implied::<'a, T>();
}
fn not_implied<'a, T>() {
// This errors, because `T: 'a` is not implied by the function signature.
requires_t_outlives_a_not_implied::<'a, T>();
}
struct Struct<'a, T> {
// This requires `T: 'a` to be well-formed which is inferred by the compiler.
field: &'a T,
}
enum Enum<'a, T> {
// This requires `T: 'a` to be well-formed, which is inferred by the compiler.
//
// Note that `T: 'a` is required even when only using `Enum::OtherVariant`.
SomeVariant(&'a T),
OtherVariant,
}
trait Trait<'a, T: 'a> {}
// This would error because `T: 'a` is not implied by any type
// in the impl header.
// impl<'a, T> Trait<'a, T> for () {}
// This compiles as `T: 'a` is implied by the self type `&'a T`.
impl<'a, T> Trait<'a, T> for &'a T {}
16.1 Higher-Rank Trait Bounds (HRTBs) #
HRTB 一般只会在 Fn 作为 Bound 时会使用到, 下面没有加 lifetime 的代码是可以正常编译的:
struct Closure<F> {
data: (u8, u16),
func: F,
}
impl<F> Closure<F> where F: Fn(&(u8, u16)) -> &u8,
{
fn call(&self) -> &u8 {
(self.func)(&self.data)
}
}
fn do_it(data: &(u8, u16)) -> &u8 { &data.0 }
fn main() {
let clo = Closure { data: (0, 1), func: do_it };
println!("{}", clo.call());
}
如果要给上面的代码添加 lifetime bound 则会遇到 F 的 lifetime 该如何指定的问题:
struct Closure<F> {
data: (u8, u16),
func: F,
}
impl<F> Closure<F> // where F: Fn(&'??? (u8, u16)) -> &'??? u8,
{
fn call<'a>(&'a self) -> &'a u8 {
(self.func)(&self.data)
}
}
fn do_it<'b>(data: &'b (u8, u16)) -> &'b u8 { &'b data.0 }
fn main() {
'x: {
let clo = Closure { data: (0, 1), func: do_it };
println!("{}", clo.call());
}
}
// Error1:
impl<'a, F> Closure<F> where F: Fn(&'a (u8, u16)) -> &'a u8,
{
fn call<'a>(&'a self) -> &'a u8 {
// lifetime name `'a` shadows a lifetime name that is already in scope
(self.func)(&self.data)
}
}
// Error2:
impl<'a, F> Closure<F> where F: Fn(&'a (u8, u16)) -> &'a u8,
{
fn call<'b>(&'b self) -> &'b u8 {
// method was supposed to return data with lifetime `'a` but it is returning data
// with lifetime `'b`
(self.func)(&self.data)
}
}
// Error3:
impl<'a, F> Closure<F> where F: Fn(&'a (u8, u16)) -> &'a u8,
{
fn call(& self) -> & u8 {
// 编译器自动为 &self 添加 liefitime 如 '1: method was supposed to return data with
// lifetime `'1` but it is returning data with lifetime `'a`
(self.func)(&self.data)
}
}
// Error4: 可以编译过,但是要求 Closure 的 liefitime 和传入的 Fn 的参数 lifetime 一致,不符合预期语
// 义(Fn 的函数有自己独立的 lifetime,和 Closure 对象 lifetime 无关)。
impl<'a, F> Closure<F> where F: Fn(&'a (u8, u16)) -> &'a u8,
{
fn call(&'a self) -> &'a u8 {
(self.func)(&self.data)
}
}
// OK:HRTB
// 1. 泛型参数中没有 'a lifetitme
// 2. 在 F 的 Bound 中使用 for <'a> 来声明 'a lifetime,这里 for <'a> 表示对于任意 lifetime 'a, Fn 都满足
impl<F> Closure<F> where F: for <'a> Fn(&'a (u8, u16)) -> &'a u8,
{
fn call<'a>(&'a self) -> &'a u8 {
// 'a 和上面的 for <'a> 没有任何关系,是 call() 方法自己的lifetime。由于编译器会自动加
// lifetime,所以可以不指定 'a 如:fn call(&self) -> &u8
(self.func)(&self.data)
}
}
for <'a> Fn 表示 Fn 满足任意 'a liftime ,所以使用 HRTB 声明的 lifetime 是其它任意 lifetime 的 =子类型
= ,该 HRTB Fn 可以赋值给其它任意 lifetime 声明的变量。另外,HRTB 也可以作为 fn 指针的 lifetime 声明:
// 使用闭包
fn use_closure<F>(f: F) where F: for<'a> Fn(&'a str) -> &'a str,
{
let s = "example";
let result = f(s);
println!("{}", result);
}
// 使用函数指针
fn use_fn_ptr(f: for<'a> fn(&'a str) -> &'a str) {
let s = "example";
let result = f(s);
println!("{}", result);
}
HRTB 有两种等效语法:
where F: for<'a> Fn(&'a (u8, u16)) -> &'a u8,
// 等效为
where for <'a> F: Fn(&'a (u8, u16)) -> &'a u8,
16.2 ‘static #
‘static 是 Rust 内置的特殊 lifetime anno,在 &str 和函数泛型参数的 Bound 中广泛使用。
&‘static 表示借用的对象的声明周期和程序的执行时间一样长,也就是在程序运行期间一直存在的对象。‘static
值在程序整个运行期间有效 指的是在 main 函数返回还有效 ,例如全局的 const 变量,全局 static 变量,字符串字面量等,它们都保存在程序二进制的 read-only 部分。
let s: &'static str = "hello world";
fn generic<T>(x: T) where T: 'static {}
fn main() {
let v: &'static string = "hello";
need_static(v);
println!("Success!")
}
fn need_static(r : &'static str) {
assert_eq!(r, "hello");
}
‘static lifetime 可以被 coerced 到一个更短的生命周期:
// Make a constant with `'static` lifetime.
static NUM: i32 = 18;
// Returns a reference to `NUM` where its `'static` lifetime is coerced to that of the input
// argument.
fn coerce_static<'a>(_: &'a i32) -> &'a i32 {
&NUM
}
fn main() {
{
// Make an integer to use for `coerce_static`:
let lifetime_num = 9;
// Coerce `NUM` to lifetime of `lifetime_num`:
let coerced_static = coerce_static(&lifetime_num);
println!("coerced_static: {}", coerced_static);
}
println!("NUM: {} stays accessible!", NUM);
}
‘static 的两种解释:
- Give me an owned value
- Give me a reference that’s valid for the entire duration of the program
对象赋值、闭包 move 等语义下, 接收方 owned 传入的对象值 ,这时该接收方也实现了 ‘static,如 Box<dyn
MyTrait + ‘static + Send>。所以 ‘static 只有在引用场景下,才代表引用存在于整个程序运行期间。
use std::fmt::Debug;
// 函数 hold T 值,所以 T 的 Bound 会隐式的自动会加 'static 并自动满足。
fn print_it<T: Debug + 'static>(input: T) {
println!("'static value passed in is: {:?}", input);
}
// 函数 hold input 值,所以 input 的 Bound 会隐式的自动会加 'static 并自动满足。
fn print_it1(input: impl Debug + 'static) {
println!("'static value passed in is: {:?}", input);
}
// input 是 ref,借用的 T 值必须是 'static 即延续到整个程序的生命周期。
fn print_it2<T: Debug + 'static>(input: &T) {
println!("'static value passed in is: {:?}", input);
}
fn main() {
// i is owned and contains no references, thus it's 'static:
let i = 5;
print_it(i);
// oops, &i only has the lifetime defined by the scope of main(), so it's not 'static:
print_it(&i); // `i` does not live long enough
print_it1(&i); // `i` does not live long enough
// but this one WORKS !
print_it2(&i);
}
16.3 lifetime elision #
Rust borrow checker 使用 lifetime annotation 来检查所有 borrow,确保所有的 borrow 都是有效的。一般情况下,一个变量的 lifetime 开始于它创建,结束于它被销毁。
在大部分情况下,由于有一些 elision rule,用户不需要显式指定 borrow 变量的 lifetime annotation。
- 非引用类型的参数,由于是 Copy 或 Move 对应 ownership,故不需要 lifetime 定义。
fn first_word(s: &str) -> &str {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[0..i];
}
}
&s[..]
}
Rust 编译器 :
- The first rule 针对函数的输入参数:is that the compiler
assigns a lifetime parameter to each parameter that’s a reference. In other words, a function with one parameter gets one lifetime parameter: fn foo<‘a>(x: &‘a i32); a function with two parameters gets two separate lifetime parameters: fn foo<‘a, ‘b>(x: &‘a i32, y: &‘b i32); and so on.
struct S<'a, 'b> {
x: &'a i32,
y: &'b i32
}
fn sum_r_xy(r: &i32, s: S) -> i32 {
r + s.x + s.y
}
// 函数签名等效为:
fn sum_r_xy<'a, 'b, 'c>(r: &'a i32, s: S<'b, 'c>) -> i32
- The second rule 针对函数的输出参数:is that, if there is
exactly oneinput lifetime parameter, that lifetime is assigned toall outputlifetime parameters: fn foo<‘a>(x: &‘a i32) -> &‘a i32.
fn first_third(point: &[i32; 3]) -> (&i32, &i32) {
(&point[0], &point[2])
}
// 等效为
fn first_third<'a>(point: &'a [i32; 3]) -> (&'a i32, &'a i32)
- The third rule 针对方法:is that, if there are multiple input lifetime parameters, but one of
them is
&self or &mut selfbecause this is a method, the lifetime of self is assigned toall output lifetime parameters. This third rule makes methods much nicer to read and write because fewer symbols are necessary. 所以,对于方法函数,一般不需要指定输入&输出参数的声明周期。
struct StringTable {
elements: Vec<String>,
}
impl StringTable {
fn find_by_prefix(&self, prefix: &str) -> Option<&String> {
for i in 0 .. self.elements.len() {
if self.elements[i].starts_with(prefix) {
return Some(&self.elements[i]); // [i] 返回对象本身,这里需要通过 & 获得它的引用
}
}
None
}
}
// 等效为
fn find_by_prefix<'a, 'b>(&'a self, prefix: &'b str) -> Option<&'a String>
如果经过上面 elision rule,还有引用参数的 lifetime 不明确, Rust 拒绝编译 :
fn first_word(s: &str) -> &str { // 正确
// 编译器等效为
fn first_word<'a>(s: &'a str) -> &'a str {
fn longest(x: &str, y: &str) -> &str { // 错误
// 经过 rule 后:
fn longest<'a, 'b>(x: &'a str, y: &'b str) -> &str { // 输出引用 lifetime 不明确,报错
// Cannot infer, because there are no parameters to infer from.
fn get_str() -> &str; // ILLEGAL
通过给类型指定 ‘_ lifetime 可以强制使用上面的 lifetime elision 规则,特别是位于 path 中的 lifetime,优选 ‘_:
fn new1(buf: &mut [u8]) -> Thing<'_>; // elided - preferred
fn new2(buf: &mut [u8]) -> Thing; // elided
fn new3<'a>(buf: &'a mut [u8]) -> Thing<'a>; // expanded
其他函数参数或结果中可以消除 lifetime 的情况:
fn requires_t_outlives_a<'a, T>(x: &'a T) {} // 隐式:T: 'a
fn requires_t_outlives_a_not_implied<'a, T: 'a>() {}
fn requires_t_outlives_a<'a, T>(x: &'a T) {
// This compiles, because `T: 'a` is implied by the reference type `&'a T`.
requires_t_outlives_a_not_implied::<'a, T>();
}
fn not_implied<'a, T>() {
// This errors, because `T: 'a` is not implied by the function signature.
requires_t_outlives_a_not_implied::<'a, T>();
}
// 只有 lifetime 会被隐式 bound,trait 还是需要显式指定的。
use std::fmt::Debug;
struct IsDebug<T: Debug>(T);
// error[E0277]: `T` doesn't implement `Debug`
fn doesnt_specify_t_debug<T>(x: IsDebug<T>) {}
trait object 有特殊的 lifetime bound。参考: 20.4
- Box<dyn Trait> 默认等效于
Box<dyn Trait + 'static>, 因为实际将实现 Trait 对象的所有权转移到了Box 中; - &‘x Box<dyn Trait> 等效于 &‘x Box<dyn Trait + ‘static>, ‘x 可能是编译器自动加的, 所以即使没有明确指定, &Box<dyn Trait> 等效于 &Box<dyn Trait + ‘static>;
- &‘r Ref<‘q, dyn Trait> 等效于 &‘r Ref<‘q, dyn Trait+‘q>;
17 flow control #
Rust 控制流结构包括: if 表达式、match 表达式和循环(loop、while、for)。
Rust 是表达式语言,程序 block 由 分号 结尾的 statement 来组成。如果 expression 不以分号结尾,则它作为 block 的返回值,否则返回 unit type 值 ();
fn main() {
let x = 5u32;
let y = {
let x_squared = x * x;
let x_cube = x_squared * x;
// This expression will be assigned to `y`
x_cube + x_squared + x
};
let z = {
// The semicolon suppresses this expression and `()` is assigned to `z`
2 * x;
};
println!("x is {:?}", x);
println!("y is {:?}", y);
println!("z is {:?}", z);
}
if-else,if-let,while-let,match,loop,block 等都是表达式,可以用于变量赋值:
- if/while 表达式的结果必须是 bool 类型。
fn main() {
let n = 5;
let big_n = if n < 10 && n > -10 {
println!(", and is a small number, increase ten-fold");
10 * n
} else {
println!(", and is a big number, halve the number");
n / 2
}; // 在 let 变量赋值时,} 右边的分号不能省!
println!("{} -> {}", n, big_n);
}
let mut counter = 0;
let result = loop {
counter += 1;
if counter == 10 {
break 10; // loop break 可以返回值。
}
};
循环支持嵌套,可以使用 break ’label 来跳出循环:label 的格式和 lifetime 一样,都是 ’label 格式;’label必须位于 loop/for/while 或 { 之前:
fn main() {
'outer2: { // lable 可以位于 block { 之前
let mut count = 0;
'outer: loop {
'inner1: loop {
if count >= 20 {
// This would break only the inner1 loop
break 'inner1; // `break` is also works.
}
count += 2;
}
count += 5;
'inner2: loop {
if count >= 30 {
// This breaks the outer loop
break 'outer;
}
// This will continue the outer loop
continue 'outer;
}
}
break 'outer2;
}
println!("Success!");
}
break 还可以返回值:
let answer = loop {
if let Some(line) = next_line() {
if line.starts_with("answer: ") {
break line; }
} else {
break "answer: nothing";
}
};
if-let 和 while-let 支持模式匹配语法: if/while let pattern = expression {}:
- pattern 元素的数量必须与 expression 结果的元素数量一致;
- pattern 中变量有效 scope 是 expression 右边的 block;
fn main() {
if let (a, 1) = (2, 4) { // pattern 的元素数量必须与右边一致,结构后的变量 scope 是表达式右边的 block;
println!("a: {a}")
} else { // if let 不匹配的情况
println!("not match!")
}
}
// if-let 和 if 可以混合使用
let x = Some(3);
let a = if let Some(1) = x {
1
} else if x == Some(2) {
2
} else if let Some(y) = x {
y
} else {
-1
};
assert_eq!(a, 3);
// 多个 pattern 可以使用 | 分割
enum E {
X(u8),
Y(u8),
Z(u8),
}
let v = E::Y(12);
if let E::X(n) | E::Y(n) = v {
assert_eq!(n, 12);
}
match/if-let/while-let 绑定的变量只是表达式右边的 block 内部有效,一般还需要 outer let 表达式来返回值。Rust 1.65(rustc –edition=2021)开始支持 let-else 语法,let-else 的变量 scope 是所在 block:
- 注意:pattern 也用于赋值析构,这时变量 scope 也是所在 block:
use std::str::FromStr;
fn get_count_item(s: &str) -> (u64, &str) {
let mut it = s.split(' ');
// 如果匹配,count_str/item 可以在函数中使用。
let (Some(count_str), Some(item)) = (it.next(), it.next()) else {
panic!("Can't segment count item pair: '{s}'");
};
let Ok(count) = u64::from_str(count_str) else {
panic!("Can't parse integer: '{count_str}'");
};
(count, item)
}
fn main() {
assert_eq!(get_count_item("3 chairs"), (3, "chairs"));
}
// 对比,使用 match/if-let 的例子
let (count_str, item) = match (it.next(), it.next()) {
// count_str/item 只在内部有效
(Some(count_str), Some(item)) => (count_str, item),
_ => panic!("Can't segment count item pair: '{s}'"),
};
// count 只在下面匹配的 block 内部有效
let count = if let Ok(count) = u64::from_str(count_str) {
count
} else {
panic!("Can't parse integer: '{count_str}'");
};
// 变量析构
// `Pair` owns resources: two heap allocated integers
struct Pair(Box<i32>, Box<i32>);
impl Pair {
// This method "consumes" the resources of the caller object `self` desugars to `self: Self`
fn destroy(self) {
// Destructure `self`
// self 的两个 Box 被转移到 first 和 second 变量,他们的 scope 是 destroy 函数体。
let Pair(first, second) = self;
println!("Destroying Pair({}, {})", first, second);
// `first` and `second` go out of scope and get freed
}
}
while 用于 true/false 循环:
fn main() {
// A counter variable
let mut n = 1;
// Loop while `n` is less than 101
while n < 101 {
if n % 15 == 0 {
println!("fizzbuzz");
} else if n % 3 == 0 {
println!("fizz");
} else if n % 5 == 0 {
println!("buzz");
} else {
println!("{}", n);
}
// Increment counter
n += 1;
}
}
while-let 主要用于消除 loop-match 循环模式,while-let 没有 else 子句:
while let _ = 5 {
println!("Irrefutable patterns are always true");
break;
}
// Make `optional` of type `Option<i32>`
let mut optional = Some(0);
// Repeatedly try this test.
loop {
match optional {
// If `optional` destructures, evaluate the block.
Some(i) => {
if i > 9 {
println!("Greater than 9, quit!");
optional = None;
} else {
println!("`i` is `{:?}`. Try again.", i);
optional = Some(i + 1);
}
// ^ Requires 3 indentations!
},
// Quit the loop when the destructure fails:
_ => { break; }
// ^ Why should this be required? There must be a better way!
}
}
// 使用 while-let 语句
// Make `optional` of type `Option<i32>`
let mut optional = Some(0);
// This reads: "while `let` destructures `optional` into `Some(i)`, evaluate the block (`{}`). Else
// `break`.
while let Some(i) = optional {
if i > 9 {
println!("Greater than 9, quit!");
optional = None;
} else {
println!("`i` is `{:?}`. Try again.", i);
optional = Some(i + 1);
}
// ^ Less rightward drift and doesn't require explicitly handling the failing case.
}
// ^ `if let` had additional optional `else`/`else if` clauses. `while let` does not have these.
for 专用于迭代(for-in),有三种迭代方式:
- for item in collect; // item 为元素值;
- for item in &collect; // item 为元素值引用 &T;
- for item in &mut collect; // item 为元素值可变引用 &mut T;
a..b, a..=b, a.. 都是 RangeXX 语法糖, 可以直接用于 index 操作和 for 迭代:
- a 和 b 也可以是表达式。
fn main() {
for n in 1..=100 {
if n == 100 {
panic!("NEVER LET THIS RUN")
}
}
println!("Success!");
// 使用范围和 `for` 循环进行倒计时
for number in (1..4).rev() {
println!("{}!", number);
}
}
// 范围可以是表达式
let end = 5;
let mut sum = 0;
for i in 1..(end + 1) {
sum += i;
}
注意, 对于 array 的 into_iter() , 2021 和以前的版本有所变化:
- 在 2021 以前版本, 如 2018, for i in array.into_iter() 等效为 for i (&array).into_iter(), 所以迭代产生的 i 为数组元素的引用 &T;
- 2021 版本以后, for i in array.into_iter() 迭代产生的值为数组元素本身:
fn main() {
let a = [4, 3, 2, 1];
// 2021 及以后 v 类型是元素本身, 以前版本是 &T;
for (i, v) in a.into_iter().enumerate() {
println!("{i} {v}");
}
}
? 运算法可以用于 Result/Option, 它自动调用 From trait 来实现类型转换.
18 match pattern #
match expression {} 结果是一个表达式,可以用于变量赋值(值类型必须相同):
- 子句格式: pattern => {statements;}, 如果是单条语句则可以省略大括号,如 pattern => expression,
- match block 中各子句用逗号分割;(函数和闭包的返回值用 -> 分割;)
- expression 可以返回复杂类型,如 tuple、struct 等,从而实现多个返回值的 pattern 匹配;
enum Direction {
East,
West,
North,
South,
}
fn main() {
let dire = Direction::South;
let result = match dire { // match express-表达式
Direction::East => println!("East"), // println!() 返回 ()
_ => {
Ok(1); // 也返回 ()
}
}; // let 赋值的结尾分号不能省!
println!("{result}")
}
// pattern 引入了新的变量,可能 shadow 以前同名的变量。
fn main() {
let age = Some(30);
if let Some(age) = age {
// Create a new variable with the same name as previous `age`
assert_eq!(age, 30);
} // The new variable `age` goes out of scope here
match age {
// Match can also introduce a new shadowed variable
Some(age) => println!("age is a new variable, it's value is {}",age),
_ => ()
}
}
let mut setting_value = Some(5);
let new_setting_value = Some(10);
match (setting_value, new_setting_value) {
(Some(_), Some(_)) => {
println!("Can't overwrite an existing customized value");
}
_ => {
setting_value = new_setting_value;
}
}
println!("setting is {:?}", setting_value);
matches!() 宏(注意:match 是关键字)将 express value 和 pattern 进行匹配,结果为 true/false,可用于表达式或条件判断:
let foo = 'f';
assert!(matches!(foo, 'A'..='Z' | 'a'..='z'));
let bar = Some(4);
assert!(matches!(bar, Some(x) if x > 2));
match pattern 支持的语法:
- 字面量:如 100,字符串, bool,char;
- 必须是 inclusive range:如 0..=100, ‘a’..=‘z’;
- | 来分割多个 pattern;
- _ 来匹配任意值;_ 是一个特殊的模式,它匹配任何值,但不绑定到变量。
- @ 来匹配并定义一个变量,如 [email protected], y@(1|2|3), y@.. 匹配后,y 是一个包含了匹配值的变量;
- 枚举:如 Some(value), None, Ok(value), Err(err);
- 变量:如 name, mut name, ref name, ref mut name, 这里的 ref/mut 是用来修饰生成的变量 name 的类型;
- tuple:(key, value), (r, g, b), (r, g, 12); // 12 为字面量匹配条件;
- array:[a, b, c], [a, b, 1] // 1 为字面量匹配条件;
- slice:[a, b], [a, _, b], [a, .., b]
- struct:必须列出每一个 field,可以使用 .. 来忽略部分 field;
- 匹配引用:&value, &(k, v); // & 用于匹配表达式结果, value/k/v 都代表解了一层引用后的值;
- guard expression:4|5|6 if x < 2,表达式是针对整个 pattern 的,等效于 (4|5|6) if x < 2
let x = 9;
let message = match x {
0 | 1 => "not many",
2 ..= 9 => "a few",
_ => "lots"
};
// Demonstration of pattern match order.
struct S(i32, i32);
match S(1, 2) {
// _ 用在 slice/array/tuple 中可以用于忽略指定位置的元素
S(z @ 1, _) | S(_, z @ 2) => assert_eq!(z, 1),
_ => panic!(),
}
let p = Point { x: 0, y: 7 };
match p {
Point { x, y: 0 } => println!("On the x axis at {x}"),
Point { x: 0, y } => println!("On the y axis at {y}"),
Point { x, y } => {
println!("On neither axis: ({x}, {y})");
}
}
enum Message {
Quit,
Move { x: i32, y: i32 },
Write(String),
ChangeColor(i32, i32, i32),
}
fn main() {
let msg = Message::ChangeColor(0, 160, 255);
match msg {
Message::Quit => {
println!("The Quit variant has no data to destructure.");
}
// 对于有成员的 variant,必须列出成员。
Message::Move { x, y } => {
println!("Move in the x direction {x} and in the y direction {y}");
}
Message::Write(text) => {
println!("Text message: {text}");
}
Message::ChangeColor(r, g, b) => {
println!("Change the color to red {r}, green {g}, and blue {b}",)
}
}
}
// 解构复杂的嵌套数据解构
enum Color {
Rgb(i32, i32, i32),
Hsv(i32, i32, i32),
}
enum Message {
Quit,
Move { x: i32, y: i32 },
Write(String),
ChangeColor(Color),
}
fn main() {
let msg = Message::ChangeColor(Color::Hsv(0, 160, 255));
match msg {
// 多级解构
Message::ChangeColor(Color::Rgb(r, g, b)) => {
println!("Change color to red {r}, green {g}, and blue {b}");
}
Message::ChangeColor(Color::Hsv(h, s, v)) => {
println!("Change color to hue {h}, saturation {s}, value {v}")
}
_ => (), // 其他 arm 都返回 (), 所以缺省 arm 也需要返回 () 类型。
}
}
pattern .. 的用法:
- 对于 array/tuple/slice 元素,可以使用 .. 来省略任意数量部分的元素;
- 对于 struct,使用 .. 来省略未列出的 field;
- 只能使用一次 ..;
- Vec 需要转换为 slice 后才能解构;
struct Point {
x: i32,
y: i32,
}
fn main() {
let p = Point { x: 3, y: 10};
match p {
// struct pattern,y 的值用来做匹配判断
Point { x, y: 0 } => println!("On the x axis at {}", x),
// y: yy@(xx) 是将 y 与 xx 匹配, 如果满足, 匹配的值被设置给变量 yy
Point { x: 0..=5, y: yy@ (10 | 20 | 30) } => println!("On the y axis at {}", yy),
Point { x, y } => println!("On neither axis: ({}, {})", x, y),
}
struct Foo {
x: (u32, u32),
y: u32,
}
let foo = Foo { x: (1, 2), y: 3 };
match foo {
Foo { x: (1, b), y } => println!("First of x is 1, b = {}, y = {} ", b, y),
// you can destructure structs and rename the variables, the order is not important
Foo { y: 2, x: i } => println!("y is 2, i = {:?}", i),
// 忽略剩余的部分
Foo { y, .. } => println!("y = {}, we don't care about x", y),
// this will give an error: pattern does not mention field `x`
//Foo { y } => println!("y = {}", y),
}
let faa = Foo { x: (1, 2), y: 3 };
// You do not need a match block to destructure structs:
let Foo { x : x0, y: y0 } = faa;
println!("Outside: x0 = {x0:?}, y0 = {y0}");
// Destructuring works with nested structs as well:
struct Bar {
foo: Foo,
}
let bar = Bar { foo: faa };
let Bar { foo: Foo { x: nested_x, y: nested_y } } = bar;
println!("Nested: nested_x = {nested_x:?}, nested_y = {nested_y:?}");
}
// match guard
let num = Some(4);
let split = 5;
match num {
// if match guard
Some(x) if num < split => assert!(x < split),
Some(x) => assert!(x >= split),
None => (),
}
// (xx) 和 [xx] 也可以作为 pattern,后者可以匹配 Array/Vec/Slice
let numbers = (2, 4, 8, 16, 32, 64, 128, 256, 512, 1024, 2048);
match numbers {
// ERROR: pattern 中最多只能包含一个 ..
// (first, .., 16, .., 1024, last) => {
// assert_eq!(first, 2);
// assert_eq!(last, 2048);
// }
// OK
(first, .., 1024, last) => {
assert_eq!(first, 2);
assert_eq!(last, 2048);
}
// OK
(first, .., last) => {
assert_eq!(first, 2);
assert_eq!(last, 2048);
}
}
// array/slice 也可以解构,使用 [xxx] pattern:
fn main() {
// Try changing the values in the array, or make it a slice!
let array = [1, -2, 6];
// array 和 slice 可以直接解构
match array {
// Binds the second and the third elements to the respective variables
[0, second, third] => println!("array[0] = 0, array[1] = {}, array[2] = {}", second, third),
// Single values can be ignored with _
[1, _, third] => println!( "array[0] = 1, array[2] = {} and array[1] was ignored", third ),
// You can also bind some and ignore the rest
[-1, second, ..] => println!("array[0] = -1, array[1] = {} and all the other ones were ignored", second ),
// The code below would not compile
// [-1, second] => ...
// Or store them in another array/slice (the type depends on that of the value that is being
// matched against)
[3, second, tail @ ..] => println!( // 匹配后,tail 是一个包含匹配值的变量。
"array[0] = 3, array[1] = {} and the other elements were {:?}",
second, tail
),
// Combining these patterns, we can, for example, bind the first and last values, and store
// the rest of them in a single array
[first, middle@ .., last] => println!("array[0] = {}, middle = {:?}, array[2] = {}", first, middle, last),
}
}
// Vec 可以先转换为 slice, 再解构.
let v = vec![1, 2, 3];
match v[..] {
[a, b] => { /* this arm will not apply because the length doesn't match */ }
[a, b, c] => { /* this arm will apply */ }
_ => { /* this wildcard is required, since the length is not known statically */ }
};
// 在 pattern 中 & 不能用于 field value:
if let Person { name: &person_name, age: 18..=150 } = value { } // 错误
if let Person {name: ref person_name, age: 18..=150 } = value { } // 正确
// & 和 * 匹配
fn main() {
let reference = &4;
match reference {
// If `reference` is pattern matched against `&val`, it results in a comparison like:
// `&i32`
// `&val`
// ^ We see that if the matching `&`s are dropped, then the `i32`
// should be assigned to `val`.
&val => println!("Got a value via destructuring: {:?}", val),
}
// To avoid the `&`, you dereference before matching.
match *reference {
val => println!("Got a value via dereferencing: {:?}", val),
}
// What if you don't start with a reference? `reference` was a `&` because the right side was
// already a reference. This is not a reference because the right side is not one.
let _not_a_reference = 3;
// Rust provides `ref` for exactly this purpose. It modifies the assignment so that a reference
// is created for the element; this reference is assigned.
let ref _is_a_reference = 3;
// Accordingly, by defining 2 values without references, references can be retrieved via `ref`
// and `ref mut`.
let value = 5;
let mut mut_value = 6;
// Use `ref` keyword to create a reference.
match value {
ref r => println!("Got a reference to a value: {:?}", r),
}
// Use `ref mut` similarly.
match mut_value {
ref mut m => {
// Got a reference. Gotta dereference it before we can add anything to it.
*m += 10;
println!("We added 10. `mut_value`: {:?}", m);
},
}
}
使用 pattern 解构的场景:
- let 赋值时,tuple/slice/struct/enum 等复杂数据类型值的
赋值解构场景: - 表达式:if-let,while-let,for,match
- 函数或方法或闭包的参数,它们在传参时其实是赋值解构。
赋值析构的变量 scope 是所在 block,对于被析构的对象,新的变量 by-ref/by-mov/by-copy 对应的值。
- if let/while let/match/match! 匹配场景是
可失败模式,但是变量赋值解构(let)、函数参数解构、for 循环解构是不可失败模式。
#[derive(PartialEq, PartialOrd)]
struct Centimeters(f64);
// `Inches`, a tuple struct that can be printed
#[derive(Debug)]
struct Inches(i32);
impl Inches {
fn to_centimeters(&self) -> Centimeters {
let &Inches(inches) = self; // & 用于匹配应用类型,这样 inches 是 i32 值。
Centimeters(inches as f64 * 2.54)
}
}
struct Point {
x: i32,
y: i32,
}
fn main() {
let p = Point { x: 0, y: 7 };
let Point { x: a, y: b } = p;
assert_eq!(0, a);
assert_eq!(7, b);
let p = Point { x: 0, y: 7 };
let Point { x, y } = p;
assert_eq!(0, x);
assert_eq!(7, y);
}
let ((feet, inches), Point { x, y }) = ((3, 10), Point { x: 3, y: -10 });
// 函数参数中使用 pattern 进行赋值解构
fn print_coordinates(&(x, y): &(i32, i32)) {
println!("Current location: ({}, {})", x, y);
}
fn main() {
let point = (3, 5);
print_coordinates(&point);
}
fn foo(_: i32, y: i32) {
println!("This code only uses the y parameter: {}", y);
}
fn main() {
foo(3, 4);
}
// 不可失败匹配模式, let 解构后的变量后续可以直接使用。
let ((feet, inches), Point {x, y}) = ((3, 10), Point { x: 3, y: -10 });
let Some(caps) = re.captures(hay) else { return };
assert_eq!("J", &caps[1]);
在进行解构时,_ 表达式用于占位,表示匹配所有。当位于 array/tuple/slice 中表示忽略指定位置的元素。
let p = (1, 2);
let mut a = 0;
(_, a) = p;
let mut setting_value = Some(5);
let new_setting_value = Some(10);
match (setting_value, new_setting_value) {
(Some(_), Some(_)) => {
println!("Can't overwrite an existing customized value");
}
_ => {
setting_value = new_setting_value;
}
}
println!("setting is {:?}", setting_value);
模式匹配中, & 引用匹配 reference, 而 ref/ref mut 不是用来匹配而是表示绑定的变量类型.
- 变量先匹配再绑定, 绑定时默认是 copy 或 move, 通过指定 ref 或 ref mut 表示变量是引用或可变引用类型;
match struct_value {
Struct{a: 10, b: 'X', c: false} => (),
Struct{a: 10, b: 'X', ref c} => (),
Struct{a: 10, b: 'X', ref mut c} => (),
Struct{a: 10, b: 'X', c: _} => (),
Struct{a: _, b: _, c: _} => (),
}
match a {
None => (),
Some(value) => (), // value 被 Copy 或 Moved
}
match a {
None => (),
Some(ref value) => (), // value 是引用类型
}
// `name` is moved from person and `age` referenced
let Person { name, ref age } = person;
注意:
- 对于 enum 类型是在枚举 variant 值外部而非内部类匹配 & 或 &mut 的:
- 对于 tuple 类型, 也是在 tuple 外部匹配 & 或 &mut 的:
- &/&mut 用来匹配共享引用和可变引用, && 或 &&mut 来匹配间接引用: Reference patterns dereference the pointers that are being matched and, thus, borrow them.
let x: &Option<i32> = &Some(3);
// OK: 等效为 Some(ref y), y 的类型是 &i32
if let Some(y) = x {
}
// OK: 在 variant 外指定 &, y 的类型是 i32, y 类型必须实现 Copy
if let &Some(y) = x {
}
// ERROR: 不能在 variant 内指定 &,expected `i32`, found `&_`
if let Some(&y) = x {
}
// 另一个例子
enum MyEnum {
A { name: String, x: u8 },
B { name: String },
}
fn a_to_b(e: &mut MyEnum) {
if let MyEnum::A {
name, // &mut String 类型
x: 0,
} = e
{
*e = MyEnum::B {
// take 参数类型是 &mut T, 而 name 类型是 &mut String 故满足。
name: std::mem::take(name),
}
}
// OK: name 是 String 类型
if let &mut MyEnum::A {
name,
x: 0,
} = e
}
fn main() {
let (a, b ) = &(1, 2); // a 和 b 都是 &i32 类型
println!("Results: {a} {b}");
let &(c, d ) = &(1, 2); // c 和 d 都是 i32 类型, c/d 都必须实现 Copy
println!("Results: {c} {d}");
let (&c, d ) = &(1, 2); // Error
let (ref c, d ) = &(1, 2); // OK
}
let int_reference = &3; // Rust 字面量也支持引用
let a = match *int_reference { 0 => "zero", _ => "some" };
let b = match int_reference { &0 => "zero", _ => "some" }; // int_reference 是引用类型
assert_eq!(a, b);
let int_reference = &3;
match int_reference {
&(0..=5) => (),
_ => (),
}
对于实现了 Deref<Target=U> 的类型 T 值, &*T 可以返回 &U:
- let (a, b) = &v; 这时 a 和 b 都是引用类型, 正确!
- let &(a, b) = &v; 这时 a 和 b 都是 move 语义.
Rust 不允许从引用类型(不管是共享还是可变)值 move 其中的内容, 所以如果对应值没有实现 Copy 则出错.
use std::sync::{Arc, Mutex, Condvar};
use std::thread;
let pair = Arc::new((Mutex::new(false), Condvar::new()));
let pair2 = Arc::clone(&pair);
// Inside of our lock, spawn a new thread, and then wait for it to start.
thread::spawn(move|| {
// 这里 &*pair2 返回的是 &(Mutex::new(false), Condvar::new()), 赋值解构后, lock 是 &Mutex, cvar
// 是 &Convar不能使用 let &(lock, cvar) = &*pair2; 这会导致 pair2 中的值发生了移动( lock 是
// Mutex, cvar 是 Convar), 由于 pair2 和 pair 是共享底层的对象, 所以是不允许移动的.
let (lock, cvar) = &*pair2;
let mut started = lock.lock().unwrap();
*started = true;
// We notify the condvar that the value has changed.
cvar.notify_one();
});
// Wait for the thread to start up.
let (lock, cvar) = &*pair;
let mut started = lock.lock().unwrap();
while !*started {
started = cvar.wait(started).unwrap();
}
pattern match 可能会产生 partial move:
- struct/enum 的 field 可以被 partial move,但是 Vec/Array 等容器不能;
- struct/enum 被 partial move 的字段后续不能再访问,同时 struct 整体也不能被访问, 但是未被 partial move的字段还可以访问;
// https://practice.course.rs/ownership/ownership.html
fn main() {
#[derive(Debug)]
struct Person {
name: String,
age: Box<u8>,
}
let person = Person {
name: String::from("Alice"),
age: Box::new(20),
};
// `name` is moved out of person, but `age` is referenced
let Person { name, ref age } = person;
println!("The person's age is {}", age);
println!("The person's name is {}", name);
// Error! borrow of partially moved value: `person` partial move occurs
//println!("The person struct is {:?}", person);
// `person` cannot be used but `person.age` can be used as it is not moved
println!("The person's age from person struct is {}", person.age);
}
// `name` is moved from person and `age` referenced
let Person { name, ref age } = person;
Vec/Array 等容器不支持 partial move(如果元素实现了 Copy,则不是 move),解决办法:
- 元素 clone();
- 如果能获得元素的 &mut 引用,这可以使用 std::mem:take()/std:mem::replace() 来拥有对应元素;
Vec 不支持解构,需要转换为 slice 后,才能解构;
fn main() {
let mut data = vec!["abc".to_string()];
// let e = data[0]; // move occurs because value has type `String`, which does not implement the `Copy` trait
// Vec 的元素不能被解构,需要转换为 &[T] 后才能解构。
//let [a] = data; // pattern cannot match with input type `Vec<String>`
// if let [a] = data[..] { // move occurs because `a` has type `String`, which does not implement the `Copy` trait
// println!("Results: {a:?}");
// }
// if let &[a] = &data[..] { // move occurs because `a` has type `String`, which does not implement the `Copy` trait
// println!("Results: {a:?}");
// }
if let [a] = &data[..] { // OK: a 是 &String 类型, 引用的是 data 中的元素。
println!("Results: {a:?}");
}
}
19 function/method/closure #
Rust 函数是具有特定名称和参数列表的代码块,可用于执行一个任务或计算一个值。函数定义的顺序没有关系。
fn function_name(parameter1: Type1, parameter2: Type2, ...) -> ReturnType { // 只能有一个返回值类型
// 函数体,包含执行的代码
}
// 无参数、无返回值的函数
fn greet_world() {
println!("Hello, world!");
}
// 接受一个参数、无返回值的函数
fn greet(name: &str) {
println!("Hello, {}!", name);
}
// 接受两个参数、有返回值的函数
fn add(a: i32, b: i32) -> i32 {
a + b // 表达式的值将作为函数的返回值
}
函数的标准语法如下:
- FunctionQualifiers:fn 前函数限定符:const,async,unsafe,extern;
- self 参数支持两种格式:
- ShorthandSelf: (& | & Lifetime)? mut? self, 例如 self, mut self, &self, &mut self, &‘a mut self;
- TypedSelf: mut? self : Type, 例如 self: Type, mut self: Type;
- 该格式不支持借用,传入的是 self 或 mut self;
函数语法格式:
# https://doc.rust-lang.org/reference/items/functions.html
Syntax
Function :
FunctionQualifiers fn IDENTIFIER GenericParams?
( FunctionParameters? )
FunctionReturnType? WhereClause?
( BlockExpression | ; )
FunctionQualifiers :
const? async1? unsafe? (extern Abi?)?
Abi :
STRING_LITERAL | RAW_STRING_LITERAL
FunctionParameters :
SelfParam ,?
| (SelfParam ,)? FunctionParam (, FunctionParam)* ,?
SelfParam :
OuterAttribute* ( ShorthandSelf | TypedSelf )
ShorthandSelf :
(& | & Lifetime)? mut? self
TypedSelf :
mut? self : Type
FunctionParam :
OuterAttribute* ( FunctionParamPattern | ... | Type 2 )
FunctionParamPattern :
PatternNoTopAlt : ( Type | ... )
FunctionReturnType :
-> Type
1 The async qualifier is not allowed in the 2015 edition.
2 Function parameters with only a type are only allowed in an associated function of a trait item in the 2015 edition.
函数的泛型参数 Generic parameters 定义如下:
- 泛型参数有三种类型:lifetime,type,const;
- lifetime 示例:
- ‘a
- ‘a: ‘b + ‘c
- ‘a: ‘static
- ‘a: ‘_
- type 示例:
- T
- T: ‘a + Trait
- T = MyType
- T: ‘a + TraitA + for <‘a> Fn(&‘a i32) -> i32
- T: for <‘a> Fn(&‘a i32) -> i32 + ‘b + TraitA
- T: (for <‘a> Fn(&‘a i32) -> i32) + ‘b + TraitA
- T: ‘a + TraitA + std::ops::Index<std::ops::Range<usize>>
Syntax
GenericParams :
< >
| < (GenericParam ,)* GenericParam ,? >
GenericParam :
OuterAttribute* ( LifetimeParam | TypeParam | ConstParam )
LifetimeParam :
LIFETIME_OR_LABEL ( : LifetimeBounds )?
TypeParam :
IDENTIFIER( : TypeParamBounds? )? ( = Type )?
ConstParam:
const IDENTIFIER : Type ( = Block | IDENTIFIER | -?LITERAL )?
TypeParamBounds :
TypeParamBound ( + TypeParamBound )* +?
TypeParamBound :
Lifetime | TraitBound
TraitBound :
?? ForLifetimes? TypePath
| ( ?? ForLifetimes? TypePath )
LifetimeBounds :
( Lifetime + )* Lifetime?
Lifetime :
LIFETIME_OR_LABEL
| 'static
| '_
ForLifetimes :
for GenericParams
TypePath :
::? TypePathSegment (:: TypePathSegment)*
TypePathSegment :
PathIdentSegment (::? (GenericArgs | TypePathFn))?
TypePathFn :
( TypePathFnInputs? ) (-> Type)?
TypePathFnInputs :
Type (, Type)* ,?
其中的 ForLifetimes 用于 Higher-ranked trait bounds, ForLifetimes 后面必须跟 TypePath,也就是 :: 分割的标识符 item, 如下面的 F 或 Fn:
// 语法:
TraitBound :
?? ForLifetimes? TypePath
| ( ?? ForLifetimes? TypePath )
ForLifetimes:
for GenericParams
fn call_on_ref_zero<F>(f: F) where for<'a> F: Fn(&'a i32) {
let zero = 0;
f(&zero);
}
fn call_on_ref_zero<F>(f: F) where F: for<'a> Fn(&'a i32) {
let zero = 0;
f(&zero);
}
函数使用 fn 关键字声明, 使用 -> 来指定返回值类型(没有指定的默认为 unit type ()), 函数体中最后一个表达式(不以分号结尾)作为函数的返回值, 也可以使用 return 语句提前返回.
// Unlike C/C++, there's no restriction on the order of function definitions
fn main() {
// We can use this function here, and define it somewhere later
fizzbuzz_to(100);
}
// Function that returns a boolean value
fn is_divisible_by(lhs: u32, rhs: u32) -> bool {
// Corner case, early return
if rhs == 0 {
return false;
}
// This is an expression, the `return` keyword is not necessary here
lhs % rhs == 0
}
// Functions that "don't" return a value, actually return the unit type `()`
fn fizzbuzz(n: u32) -> () {
if is_divisible_by(n, 15) {
println!("fizzbuzz");
} else if is_divisible_by(n, 3) {
println!("fizz");
} else if is_divisible_by(n, 5) {
println!("buzz");
} else {
println!("{}", n);
}
}
// When a function returns `()`, the return type can be omitted from the signature
fn fizzbuzz_to(n: u32) {
for n in 1..=n {
fizzbuzz(n);
}
}
Rust 2018 版本开始, main 函数支持返回 Result, 当结果是 Err 时会打印错误消息, 程序退出。这意味着可以在 main 函数中使用 ? 来简化错误处理;
fn main() -> Result<(), Box<dyn std::error::Error>> {
// 代码逻辑
Ok(())
}
函数参数可以使用 Pattern match 语法来解构传入的参数:
/*
FunctionParam :
OuterAttribute* ( FunctionParamPattern | ... | Type 2 )
FunctionParamPattern :
PatternNoTopAlt : ( Type | ... )
*/
// 示例
fn first((value, _): (i32, i32)) -> i32 { value }
// 函数的最后一个参数可以是 ..., 表示可变参数函数 variadic function
fn variadic_fn(input: int32, input2: ...) -> i32 { value }
可以给函数参数指定 attribute 来实现条件编译:
fn len(
#[cfg(windows)] slice: &[u16],
#[cfg(not(windows))] slice: &[u8],
) -> usize {
slice.len()
}
const 函数的限制:
- 内部只能调用其它的 const 函数;
- 不能分配内存和操作原始指针(即使在 unsafe block 中也不行);
- 除了 lifetime 外, 不能使用其他类型作为泛型参数;
const 函数主要用来初始化全局的 const/static 变量。
extern fn 表示使用指定的 ABI 来调用函数,常用在 extern block 和 unsafe 中:
- 未指定 extern 时,默认为 extern “Rust”;
- 指定 extern 但是未指定 ABI 时,默认为 “C”;
extern "ABI" fn foo() { /* ... */ }
extern "ABI" {
fn foo(); /* no body */
}
unsafe { foo() }
// Declares a function with the "C" ABI
extern "C" fn new_i32() -> i32 { 0 }
fn foo() {}
// 等效于
extern "Rust" fn foo() {}
extern fn new_i32() -> i32 { 0 }
let fptr: extern fn() -> i32 = new_i32;
// 等效于
extern "C" fn new_i32() -> i32 { 0 }
let fptr: extern "C" fn() -> i32 = new_i32;
struct/enum/union 等自定义类型内部不能定义函数,但是可以实现方法,Associated functions 和 Method 都是和类型相关的函数,都需要在类型的 impl 中声明:
- 第一个参数名为 self 时(&self,&mut self 等)是 Method,否则为 Associated functions;
- &self 等效为 &self: Self; &mut self 等效为 &mut Self, 其中 Self 等效为 impl XX 中的 XX 类型, 当 XX 类型比较复杂(如泛型)时 Self 可以简洁的代替.
struct Point {
x: f64,
y: f64,
}
// Implementation block, all `Point` associated functions & methods go in here
impl Point {
// This is an "associated function" because this function is associated with
// a particular type, that is, Point.
//
// Associated functions don't need to be called with an instance.
// These functions are generally used like constructors.
fn origin() -> Point {
Point { x: 0.0, y: 0.0 }
}
// Another associated function, taking two arguments:
fn new(x: f64, y: f64) -> Point {
Point { x: x, y: y }
}
}
struct Rectangle {
p1: Point,
p2: Point,
}
impl Rectangle {
// This is a method `&self` is sugar for `self: &Self`, where `Self` is the type of the caller
// object. In this case `Self` = `Rectangle`
fn area(&self) -> f64 {
// `self` gives access to the struct fields via the dot operator
let Point { x: x1, y: y1 } = self.p1;
let Point { x: x2, y: y2 } = self.p2;
// `abs` is a `f64` method that returns the absolute value of the caller
((x1 - x2) * (y1 - y2)).abs()
}
fn perimeter(&self) -> f64 {
let Point { x: x1, y: y1 } = self.p1;
let Point { x: x2, y: y2 } = self.p2;
2.0 * ((x1 - x2).abs() + (y1 - y2).abs())
}
// This method requires the caller object to be mutable `&mut self` desugars to `self: &mut
// Self`
fn translate(&mut self, x: f64, y: f64) {
self.p1.x += x;
self.p2.x += x;
self.p1.y += y;
self.p2.y += y;
}
}
// `Pair` owns resources: two heap allocated integers
struct Pair(Box<i32>, Box<i32>);
impl Pair {
// This method "consumes" the resources of the caller object `self` desugars to `self: Self`
fn destroy(self) {
// Destructure `self`
let Pair(first, second) = self; // self 的两个 Box 被转移到 first 和 second 变量;
println!("Destroying Pair({}, {})", first, second);
// `first` and `second` go out of scope and get freed
}
}
fn main() {
let rectangle = Rectangle {
// Associated functions are called using double colons
p1: Point::origin(),
p2: Point::new(3.0, 4.0),
};
// Methods are called using the dot operator Note that the first argument `&self` is implicitly
// passed, i.e. `rectangle.perimeter()` === `Rectangle::perimeter(&rectangle)`
println!("Rectangle perimeter: {}", rectangle.perimeter());
println!("Rectangle area: {}", rectangle.area());
let mut square = Rectangle {
p1: Point::origin(),
p2: Point::new(1.0, 1.0),
};
// Error! `rectangle` is immutable, but this method requires a mutable object
//rectangle.translate(1.0, 0.0);
// Okay! Mutable objects can call mutable methods
square.translate(1.0, 1.0);
let pair = Pair(Box::new(1), Box::new(2));
pair.destroy();
// Error! Previous `destroy` call "consumed" `pair`
//pair.destroy();
}
方法的 self 默认类型是 Self,也可以指定 self 的类型,如 Box<T>,这时只能使用该类型的对象来调用方法:
impl<T> [T]
pub fn into_vec<A>(self: Box<[T], A>) -> Vec<T, A> where A: Allocator
let s: Box<[i32]> = Box::new([10, 40, 30]);
let x = s.into_vec();
// `s` cannot be used anymore because it has been converted into `x`.
assert_eq!(x, vec![10, 40, 30]);
函数变量赋值时,输入参数是逆变,返回值是协变:
fn takes_fn_ptr<'short, 'middle: 'short>(
// 'middle is used in both a co- and contravariant position.
f: fn(&'middle ()) -> &'middle (),
) {
// As the variance at these positions is computed separately, we can freely shrink 'middle in
// the covariant position and extend it in the contravariant position.
// 函数输入参数是逆变,返回结果是协变。
let _: fn(&'static ()) -> &'short () = f;
}
19.1 method lookup #
The Dot Operator: https://doc.rust-lang.org/stable/nomicon/dot-operator.html
The dot operator will perform a lot of magic to convert types. It will perform auto-referencing,
auto-dereferencing, and coercion until types match. The detailed mechanics of method lookup are
defined here, but here is a brief overview that outlines the main steps.
Suppose we have a function foo that has a receiver (a self, &self or &mut self parameter). If we
call value.foo(), the compiler needs to determine what type Self is before it can call the correct
implementation of the function. For this example, we will say that value has type T. We will use
fully-qualified syntax to be more clear about exactly which type we are calling a function on.
- First, the compiler checks if it can
call T::foo(value) directly. This is calleda "by value"method call.即先看 T 是否直接实现方法 foo(); - If it can’t call this function (for example, if the function has the wrong type or a trait isn’t
implemented for Self), then the compiler
tries to add in an automatic reference. This means that the compiler tries<&T>::foo(value) and <&mut T>::foo(value). This is calledan "autoref" method call.再看 T 的 &T 和 &mut T 类型是否实现了方法 foo(); - If none of these candidates worked, it
dereferences T and tries again. This uses theDeref trait- if T: Deref<Target = U> then it tries again with type U instead of T.- 如果 T 不是引用类型, 但是实现了 Deref trait, 则 * 解引用它获得 U 类型, 然后对 U 重新执行 1-2 步骤.
- 最后尝试 unsized coercion 到类型 U,然后重新执行 1-2 步骤。Rust 目前支持的 unsized coercion 参考:
21.4
[T; n] to [T].所以 array 对象可以调用 slice 的方法。T to dyn U, when T implements U + Sized, and U is object safe.- 实现了 CoerceUnsized<Foo<U>> 的 &T,&mut T 和智能指针类型;
总结:The first step is to build a list of candidate receiver types. Obtain these by repeatedly dereferencing the receiver expression's type, adding each type encountered to the list, then finally
attempting an unsized coercion at the end, and adding the result type if that is successful. Then,
for each candidate T, add &T and &mut T to the list immediately after T.
For instance, if the receiver has type Box<[i32;2]>, then the candidate types will be:
- Box<[i32;2]>, &Box<[i32;2]>, &mut Box<[i32;2]>
- [i32; 2] (by dereferencing), &[i32; 2], &mut [i32; 2],
- [i32] (byunsized coercion), &[i32], and finally &mut [i32].
注意:上面的 method lookup 过程不会考虑可变性,lifetime 和 unsafe。如果类型实现的多个 trait 有相同的方法,而且这些 trait 都在作用域,则需要使用完全限定语法来指定要调用那个 trait 的方法实现。
trait Pretty {
fn print(&self);
}
trait Ugly {
fn print(&self);
}
struct Foo;
impl Pretty for Foo {
fn print(&self) {}
}
struct Bar;
impl Pretty for Bar {
fn print(&self) {}
}
impl Ugly for Bar {
fn print(&self) {}
}
fn main() {
let f = Foo;
let b = Bar;
// we can do this because we only have one item called `print` for `Foo`s
f.print();
// more explicit, and, in the case of `Foo`, not necessary
Foo::print(&f);
// if you're not into the whole brevity thing
<Foo as Pretty>::print(&f);
// b.print(); // Error: multiple 'print' found
// Bar::print(&b); // Still an error: multiple `print` found
// necessary because of in-scope items defining `print`
<Bar as Pretty>::print(&b);
}
示例:
let array: Rc<Box<[T; 3]>> = ...;
let first_entry = array[0]; // 等效为 *array.index(0)
- Then, the compiler checks if Rc<Box<[T; 3]>> implements Index, but it does not, and neither do &Rc<Box<[T; 3]>> or &mut Rc<Box<[T; 3]>>.
- Since none of these worked, the compiler dereferences the
Rc<Box<[T; 3]>> into Box<[T; 3]>and tries again. - Box<[T; 3]>, &Box<[T; 3]>, and &mut Box<[T; 3]> do not implement Index, so it dereferences again.
[T; 3]and its autorefs also do not implement Index.- It can’t dereference [T; 3], so the compiler
unsizes it, giving [T]. Finally,[T] implements Index, so it can now call the actual index function.
19.2 closure #
Rust 中的闭包是一种匿名函数,可以将它们保存在变量中或作为参数传递给其他函数。闭包能够捕获并使用其定义作用域内的变量,这是它们名称的由来——它们"封闭"并包围了周围的环境。
闭包在定义时(而非调用时)capture 外围环境中的对象,这种 capture 是 closures 函数内部的行为,不体现在闭包的函数参数中。
- 使用 || 而非 () 来定义输入参数;
- 如果是单行表达式,可以忽略大括号,否则需要使用大括号;
- 可以省略返回值声明,默认根据表达式自动推导;
- 如果指定返回值类型,则必须使用大括号;
- 闭包的输入和输出参数一旦被自动推导后,就不能再变化,后续多次调用时传的或返回的值类型必须相同;
- 对比:普通函数 fn 的参数类型必须指定,函数 fn 不能捕获上下文中的变量对象;
let is_even = |x: u64| -> bool x % 2 == 0; // error
let is_even = |x: u64| -> bool { x % 2 == 0 }; // ok
fn main() {
let outer_var = 42;
// A regular function can't refer to variables in the enclosing environment
//fn function(i: i32) -> i32 { i + outer_var }
// Closures are anonymous, here we are binding them to references. Annotation is identical to
// function annotation but is optional as are the `{}` wrapping the body. These nameless
// functions are assigned to appropriately named variables.
let closure_annotated = |i: i32| -> i32 { i + outer_var }; // block 中 return 或最后一个表达式值作为返回
let closure_inferred = |i | i + outer_var ; // 单行表达式的结果作为值返回
// Call the closures.
println!("closure_annotated: {}", closure_annotated(1));
println!("closure_inferred: {}", closure_inferred(1));
// Once closure's type has been inferred, it cannot be inferred again with another type.
//println!("cannot reuse closure_inferred with another type: {}", closure_inferred(42i64));
// A closure taking no arguments which returns an `i32`. The return type is inferred.
let one = || 1;
println!("closure returning one: {}", one());
}
fn add_one_v1 (x: u32) -> u32 { x + 1 }
let add_one_v2 = |x: u32| -> u32 { x + 1 };
let add_one_v3 = |x| { x + 1 }; // 闭包是一个表达式,可以赋值
let add_one_v4 = |x| x + 1 ;
let color = String::from("green");
let print = move || println!("`color`: {}", color); // move
// 两次函数调用的推导类型不一致,编译失败。
let example_closure = |x| x;
let s = example_closure(String::from("hello"));
let n = example_closure(5);
fn main() {
// Increment via closures and functions.
fn function(i: i32) -> i32 { i + 1 }
// Closures are anonymous, here we are binding them to references
//
// These nameless functions are assigned to appropriately named variables.
let closure_annotated = |i: i32| -> i32 { i + 1 };
let closure_inferred = |i | i + 1 ;
let i = 1;
// Call the function and closures.
println!("function: {}", function(i));
println!("closure_annotated: {}", closure_annotated(i));
println!("closure_inferred: {}", closure_inferred(i));
// A closure taking no arguments which returns an `i32`.
// The return type is inferred.
let one = || 1;
println!("closure returning one: {}", one());
}
闭包是一个表达式,也可以作为函数返回类型,struct/enum 的成员类型:
struct Cacher<T,E> where T: Fn(E) -> E, E: Copy
{
query: T,
value: Option<E>,
}
impl<T,E> Cacher<T,E> where T: Fn(E) -> E, E: Copy
{
fn new(query: T) -> Cacher<T,E> {
Cacher {
query,
value: None,
}
}
fn value(&mut self, arg: E) -> E {
match self.value {
Some(v) => v,
None => {
let v = (self.query)(arg);
self.value = Some(v);
v
}
}
}
}
#[test]
fn call_with_different_values() {
let mut c = Cacher::new(|a| a);
let v1 = c.value(1);
let v2 = c.value(2);
assert_eq!(v2, 1);
}
在闭包函数中使用外部环境的对象时,Rust 编译器会分析闭包使用的方式来确定如何捕获该对象(复合类型 struct/tuple/enum 也是被作为一个整体来捕获的,可以使用临时变量来捕获某个 field):
- Imut Refer:不可变引用外围环境中的对象,优先选择该类型。
- Mut Refer:可变引用外围环境中的对象;
- Move:外围对象的所有权移动到闭包函数中;
- 例如闭包内部需要 drop() non-copy 对象或者需要返回对象(转移所有权到接收方);
- 更常见的情况是多线程场景,因为多线程场景的闭包函数在另一个 thread 中运行,编译器不能推断闭包引用对象的声明周期是否有效,所以需要 move,这样确保闭包捕获的对象是一直有效的。
- 使用 move 后,闭包捕获了上下文对象,这些对象的生命周期完全由闭包内部的逻辑来控制,所以该闭包实现了
'static;
let s = String::from("coolshell");
let take_str = || s; // s 作为闭包返回值,所以是 Move 语义。
println!("{}", s); // s 已经被 move 进闭包,所以不能再访问。
println!("{}", take_str()); // OK
// 在定义闭包时捕获环境中对象
fn main() {
let mut count = 0;
let mut inc = || {
count += 1; // Mut refer
println!("`count`: {}", count);
};
inc();
assert_eq!(count, 1); // 闭包后续不再使用,故还可以继续访问 count
}
// 错误的情况
fn main() {
let mut count = 0;
let mut inc = || {
count += 1; // Mut refer
println!("`count`: {}", count);
};
inc();
assert_eq!(count, 1); // inc() 继续有效的情况下,count 还是保持 &mut,所以这里 cannot borrow
// `count` as immutable because it is also borrowed as mutable
inc();
}
fn main() {
use std::mem;
let color = String::from("green");
// A closure to print `color` which immediately borrows (`&`) `color` and stores the borrow and
// closure in the `print` variable. It will remain borrowed until `print` is used the last time.
//
// `println!` only requires arguments by immutable reference so it doesn't impose anything more
// restrictive.
let print = || println!("`color`: {}", color); // print 在有效的情况下,一致保有 color 的共享引用
// Call the closure using the borrow.
print();
// `color` can be borrowed immutably again, because the closure only holds an immutable
// reference to `color`.
let _reborrow = &color;
print();
// A move or reborrow is allowed after the final use of `print`
let _color_moved = color; // print 后续不再使用,所以可以 move color
let mut count = 0;
// A closure to increment `count` could take either `&mut count` or `count` but `&mut count` is
// less restrictive so it takes that. Immediately borrows `count`.
//
// A `mut` is required on `inc` because a `&mut` is stored inside. Thus, calling the closure
// mutates `count` which requires a `mut`.
let mut inc = || {
count += 1;
println!("`count`: {}", count);
};
// Call the closure using a mutable borrow.
inc();
// The closure still mutably borrows `count` because it is called later. An attempt to reborrow
// will lead to an error.
// let _reborrow = &count; // inc 还有效(因为后面还在调用),所以 count 一直处于 inc 的 &mut 状态
inc();
// The closure no longer needs to borrow `&mut count`. Therefore, it is possible to reborrow
// without an error
let _count_reborrowed = &mut count;
// A non-copy type.
let movable = Box::new(3);
// `mem::drop` requires `T` so this must take by value. A copy type would copy into the closure
// leaving the original untouched. A non-copy must move and so `movable` immediately moves into
// the closure.
let consume = || {
println!("`movable`: {:?}", movable);
mem::drop(movable);
};
// `consume` consumes the variable so this can only be called once.
consume();
// consume();
}
// move 闭包
use std::thread;
fn main() {
let list = vec![1, 2, 3];
println!("Before defining closure: {:?}", list);
thread::spawn(move || println!("From thread: {:?}", list)) // 闭包函数使用 ownership 接管而非引用来捕获外界对象。
.join()
.unwrap();
}
对于 move 到闭包中的变量对象,闭包外不能再使用(借用)该变量:
// OK
fn main() {
let color = String::from("green");
let print = move || println!("`color`: {}", color);
print();
let _reborrow = &color; // error[E0382]: borrow of moved value: `color`
println!("{}",_reborrow);
}
// OK
fn main() {
let movable = Box::new(3);
let consume = move || {
println!("`movable`: {:?}", movable);
};
consume();
consume(); // OK, consume 保持对 movable 变量的 move,所以可以多次调用。
}
// Error
fn main() {
let movable = Box::new(3);
// consume 只能调用一次,因为它内部将 movable 变量 move 走了。
let consume = || {
println!("`movable`: {:?}", movable);
take(movable);
};
consume();
consume(); // // error[E0382]: use of moved value: `consume`。closure cannot be invoked more
// than once because it moves the variable `movable` out of its environment
}
fn take<T>(_v: T) {}
外围对象被闭包捕获后,不允许再修改它的值:
- 实际上,一旦对象被借用(不管是共享还是可变借用),只要该借用还有效,对象都不能被修改或 move。《== 借用冻结
fn main() {
let mut a = 123;
let ar = &a;
a = 456; // Error:cannot assign to `a` because it is borrowed
println!("{ar}")
}
fn main() {
let mut x = 4;
let add_to_x = |y| y + x; // x 被共享借用
let result = add_to_x(3);
println!("The result is {}", result); // 输出:The result is 7
x = x + 3; // 在被共享借用的有效情况下, 不能修改其值
let result2 = add_to_x(3);
println!("The result2 is {}", result2);
}
编译器为闭包表达式创建一个匿名的闭包类型,该类型类似于 struct,可以捕获(优先 &,其次是 &mut 或移动语义)环境中的对象。编译器根据闭包中使用环境对象的方式,来确定:
- 捕获环境对象的方式:ref,mut ref or move;
- 匿名闭包类型该实现哪一个 trait:Fn/FnMut/FnOnce。
fn f<F : FnOnce() -> String> (g: F) {
println!("{}", g());
}
let mut s = String::from("foo");
let t = String::from("bar");
f(|| {
s += &t;
s
});
// Prints "foobar".
// generates a closure type roughly like the following:
struct Closure<'a> {
s : String, // 捕获
t : &'a String, // 借用
}
impl<'a> FnOnce<()> for Closure<'a> {
type Output = String;
fn call_once(self) -> String {
self.s += &*self.t;
self.s
}
}
// so that the call to f works as if it were:
f(Closure{s: s, t: &t});
编译器自动为闭包类型实现 Fn/FnMut/FnOnce trait,当闭包作为 函数输入参数 或限界 Bound 时也需要指定该类型。
- FnOnce 类型:只能调用一次,该闭包接管了外界环境中的值;
- FnMut 类型:可以调用多次,该闭包使用 &mut 来捕获外界值;
- Fn 类型:可以调用多次,该闭包使用 &T 来捕获外界值;
- Fn 是 FnMut 子类型, FnMut 是 FnOnce 子类型;
// std::ops::FnOnce
pub trait FnOnce<Args> where Args: Tuple,
{
type Output;
// Required method
extern "rust-call" fn call_once(self, args: Args) -> Self::Output; // 传入 self
}
// std::ops::FnMut
pub trait FnMut<Args>: FnOnce<Args> where Args: Tuple, // FnMut 是 FnOnce 子类型
{
// Required method
extern "rust-call" fn call_mut( &mut self, args: Args ) -> Self::Output; // 传入 &mut self
}
pub trait Fn<Args>: FnMut<Args> where Args: Tuple, // Fn 是 FnMut 子类型
{
// Required method
extern "rust-call" fn call(&self, args: Args) -> Self::Output; // 传入 &self
}
// 例子 1 `F` must implement `Fn` for a closure which takes no inputs and returns nothing - exactly
// what is required for `print`.
fn apply<F>(f: F) where F: Fn() {
f();
}
fn main() {
let x = 7;
// Capture `x` into an anonymous type and implement `Fn` for it. Store it in `print`.
let print = || println!("{}", x);
apply(print);
}
// 例子2
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let mut list = [
Rectangle { width: 10, height: 1 },
Rectangle { width: 3, height: 5 },
Rectangle { width: 7, height: 12 },
];
list.sort_by_key(|r| r.width); // 编译器推断该闭包符合 FnMutt 要求,虽然它没有捕获外围任何对象
println!("{:#?}", list);
}
impl<T> [T] {
pub fn sort_by_key<K, F>(&mut self, mut f: F)
where
F: FnMut(&T) -> K, // F 是 FnMutt 类型,且输入是 &T
K: Ord,
{
stable_sort(self, |a, b| f(a).lt(&f(b)));
}
}
// 例子 3
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let mut list = [
Rectangle { width: 10, height: 1 },
Rectangle { width: 3, height: 5 },
Rectangle { width: 7, height: 12 },
];
let mut sort_operations = vec![];
let value = String::from("by key called");
list.sort_by_key(|r| { // 编译器推断该闭包为 FnOnce 类型,不符合 sort_by_key() 方法的要求 FnMut
sort_operations.push(value);
r.width
});
println!("{:#?}", list);
}
对于没有捕获环境中值的闭包,可以被被隐式或显式(as)为 fn 指针:
let add = |x, y| x + y;
let mut x = add(5,7);
type Binop = fn(i32, i32) -> i32;
let bo: Binop = add;
x = bo(5,7);
如果一个函数输入参数类型是闭包,则也可以传入函数指针(fn 类型对象),反之则不行。
闭包作为匿名类型,可以作为 函数输入参数、限界 Bound、函数的返回值 ,与其他类型一样,也可以实现
Send/Sync/Copy/Clone trait,具体取决于捕获的对象类型,例如:如果所有捕获的对象都实现了 Send,则闭包也实现了 Send。
闭包也可以作为函数返回值返回,但 Fn/FnMut/FnOnce 都是 trait,所以需要使用 impl Trait 或 &dyn Trait 或
Box<dyn Trait> 语法。另外,必须使用 move 关键字,否则当函数返回时,闭包捕获的引用值会失效。
- impl trait 是编译时静态确定的唯一类型;&dyn trait 和 Box<dyn trait> 是运行时动态分发的类型;
// 错误,返回值是 unsize 大小
fn returns_closure() -> Fn(i32) -> i32 {
|x| x + 1
}
// 正确
fn returns_closure() -> Box<dyn Fn(i32) -> i32> {
Box::new(|x| x + 1)
}
fn create_fn() -> impl Fn() {
let text = "Fn".to_owned();
move || println!("This is a: {}", text)
}
fn create_fnmut() -> impl FnMut() {
let text = "FnMut".to_owned();
move || println!("This is a: {}", text)
}
fn create_fnonce() -> impl FnOnce() {
let text = "FnOnce".to_owned();
move || println!("This is a: {}", text)
}
fn main() {
let fn_plain = create_fn();
let mut fn_mut = create_fnmut();
let fn_once = create_fnonce();
fn_plain();
fn_mut();
fn_once();
}
闭包 lifetime:闭包函数返回引用时可能会遇到 lifetime 问题( 16.3 并不适合闭包):
fn fn_elision(x: &i32) -> &i32 { x } // OK
let closure_elision = |x: &i32| -> &i32 { x }; // Error
| let closure = |x: &i32| -> &i32 { x }; // fails
| - - ^ returning this value requires that `'1` must outlive `'2`
| | |
| | let's call the lifetime of this reference `'2`
| let's call the lifetime of this reference `'1`
解决办法:
- 使用 nightly toolchain 和开启 #![feature(closure_lifetime_binder)],这样可以为闭包函数指定 for <‘a> 语法的 lifetime: https://github.com/rust-lang/rust/issues/97362
- 或者,定义一个 helper 函数,该函数可以指定闭包输入、输出参数所需的 lifetime,然后内部调用闭包;
- 或者,将闭包转换为 fn 函数指针类型,函数指针 支持使用 for<‘a>来定义 lifetime 参数; https://stackoverflow.com/a/60906558
// 解决办法1:
fn main() {
// let clouse_test = |input: &String| input; // error: lifetime may not live long enough
//let clouse_test = |input: &String| -> &String {input}; // error: lifetime may not live long enough
// let clouse_test = |input: &'a String| ->&'a String {input}; // error[E0261]: use of undeclared lifetime name `'a`
let clouse_test = for <'a> |input: &'a String| ->&'a String {input}; // 需要使用 nightly toolchain 和开启 #![feature(closure_lifetime_binder)]
println!("Results:")
}
// 解决办法2:
fn testStr<'a> (input: &'a String) -> &'a String {
let closure_test = |input: &'a String | -> &'a String {input}; // 闭包使用外围 helper 函数定义的 lifetime
return closure_test(input);
}
fn main() {
// let clouse_test = |input: &String| input; // error: lifetime may not live long enough
//let clouse_test = |input: &String| -> &String {input}; // error: lifetime may not live long enough
// let clouse_test = |input: &'a String| ->&'a String {input}; // error[E0261]: use of undeclared lifetime name `'a`
// let clouse_test = for <'a> |input: &'a String| ->&'a String {input};
println!("Results:{}", testStr(&"asdfab".to_string()));
}
// 解决办法3:
// 将闭包转换为 fn 函数指针,函数指针支持使用 for<'a> 来定义高阶函数,而且编译期间大小是已知的。
// 但是不能使用 Fn/FnMut/FnOnce 等 trait 类型。
let test_fn: for<'a> fn(&'a _) -> &'a _ = |p: &String| p;
println!("Results:{}", test_fn(&"asdfab".to_string()));
// 其他例子:https://github.com/rust-lang/rust/pull/56746/files
#![allow(unused)]
fn willy_no_annot<'w>(p: &'w str, q: &str) -> &'w str {
let free_dumb = |_x| { p }; // no type annotation at all
let hello = format!("Hello");
free_dumb(&hello)
}
fn willy_ret_type_annot<'w>(p: &'w str, q: &str) -> &'w str {
let free_dumb = |_x| -> &str { p }; // type annotation on the return type
let hello = format!("Hello");
free_dumb(&hello)
}
fn willy_ret_region_annot<'w>(p: &'w str, q: &str) -> &'w str {
let free_dumb = |_x| -> &'w str { p }; // type+region annotation on return type
let hello = format!("Hello");
free_dumb(&hello)
}
fn willy_arg_type_ret_type_annot<'w>(p: &'w str, q: &str) -> &'w str {
let free_dumb = |_x: &str| -> &str { p }; // type annotation on arg and return types
let hello = format!("Hello");
free_dumb(&hello)
}
fn willy_arg_type_ret_region_annot<'w>(p: &'w str, q: &str) -> &'w str {
let free_dumb = |_x: &str| -> &'w str { p }; // fully annotated
let hello = format!("Hello");
free_dumb(&hello)
}
fn main() {
let world = format!("World");
let w1: &str = {
let hello = format!("He11o");
willy_no_annot(&world, &hello)
};
let w2: &str = {
let hello = format!("He22o");
willy_ret_type_annot(&world, &hello)
};
let w3: &str = {
let hello = format!("He33o");
willy_ret_region_annot(&world, &hello)
};
let w4: &str = {
let hello = format!("He44o");
willy_arg_type_ret_type_annot(&world, &hello)
};
let w5: &str = {
let hello = format!("He55o");
willy_arg_type_ret_region_annot(&world, &hello)
};
assert_eq!((w1, w2, w3, w4, w5),
("World","World","World","World","World"));
}
}
如果要给闭包 move 传参, 比如 clone 后的值或 refer 值, 则建议使用 Use variable rebinding in a separate scope for that.
// https://rust-unofficial.github.io/patterns/idioms/pass-var-to-closure.html
use std::rc::Rc;
let num1 = Rc::new(1);
let num2 = Rc::new(2);
let num3 = Rc::new(3);
let closure = {
// `num1` is moved
let num2 = num2.clone(); // `num2` is cloned
let num3 = num3.as_ref(); // `num3` is borrowed
move || {
*num1 + *num2 + *num3;
}
};
// 而非,因为下面的 num2_cloned/num3_borrowed 的作用域在闭包之外还有效,但是它们已经 move 到闭包了
use std::rc::Rc;
let num1 = Rc::new(1);
let num2 = Rc::new(2);
let num3 = Rc::new(3);
let num2_cloned = num2.clone();
let num3_borrowed = num3.as_ref();
let closure = move || {
*num1 + *num2_cloned + *num3_borrowed;
};
19.3 HRTB Fn/fn #
HRTB 一般只会在 Fn 作为 Bound 时会使用到, 下面没有加 lifetime 的代码是可以正常编译的:
struct Closure<F> {
data: (u8, u16),
func: F,
}
impl<F> Closure<F>
where F: Fn(&(u8, u16)) -> &u8,
{
fn call(&self) -> &u8 {
(self.func)(&self.data)
}
}
fn do_it(data: &(u8, u16)) -> &u8 { &data.0 }
fn main() {
let clo = Closure { data: (0, 1), func: do_it };
println!("{}", clo.call());
}
如果要给上面的代码添加 lifetime bound 则会遇到 F 的 lifetime 该如何指定的问题:
struct Closure<F> {
data: (u8, u16),
func: F,
}
impl<F> Closure<F>
// where F: Fn(&'??? (u8, u16)) -> &'??? u8,
{
fn call<'a>(&'a self) -> &'a u8 {
(self.func)(&self.data)
}
}
fn do_it<'b>(data: &'b (u8, u16)) -> &'b u8 { &'b data.0 }
fn main() {
'x: {
let clo = Closure { data: (0, 1), func: do_it };
println!("{}", clo.call());
}
}
// Error1:
impl<'a, F> Closure<F>
where F: Fn(&'a (u8, u16)) -> &'a u8,
{
fn call<'a>(&'a self) -> &'a u8 { // lifetime name `'a` shadows a lifetime name that is
// already in scope
(self.func)(&self.data)
}
}
// Error2:
impl<'a, F> Closure<F>
where F: Fn(&'a (u8, u16)) -> &'a u8,
{
fn call<'b>(&'b self) -> &'b u8 { // method was supposed to return data with lifetime `'a`
// but it is returning data with lifetime `'b`
(self.func)(&self.data)
}
}
// Error3:
impl<'a, F> Closure<F>
where F: Fn(&'a (u8, u16)) -> &'a u8,
{
fn call(& self) -> & u8 { // rustc 自动为 &self 添加 liefitime 如 '1: method was supposed to
// return data with lifetime `'1` but it is returning data with
// lifetime `'a`
(self.func)(&self.data)
}
}
// Error4: 可以编译过,但是要求 Closure 的 liefitime 和传入的 Fn 的参数 lifetime 一致,不符合预期语
// 义(Fn 的函数有自己独立的 lifetime,和 Closure 对象 lifetime 无关)。
impl<'a, F> Closure<F>
where F: Fn(&'a (u8, u16)) -> &'a u8,
{
fn call(&'a self) -> &'a u8 {
(self.func)(&self.data)
}
}
// OK:HRTB
impl<F> Closure<F> // 1. 泛型参数中没有 'a lifetitme
where F: for <'a> Fn(&'a (u8, u16)) -> &'a u8, // 2. 在 F 的 Bound 中使用 for <'a> 来声明 'a lifetime
{
fn call<'a>(&'a self) -> &'a u8 { // 'a 和上面的 for <'a> 没有任何关系,是 call() 方法自己的
// lifetime。由于 rustc 会自动加 lifetime,所以不指定:fn
// call(&self) -> &u8
(self.func)(&self.data)
}
}
可见 HRTB 语法 for <‘a> :一般 只在 Fn Bound 中使用,for <'a> Fn 表示 Fn 满足任意 'a liftime ,所以
Fn 也满足 call() 方法的lifetime 要求,可以在 call() 方法中使用。
另外,fn 函数指针也可以使用 for <‘a> 来指定 lifetime:
let test_fn: for<'a> fn(&'a _) -> &'a _ = |p: &String| p; // OK
let test_fn: for<'a> Fn(&'a _) -> &'a _ = |p: &String| p; // Error,因为 Fn 是 trait
HRTB 有两种等效语法:
where F: for<'a> Fn(&'a (u8, u16)) -> &'a u8,
// 等效为
where for <'a> F: Fn(&'a (u8, u16)) -> &'a u8,
19.4 Diverging functions #
发散函数 Diverging functions 指的是不返回的函数,它使用 ! 来表示: 发散函数可以用在需要表示永不返回的逻辑,例如无限循环、调用 panic! 宏或者退出程序。
fn foo() -> ! {
panic!("This call never returns.");
}
fn loop_forever() -> ! {
loop {
println!("I will loop forever!");
}
}
对比: unit type 值 () 还是有唯一的值 ():
fn some_fn() {
// 未指定返回值,等效为返回 ();
()
}
fn main() {
let _a: () = some_fn();
println!("This function returns and you can see this line.");
}
! 也可以作为类型:
#![feature(never_type)]
fn main() {
let x: ! = panic!("This call never returns.");
println!("You will never see this line!");
}
! 也可以作为 loop {} 或 std::os::exit() 函数的返回值.
为什么要使用发散函数来作为一个无限循环的返回,正常的单元函数返回,然后指定一个不可退出的循环条件不也可以实现么。这里返回一个! 而不是 () 有其特定的用途,主要取决于类型系统和编译器的行为。
20 generic/trait #
泛型类型/函数/方法的泛型参数使用 <CamelCase, …> 表示:
// 泛型类型:T 为泛型类型名称,名称位于类型名后的 <xx> 中。
struct SGen<T>(T);
struct Point<T> { x: T, y: T, }
// 泛型函数:类型参数位于函数名后的 <xx> 中。
fn generic<T>(_s: SGen<T>) {}
// 为泛型类型实现关联函数或方法时,impl 后面需要列出泛型类型所需的所有泛型参数
struct Val<T> {
val: T,
}
// 函数和方法也可以定义自己的泛型参数, 它们不需要在 impl 后列出,而是在调用时推导或指定。
impl<T> Val<T> {
// 方法可以使用 impl 后的泛型参数类型。
fn value(&self) -> &T {
&self.val
}
// 方法可以有自己的泛型参数 O
fn add<O: Debug>(&self, other: O) {
println!("{:?}", other);
}
}
// 具体类型
struct A;
struct S(A);
fn reg_fn(_s: S) {}
fn gen_spec_t(_s: SGen<A>) {} // 实例化后的具体类型
fn gen_spec_i32(_s: SGen<i32>) {}
fn main() {
reg_fn(__);
gen_spec_t(__);
gen_spec_i32(__);
// 调用泛型方法时,使用比目鱼语法:method::<type>() 来指定泛型参数的具体类型。
generic::<char>(__);
// 未指定泛型类型具体值,编译器自动推导
let p = Point{
x: "5".to_string(),
y : "hello".to_string()
};
let x = Val{ val: 3.0 }; // x 是 Val<f64> 类型
let y = Val{ val: "hello".to_string()}; // y 是 Val<String> 类型
println!("{}, {}", x.value(), y.value()); // 3.0, hello
let x = Val { val: 3.0 };
let y = Val { val: "hello".to_string(), };
println!("{}, {}", x.value(), y.value());
x.add(123); // 推断
x.add::<i32>(123); // 为泛型方法手动指定类型,使用比目鱼语法。
}
impl<T> 语法:
- 定义泛型类型的方法或关联函数:impl<T> MyStruct<T> {}
- 或为类型定义泛型 trait 的实现: impl<T> MyTrait<T> for MyStruct<T> {}
- impl<T> 指定 trait 或类型使用的泛型参数,甚至整个类型都可以是泛型参数(blanket implement),如 impl<T, U> MyTrait<T> for U {};
struct GenericVal<T>(T);
// 对于泛型类型,在进行 impl 时,如果明确指定了泛型参数类型,则不需要为 imp 指定泛型参数,例如:
impl GenericVal<f32> {}
impl GenericVal<S> {}
// 未指定具体类型时,必须在 impl<T> 中指定 GenericVal 的所有泛型参数。
impl<T> GenericVal<T> {}
struct GenVal<T> {
gen_val: T,
}
// impl of GenVal for a generic type `T`
impl<T> GenVal<T> {
fn value(&self) -> &T {
&self.gen_val
}
}
// 泛型 trait
trait DoubleDrop<T> {
fn double_drop(self, _: T);
}
// 为 U 实现泛型 trait,U 本身也是泛型参数,由于 U 没有加任何 bound,所以
// 相当于为所有类型实现了 DoubleDrop trait。
impl<T, U> DoubleDrop<T> for U {
fn double_drop(self, _: T) {}
}
fn main() {
let y = GenVal { gen_val: 3i32 }; // 示例化 GenVal<T> 时可以不指定 T,编译器自动推导
println!("{}, {}", x.value(), y.value());
}
在使用 trait 提供的方法或函数时,该 trait 必须先引入到当前 scope, 否则编译器不知道应该使用该类型实现的哪个 trait 的同名函数或方法.
- std::prelude::v1 moudle 列出的 item 会被自动导入到所有 std Rust 程序中,如 std::convert::{AsRef, AsMut, Into, From} 等,所以在调用对象的 into()/from()/as_ref()/as_mut() 方法前不需要手动导入它们。
trait 支持关联类型 type , 这些类型在定义 trait 时未知,但是在实现该 trait 时需要指定 具体类型 :
- 定义泛型 trait 时 trait MyTrait<T> 的泛型参数 T 中不需要体现关联类型,但是在使用泛型 trait 时,可以指定关联类型的值,如 Deref<Target=String>;
- 在定义 trait 使,可以为关联类型指定
缺省值或限界约束。 - 在实现该 trait 或将 trait 作为 bound 约束时,需要指定关联类型的具体类型,但是如果关联类型有缺省值,则可以不需要指定具体类型。
- fn my_func<Iter: Iterator<Item=u8>>(iter: Iter) {}
trait Iterator {
// 关联类型, 可以对类型进行限界。
type Item: std::fmt::Display;
fn next(&mut self) -> Option<Self::Item>;
}
struct EvenNumbers { count: usize, limit: usize, }
impl Iterator for EvenNumbers {
// 实现时必须为关联类型指定 =具体类型=,该具体类型需要满足 trait 定义的限界要求。
type Item = usize;
// 通过 Self 引用关联类型
fn next(&mut self) -> Option<Self::Item> {
if self.count > self.limit {
return None;
}
let ret = self.count * 2;
self.count += 1;
Some(ret)
}
}
在定义泛型 trait 时, 泛型参数和关联类型都可以有缺省类型 , 例如各种运算符重载 trait 都指定了默认类型。
对于有缺省参数 + 关联类型的泛型 trait, 使用该 trait 时可以同时指定泛型类型参数+关联类型, 其中 按顺序指定泛型类型参数的具体类型,使用 K=V 来指定关联类型 。如, 在使用 Add 进行限界时:
- Add<&T,Output=T>
- Add<Output=T> (省略有缺省值的参数)
但不能使用 Add<Rhs=&T, Output=T>, 因为 Rhs 不是关联类型参数:
// 定义泛型 trait 时,可以为泛型类型参数指定缺省值
pub trait Add<Rhs = Self> {
// 关联类型可以指定缺省值
type Output = Self;
// Required method
fn add(self, rhs: Rhs) -> Self::Output;
}
// 定义一个泛型函数,使用 Add trait 作为泛型参数的限界,同时指定 Rhs 类型和关联类型
fn add_values<T, Rhs>(a: T, b: Rhs) -> T
where T: Add<Rhs, Output = T>, // 不能使用 Rhs = Rhs, 否则 Rust 会报错没有 Rhs 关联类型。
{ a + b }
// 定义一个包含 Add trait 作为泛型限界的结构体
struct MyStruct<T> { value: T, }
fn main() {
let struct_a = MyStruct { value: 10 };
let scalar_b = 20;
// 指定 Rhs 类型为 i32,确保加法操作的结果类型是相同的
let result = add_values(struct_a.value, scalar_b);
}
// 在实现 trait 时实例化泛型 trait 的参数。
impl Add<Bar> for Foo {
type Output = FooBar;
fn add(self, _rhs: Bar) -> FooBar {
FooBar
}
}
trait 也支持常量参数(例如 <const N: usize> ),这样可以在泛型类型/函数/方法中使用 Array。实例化常量参数时,可以使用 {XXX} 常量表达式。
struct ArrayPair<T, const N: usize> {
left: [T; N],
right: [T; N],
}
impl<T: Debug, const N: usize> Debug for ArrayPair<T, N> {
// ...
}
// 实例化常量参数
fn foo<const N: usize>() {}
fn bar<T, const M: usize>() {
foo::<M>(); // Okay: `M` is a const parameter
foo::<2021>(); // Okay: `2021` is a literal
foo::<{20 * 100 + 20 * 10 + 1}>(); // Okay: const expression contains no generic parameters
foo::<{ M + 1 }>(); // Error: const expression contains the generic parameter `M`
foo::<{ std::mem::size_of::<T>() }>(); // Error: const expression contains the generic parameter `T`
let _: [u8; M]; // Okay: `M` is a const parameter
let _: [u8; std::mem::size_of::<T>()]; // Error: const expression contains the generic parameter `T`
}
使用 trait bound 的场景:
- 泛型参数: fn f<A: Copy>() {}
- supertrait: trait Circle : Shape + Color {}
- trait 关联类型: trait A { type B: Copy; } 等效于 trait A where Self::B: Copy { type B;}
在函数传参匹配 trait bound 时不会自动隐式进行 type coercion 协变,例如,虽然 &mut i32 可以协变到 &i32, 但传参时不会协变。带来的影响是:如果 Trait 作为函数参数限界,&i32 和 &mut i32 两种类型都需要实现该 Trait,所以标准库的很多类型 T 都是同时在 &T 和 &mut T 上实现了相同的接口。
trait Trait {}
fn foo<X: Trait>(t: X) {}
impl<'a> Trait for &'a i32 {}
fn main() {
let t: &mut i32 = &mut 0;
foo(t);
}
// error[E0277]: the trait bound `&mut i32: Trait` is not satisfied
// --> src/main.rs:9:9
// |
// 3 | fn foo<X: Trait>(t: X) {}
// | ----- required by this bound in `foo`
// ...
// 9 | foo(t);
// | ^ the trait `Trait` is not implemented for `&mut i32`
// |
// = help: the following implementations were found:
// <&'a i32 as Trait>
// = note: `Trait` is implemented for `&i32`, but not for `&mut i32`
20.1 泛型 trait 和 blanket impl #
泛型 trait 是有类型参数的 trait。trait 也可以作为泛型类型参数的限界(bound)约束,也可以作为函数的参数或返回值(impl Trait):
- 匿名函数也可以作为类型参数的 bound 约束,例如函数指针 fn() -> u32 或闭包 Fn() -> u32;
- 除了可以对泛型类型参数 T 直接限界外,也可以使用 where 对
使用 T 的其它类型进行限界,如: Option<T>: Debug;
// 对 T 无限制。
struct Pair<T> { x: T, y: T,
}
impl<T> Pair<T> {
fn new(x: T, y: T) -> Self {
Self { x, y, }
}
}
// 实现 trait 时,对 T 添加限制,可以添加多个不同类型的 trait 限制。
impl<T: std::fmt::Debug + PartialOrd> Pair<T> {
fn cmp_display(&self) {
if self.x >= self.y {
println!("The largest member is x = {:?}", self.x);
} else {
println!("The largest member is y = {:?}", self.y);
}
}
}
trait Contains<A, B> {
fn contains(&self, _: &A, _: &B) -> bool;
fn first(&self) -> i32;
fn last(&self) -> i32;
}
// 实现泛型 trait 时,可以指定具体类型或者继续使用泛型参数。
impl Contains<i32, i32> for Container {
fn contains(&self, number_1: &i32, number_2: &i32) -> bool {
(&self.0 == number_1) && (&self.1 == number_2)
}
fn first(&self) -> i32 { self.0 }
fn last(&self) -> i32 { self.1 }
}
// 泛型参数可以使用多个 trait 或 lifetime 作为限界。
use std::fmt::{Debug, Display};
fn compare_prints<T: Debug + Display>(t: &T) {
println!("Debug: `{:?}`", t);
println!("Display: `{}`", t);
}
fn compare_types<T: Debug, U: Debug>(t: &T, u: &U) {
println!("t: `{:?}`", t);
println!("u: `{:?}`", u);
}
fn main() {
let string = "words";
let array = [1, 2, 3];
let vec = vec![1, 2, 3];
compare_prints(&string);
//compare_prints(&array);
// TODO ^ Try uncommenting this.
compare_types(&array, &vec);
}
// 对于复杂的限界,可以使用 where 来定义.
impl <A: TraitB + TraitC, D: TraitE + TraitF> MyTrait<A, D> for YourType {}
// 等效于:
impl <A, D> MyTrait<A, D> for YourType
where
A: TraitB + TraitC,
D: TraitE + TraitF {
//..
}
// 有些场景, 必须使用 where 来限界。
use std::fmt::Debug;
trait PrintInOption {
fn print_in_option(self);
}
// Because we would otherwise have to express this as `T: Debug` or use another method of indirect
// approach, this requires a `where` clause:
impl<T> PrintInOption for T where Option<T>: Debug {
fn print_in_option(self) {
println!("{:?}", Some(self));
}
}
fn main() {
let vec = vec![1, 2, 3];
vec.print_in_option();
}
除了为具体类型实现泛型 trait,也可以为泛型类型 T 实现泛型 trait,这样可以批量对已知或未知的类型实现 trait。例如为所有 &T 或 &mut T 实现 Deref<Target = T> trait:
// https://doc.rust-lang.org/src/core/ops/deref.rs.html#84
#[stable(feature = "rust1", since = "1.0.0")]
impl<T: ?Sized> Deref for &T {
type Target = T;
#[rustc_diagnostic_item = "noop_method_deref"]
fn deref(&self) -> &T {
*self
}
}
#[stable(feature = "rust1", since = "1.0.0")]
impl<T: ?Sized> !DerefMut for &T {}
#[stable(feature = "rust1", since = "1.0.0")]
impl<T: ?Sized> Deref for &mut T {
type Target = T;
fn deref(&self) -> &T {
*self
}
}
一般情况下定义函数或方法使用的 trait 或 type 必须是本 crate package 定义的,称为 Orphan Rule ,这是为了避免破坏开发者原来的定义。解决办法是使用 newtype pattern 来新定义一个类型:
use std::fmt;
// a newtype Pretty, 相当于为 String 实现 Display
sturct Pretty(String)
impl fmt::Display for Pretty {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
write!(f, "\"{}\"", self.0.clone() + ", world")
}
}
fn main() {
let w = Pretty("hello".to_string());
println!("w = {}", w);
}
对于泛型 trait 则放宽了这个条件限制:可以在本 crate package 没有定义 trait 或 type 时,给它们实现方向函数或方法,这种实现称为 blanket impl 。例如为任意 T 类型实现 Borrow<T> trait:
// https://doc.rust-lang.org/src/core/borrow.rs.html#207
impl<T: ?Sized> Borrow<T> for T {
#[rustc_diagnostic_item = "noop_method_borrow"]
fn borrow(&self) -> &T {
self
}
}
// https://doc.rust-lang.org/src/core/convert/mod.rs.html#217
pub trait AsRef<T: ?Sized> {
/// Converts this type into a shared reference of the (usually inferred) input type.
#[stable(feature = "rust1", since = "1.0.0")]
fn as_ref(&self) -> &T;
}
// OsStr 是当前 crate 的类型
// https://doc.rust-lang.org/src/std/ffi/os_str.rs.html#1452
impl AsRef<OsStr> for String {
#[inline]
fn as_ref(&self) -> &OsStr {
(&**self).as_ref()
}
}
// str 是当前 crate 的类型
// https://doc.rust-lang.org/src/alloc/string.rs.html#2580
impl AsRef<str> for String {
#[inline]
fn as_ref(&self) -> &str {
self // self 为 &String 类型,编译器通过 Defref 转换为 &str
}
}
如果明确指定了泛型 trait 的类型参数, 则 impl 该 trait 时不需要使用 impl<T, U> 来指定泛型参数:
struct Container(i32, i32);
trait Contains<A, B> {
fn contains(&self, _: &A, _: &B) -> bool; // Explicitly requires `A` and `B`.
fn first(&self) -> i32;
fn last(&self) -> i32;
}
// 不需要使用 impl<i32,i32>
impl Contains<i32, i32> for Container {
fn contains(&self, number_1: &i32, number_2: &i32) -> bool {
(&self.0 == number_1) && (&self.1 == number_2)
}
fn first(&self) -> i32 { self.0 }
fn last(&self) -> i32 { self.1 }
}
Rust 不会自动通过 Deref trait 来解引用来满足泛型参数限界的要求:
use std::ops::{Deref, DerefMut};
impl<T> Deref for Selector<T> {
type Target = T;
fn deref(&self) -> &T { &self.elements[self.current] }
}
impl<T> DerefMut for Selector<T> {
fn deref_mut(&mut self) -> &mut T { &mut self.elements[self.current] }
}
// OK: 在函数传参时, Rust 会自动隐式解引用, &Selector -> &str
let s = Selector { elements: vec!["good", "bad", "ugly"], current: 2 };
fn show_it(thing: &str) { println!("{}", thing); }
show_it(&s);
// Error: 当使用 Trait 作为泛型参数的限界时, Rust 不会自动解引用到 &str 类型来满足类型限界的要求
use std::fmt::Display;
fn show_it_generic<T: Display>(thing: T) { println!("{}", thing); }
show_it_generic(&s);
// 两种解决办法:
show_it_generic(&s as &str); // 使用 as 类型转换;
show_it_generic(&*s) // 手动解引用 &*V 来得到 &str 类型:
20.2 supertrait #
trait 可以有多个父 trait(称为 supertrait),类型在实现该 trait 的同时也必须实现这些父 trait:
- supertrait 也支持 lifetime bound;
trait Person {
fn name(&self) -> String;
}
trait Student: Person { // 等效于 trait Student where Self: Person
fn university(&self) -> String;
}
trait Programmer {
fn fav_language(&self) -> String;
}
// 使用 + 运算符指定多个父 trait:
trait CompSciStudent: Programmer + Student {
fn git_username(&self) -> String;
}
trait Circle<'a> : Shape + 'a {
fn radius(&self) -> f64;
}
20.3 完全限定方法调用 #
类型可以实现不同 crate package 定义的同名 trait,它们可以有相同或不同的方法,所以在 VecK<u8> 上调用 trait 定义的方法时,必须先将对应的 trait 引入到作用域,否则 Rust 不知道该调用哪一个 trait 的方法实现:
- 位于 std::prelude::v1 module 中的 trait,如 From/Into/Cone/Iterator,会被自动导入到所有 std 程序中,故不需要手动导入。
use std::io::Write
let mut buf: Vec<u8> = vec![];
// write_all() 方法是 std::io::Write trait 定义的,调用它前需要引入 Write trait。
buf.write_all(b"hello")?;
trait Pilot {
fn fly(&self);
}
trait Wizard {
fn fly(&self);
}
struct Human;
impl Pilot for Human {
fn fly(&self) {
println!("This is your captain speaking.");
}
}
impl Wizard for Human {
fn fly(&self) {
println!("Up!");
}
}
impl Human {
fn fly(&self) {
println!("*waving arms furiously*");
}
}
fn main() {
let person = Human;
// 调用 Human 自身实现的 fly() 方法。
person.fly();
// 调用实现的 trait 的方法,这里为了避免歧义,使用的是完全限定方法调用,及 TraitName::method(object).
Pilot::fly(&person); // 等效于:<Human as Pilot>::fly(&person)
Wizard::fly(&person);
}
Pilot::fly(&person) 调用方式不适合没有 self 参数的关联函数:调用 trait 关联函数时,Rust 不能推导出调用哪一个类型实现的该关联函数,这时需要使用完全限定方法调用。
完全限定方法调用: Rust 中的完全限定语法(Fully Qualified Syntax)可以解决命名冲突或混淆的问题。这是因为你明确地指出了你想要调用特定 trait 的方法,即使你的类型对多个 trait 实现了同名的方法。
trait CalSum {
fn sum(&self, a: i32) -> i32;
}
trait CalSumV2 {
fn sum(&self, a: i32) -> i32;
}
#[derive(Clone, Copy, Debug)]
struct S1(i32);
impl CalSum for S1 {
fn sum(&self, a: i32) -> i32 {
self.0 + a
}
}
impl CalSumV2 for S1 {
fn sum(&self, a: i32) -> i32 {
self.0 + a
}
}
fn main() {
let s1 = S1(0);
// 调用指定 trait 的方法
println!("Results: {}", CalSum::sum(&s1, 1));
println!("Results: {}", CalSumV2::sum(&s1, 1));
// ERROR: S1 同时实现了 CalSum 和 CalSumV2, 它们都提供了 sum() 方法, Rust 不确定该调用哪一个.
//println!("Results: {}", s1.sum(1)); // Error: multiple `sum` found
// 使用完全限定方法调用.
println!("Results: {}", <S1 as CalSum>::sum(&s1, 1)); // OK
}
使用完全限定的语法 <Type as Trait>::function 来清楚地调用特定的 ‘sum’ 实现, 如 <S1 as
CalSum>::sum(&s1, 1) 明确表示我们要调用 S1 实现的 CalSum 的 sum() 方法。
在没有歧义的情况下, 可以直接调用对象实现的 trait 的方法, 而不需要使用完全限定调用的方式:
let i: i8 = Default::default();
let (x, y): (Option<String>, f64) = Default::default();
let (a, b, (c, d)): (i32, u32, (bool, bool)) = Default::default();
#[derive(Default)]
struct SomeOptions {
foo: i32,
bar: f32,
}
fn main() {
// 如果 SomeOptions 没有实现除 Default 外的其它 trait 的 default() 方法, 则<SomeOptions as
// Default>::default() 可以简写为 Default::default().
let options: SomeOptions = Default::default();
let options = SomeOptions { foo: 42, ..Default::default() };
}
20.4 trait object #
参考: https://quinedot.github.io/rust-learning/dyn-trait.html
dyn TraitName 称为 trait object,它是一个类型,表示实现 TraitName 的任意对象类型。
由于在编译时类型和大小不确定, 所以一般使用 &dyn TraitName 或 Box<dyn TraitName> 来表示, 它们都是胖指针,包含两个字段:指向动态对象内存的指针 + 该对象实现 trait 定义的各种方法的虚表(vtable) 的指针。
&dyn TraitName使用实现 TraitName 的对象引用赋值:let n: &dyn TraitName = &value;Box<dyn TraitName>使用 Box::new(value):let b: Box<dyn TraitName> = Box::new(value);
支持 trait object 的 trait 必须是对象安全(object safe)的,需要满足如下要求:
- Trait 方法不返回 Self,因为 trait object 是运行时派发,编译时不能对确定 Self 类型,故不能做检查;
- 解决办法:fn splice(&self, other: &Self) -> Self 修正为 fn splice(&self, other: &dyn MyTrait) -> Box<dyn MyTrait>
- Trait 方法没有任何泛型参数。
这是由于 trait object 在编译时是不知道自己具体类型的,而是在运行时动态派发,所以在编译器时,如果返回 Self,则编译器不能正确检查返回值合法性。同理,由于在运行时才能确定 trait object 的具体对象类型,所以在编译阶段是不能确认泛型参数的对应的实现类型,所以编译器也不能正确检查。
trait object,如 Box<dyn Trait + Send + ‘static> 的要求:
- 除了第一个 trait 外,其它 trait 只能是 auto trait ,包括:Send, Sync, Unpin, UnwindSafe 和 RefUnwindSafe。注意:不包含 ?Sized,Hash,Eq 等 trait。
- 最多指定一个 lifetime;
- trait 的路径可以用括号括起来,适用于复杂的定义场景;
// Rust 2021 前版本 dyn 关键字是可选的,2021 版本开始 dyn 关键字是必选的。
dyn Trait
dyn Trait + Send
dyn Trait + Send + Sync
dyn Trait + 'static
dyn Trait + Send + 'static
dyn Trait + Send + Sync + 'static
dyn (Trait)
dyn Trait + 'a // 可以为 trait object 指定 lifetime
dyn eviction::EvictionManager + Sync // 可以使用 path 来完整指定 trait
&(dyn MyTrait + Send) // 使用 & 时必须将 dyn 和后续的限制用括号括起来,否则会因歧义而报错。
两个 dyn trait 的 trait、lifetime 如果相同的话,则类型互为别名,例如:dyn Trait + Send + UnwindSafe 和 dyn Trait + UnwindSafe + Send 相同。
当使用 &dyn Trait 时,如果要指定 Send/lifetime 等,则需要使用 &mut (dyn Trait + Send + 'a) 格式 ,否则Rust 报错加号有歧义:
- 当参数类型是 &dyn Trait 时,需要传入实现该 Trait 的借用类型值,如 MyStruct 实现了 MyTrait, 则需要使用 &dyn Trait 的地方需要传入 &MyStruct 的值。
- 当参数类型是 &Box<dyn Trait> 时,不能传入 &Box::new(my_struct), Rust 报错类型不匹配,两个解决办法:
- 将参数类型修改为 Box<dyn Trait>, 后续可以直接传入 Box::new(my_struct);
- 或者,先创建一个 Box<dyn Triat> 的对象 b,然后再传入 &b;
trait MyTrait {
fn say_hello(&self);
}
struct MyStruct(String);
impl MyTrait for MyStruct {
fn say_hello(&self) {
println!("hello {}", self.0);
}
}
fn main() {
// let b = &'a dyn MyTrait + Send + 'static; // error: expected expression, found keyword `dyn`
// let b = &'a(dyn MyTrait + Send + 'static); // error: borrow expressions cannot be annotated with lifetimes
let my_struct = MyStruct("abc".to_string());
//printf_hello(Some(my_struct)); // expected `&dyn MyTrait`, found `MyStruct`
// printf_hello(Some(&'static my_struct)); // error: borrow expressions cannot be annotated with lifetimes: help: remove the lifetime annotation
printf_hello(Some(&my_struct));
// printf_hellov2(Some(&Box::new(my_struct))); // error[E0308]: mismatched types,expected `&Box<dyn MyTrait + Send>`, found `&Box<MyStruct>`
// 解决办法:先创建一个 Box 对象,然后再借用。
let st1: Box<dyn MyTrait + Send + 'static> = Box::new(my_struct);
printf_hellov2(Some(&st1));
let my_struct2 = MyStruct("def".to_string());
printf_hellov3(Some(Box::new(my_struct2)));
}
//fn printf_hello<'a>(say_hello: Option<&'a dyn MyTrait + Send>) { // error: ambiguous `+` in a type: use parentheses to disambiguate: `(dyn MyTrait + Send)`
fn printf_hello(say_hello: Option<&(dyn MyTrait + Send)>) {
if let Some(my_trait) = say_hello {
my_trait.say_hello();
}
}
fn printf_hellov2(say_hello: Option<&Box<dyn MyTrait + Send + 'static>>) {
// if let Some( &my_trait) = say_hello { // error[E0507]: cannot move out of `*say_hello` as enum variant `Some` which is behind a shared reference
if let Some(my_trait) = say_hello {
my_trait.say_hello();
}
}
fn printf_hellov3(say_hello: Option<Box<dyn MyTrait + Send + 'static>>) {
if let Some(my_trait) = say_hello {
my_trait.say_hello();
}
}
trait object 和泛型参数的差别:
- 对于使用 Trait bound 的泛型参数,在编译阶段 Rust 编译器是可以推断出一种实际具体类型,所以不能实例化出一类实现 trait 的类型。例如 Vec<T: Display> , 在编译器间实例化后只能保存一种实现 Display trait 的实例;
- 对于 trait object,在编译期间是不能实例化为单一类型,而是在运行时来根据调用方法的对象指针(类型)来查找编译期间构造的 vtab 来调用对应对象的方法。所以 Vec<&dyn Display> 是可以保存各种实现了 Display trait 的多种对象。
使用 Box 定义 trait object 时, 一般有三种标准格式, Rust 标准库为这三种格式定义了对应的方法和函数:
- Box<dyn TraitName + ‘static>
- Box<dyn TraitName + Send + ‘static>
- Box<dyn TraitName + Sync + Send + ‘static>
Fn/FnMut/FnOnce 等闭包函数也是 trait,故上面的 TraitName 可以是闭包函数,如: Box<dyn Fn(int32) -> int32>;
struct Sheep {}
struct Cow {}
trait Animal {
fn noise(&self) -> &'static str;
}
impl Animal for Sheep {
fn noise(&self) -> &'static str {
"baaaaah!"
}
}
impl Animal for Cow {
fn noise(&self) -> &'static str {
"moooooo!"
}
}
// Returns some struct that implements Animal, but we don't know which one at compile time.
fn random_animal(random_number: f64) -> Box<dyn Animal> {
if random_number < 0.5 {
Box::new(Sheep {})
} else {
Box::new(Cow {})
}
}
fn main() {
let random_number = 0.234;
let animal = random_animal(random_number);
println!("You've randomly chosen an animal, and it says {}", animal.noise());
}
trait MyTrait {
fn say_hello(&self);
}
struct MyStruct(String);
impl MyTrait for MyStruct {
fn say_hello(&self) {
println!("hello {}", self.0);
}
}
fn main() {
// error[E0308]: mismatched types,expected `&Box<dyn MyTrait + Send>`, found `&Box<MyStruct>`
// printf_hellov2(Some(&Box::new(my_struct)));
// 解决办法:先创建一个 Box 对象,然后再借用。
let st1: Box<dyn MyTrait + Send + 'static> = Box::new(my_struct);
printf_hellov2(Some(&st1));
}
fn printf_hellov2(say_hello: Option<&Box<dyn MyTrait + Send + 'static>>) {
// error[E0507]: cannot move out of `*say_hello` as enum variant `Some` which is behind a shared
// reference if let Some(&my_trait) = say_hello {
if let Some(my_trait) = say_hello {
my_trait.say_hello();
}
}
On-Stack Dynamic Dispatch: We can dynamically dispatch over multiple values, however, to do so, we
need to declare multiple variables to bind differently-typed objects. To extend the lifetime as necessary , we can use deferred conditional initialization, as seen below:
// https://rust-unofficial.github.io/patterns/idioms/on-stack-dyn-dispatch.html
use std::io;
use std::fs;
// These must live longer than `readable`, and thus are declared first:
let (mut stdin_read, mut file_read);
// We need to describe the type to get dynamic dispatch.
let readable: &mut dyn io::Read = if arg == "-" {
stdin_read = io::stdin();
&mut stdin_read
} else {
file_read = fs::File::open(arg)?;
&mut file_read
};
// Read from `readable` here.
// 使用 Box 更简洁,Box 拥有了 dyn io::Read
// We still need to ascribe the type for dynamic dispatch.
let readable: Box<dyn io::Read> = if arg == "-" {
Box::new(io::stdin())
} else {
Box::new(fs::File::open(arg)?)
};
// Read from `readable` here.
as 只能用于 primitive 或者 coerce trait object 类型的转换
// `as` expression can only be used to convert between primitive types or to coerce to a specific trait object
// let val: Box<dyn Any + 'a> = *val as Box<dyn Any + 'a>;
创建 Box<dyn MyTrait> 时,不能使用 Box::<dyn MyTrait>::new(value) 来创建,因为 Box new() 方法是定义在 impl <T> Box<T> 上的, T 没有任何 trait bound, 所以 T 默认是 Sized, 而 dyn MyTrait 是 un-sized 的, 所以编译报错. 解决办法是: 在返回值中指定 Box::<dyn MyTrait> 类型, 让 Rust 编译器自动转换:
let val: Box<dyn Any + 'a> = Box::new(*val); // OK
// function or associated item cannot be called on `Box<dyn Any>` due to unsatisfied trait bounds,
// 115 | pub trait Any: 'static {
// | ---------------------- doesn't satisfy `dyn std::any::Any: std::marker::Sized`
// let val: Box<dyn Any + 'a> = Box::<dyn Any + 'a>::new(*val);
// Box::<&dyn Any>::new() 是 OK 的, 因为 &dyn Any 是 Sized 对象.
// let val: Box<&dyn Any> = Box::<&dyn Any>::new(&val);
20.5 Default trait object lifetime #
dyn Trait 的 lifetime 规则:
Box<dyn Trait>等效于Box<dyn Trait + 'static>;&'x Box<dyn Trait>等效于&'x Box<dyn Trait + 'static>;&'a dyn Foo等效于&'a (dyn Foo + 'a);- 因为 &‘a T 隐式声明了 T: ‘a;
- &‘a (dyn Foo + ‘a) 表示 dyn Foo 的 trait object 的 lifetime 要比 ‘a 长,同时它的引用也要比’a 长;
&'r Ref<'q, dyn Trait>等效于&'r Ref<'q, dyn Trait+'q>;
https://doc.rust-lang.org/reference/lifetime-elision.html#default-trait-object-lifetimes
// For the following trait...
trait Foo { }
// These two are the same because Box<T> has no lifetime bound on T
type T1 = Box<dyn Foo>;
type T2 = Box<dyn Foo + 'static>;
// ...and so are these:
impl dyn Foo {}
impl dyn Foo + 'static {}
// ...so are these, because &'a T requires T: 'a
type T3<'a> = &'a dyn Foo;
type T4<'a> = &'a (dyn Foo + 'a);
// std::cell::Ref<'a, T> also requires T: 'a, so these are the same
type T5<'a> = std::cell::Ref<'a, dyn Foo>;
type T6<'a> = std::cell::Ref<'a, dyn Foo + 'a>;
// This is an example of an error.
struct TwoBounds<'a, 'b, T: ?Sized + 'a + 'b> {
f1: &'a i32,
f2: &'b i32,
f3: T,
}
type T7<'a, 'b> = TwoBounds<'a, 'b, dyn Foo>;
// ^^^^^^^
// Error: the lifetime bound for this object type cannot be deduced from context
// For the following trait...
trait Bar<'a>: 'a { }
// ...these two are the same:
type T1<'a> = Box<dyn Bar<'a>>;
type T2<'a> = Box<dyn Bar<'a> + 'a>;
// ...and so are these:
impl<'a> dyn Bar<'a> {}
impl<'a> dyn Bar<'a> + 'a {}
理解 Box<dyn Trait> 等效于 Box<dyn Trait + 'static>:
- 使用 Box::new(value) 来赋值, 其中 value 的类型实现了 Trait. value 所有权被转移到 Box 中, 所以相当于 Box 可以随意决定 value 的生命周期, 相当于具有了 ‘static 语义.
- 当将一个对象被转移给函数时,该对象满足函数的 ‘static 要求(因为转移给函数后,函数可以自由决定对象的
生命周期). 如果对象有借用,则不能转移给函数;
let Box<dyn Trait> = Box::new(value);
// 表示 Parent 的生命周期可以任意长,但是当 parent 被 drop 时,child 也会被 drop,从而释放 dyn
// OtherTrait 对象。
struct Parent {
child: Box<dyn OtherTrait + 'static>,
}
// 另一个例子
use std::collections::HashMap;
trait App {}
struct AppRegistry {
apps: HashMap<String, Box<dyn App>>,
}
impl AppRegistry {
fn new() -> AppRegistry {
Self { apps: HashMap::new() }
}
fn add(&mut self, name: &str, app: impl App + 'static) {
self.apps.insert(name.to_string(), Box::new(app));
}
}
struct MyApp {}
impl App for MyApp {}
fn main() {
let mut registry = AppRegistry::new();
registry.add("thing", MyApp {}); // paas by value 传递对象,这时 add 方法相当于拥有了这个对象,所以满足 'static
println!("apps: {}", registry.apps.len());
}
One thing to realize is that lifetimes in Rust are never talking about the lifetime of a value,
instead they are upper bounds on how long a value can live. If a type is annotated with a lifetime,
then it must go out of scope before that lifetime ends, but there’s no requirement that it lives for
the entire lifetime.
https://doc.rust-lang.org/reference/lifetime-elision.html
The assumed lifetime of references held by a trait object is called its default object lifetime bound . These were defined in RFC 599 and amended in RFC 1156.
These default object lifetime bounds are used instead of the lifetime parameter elision rules
defined above when the lifetime bound is omitted entirely. If ‘_ is used as the lifetime bound then
the bound follows the usual elision rules.
如果 trait object 作为 trait bound, 且没有指定 lifetime bound, 则使用这里说明的 defualt trait object lifetime bound.
如果为 trait object 指定 ‘_ liftime bound, 则使用 lifetime elide rule 来自动添加 lifetime。
If the trait object is used as a type argument of a generic type then the containing type is first used to try to infer a bound.
- If there is
a unique boundfrom the containing type then that is the default - If there is more than one bound from the containing type then an explicit bound
must be specified
If neither of those rules apply, then the bounds on the trait are used:
- If the trait is defined with
a single lifetime boundthen that bound is used. - If ‘static is used for any lifetime bound then
'staticis used. - If the trait has no lifetime bounds, then the lifetime is
inferred in expressions and is 'static outside of expressions.
// For the following trait...
trait Foo { }
// 下面这些 T1 到 T7 都是将 trait object 用作 type argument, 所以先检查对应 containing type 的
// lifetime 来推导 trait object 的 lifetime。主要是 3 条规则:
// 1. 如果 containing type 没有 lifetime,如 T1/T2 则使用 'static;
// 2. 如果 containing type 只指定了一个 lifetime, 则使用对应的 lifetime, 如 T3/T4/T5/T6;
// 3. 如果 containing type 有多个 lifetime,则必须为 trit object 明确指定 liftime
// These two are the same because Box<T> has no lifetime bound on T
type T1 = Box<dyn Foo>;
type T2 = Box<dyn Foo + 'static>;
// ...and so are these:
impl dyn Foo {}
impl dyn Foo + 'static {}
// ...so are these, because &'a T requires T: 'a
// 首先检查 containing type 是否有 lifetime,如果有的话且唯一,则使用它。
// 这里的 containing type 指的是 &'a dyn Foo 中的 &'a.
type T3<'a> = &'a dyn Foo;
type T4<'a> = &'a (dyn Foo + 'a);
// std::cell::Ref<'a, T> also requires T: 'a, so these are the same
type T5<'a> = std::cell::Ref<'a, dyn Foo>;
type T6<'a> = std::cell::Ref<'a, dyn Foo + 'a>;
// This is an example of an error.
struct TwoBounds<'a, 'b, T: ?Sized + 'a + 'b> {
f1: &'a i32,
f2: &'b i32,
f3: T,
}
type T7<'a, 'b> = TwoBounds<'a, 'b, dyn Foo>;
// ^^^^^^^
// Error: the lifetime bound for this object type cannot be deduced from context
// 如果 trait object 不是作为 type argument,而是用于赋值,则使用对应目标类型的 trait bound 来决定
// trait object 的 lifetime:
//
// 1. 如果目标 trait 只有一个 lifetime, 则使用它;
// 2. 如果目标没有 lifetime,则使用 'static 或从 expression 推导;
Note that the innermost object sets the bound, so &'a Box<dyn Foo> is still &'a Box<dyn Foo + 'static> .
// For the following trait...
trait Bar<'a>: 'a { }
// ...these two are the same:
type T1<'a> = Box<dyn Bar<'a>>;
type T2<'a> = Box<dyn Bar<'a> + 'a>;
// ...and so are these:
impl<'a> dyn Bar<'a> {}
impl<'a> dyn Bar<'a> + 'a {}
20.6 impl trait #
impl TraitName 或 &impl TraintName 和泛型类型参数类似, 也是在编译时实例化为一种特定类型, 但不支持运行时动态派发。
impl Traitname 的主要使用场景是简化泛型参数约束的复杂性,如函数返回一个复杂的多种嵌套迭代器时,该类型可能只有编译器才能准确写出来,这时可以用 impl TraitName 来简化返回参数类型。例如将
iter::Cycle<iter::Chain<IntoIter<i32>, IntoIter<i32>>> 简化为 impl Iterator<Item=i32>。
impl trait 可以作为函数输入参数和返回值类型:
- 但是不能作为泛型参数的 bound,因为 impl trait 被编译时实例化为具体类型,所以不用用于泛型参数限界。
// impl trait 作为函数参数的类型时,不需要引入泛型函数。
fn print_it1(input: impl Debug + 'static ) {
println!( "'static value passed in is: {:?}", input );
}
// 等效为泛型参数版本,这个版本的优势是实例化时可以指定 T 的类型,但是 impl Debug 不行。
fn print_it<T: Debug + 'static>(input: T) {
println!( "'static value passed in is: {:?}", input );
}
use std::iter;
use std::vec::IntoIter;
fn combine_vecs_explicit_return_type(v: Vec<i32>, u: Vec<i32>,
) -> iter::Cycle<iter::Chain<IntoIter<i32>, IntoIter<i32>>> {
v.into_iter().chain(u.into_iter()).cycle()
}
// 等效为
fn combine_vecs(v: Vec<i32>, u: Vec<i32>, ) -> impl Iterator<Item=i32> {
v.into_iter().chain(u.into_iter()).cycle()
}
由于闭包 Fn 也是 trait,所以函数可以返回 Box<dyn Fn() -> i32> 或 impl Fn() -> i32:
fn make_adder_function(y: i32) -> impl Fn(i32) -> i32 {
let closure = move |x: i32| { x + y };
closure
}
fn main() {
let plus_one = make_adder_function(1);
assert_eq!(plus_one(2), 3);
}
fn returns_closure() -> Box<dyn Fn(i32) -> i32> {
Box::new(|x| x + 1) // 堆分配空间,性能差些
}
fn returns_closure() -> impl Fn(i32) -> i32 {
|x| x + 1 // 栈分配,性能好
}
20.7 运算符重载 trait #
| Operator | Trait |
|---|---|
| + | Add |
| - | Sub |
| * | Mul |
| % | Rem |
== and != |
PartialEq |
| <, >, <=, and >= | PartialOrd |
PartialEq 只包含 eq 或 ne,而 PartialOrd 只需要实现 partial_cmp() 方法,则可以实现各种大小比较关系。
类型实现 std::ops 下的各 trait 以实现运算符重载:
use std::ops;
struct Foo;
struct Bar;
#[derive(Debug)]
struct FooBar;
#[derive(Debug)]
struct BarFoo;
// The `std::ops::Add` trait is used to specify the functionality of `+`. Here, we make `Add<Bar>`
// - the trait for addition with a RHS of type `Bar`. The following block implements the operation:
// Foo + Bar = FooBar
impl ops::Add<Bar> for Foo {
type Output = FooBar;
fn add(self, _rhs: Bar) -> FooBar {
println!("> Foo.add(Bar) was called");
FooBar
}
}
// By reversing the types, we end up implementing non-commutative addition. Here, we make
// `Add<Foo>` - the trait for addition with a RHS of type `Foo`. This block implements the
// operation: Bar + Foo = BarFoo
impl ops::Add<Foo> for Bar {
type Output = BarFoo;
fn add(self, _rhs: Foo) -> BarFoo {
println!("> Bar.add(Foo) was called");
BarFoo
}
}
fn main() {
println!("Foo + Bar = {:?}", Foo + Bar);
println!("Bar + Foo = {:?}", Bar + Foo);
}
可以使用 derive 宏来自动生成 PartialEq,PartialOrd 的实现:
#[derive(PartialEq)]
struct Ticket {
title: String,
description: String,
status: String
}
20.8 PhantomData #
PhantomData 是一个 zero-sized 泛型 struct, 唯一的一个值是 PhantomData,主要的用处是通过编译时检查:
pub struct PhantomData<T> where T: ?Sized;
使用举例:
- lifetime:
// Error: 没有 field 使用 'a
struct Slice<'a, T> {
start: *const T,
end: *const T,
}
// OK: 用 0 长字段来使用 'a
use std::marker::PhantomData;
struct Slice<'a, T> {
start: *const T,
end: *const T,
phantom: PhantomData<&'a T>, // 表示 T: 'a, 即 T 对象的引用的生命周期要比 'a 长。
}
- 隐藏数据:
use std::marker::PhantomData;
// A phantom tuple struct which is generic over `A` with hidden parameter `B`.
#[derive(PartialEq)] // Allow equality test for this type.
struct PhantomTuple<A, B>(A, PhantomData<B>);
// A phantom type struct which is generic over `A` with hidden parameter `B`.
#[derive(PartialEq)] // Allow equality test for this type.
struct PhantomStruct<A, B> { first: A, phantom: PhantomData<B> }
// Note: Storage is allocated for generic type `A`, but not for `B`.
// Therefore, `B` cannot be used in computations.
fn main() {
// Here, `f32` and `f64` are the hidden parameters.
// PhantomTuple type specified as `<char, f32>`.
let _tuple1: PhantomTuple<char, f32> = PhantomTuple('Q', PhantomData);
// PhantomTuple type specified as `<char, f64>`.
let _tuple2: PhantomTuple<char, f64> = PhantomTuple('Q', PhantomData);
// Type specified as `<char, f32>`.
let _struct1: PhantomStruct<char, f32> = PhantomStruct { first: 'Q', phantom: PhantomData, };
// Type specified as `<char, f64>`.
let _struct2: PhantomStruct<char, f64> = PhantomStruct { first: 'Q', phantom: PhantomData, };
// Compile-time Error! Type mismatch so these cannot be compared:
// println!("_tuple1 == _tuple2 yields: {}",
// _tuple1 == _tuple2);
// Compile-time Error! Type mismatch so these cannot be compared:
// println!("_struct1 == _struct2 yields: {}",
// _struct1 == _struct2);
}
- 编译时类型检查:
use std::ops::Add;
use std::marker::PhantomData;
/// Create void enumerations to define unit types.
#[derive(Debug, Clone, Copy)]
enum Inch {}
#[derive(Debug, Clone, Copy)]
enum Mm {}
/// `Length` is a type with phantom type parameter `Unit`,
/// and is not generic over the length type (that is `f64`).
///
/// `f64` already implements the `Clone` and `Copy` traits.
#[derive(Debug, Clone, Copy)]
struct Length<Unit>(f64, PhantomData<Unit>);
/// The `Add` trait defines the behavior of the `+` operator.
impl<Unit> Add for Length<Unit> {
type Output = Length<Unit>;
// add() returns a new `Length` struct containing the sum.
fn add(self, rhs: Length<Unit>) -> Length<Unit> {
// `+` calls the `Add` implementation for `f64`.
Length(self.0 + rhs.0, PhantomData)
}
}
fn main() {
// Specifies `one_foot` to have phantom type parameter `Inch`.
let one_foot: Length<Inch> = Length(12.0, PhantomData);
// `one_meter` has phantom type parameter `Mm`.
let one_meter: Length<Mm> = Length(1000.0, PhantomData);
// `+` calls the `add()` method we implemented for `Length<Unit>`.
//
// Since `Length` implements `Copy`, `add()` does not consume
// `one_foot` and `one_meter` but copies them into `self` and `rhs`.
let two_feet = one_foot + one_foot;
let two_meters = one_meter + one_meter;
// Addition works.
println!("one foot + one_foot = {:?} in", two_feet.0);
println!("one meter + one_meter = {:?} mm", two_meters.0);
// Nonsensical operations fail as they should:
// Compile-time Error: type mismatch.
//let one_feter = one_foot + one_meter;
}
20.9 Copy/Clone #
Copy 是 Clone 的 子 trait, 所以在实现 Copy 的同时也必须实现 Clone. Copy 是一个 marker trait, 不需要实现特定的方法.
pub trait Copy: Clone { }
Clone 和 Copy 的差别:
- Copy 是 Rust 隐式调用的(如变量赋值, 传参等), 不能被重载或控制, 做的是 simple bit-wise copy.
- Clone 是需要明确调用的方法, 如 x.clone(), 在具体实现时, 可能会 copy the point-to buffer in the heap, 而不向 Copy 那样可能值会做栈空间的拷贝(如指针拷贝).
默认实现 Copy 的情况:
- 基本类型, 如整型, 浮点型, bool, char,
- Option<T>, Result<T,E>, Bound<T>, 共享引用 &T, 如 &str;
- 数组 [T;N], 元组 (T, T): 前提: 元素类型 T 实现了 Copy;
没有实现 Copy 的情况:
- 自定义的 Struct/Enum;
- std::collections 中的各种容器类型, 如 Vec/HashMap/HashSet; (但都实现了 Clone)
- &mut T 没有实现 Copy, 但是 &T 实现了 Copy.
- 任何实现了 Drop 的对象也没有实现 Copy.
- 各种智能指针,如 Box/Rc/Arc/Ref 都没有实现 Copy。
实现 Copy 方式: derive 宏或手动实现.
// OK: i32 实现了 Copy
#[derive(Copy, Clone)]
struct Point {
x: i32,
y: i32,
}
// 错误: Vec<T> 没有实现 Copy
// the trait `Copy` cannot be implemented for this type; field `points` does not implement `Copy`
#[derive(Copy, Clone)]
struct PointList {
points: Vec<Point>,
}
// OK: 因为 &T 实现了 Copy, 即使 T 没有实现 Copy, &T 也实现了 Copy
#[derive(Copy, Clone)]
struct PointListWrapper<'a> {
point_list_ref: &'a PointList,
}
// 或者
struct MyStruct;
impl Copy for MyStruct { }
impl Clone for MyStruct {
fn clone(&self) -> MyStruct {
*self
}
}
20.10 Default #
https://doc.rust-lang.org/stable/std/default/trait.Default.html
按照惯例, 各类型使用 new() 关联函数来作为类型的 constructor. Rust 并没有强制所有类型都实现该方法, 但是它提供了 Default trait, 各类型可以实现该 trait 提供的 default() -> Self 方法:
/// Time in seconds.
///
/// # Example
///
/// ```
/// let s = Second::default();
/// assert_eq!(0, s.value());
/// ```
pub struct Second {
value: u64,
}
impl Second {
/// Returns the value in seconds.
pub fn value(&self) -> u64 {
self.value
}
}
impl Default for Second {
fn default() -> Self {
Self { value: 0 }
}
}
Default can also be derived if all types of all fields implement Default, like they do with Second:
use std::{path::PathBuf, time::Duration};
// note that we can simply auto-derive Default here.
#[derive(Default, Debug, PartialEq)]
struct MyConfiguration {
// Option defaults to None
output: Option<PathBuf>,
// Vecs default to empty vector
search_path: Vec<PathBuf>,
// Duration defaults to zero time
timeout: Duration,
// bool defaults to false
check: bool,
}
impl MyConfiguration {
// add setters here
}
fn main() {
// construct a new instance with default values
let mut conf = MyConfiguration::default(); // 调用 Default trait 的 default() 方法来创建对象.
// do something with conf here
conf.check = true;
println!("conf = {conf:#?}");
// partial initialization with default values, creates the same instance
let conf1 = MyConfiguration {
check: true,
..Default::default() // struct 对象部分输出化, 没有指定的 field 都使用 default() 方法的值来填充.
};
assert_eq!(conf, conf1);
}
// 另一个例子
#[derive(Default)]
struct SomeOptions {
foo: i32,
bar: f32,
}
fn main() {
let options: SomeOptions = Default::default();
// 自动根据目标类型调用对应实现的方法, 等效于 <SomeOptions as Default>::default()
}
对于 enum 类型, 需要明确定义哪一个是 default:
#[derive(Default)]
enum Kind {
#[default]
A,
B,
C,
}
// 或者
enum Kind {
A,
B,
C,
}
impl Default for Kind {
fn default() -> Self { Kind::A }
}
Rust 基本类型和 &str, &CStr, &OsStr, Box<str>, Box<CStr>, Box<OsStr>, CString, OsString, Error, PathBuf, String, &[T], Option<T>, [T; N], Rc<T>, Arc<T>, Vec<T>, HashSet<T, S> 等都实现了 Default.
Default trait 作为泛型类型的定界, 在标准库中得到广泛使用, 例如:
- 很多 Option::unwrap_or_default() 方法;
- std::mem::take(&mut T) 将 T 的值 move 出来,然后将原始的 T 的值用他的 Default 填充;
let x: Option<u32> = None;
let y: Option<u32> = Some(12);
assert_eq!(x.unwrap_or_default(), 0);
assert_eq!(y.unwrap_or_default(), 12);
20.11 Drop #
Drop trait 为对象提供了自定义析构能力, 一般在对象离开 scope 时由编译器自动调用来释放资源:
- Box, Vec, String, File, and Process 都实现了 Drop;
- 不能直接调用对象的 drop() 方法来直接释放资源,这样会导致对象离开作用域被二次释放。但是可以调用 drop(obj) 或 std::mem::drop/forget 来手动释放对象,这时 Rust 不会再自动释放它:
fn bar() -> Result<(), ()> {
// These don't need to be defined inside the function.
struct Foo;
// Implement a destructor for Foo.
impl Drop for Foo {
fn drop(&mut self) {
println!("exit");
}
}
// The dtor of _exit will run however the function `bar` is exited.
let _exit = Foo;
// Implicit return with `?` operator.
baz()?;
// Normal return.
Ok(())
}
Drop 在程序 panic 时也会被执行: Code in destructors will (nearly) always be run - copes with panics, early returns, etc.
20.12 From/Into: #
自定义类型一般只需实现 From,Rust 会自动生成相反方向的 Into。
use std::convert::From;
#[derive(Debug)]
struct Number {
value: i32,
}
impl From<i32> for Number {
fn from(item: i32) -> Self {
Number { value: item }
}
}
fn main() {
let num = Number::from(30);
println!("My number is {:?}", num);
}
Into 一般作用在泛型函数的限界场景中,例如:
pub fn stdout<T: Into<Stdio>>(&mut self, cfg: T) -> &mut Command
Rust 中实现了 `From` trait 的类型,会在以下场景自动调用:
Into trait规定了任何实现了From<T>的类型,自动实现Into<U>。
let from_type: FromType = FromType::new();
let into_type: IntoType = from_type.into(); // 自动调用 From<FromType> for IntoType 的实现
- 使用 `?` 运算符处理 `Result` 或 `Option` 错误在返回错误时,将错误类型转换为函数返回的错误类型。
fn from_type() -> Result<IntoType, IntoError> {
let result: Result<FromType, FromError> = do_something_may_fail();
let from_type = result?; // 如果出错,自动调用 From<FromError> for IntoError 的实现并返回
}
the standard library gives us a blanket From impl for converting from anything that implements Error to a Box<dyn Error>, which ? automatically uses :
impl<'a, E: Error + Send + Sync + 'a> From<E> for Box<dyn Error + Send + Sync + 'a> {
fn from(err: E) -> Box<dyn Error + Send + Sync + 'a> {
Box::new(err)
}
}
type GenericError = Box<dyn std::error::Error + Send + Sync + 'static>;
type GenericResult<T> = Result<T, GenericError>;
fn parse_i32_bytes(b: &[u8]) -> GenericResult<i32> {
Ok(std::str::from_utf8(b)?.parse::<i32>()?)
}
- `collect` 方法将 `Iterator<Item=T>` 转换为其他容器类型。
let vec: Vec<FromType> = get_some_from_types();
let result: Result<Vec<IntoType>, _> = vec.into_iter().collect(); // 自动调用 From<FromType> for IntoType 的实现
- `std::convert::from` 函数会显式调用 `From` trait。
let from_type = FromType::new();
let into_type:IntoType = std::convert::From::from(from_type); // 显式调用 From<FromType> for IntoType 的实现
变量赋值和函数返回值: 如 &str 实现了 Into Box<dyn std::error::Error> 的 trait, 则可以直接调用 into() 方法:
- 如果 impl From<T> for U, 则可以 let u: U = U::from(T) 或 let u:U = T.into().
fn main() {
if let Err(e) = run_app() {
eprintln!("Application error: {}", e);
std::process::exit(1);
}
}
fn run_app() -> Result<(), Box<dyn std::error::Error>> {
// 代码逻辑
// Ok(()) 执行这行将会正常返回0
return Err("main will return 1".into());
}
trait Into<t>: Sized {
fn into(self) -> T; // ownership 方法,将之声转换为 T 对象
}
trait From<T>: Sized {
fn from(other: T) -> Self; // 关联函数,ownership 传入的 T 对象
}
use std::net::Ipv4Addr;
fn ping<A>(address: A) -> std::io::Result<bool> where A: Into<Ipv4Addr> // A 是任意能转换为 Ipv4Addr 的类型
{
let ipv4_address = address.into();
// ...
}
其他情况下,Rust 并不会自动调用 From/Into trait:
20.13 FromStr/ToString #
从 string 来生成各种类型的值:
- 一般被 &str.parse::<T>() 方法隐式调用。
- rust 的基本类型,如整数、浮点数、bool、char、String、PathBuf、IpAddr、SocketAddr、Ipv4Addr、 Ipv6Addr 都实现了该 trait。
pub trait FromStr: Sized {
type Err;
// Required method
fn from_str(s: &str) -> Result<Self, Self::Err>;
}
str 的 parse::<T>() 方法用于将字符串转换为其它对象:
pub fn parse<F>(&self) -> Result<F, <F as FromStr>::Err>
where
F: FromStr,
在使用 &str.parse() 方法时一般需要指定目标对象类型,否则 rustc 不支持该调用哪个类型的 FromStr 实现:
- 注意:只支持目标类型本身,而不是它的 &T 或 &mut T;
let four: u32 = "4".parse().unwrap();
assert_eq!(4, four);
let four = "4".parse::<u32>();
assert_eq!(Ok(4), four);
// Error
let nope = "j".parse::<u32>();
assert!(nope.is_err());
如果类型实现了 ToString trait,则可以用它生成一个 String。rust 对于任意实现了 Display trait 的类型自动实现了 ToString trait。
use std::fmt;
struct Circle {
radius: i32
}
impl fmt::Display for Circle {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
write!(f, "Circle of radius {}", self.radius)
}
}
fn main() {
let circle = Circle { radius: 6 };
println!("{}", circle.to_string());
}
20.14 FromIterator/IntoIterator #
FromIterator: 从一个实现了 IntoIterator<Item=A> 的迭代器创建一个 Self 类型对象:
pub trait FromIterator<A>: Sized {
// Required method
fn from_iter<T>(iter: T) -> Self
where T: IntoIterator<Item = A>;
}
如果一个类型 B 实现了 FromIterator<Iterm=A>, 则可以从能迭代生产 A 的迭代器生产 B。FromIterator 的典型使用场景是 IntoIterator 的 collect::<TargetType>() 方法,用于将前序迭代器对象的值生产一个 TargetType。
IntoIterator 是 for item in type 迭代语句对 type 的要求,即 type 要实现 IntoIterator 才能被 for 迭代:
pub trait IntoIterator {
type Item;
type IntoIter: Iterator<Item = Self::Item>;
// Required method
fn into_iter(self) -> Self::IntoIter;
}
20.15 Extend #
std::iter::Extend trait 定义:
pub trait Extend<A> {
// Required method
fn extend<T>(&mut self, iter: T)
where T: IntoIterator<Item = A>;
// Provided methods
fn extend_one(&mut self, item: A) { ... }
fn extend_reserve(&mut self, additional: usize) { ... }
}
主要用于消费传入的迭代器,将元素插入到自身集合中。Rust 的各种集合类型都实现了 Extend trait:
// You can extend a String with some chars:
let mut message = String::from("The first three letters are: ");
message.extend(&['a', 'b', 'c']);
assert_eq!("abc", &message[29..32]);
20.16 Try #
? 运算法可以用于 Result/Option, 它可以使用 std::ops::Try trait 来自定义:
- Try trait 用于自定义 The ? operator and try {} blocks.
pub trait Try: FromResidual {
type Output;
type Residual;
// Required methods
fn from_output(output: Self::Output) -> Self;
fn branch(self) -> ControlFlow<Self::Residual, Self::Output>;
}
20.17 AsRef/AsMut #
例如 std::fs:<:open> 函数的声明:open 的实现依赖于 &Path,通过限定 P 实现了 AsRef<Path>,在 open 内部就可以通过 P.as_ref() 方法调用返回 &Path 的类型对象。
fn open<P: AsRef<Path>>(path: P) -> Result<file>
标准库各种类型,如 String/str/OsString/OsStr/PathBuf/Path 等都实现了 AsRef<Path>, 所以都可以作为 open 的参数输入:
// https://doc.rust-lang.org/src/std/path.rs.html#3170
impl AsRef<Path> for String {
#[inline]
fn as_ref(&self) -> &Path {
Path::new(self)
}
}
20.18 Index/IndexMut #
a 可以实现 Index trait 和 IndexMutt trait, 前者的 index() 返回 &Self::Output, 后者的 index_mut() 返回 &mut Self::Output;
a[i] 是 *a.index(i) 的简写形式,它返回一个对象而非引用,这是由于 index() 方法返回的是对象的不可变引用。返回一个对象的好处是,可以作为左值使用,例如 a[i] = 3;
rust 根据 a[xx] 操作中的 xx 类型,自动生成对应的 RangeXX struct 类型:
- Range: m..n
- RangeFrom: m..
- RangeFull: ..
- RangeInclusive: m..=n
- RangeTo: ..n
- RangeToInclusive: ..=n
然后创建一个 SliceIndex<str> 或 SliceIndex<T> 类型,调用他的 index() 方法返回 或 &str 或 &T 对象,再解引用获得 &str 或 T 对象。
rust 编译器根据 a[i] 索引表达式出现的上下文来自动选择 index() 或 index_mut() 方法。
对 &[T] 使用 index 操作时,返回的是 &[T] 类型。
#[stable(feature = "rust1", since = "1.0.0")]
impl<I> ops::Index<I> for str
where
I: SliceIndex<str>,
{
type Output = I::Output;
#[inline]
fn index(&self, index: I) -> &I::Output {
index.index(self)
}
}
// 然后查看那些类型实现了 SliceIndex<str>,然后获得他的 Output 关联类型。在 SliceIndex 的文档页面的
// Implementors 部分可以看到实现 SliceIndex<str> 的类型列表:
// std/slice/trait.SliceIndex.html#implementors
impl SliceIndex<str> for (Bound<usize>, Bound<usize>)
type Output = str
impl SliceIndex<str> for Range<usize>
type Output = str
impl SliceIndex<str> for RangeFrom<usize>
type Output = str
impl SliceIndex<str> for RangeFull
type Output = str
impl SliceIndex<str> for RangeInclusive<usize>
type Output = str
impl SliceIndex<str> for RangeTo<usize>
type Output = str
impl SliceIndex<str> for RangeToInclusive<usize>
type Output = str
20.19 Borrow/ToOwned/Cow #
Borrow 和 BorrowMut 和 AsRef/AsMut 类似,Borrow<T> 是从自身创建一个 &T 的借用,但是它要求 &T 必须和 Self 能以相同的方式进行哈希和比较时,Self 才应该实现 Borrow<T>。Rust 编译器并不会强制该限制,但是 Borrow 有这种约定的意图。
String 实现了 AsRef<str>, AsRef<[u8]>, AsRef<Path>, 但是只有 String 和 &str 才能保证做相同的 hash,所以 String 只实现按了 Borrow<str>.
Borrow 用于解决泛型哈希表和其他关联集合类型的情况:K 和 Q 都是 Eq + Hash 语义,K: Borrow<Q> 表示可以从 K 对象生成 &Q 的引用。所以可以给 HashMap 的 get() 方法传入任何满足上面两个约束的引用对象,在 get() 方法的内部实现中,会从自身的 K.borrow() 生成 &Q 对象,然后用 K 的 Eq+Hash 值于 Q 的 Eq+Hash 值进行比较。
- self 一般是 owned 类型, 如 String/PathBuf/OsString/Box/Arc/Rc 等, borrow 的结果是对应的 unsized 类型, 如 &str/&Path/&OsStr/&T;
impl<K,V> HashMap<K, V> where K: Eq + Hash
{
// key 必须是借用类型 &Q,而且需要 K 实现了 Borrow<Q>
fn get<Q: ?Sized>(&self, key: &Q) -> Option<&V>
where K: Borrow<Q>,
Q: Eq + Hash
// ...
}
例如,String 实现了 Borrow<str> 和 Borrow<String>, 所以 HashMap<String, i32> 的 get() 方法可以传入 &String 或 &str 类型的 key。
实现 Borrow 的类型如下:
// 从 Ownerd 类型生成 unsized 的类型引用
impl Borrow<str> for String
impl Borrow<CStr> for CString
impl Borrow<OsStr> for OsString
impl Borrow<Path> for PathBuf
impl<'a, B> Borrow<B> for Cow<'a, B> where B: ToOwned + ?Sized,
impl<T> Borrow<T> for &T where T: ?Sized,
impl<T> Borrow<T> for &mut T where T: ?Sized,
impl<T> Borrow<T> for T where T: ?Sized,
impl<T, A> Borrow<[T]> for Vec<T, A> where A: Allocator,
impl<T, A> Borrow<T> for Box<T, A> where A: Allocator, T: ?Sized,
impl<T, A> Borrow<T> for Rc<T, A> where A: Allocator, T: ?Sized,
impl<T, A> Borrow<T> for Arc<T, A> where A: Allocator, T: ?Sized,
impl<T, const N: usize> Borrow<[T]> for [T; N] // &[T;N] -> &[T]
反过来, 由 Borrow trait 创建的类型,如 str, 也实现了 ToOwned trait, 将 &T 转换为 Owned 类型, 如:
- &str -> String
- &CStr -> CString
- &OsStr -> OsString
- &Path -> PathBuf
- &[T] -> Vec<T>
- &T -> T
pub trait ToOwned {
type Owned: Borrow<Self>; // Ownerd 是实现了 Borrow<Self> 的任意类型
// Required method
fn to_owned(&self) -> Self::Owned;
// Provided method
fn clone_into(&self, target: &mut Self::Owned) { ... }
}
// 实现 ToOwned 的类型都是 unsized 类型, 它们的 Owned 类型都是 sized 版本
impl ToOwned for str type Owned = String
impl ToOwned for CStr type Owned = CString
impl ToOwned for OsStr type Owned = OsString
impl ToOwned for Path type Owned = PathBuf
impl<T> ToOwned for [T] where T: Clone, type Owned = Vec<T>
impl<T> ToOwned for T where T: Clone, type Owned = T
// 示例
let s: &str = "a";
let ss: String = s.to_owned();
let v: &[i32] = &[1, 2];
let vv: Vec<i32> = v.to_owned();
Clone 和 ToOwned 的区别:
- 相同点: 两者都可以从 &self -> Self, 也即 &T -> T;
- 不同点: Clone trait 只能实现 &T -> T 的转换, 而 ToOwned trait 可以更灵活, 转换后的对象不局限于 T,只要 Owned 类型实现了 Borrow<Self> 就可以转换为该 Owned 类型. 例如 String 实现了 Borrow<str>, 则 &str 就可以转换为 Owned 类型为 String 的对象.
std::borrow::Cow 是一个同时可以保存 &B 和 B owned 类型的枚举类型:
pub enum Cow<'a, B>
where
B: 'a + ToOwned + ?Sized,
{
Borrowed(&'a B), // &B
Owned(<B as ToOwned>::Owned), // &B 的 Owned 类型对象
}
Cow<'a, B> 实现了 Deref<Target=B>, 所以可以直接调用 &B 的方法, 如果需要 mutation, 则可以调用他的
to_mut(&mut self) 方法, 它返回一个 Owned 类型的 &mut 引用(如果 Cow 当前保存的是 Borrowed(&B), 则会自动调用 &B 的 ToOwned trait 来生成 &B 的 Owned 类型对象, 然后返回它的 &mut 借用):
Cow 的重要方法:
- pub fn is_borrowed(&self) -> bool
- pub fn is_owned(&self) -> bool
- pub fn into_owned(self) -> <B as ToOwned>::Owned // 消耗 Cow, 生成 Owned 对象
- pub fn to_mut(&mut self) -> &mut <B as ToOwned>::Owned // 返回 Owned 对象的 &mut 引用;
如果 Cow 实际保存的是 Borrow<B> 对象, 则在调用 into_owned()/to_mut() 方法时,会调用 &B 实现的 ToOwned trait 来生成 Owned 对象, 也就是实现了 Copy on Write 的特性.
Cow 示例:
use std::borrow::Cow;
// 函数参数是 Cow<'_, [i32> ], 其中可以保存 &[i32] 或它的 Owned 类型 Vec[i32] 或 [i32; N]
fn abs_all(input: &mut Cow<'_, [i32]>) {
// Cow 实现了 Deref<Target=B>, 所以可以调用 &B 的方法.
for i in 0..input.len() {
let v = input[i];
if v < 0 {
// 这里是通过 &[T] 实现的 ToOwned trait 来生成一个 Vec<T> 对象
input.to_mut()[i] = -v;
}
}
}
// slice 元素都大于 0,所以不会 clone
let slice = [0, 1, 2];
let mut input = Cow::from(&slice[..]); // 保存 &[i32]
abs_all(&mut input);
// slice 有小于 0 的元素,所以会被 clone
let slice = [-1, 0, 1];
let mut input = Cow::from(&slice[..]);
abs_all(&mut input);
// 不会 clone,因为 input 保存的就是 owned 类型 Vec<i32>
let mut input = Cow::from(vec![-1, 0, 1]);
abs_all(&mut input);
// Another example showing how to keep Cow in a struct:
use std::borrow::Cow;
struct Items<'a, X> where [X]: ToOwned<Owned = Vec<X>> {
values: Cow<'a, [X]>,
}
impl<'a, X: Clone + 'a> Items<'a, X> where [X]: ToOwned<Owned = Vec<X>> {
fn new(v: Cow<'a, [X]>) -> Self {
Items { values: v }
}
}
// Creates a container from borrowed values of a slice
let readonly = [1, 2];
let borrowed = Items::new((&readonly[..]).into());
match borrowed {
Items { values: Cow::Borrowed(b) } => println!("borrowed {b:?}"),
_ => panic!("expect borrowed value"),
}
let mut clone_on_write = borrowed;
// Mutates the data from slice into owned vec and pushes a new value on top
clone_on_write.values.to_mut().push(3);
println!("clone_on_write = {:?}", clone_on_write.values);
// The data was mutated. Let's check it out.
match clone_on_write {
Items { values: Cow::Owned(_) } => println!("clone_on_write contains owned data"),
_ => panic!("expect owned data"),
}
Cow 语义看成『potentially owned』,即可能拥有所有权,可以用来避免一些不必须的拷贝,一种使用场景保存函数内临时对应的引用:
// 编译报错的例子:
fn foo(s: &str, some_condition: bool) -> &str {
if some_condition {
&s.replace("foo", "bar") // 临时对象的引用,在 block 结束前,临时对象被释放,引用无效
} else {
s
}
}
如果把返回值改成 String,那么在 else 分支会有一次额外的拷贝,这时,Cow 就可以派上用场了:
fn foo(s: &str, some_condition: bool) -> Cow<str> {
if some_condition {
Cow::from(s.replace("foo", "bar")) // 保存 Owned 的 String 对象
} else {
Cow::from(s) // 保存 &str
}
}
20.20 Deref/DerefMut #
Deref/DerefMut trait 定义:
pub trait Deref {
type Target: ?Sized;
// Required method
fn deref(&self) -> &Self::Target;
}
pub trait DerefMut: Deref {
// Required method
fn deref_mut(&mut self) -> &mut Self::Target;
}
Defer 主要使用场景是智能指针,例如 t=Box<U>,则可以对 t 进行 *t 和 &t 操作:
- *t 返回 U,等效于 *Deref.deref(&t);
- &t 返回 &U, 等效于 Deref.deref(&t);
- 同时,t 可以调用 U 的所有非可变方法;
在需要获取对象的 &mut 引用时,如方法调用或变量赋值场景,Rust 会看对象是否实现了 DerefMut trait,如果实现了则 自动调用(被称为 mutable deref coercion) 它来实现转换 , 所以,*v 作为左值的场景,Rust 使用 DerefMut<Target=U> 来对 * 操作符进行了重载,相当于用生成 Target U对象来进行赋值。
对于实现了 Deref<Target=U> 的类型 T 值, &*T 返回 &U:
- Deref 重载了 * 运算符, 所以
*T == *t.deref(), 返回 U 对象, 为了获得 &U, 一般使用&*T; - let (a, b) = &v; 这时 a 和 b 都是引用类型, 正确!
- let &(a, b) = &v; 这时 a 和 b 都是 move 语义, 如果对应值没有实现 copy, 则不允许从引用类型 move 值出来.
*v = 1; // 引用变量赋值
let mut data = data.lock().unwrap(); // 变量赋值时类型转换
let mut v = xx;
v.setXX(xxx); // 自动获得 v 的 &mut 引用来调用 setXX() 方法.
use std::sync::{Arc, Mutex, Condvar};
use std::thread;
let pair = Arc::new((Mutex::new(false), Condvar::new()));
let pair2 = Arc::clone(&pair);
// Inside of our lock, spawn a new thread, and then wait for it to start.
thread::spawn(move|| {
// pair2 实现了 Deref trait, 会重载 * 运算符, 所以 &*pair2 等效为 &*pair2.deref();
// 这里 &*pair2 返回的是 &(Mutex::new(false), Condvar::new()), 赋值解构后, lock 是 &Mutex, cvar
// 是 &Convar不能使用 let &(lock, cvar) = &*pair2; 这会导致 pair2 中的值发生了移动( lock 是
// Mutex, cvar 是 Convar), 由于 pair2 和 pair 是共享底层的对象, 所以是不允许移动的.
let (lock, cvar) = &*pair2;
let mut started = lock.lock().unwrap();
*started = true;
// We notify the condvar that the value has changed.
cvar.notify_one();
});
// Wait for the thread to start up.
let (lock, cvar) = &*pair;
let mut started = lock.lock().unwrap();
while !*started {
started = cvar.wait(started).unwrap();
}
Rust 自动通过 Deref trait 来满足赋值或传参类型的隐式转换,但是如果函数的参数是泛型限界,则 Rust 不会通过 Deref trait 来解引用来满足泛型参数限界的要求,两种解决办法:
- 使用 as 类型转换;
- 手动解引用 &*V;
use std::ops::{Deref, DerefMut};
impl<T> Deref for Selector<T> {
type Target = T;
fn deref(&self) -> &T { &self.elements[self.current] }
}
impl<T> DerefMut for Selector<T> {
fn deref_mut(&mut self) -> &mut T { &mut self.elements[self.current] }
}
// OK: 在函数传参时, Rust 会自动隐式解引用, &Selector -> &str
let s = Selector { elements: vec!["good", "bad", "ugly"], current: 2 };
fn show_it(thing: &str) { println!("{}", thing); }
show_it(&s);
// Error: 当使用 Trait 作为泛型参数的限界时, Rust 不会自动解引用到 &str 类型来满足类型限界的要求
use std::fmt::Display;
fn show_it_generic<T: Display>(thing: T) { println!("{}", thing); }
show_it_generic(&s);
// 两种解决办法:
show_it_generic(&s as &str); // 使用 as 类型转换;
show_it_generic(&*s) // 手动解引用 &*V 来得到 &str 类型:
类型自动转化是 Rust 为了追求语言简洁,使用 Deref/DerefMut 实现的另一种隐式操作,比如下面的赋值都是正确的:
let s: String = "hello".to_string();
let s1: &String = &s;
let s2: &str = s1;
let s3: &str = &&s;
let s4: &str = &&&s;
let s5: &str = &&&&s;
无论有多少个 & ,Rust 都能正确的将其转为 &str 类型 ,究其原因,是因为 deref coercions ,它允许在 T:
Deref<U> 时, &T 可以自动转为 &U 。
因为 s2 的赋值能成功就是利用了 deref coercion 的原理,那么 s3/s4/s5 呢?如果稍微有些 Rust 经验的话,当一个类型可以调用一个不知道哪里定义的方法时, =大概率是 trait 的通用实现(blanket implementation)=起作用的,这里就是这种情况:
impl<T: ?Sized> const Deref for &T {
type Target = T;
fn deref(&self) -> &T {
*self
}
}
20.21 smart pointer #
实际上只要实现了 Deref trait 的类型都可以称为 smart pointer。Deref 文档列出了标准库中实现 Deref trait 的所有类型列表: https://doc.rust-lang.org/std/ops/trait.Deref.html
impl Deref for String type Target = str
impl<B> Deref for Cow<'_, B> where B: ToOwned + ?Sized, <B as ToOwned>::Owned: Borrow<B> type Target = B
impl<P> Deref for Pin<P> where P: Deref, type Target = <P as Deref>::Target
impl<T> Deref for &T where T: ?Sized, type Target = T
impl<T> Deref for &mut T where T: ?Sized, type Target = T
impl<T> Deref for Ref<'_, T> where T: ?Sized, type Target = T
impl<T> Deref for RefMut<'_, T> where T: ?Sized, type Target = T
impl<T, A> Deref for Box<T, A> where A: Allocator, T: ?Sized, type Target = T
impl<T, A> Deref for Rc<T, A> where A: Allocator, T: ?Sized, type Target = T
impl<T, A> Deref for Arc<T, A> where A: Allocator, T: ?Sized, type Target = T
impl<T, A> Deref for Vec<T, A> where A: Allocator, type Target = [T]
上面各种智能指针都没有实现 Copy trait,所以 ownership 会转移。
Ref<T>/RefMut<T>/Rc<T>/Arc<T>/Box<T> :
- * 操作符解引用后类型都是 T,实际执行的操作为:*(v.deref()).
- 在需要 &T 的地方都可以传入 &Ref/&Rc/&Box 类型;
- Ref<T>/Box<T> 可以调用 T 定义的所有方法;
由于智能指针都可以调用 &T 的方法, 为了避免指针自己和 &T 的方法冲突, 在调用只能指针自己的方法或实现的 trait 时,一般使用全限定名称:
use std::sync::Arc;
let foo = Arc::new(vec![1.0, 2.0, 3.0]);
// The two syntaxes below are equivalent.
let a = foo.clone();
let b = Arc::clone(&foo); // 建议: 全限定名称的方法或关联函数调用
let my_weak = Arc::downgrade(&my_arc); // 全限定语法
// a, b, and foo are all Arcs that point to the same memory location
#![feature(new_uninit)]
#![feature(get_mut_unchecked)]
use std::sync::Arc;
let mut five = Arc::<u32>::new_uninit();
// Deferred initialization:
Arc::get_mut(&mut five).unwrap().write(5); // 全限定语法
let five = unsafe { five.assume_init() };
use std::sync::Arc;
use std::sync::atomic::{AtomicUsize, Ordering};
use std::thread;
let val = Arc::new(AtomicUsize::new(5));
for _ in 0..10 {
let val = Arc::clone(&val);
thread::spawn(move || {
let v = val.fetch_add(1, Ordering::SeqCst);
println!("{v:?}");
});
}
String/Vec<T> 其实也是 smartpointer, 只不过是专用的,它们占用 3 个机器字栈空间+可变长堆空间:
- String 实现了 Deref<Target = str>;
- Vec<T> 实现了 Deref<Target = [T]>;
fn read_slice(slice: &[usize]) {
// ...
}
let v = vec![0, 1];
read_slice(&v); // Deref 自动转换
let u: &[usize] = &v; // Deref 自动转换
// or like this:
let u: &[_] = &v;
Use borrowed types for arguments
- 一般情况下, 使用 borrowed type 而不是 borrowing the owned type, 例如 &str over &String, &[T] over &Vec<T>, or &T over &Box<T>.
Box/Rc/Arc 的 lifetime 规则:
- Box<Trait> 默认等效于 Box<Trait + ‘static>;
- &‘x Box<Trait> 等效于 &‘x Box<Trait+‘static>;
- ‘x 可能是编译器自动加的, 所以即使没有明确指定, &Box<Trait> 等效于 &Box<Trait+‘static>;
- &‘r Ref<‘q, Trait> 等效于 &‘r Ref<‘q, Trait+‘q>;
在函数传参匹配 trait bound 时不会进行协变和 Deref trait 调用,例如虽然 &mut i32 可以协变到 &i32, 但传参时不会协变:
- 带来的影响是:如果 Trait 作为函数参数限界,&i32 和 &mut i32 两种类型都需要实现该 Trait。
trait Trait {}
fn foo<X: Trait>(t: X) {}
impl<'a> Trait for &'a i32 {}
fn main() {
let t: &mut i32 = &mut 0;
foo(t);
}
// error[E0277]: the trait bound `&mut i32: Trait` is not satisfied
// --> src/main.rs:9:9
// |
// 3 | fn foo<X: Trait>(t: X) {}
// | ----- required by this bound in `foo`
// ...
// 9 | foo(t);
// | ^ the trait `Trait` is not implemented for `&mut i32`
// |
// = help: the following implementations were found:
// <&'a i32 as Trait>
// = note: `Trait` is implemented for `&i32`, but not for `&mut i32`
20.22 Box<T> #
Rust 值默认在 stack 上分配. 可以使用 Box<T> 将 T 值在 heap 上分配,从而解决几个问题:
- 封装 unsize 对象为固定大小对象,解决自引用递归类型或 trait object 问题;
- 避免栈上的大量内存拷贝,可以用 Box 封装 struct/array 来将内容保存在堆上;
- 自动解引用和类型转换。
Box 是一个 hold T 值的智能指针, 它实现了 Drop trait,在离开 Box scope 时, T 值的解构被调用, heap 上内存被释放.
// 解决自引用递归类型 unsize 的问题
enum List {
Cons(i32, Box<List>),
Nil,
}
use crate::List::{Cons, Nil};
fn main() {
let list = Cons(1,
Box::new(Cons(2,
Box::new(Cons(3,
Box::new(Nil))))));
}
use std::mem;
#[allow(dead_code)]
#[derive(Debug, Clone, Copy)]
struct Point {
x: f64,
y: f64,
}
// A Rectangle can be specified by where its top left and bottom right corners are in space
#[allow(dead_code)]
struct Rectangle {
top_left: Point,
bottom_right: Point,
}
fn origin() -> Point {
Point { x: 0.0, y: 0.0 }
}
fn boxed_origin() -> Box<Point> {
// Allocate this point on the heap, and return a pointer to it
Box::new(Point { x: 0.0, y: 0.0 })
}
fn main() {
// 栈上分配内存
// (all the type annotations are superfluous) Stack allocated variables
let point: Point = origin();
let rectangle: Rectangle = Rectangle {
top_left: origin(),
bottom_right: Point { x: 3.0, y: -4.0 }
};
// 堆上分配内存
// Heap allocated rectangle
let boxed_rectangle: Box<Rectangle> = Box::new(Rectangle {
top_left: origin(),
bottom_right: Point { x: 3.0, y: -4.0 },
});
// The output of functions can be boxed
let boxed_point: Box<Point> = Box::new(origin());
// Double indirection
let box_in_a_box: Box<Box<Point>> = Box::new(boxed_origin());
println!("Point occupies {} bytes on the stack", mem::size_of_val(&point));
println!("Rectangle occupies {} bytes on the stack", mem::size_of_val(&rectangle));
// box size == pointer size
println!("Boxed point occupies {} bytes on the stack", mem::size_of_val(&boxed_point));
println!("Boxed rectangle occupies {} bytes on the stack", mem::size_of_val(&boxed_rectangle));
println!("Boxed box occupies {} bytes on the stack", mem::size_of_val(&box_in_a_box));
// Copy the data contained in `boxed_point` into `unboxed_point`
let unboxed_point: Point = *boxed_point;
println!("Unboxed point occupies {} bytes on the stack", mem::size_of_val(&unboxed_point));
}
Box<T> 实现了 Deref<Target=T>,故可以将 Box 视为常规引用:
- 如支持使用 *v 操作符来解引用 *(v.deref()),返回 T 值,&*v 来返回 &T 值:
- 在需要 &T 的地方可以直接使传入 &Box<T> 值;
// https://doc.rust-lang.org/src/alloc/boxed.rs.html#1918
#[stable(feature = "rust1", since = "1.0.0")]
impl<T: ?Sized, A: Allocator> Deref for Box<T, A> {
type Target = T;
fn deref(&self) -> &T {
&**self
}
}
fn main() {
let x = 5;
let y = Box::new(x);
assert_eq!(5, x);
assert_eq!(5, *y); // *y 等效为 *(y.deref()), 返回 5。
}
自定义对象实现 Deref:
struct MyBox<T>(T);
use std::ops::Deref;
impl<T> Deref for MyBox<T> {
type Target = T;
fn deref(&self) -> &Self::Target {
&self.0
}
}
示例:deref coercion:
fn hello(name: &str) {
println!("Hello, {name}!");
}
fn main() {
let m = MyBox::new(String::from("Rust"));
hello(&m); // Rust 自动进行多级 Defer 解引用,也就是 deref coercion:MyBox<String> -> String -> str
// 如果 rust 不做 deref coercion,则需要做如下繁琐操作
hello(&(*m)[..]);
}
v = Box<T> 会 ownership T 的内容,当 v 被 drop 时,堆中的 T 内存也会被 drop。所以直接用 v 赋值或传递到函数时,会转移所有权。
enum List {
Cons(i32, Box<List>), // 元组类型,由于 Box 没有实现 Copy,所以整个元组没有实现 Copy
Nil,
}
use crate::List::{Cons, Nil};
fn main() {
let a = Cons(5, Box::new(Cons(10, Box::new(Nil))));
let b = Cons(3, Box::new(a)); // a 所有权转移。这里不能传入 &a, 否则只是分配一个指针的空间。
let c = Cons(4, Box::new(a)); // 编译器报错,解决办法是使用 Rc<T>
}
Box<T> 默认没有实现 Copy,在赋值时会被移动。其他智能指针,如 Rc/Arc/Cell/RefCell 类似。
20.23 Rc/Arc<T> #
Rc<T> 和 Box<T> 类似, a = Rc::new(T) 都是在堆上为 T 分配内存,并 ownership 它,但是:
- Rc::clone(&a) 返回一个新的 Rc<T>, 只增加 a 的引用计数,并不会重新分配堆内存;
- 原始 Rc 对象,以及 clone 后返回的 Rc 对象都被 drop 后(引用计数 Rc.strong_count(&a) == 0),a 对应的堆内存才会被释放;
- Rc 对象的值是只读共享的,不能改变。可以和 Cell/RefCell 结合使用,使用内部可变性机制来修改共享对象。
impl<T, A> Clone for Rc<T, A>
where
A: Allocator + Clone,
T: ?Sized,
fn clone(&self) -> Rc<T, A> // 返回一个 Rc<T> 对象
Rc<T> 的主要使用场景是需要多 owner 的情况,例如一个链接表对象被多个其他链接表共享引用。
- 使用 Rc/Arc 的一个常见场景是在多线程中共享大的数据,避免内存拷贝。
enum List {
Cons(i32, Rc<List>),
Nil,
}
use crate::List::{Cons, Nil};
use std::rc::Rc;
fn main() {
let a = Rc::new(Cons(5, Rc::new(Cons(10, Rc::new(Nil)))));
let b = Cons(3, Rc::clone(&a)); // 不能使用 Box<T>, 否则这里会发生所有权转移,后续不能再使用它。
let c = Cons(4, Rc::clone(&a));
}
Rc::clone(&a) 增加 a 的引用计数,返回一个新的 Rc 对象,这些 Rc 对象指向的值是共享的,不能改变。
enum List {
Cons(i32, Rc<List>),
Nil,
}
use crate::List::{Cons, Nil};
use std::rc::Rc;
fn main() {
let a = Rc::new(Cons(5, Rc::new(Cons(10, Rc::new(Nil)))));
let b = Cons(3, Rc::clone(&a));
let c = Cons(4, Rc::clone(&a));
}
惯例使用 Rc::clone(&a) 而不是 a.clone() 来创建 a 的新引用计数对象,因为如果 a 类型也实现了 Clone trait,则 a.clone() 将不能区分该调用哪一个 trait 的 clone() 方法,从而导致编译出错。
打印引用计数:
fn main() {
let a = Rc::new(Cons(5, Rc::new(Cons(10, Rc::new(Nil)))));
println!("count after creating a = {}", Rc::strong_count(&a));
let b = Cons(3, Rc::clone(&a));
println!("count after creating b = {}", Rc::strong_count(&a));
{
let c = Cons(4, Rc::clone(&a));
println!("count after creating c = {}", Rc::strong_count(&a));
}
println!("count after c goes out of scope = {}", Rc::strong_count(&a));
}
// $ cargo run
// Compiling cons-list v0.1.0 (file:///projects/cons-list)
// Finished dev [unoptimized + debuginfo] target(s) in 0.45s
// Running `target/debug/cons-list`
// count after creating a = 1
// count after creating b = 2
// count after creating c = 3
// count after c goes out of scope = 2
Rc 提供了 get_mut()/make_mut()/into_inner() 方法来修改对象,Rc::get_mut() 方法
pub fn get_mut(this: &mut Rc<T, A>) -> Option<&mut T>
当没有其他 Rc 对象引用 this 时, 也就是 this Rc 对象的引用计数为 1 时, 返回 &mut T, 否则返回 None.
- 而 make_mut() 方法在引用计数 >=1 时, clone 一个新对象来替换 this, 然后返回他的 &mut T;
use std::rc::Rc;
let mut x = Rc::new(3);
*Rc::get_mut(&mut x).unwrap() = 4;
assert_eq!(*x, 4);
let _y = Rc::clone(&x);
assert!(Rc::get_mut(&mut x).is_none());
Rc::make_mut() 方法:
pub fn make_mut(this: &mut Rc<T, A>) -> &mut T
创建传入 Rc<T> 的 &mutT 可变引用,当调用该方法时, 如果传入的 Rc 对象被 clone 过, 也就是引用计数 >=2, 则该方法会 clone 生成一个新的 Rc 对象并替换 this, 这被称为 clone-on-write;
use std::rc::Rc;
let mut data = Rc::new(5);
*Rc::make_mut(&mut data) += 1; // Won't clone anything
let mut other_data = Rc::clone(&data); // Won't clone inner data
// 由于 data 被 clone 过, 再次调用 data 的 make_mut 时会 clone 一个新 Rc 对象并替换 data
// 这是 other_data 的引用计数 -1 变为 1, data 的引用计数也为 1
*Rc::make_mut(&mut data) += 1; // Clones inner data
// data 是刚才 clone 生成的新对象, 计数为 1, 所以这次不会再 clone
*Rc::make_mut(&mut data) += 1; // Won't clone anything
// other_data 引用计数为 1, 所以也不会 clone
*Rc::make_mut(&mut other_data) *= 2; // Won't clone anything
// Now `data` and `other_data` point to different allocations.
assert_eq!(*data, 8);
assert_eq!(*other_data, 12);
Rc::into_inner() 方法:
pub fn into_inner(this: Rc<T, A>) -> Option<T>
Returns the inner value, if the Rc has exactly one strong reference. Otherwise, None is returned and
the Rc is dropped.
- 传入的是 Rc 对象本身而非引用, 会消耗传入的 Rc(其他类型的 into_inner() 方法都是类似的语义).
This will succeed even if there are outstanding weak references.
If Rc::into_inner is called on every clone of this Rc, it is guaranteed that exactly one of the
calls returns the inner value. This means in particular that the inner value is not dropped.
This is equivalent to Rc::try_unwrap(this).ok(). (Note that these are not equivalent for Arc, due to race conditions that do not apply to Rc.)
另外,into_inner() 是一个常见的类型方法, 都是从包装类型生成对应的 T, 例如:
- pub fn into_inner(boxed: Box<T, A>) -> T
- Cell/RefCell
// pub fn into_inner(self) -> T
use std::cell::Cell;
let c = Cell::new(5);
let five = c.into_inner();
assert_eq!(five, 5);
使用 Rc/Arc 可能创建出一些循环引用的数据解构,导致 Rc/Arc 管理的对象引用计数 strong_count() 不为 0,从而发生内存泄露。
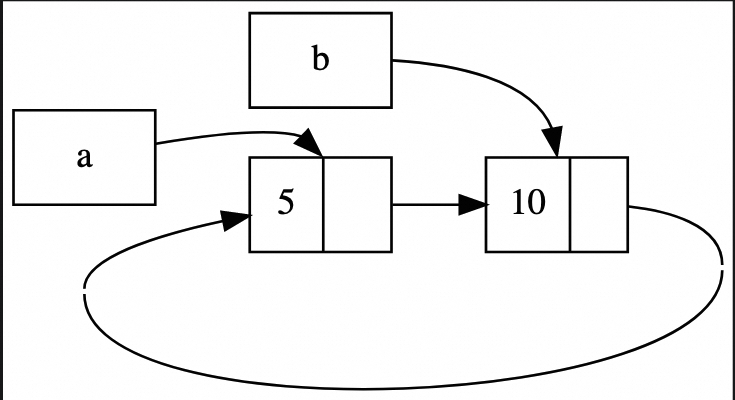
use crate::List::{Cons, Nil};
use std::cell::RefCell;
use std::rc::Rc;
#[derive(Debug)]
enum List {
Cons(i32, RefCell<Rc<List>>),
Nil,
}
impl List {
fn tail(&self) -> Option<&RefCell<Rc<List>>> {
match self {
Cons(_, item) => Some(item),
Nil => None,
}
}
}
fn main() {
let a = Rc::new(Cons(5, RefCell::new(Rc::new(Nil))));
println!("a initial rc count = {}", Rc::strong_count(&a));
println!("a next item = {:?}", a.tail());
let b = Rc::new(Cons(10, RefCell::new(Rc::clone(&a))));
println!("a rc count after b creation = {}", Rc::strong_count(&a));
println!("b initial rc count = {}", Rc::strong_count(&b));
println!("b next item = {:?}", b.tail());
if let Some(link) = a.tail() {
*link.borrow_mut() = Rc::clone(&b);
}
println!("b rc count after changing a = {}", Rc::strong_count(&b));
println!("a rc count after changing a = {}", Rc::strong_count(&a));
// Uncomment the next line to see that we have a cycle;
// it will overflow the stack
// println!("a next item = {:?}", a.tail());
// block 结束时, b 被 drop 后 strong_count() 为 1, 所以堆内存不会被释放, a 也是同样的情况.
}
解决办法是使用 Rc::downgrade() 而非 Rc::clone() 来增加对象弱引用计数 weak_count() 而不会增加 strong_count(), 他返回一个 Weak<T> 智能指针。
- weak_count() 记录 Rc 对象的 Weak<T> 对象数量。
- Rc<T> 并不会在执行清理时要求 weak_count() 必须为 0;一旦强引用计数为 0,任何由弱引用组成的循环就会被打破,因此弱引用不会造成循环依赖;
- 由于 Weak<T> 引用的值可能会被释放,可以使用 weak.upgrade() 方法来验证 weak 指向的值是否存在,他返回一个 Option<Rc<T>>, 在 Rc<T> 值存在时返回 Some, 否则返回 None.
use std::cell::RefCell;
use std::rc::{Rc, Weak};
#[derive(Debug)]
struct Node {
value: i32,
parent: RefCell<Weak<Node>>,
children: RefCell<Vec<Rc<Node>>>,
}
fn main() {
let leaf = Rc::new(Node {
value: 3,
parent: RefCell::new(Weak::new()),
children: RefCell::new(vec![]),
});
println!(
"leaf strong = {}, weak = {}",
Rc::strong_count(&leaf),
Rc::weak_count(&leaf),
);
{
let branch = Rc::new(Node {
value: 5,
parent: RefCell::new(Weak::new()),
children: RefCell::new(vec![Rc::clone(&leaf)]),
});
*leaf.parent.borrow_mut() = Rc::downgrade(&branch);
println!(
"branch strong = {}, weak = {}",
Rc::strong_count(&branch),
Rc::weak_count(&branch),
);
println!(
"leaf strong = {}, weak = {}",
Rc::strong_count(&leaf),
Rc::weak_count(&leaf),
);
}
println!("leaf parent = {:?}", leaf.parent.borrow().upgrade());
println!(
"leaf strong = {}, weak = {}",
Rc::strong_count(&leaf),
Rc::weak_count(&leaf),
);
}
20.24 Cell<T>/RefCell<T> #
在不可变对象中引入一些可变性,称为内部可变性 interior mutability。
Rust 标准库的 std::cell module 提供了 Cell<T> 和 RefCell<T> 来支持这种场景:在对 Cell 自身没有 mut access 的情况下,也能 get/set 它的 field。
Cell 适用于支持 Copy trait 的对象类型,他使用 Copy 来 get 对象,cell.set() 方法是 &self 类型而非 &mut self ,但是又能对 self 进行设置操作,这是 Cell<T> 在 Rust 中存在的主要价值。
- Cell::new(value): Creates a new Cell,
movingthe given value into it. - cell.get(): Returns a copy of the value in the cell.
- cell.set(value): Stores the given value in the cell, dropping the previously stored value. This
method takes
self as a non-mut reference: fn set(&self, value: T) // note: not `&mut self`
use std::cell::Cell;
pub struct SpiderRobot {
// ...
hardware_error_count: Cell<u32>, // 成员是 Cell<T> 类型
// ...
}
// SpiderRobot 的非 mutt 方法也可以 get/set 对应的 Cell<T> 成员。
impl SpiderRobot {
/// Increase the error count by 1.
pub fn add_hardware_error(&self) { // &self 而非 &mut self
let n = self.hardware_error_count.get();
self.hardware_error_count.set(n + 1);
}
/// True if any hardware errors have been reported.
pub fn has_hardware_errors(&self) -> bool {
self.hardware_error_count.get() > 0
}
}
如果类型 T 不支持 Copy trait,则不能使用 Cell,而需要使用 RefCell<T>, 他使用借用来获得或修改对象。 RefCell<T> supports borrowing references to its T value:
- RefCell::new(value) Creates a new RefCell,
movingvalue into it. - ref_cell.borrow() Returns a
Ref<T>, which is essentially just a shared reference to the value stored in ref_cell. This method panics if the value is already mutably borrowed; see details to follow. - ref_cell.borrow_mut() Returns a
RefMut<T>, essentially a mutable reference to the value in ref_cell. This method panics if the value is already borrowed; see details to follow. - ref_cell.try_borrow(), ref_cell.try_borrow_mut() Work just like borrow() and borrow_mut(), but
return
a Result. Instead of panicking if the value is already mutably borrowed, they return an Err value.
borrow()/borrow_mut() 返回的 Ref<T>/RefMut<T> 是智能指针,实现了 Deref<Target=T>, 可以直接调用 T 的方法.
对于已经通过 r = RefCell<T>.borrow() 的 r 不能调用 borrow_mut(), 否则会 panic:
- Rust 对引用和智能指针如 Box<T> 进行
编译时检查,避免引用出错。但是对于 RefCell<T>,Rust 会在运行时检查这些规则,在出现违反借用的情况下出发 panic 来提前终止程序。
use std::cell::RefCell;
let ref_cell: RefCell<String> = RefCell::new("hello".to_string());
let r = ref_cell.borrow(); // ok, returns a Ref<String>
let count = r.len(); // ok, returns "hello".len()
assert_eq!(count, 5);
let mut w = ref_cell.borrow_mut(); // panic: already borrowed
w.push_str(" world");
例子:
pub struct SpiderRobot {
// ...
log_file: RefCell<File>,
// ...
}
impl SpiderRobot {
/// Write a line to the log file.
pub fn log(&self, message: &str) {
// self 虽然是不可变引用, 但是使用 RefCell<T>.borrow_mut() 来返 RefMut<T>
let mut file = self.log_file.borrow_mut();
// `writeln!` is like `println!`, but sends
// output to the given file.
writeln!(file, "{}", message).unwrap();
}
}
另一个例子:
// https://doc.rust-lang.org/book/ch15-05-interior-mutability.html
#[cfg(test)]
mod tests {
use super::*;
use std::cell::RefCell;
struct MockMessenger {
sent_messages: RefCell<Vec<String>>,
}
impl MockMessenger {
fn new() -> MockMessenger {
MockMessenger {
sent_messages: RefCell::new(vec![]),
}
}
}
impl Messenger for MockMessenger {
fn send(&self, message: &str) {
self.sent_messages.borrow_mut().push(String::from(message));
}
}
#[test]
fn it_sends_an_over_75_percent_warning_message() {
// --snip--
assert_eq!(mock_messenger.sent_messages.borrow().len(), 1);
}
}
Cell/RefCell 没有实现 Sync trait,Rust 不允许多线程使用它们。
Mutext<T>/RwLock<T>/OnceLock<T>/原子操作类型,提供了线程安全的内部可变性,都可以使用共享引用 &self 来调用它们的 mut 方法,例如 lock().
20.25 Pin/UnPin #
由于 move 机制的存在,导致在 Rust 很难去正确表达『自引用』的结构,比如链表、树等。主要问题:move 只会进行值本身的拷贝,指针的指向则不变。如果被 move 的结构有指向其他字段的指针,那么这个指向被 move 后就是非法的,因为原始指向已经换地址了。
Pin 的常用场景是 std::future::Feature trait 的 poll 方法:由于 Future trait object 必须保存执行上下文中 stack 上的变量,而 Future 下一次被 wake 执行的时机是不定的,所以为了避免 Future 对象上报错的 stack 变量的地址发生变化导致引用出错,需要将 Future 对象设置为 Pin<&mut Self> 类型,表示该对象不能被 move 转移所有权。
pub trait Future {
type Output;
// Required method
fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output>;
}
举例:
#![feature(noop_waker)]
use std::future::Future;
use std::task;
let waker = task::Waker::noop();
let mut cx = task::Context::from_waker(&waker);
let mut future = Box::pin(async { 10 });
assert_eq!(future.as_mut().poll(&mut cx), task::Poll::Ready(10));
20.26 Send/Sync #
- Send:对象可以在多个线程中转移 move (也就是对象在多线程间转移具有原子性);
- Sync:可以在多个线程中共享引用对象;
对于 thread closure 而言,一般使用 move 来转移引用的对象,所以对象类型必须实现 Send。但是对于 scope thread 的闭包函数不使用 move,它们可以共享引用父 thread 的 stack 变量,所以要求这些对象必须实现 Sync。
由于 thread closure 要求使用 move 来将外部环境中的对象所有权转义到闭包函数内,所以转义的对象必须要实现 Send trait。绝大部分 rust 类型,如 Vec/Map/Array 等实现了 Send/Sync,可以自由地被 move 到 thread closure 中。自定义类型的各成员如果实现了 Send/Sync,则该类型也自动实现了 Send/Sync。
特殊情况:
- Rc<T> 没有实现 Send 和 Sync(多线程转移 Rc 对象时,不能保证原子性),不能被 move 到 thread closure 中。多线程环境中需要使用 Arc<T> 和它的clone()对象;
- Cell/RefCell/mpsc:Receiver 没有实现 Sync,不能在多个线程中共享引用;
- std::sync::MutexGurad 没实现 Send。
21 type coercion #
21.1 Subtyping and Variance #
https://doc.rust-lang.org/reference/subtyping.html
https://doc.rust-lang.org/nomicon/subtyping.html
Subtyping is the idea that one type can be used in place of another. What this is suggesting to us
is that the set of requirements that Super defines are completely satisfied by Sub. Sub may then
have more requirements.
fn debug<'a>(a: &'a str, b: &'a str) {
println!("a = {a:?} b = {b:?}");
}
fn main() {
let hello: &'static str = "hello";
{
let world = String::from("world");
let world = &world; // 'world has a shorter lifetime than 'static
debug(hello, world); // hello silently downgrades from `&'static str` into `&'world str`
}
}
fn bar<'a>() {
let s: &'static str = "hi";
let t: &'a str = s;
}
Subtyping 是 Rust 进行的隐式操作(类似的隐式操作还有 type coercion), 用于 type checking 和 infrerence, 它们都指的是 lifetime 之间的关系(Rust 的自定义类型之间没有 subtype 语义),有两种情况:
- 基于 lifetime 的子类型: 生命周期更长的 lifetime 是更短的子类型, 比如
- ‘b: ‘a 表示 ‘b 的声明周期比 ‘a 长,在需要 ‘a 的地方,可以传入 ‘b;
- ‘static 的生命周期比其它 lifetime 如 ‘a 长,在需要 ‘a 的地方,可以传入 ‘static。 例如 &‘static str 是 &‘a str 的子类型,在需要 &‘a str 的地方可以赋值 &‘static str:
- HRTB 的 lifetime 是其他任意 lifetime 的子类型:
注:supertrait 只是用于约束 Self 必须实现多个 trait + ’lifetime, 并不表示 trait 之间的 subtype 关系。
// 使用闭包
fn use_closure<F>(f: F) where F: for<'a> Fn(&'a str) -> &'a str,
{
let s = "example";
let result = f(s); // f 的 HRBT lifetime 是任意其他 lifetime 的子类型
println!("{}", result);
}
// 使用函数指针
fn use_fn_ptr(f: for<'a> fn(&'a str) -> &'a str) {
let s = "example";
let result = f(s); // f 的 HRBT lifetime 是任意其他 lifetime 的子类型
println!("{}", result);
}
// Here 'a is substituted for 'static
let subtype: &(for<'a> fn(&'a i32) -> &'a i32) = &((|x| x) as fn(&_) -> &_);
let supertype: &(fn(&'static i32) -> &'static i32) = subtype;
// This works similarly for trait objects
let subtype: &(dyn for<'a> Fn(&'a i32) -> &'a i32) = &|x| x;
let supertype: &(dyn Fn(&'static i32) -> &'static i32) = subtype;
// We can also substitute one higher-ranked lifetime for another
let subtype: &(for<'a, 'b> fn(&'a i32, &'b i32))= &((|x, y| {}) as fn(&_, &_));
let supertype: &for<'c> fn(&'c i32, &'c i32) = subtype;
Variance 指的是在传参和赋值时,类型之间支持的 subtype 场景:
- covariant 协变: 如果 T 是 U 的 subtype, 则 F<T> 是 F<U> 的子类型;
- contravariant 逆变: 如果 T 是 U 的 subtype, 则 F<U> 是 F<T> 的子类型;
- invariant 不可变: 没有子类型的关系.
Variance of types is automatically determined as follows:
| Type | Variance in ‘a | Variance in T |
|---|---|---|
| &‘a T | covariant, ‘a 可以有子类型 | covariant,T 可以有子类型 |
| &‘a mut T | covariant, ‘a 可以有子类型 | invariant, T 不可变 |
| *const T | covariant,T 可以有子类型 | |
| *mut T | invariant | |
| [T] and [T; N] | covariant, T 可以有子类型 | |
| fn() -> T | covarian t, T 可以有子类型 | |
| fn(T) -> () | contravariant, 可以传入 T 的父类型 | |
| std::cell::UnsafeCell<T> | invariant,T 不可变 | |
| std::marker::PhantomData<T> | covariant,T 可以有子类型 | |
| dyn Trait<T> + ‘a | covariant, ‘a 可以有子类型 | invariant, T 不可以变 |
注意:
- 上面的 T 是一个类型代表,实际可能包含 lifetime, 比如 fn() -> T 中的 T 可能是 &‘a String, 这时可以使用 &‘static String, 因为 ‘static 是 ‘a 的子类型;
- fn(T) -> () 中的 T 是逆变,所以如果 fn(&‘static String) 则可以传入 fn(&‘a String), 一般使用场景比较少;
- Vec<T> and all other owning pointers and collections follow the same logic as Box<T>:T 可变;
- 表格中没提,但是 Box<T> 和 Vec<T> 都是 covariant,Cell<T> 都是 invariant;
- UnsafeCell<T>/Cell<T> 等内部可变性类型和 &mut T 类型一致,T 不可变。
- *const T follows the logic of &T
- *mut T follows the logic of &mut T (or UnsafeCell<T>)
示例:
- A
&'long Tcoerces to a ~&‘short T~, T 也可以协变到 U; - A
&'long mut Tcoerces to a ~&‘short mut T~, 虽然 T 不可变,但是 lifetime 可变; - A
&'medium &'long Ucoerces to a&'short &'short U - A
&'medium mut &'long mut Ucoerces to a&'short mut &'long mut U…, but not to a &‘short mut &‘short mut U Cell<T>andRefCell<T>are also invariant in T.T: dyn Trait<U> 或 T: Trait<U>, U becomes invariant because it’s a type parameter of the trait. If your U resolves to&'x V, the lifetime'xwill be invariant too.
// 由于输入参数是 &mut T 类型,所以在赋值时,val 对应 T 的类型是不可变的,必须和 input 的 T 类型一致。
fn assign<T>(input: &mut T, val: T) {
*input = val;
}
fn main() {
let mut hello: &'static str = "hello";
{
let world = String::from("world");
// 传入的参数类型是 &mut &'static str, 所以 T 的类型必须是 &'static str, 但是 &world 的类型
// 是 &'world str,所以编译错误。
assign(&mut hello, &world);
}
println!("{hello}");
}
// error[E0597]: `world` does not live long enough
// --> src/main.rs:9:28
// |
// 6 | let mut hello: &'static str = "hello";
// | ------------ type annotation requires that `world` is borrowed for `'static`
// ...
// 9 | assign(&mut hello, &world);
// | ^^^^^^ borrowed value does not live long enough
// 10 | }
// | - `world` dropped here while still borrowed
下面的代码 OK,这是由于 Box<T> 中的 T 是协变的,&‘static 是 &‘b 的 subtype,所以可以赋值:
let hello: Box<&'static str> = Box::new("hello");
let mut world: Box<&'b str>;
world = hello; // 对象所有权转移时可以更改可变性
fn get_str() -> &'a str;
// 可以用如下函数指针赋值 get_str
fn get_static() -> &'static str;
// 示例:
thread_local! {
pub static StaticVecs: RefCell<Vec<&'static str>> = RefCell::new(Vec::new());
}
/// saves the input given into a thread local `Vec<&'static str>`
fn store(input: &'static str) {
StaticVecs.with_borrow_mut(|v| v.push(input));
}
/// Calls the function with it's input (must have the same lifetime!)
fn demo<'a>(input: &'a str, f: fn(&'a str)) {
f(input);
}
fn main() {
demo("hello", store); // "hello" is 'static. Can call `store` fine
{
let smuggle = String::from("smuggle");
// `&smuggle` is not static. If we were to call `store` with `&smuggle`, we would have
// pushed an invalid lifetime into the `StaticVecs`. Therefore, `fn(&'static str)` cannot
// be a subtype of `fn(&'a str)`
demo(&smuggle, store);
}
// use after free 😿
StaticVecs.with_borrow(|v| println!("{v:?}"));
}
对于自定义的 struct/enum/union 的 variance 取决于各 field 的 variance:
- 如果 parameter A 在各 field 的使用都是 covariant, 则整体对 A 是 covariant;
- 如果 parameter A 在各 field 的使用都是 contravariant, 则整体对 A 是 contravariant;
- 否则,整体对 A 是 invariant;
比如下面的 struct 的 ‘a 和 T 是 covariant 可变的, 而 ‘b, ‘c 和 U 是 invariant 不可变的:
use std::cell::UnsafeCell;
struct Variance<'a, 'b, 'c, T, U: 'a> {
x: &'a U, // This makes `Variance` covariant in 'a, and would make it covariant in
// U, but U is used later, 由于 U 在多个 field 中使用, 所以 U 是不可变的
y: *const T, // Covariant in T
z: UnsafeCell<&'b f64>, // Invariant in 'b, 因为 std::cell::UnsafeCell<T> 中的 T 是不可变的.
w: *mut U, // Invariant in U, makes the whole struct invariant, 部分字段不可变时,
// 整个 struct 不可变.
f: fn(&'c ()) -> &'c () // Both co- and contravariant, makes 'c invariant in the struct.
}
在 struct/enum/uion filed 之外, variance 是单独计算的, 所以长的 lifetime 类型值可以赋值给短的 liftime 类型值, 因为 liftime 间有 subtype 关系;
fn generic_tuple<'short, 'long: 'short>(
// 'long is used inside of a tuple in both a co- and invariant position.
x: (&'long u32, UnsafeCell<&'long u32>),
) {
// As the variance at these positions is computed separately, we can freely shrink 'long in the
// covariant position.
let _: (&'short u32, UnsafeCell<&'long u32>) = x;
}
fn takes_fn_ptr<'short, 'middle: 'short>(
// 'middle is used in both a co- and contravariant position.
f: fn(&'middle ()) -> &'middle (),
) {
// As the variance at these positions is computed separately, we can freely shrink 'middle in
// the covariant position and extend it in the contravariant position.
// 函数输入参数是逆变,返回结果是协变。
let _: fn(&'static ()) -> &'short () = f;
}
21.2 type-coercions #
https://doc.rust-lang.org/reference/type-coercions.html#type-coercions
类型协变是 Rust 的隐式行为(类似的还有 subtyping),用于改变一个 value 的 type,Rust 只在一些特定的位置(场景)才会使用类型协变。
注意:在函数传参匹配 trait bound 时不会进行协变,例如虽然 &mut i32 可以协变到 &i32, 但传参时不会协变:
- 带来的影响是:如果 Trait 作为函数参数限界,&i32 和 &mut i32 两种类型都需要实现该 Trait。
trait Trait {}
fn foo<X: Trait>(t: X) {}
impl<'a> Trait for &'a i32 {}
fn main() {
let t: &mut i32 = &mut 0;
foo(t);
}
// error[E0277]: the trait bound `&mut i32: Trait` is not satisfied
// --> src/main.rs:9:9
// |
// 3 | fn foo<X: Trait>(t: X) {}
// | ----- required by this bound in `foo`
// ...
// 9 | foo(t);
// | ^ the trait `Trait` is not implemented for `&mut i32`
// |
// = help: the following implementations were found:
// <&'a i32 as Trait>
// = note: `Trait` is implemented for `&i32`, but not for `&mut i32`
Rust 支持自动类型协变的场景(自动类型协变的转换都可以使用 as 运算符转换):
-
let statements where an explicit type is given. For example, &mut 42 is coerced to have type &i8 in the following: let _: &i8 = &mut 42; -
static and constitem declarations (similar to let statements). -
Argumentsfor function calls.The value being coerced is the actual parameter, and it is coerced to the type of the formal parameter. For example, &mut 42 is coerced to have type &i8 in the following:
fn bar(_: &i8) { } fn main() { bar(&mut 42); }For method calls, the receiver (self parameter) type is coerced differently, see the documentation on method-call expressions for details.
-
Instantiations of struct, union, or enum variant fieldsFor example, &mut 42 is coerced to have type &i8 in the following:
struct Foo<'a> { x: &'a i8 } fn main() { Foo { x: &mut 42 }; } -
Function results—either the final line of a block if it is not semicolon-terminated or any expression in a return statementFor example, x is coerced to have type &dyn Display in the following:
use std::fmt::Display; fn foo(x: &u32) -> &dyn Display { x }
If the expression in one of these coercion sites is a coercion-propagating expression, then the
relevant sub-expressions in that expression are also coercion sites. Propagation recurses from these
new coercion sites. Propagating expressions and their relevant sub-expressions are:
Array literals, where the array has type [U; n]. Each sub-expression in the array literal is a coercion site for coercion to type U.Array literals with repeating syntax, where the array has type [U; n]. The repeated sub-expression is a coercion site for coercion to type U.Tuples, where a tuple is a coercion site to type (U_0, U_1, …, U_n). Each sub-expression is a coercion site to the respective type, e.g. the zeroth sub-expression is a coercion site to type U_0.Parenthesized sub-expressions ((e)): if the expression has type U, then the sub-expression is a coercion site to U.Blocks: if a block has type U, then the last expression in the block (if it is not semicolon-terminated) is a coercion site to U. This includes blocks which are part of control flow statements, such as if/else, if the block has a known type.
21.3 Coercion types #
Coercion is allowed between the following types:
-
T to U if T is a
subtypeof U (reflexive case) -
T_1 to T_3 where T_1 coerces to T_2 and T_2 coerces to T_3 (
transitive case): Note that this is not fully supported yet. -
&mut T to &T -
*mut T to *const T -
&T to *const T -
&mut T to *mut T -
&T or &mut T to &Uif T implements Deref<Target = U>. For example: -
&mut T to &mut Uif T implements DerefMut<Target = U>. -
TyCtor(T) to TyCtor(U), where TyCtor(T) is one of
- &T
- &mut T
- *const T
- *mut T
- Box<T>
and where U can be obtained from T by
unsized coercion. -
Function item types to
fn pointers -
Non capturing closures to
fn pointers -
! to any T:例如 match 的某个条件返回 return
use std::ops::Deref;
struct CharContainer {
value: char,
}
impl Deref for CharContainer {
type Target = char;
fn deref<'a>(&'a self) -> &'a char {
&self.value
}
}
fn foo(arg: &char) {}
fn main() {
let x = &mut CharContainer { value: 'y' };
foo(x); //&mut CharContainer is coerced to &char.
}
21.4 Unsized Coercions #
The following coercions are called unsized coercions, since they relate to converting sized types to unsized types, and are permitted in a few cases where other coercions are not, as described
above. They can still happen anywhere else a coercion can occur.
Two traits, Unsize and CoerceUnsized, are used to assist in this process and expose it for library
use. The following coercions are built-ins and, if T can be coerced to U with one of them, then an
implementation of Unsize<U> for T will be provided:
[T; n] to [T].T to dyn U, when T implements U + Sized, and U is object safe. <- T 必须是 Sized- Foo<…, T, …> to Foo<…, U, …>, when:
- Foo is a struct.
- T implements Unsize<U>.
- The last field of Foo has a type involving T.
- If that field has type Bar<T>, then Bar<T> implements Unsized<Bar<U>>.
- T is not part of the type of any other fields.
Additionally, a type Foo<T> can implement CoerceUnsized<Foo<U>> when T implements Unsize<U> or CoerceUnsized<Foo<U>>. This allows it to provide a unsized coercion to Foo<U>.
Note: While the definition of the unsized coercions and their implementation has been stabilized, the traits themselves are not yet stable and therefore can’t be used directly in stable Rust.
T: ?Sized 前的 ? 只能用在 Sized trait 前,而不能用于其他 trait。这时需要使用 &T.
21.5 Least upper bound coercions #
In some contexts, the compiler must coerce together multiple types to try and find the most general
type. This is called a "Least Upper Bound" coercion. LUB coercion is used and only used in the
following situations:
- To find the common type for a series of if branches.
- To find the common type for a series of match arms.
- To find the common type for array elements.
- To find the type for the return type of a closure with multiple return statements.
- To check the type for the return type of a function with multiple return statements.
In each such case, there are a set of types T0..Tn to be mutually coerced to some target type T_t,
which is unknown to start. Computing the LUB coercion is done iteratively. The target type T_t
begins as the type T0. For each new type Ti, we consider whether
- If Ti can be coerced to the current target type T_t, then no change is made.
- Otherwise, check whether T_t can be coerced to Ti; if so, the T_t is changed to Ti. (This check is also conditioned on whether all of the source expressions considered thus far have implicit coercions.)
- If not, try to compute a mutual supertype of T_t and Ti, which will become the new target type.
Examples:
// For if branches
let bar = if true {
a
} else if false {
b
} else {
c
};
// For match arms
let baw = match 42 {
0 => a,
1 => b,
_ => c,
};
// For array elements
let bax = [a, b, c];
// For closure with multiple return statements
let clo = || {
if true {
a
} else if false {
b
} else {
c
}
};
let baz = clo();
// For type checking of function with multiple return statements
fn foo() -> i32 {
let (a, b, c) = (0, 1, 2);
match 42 {
0 => a,
1 => b,
_ => c,
}
}
In these examples, types of the ba* are found by LUB coercion. And the compiler checks whether LUB
coercion result of a, b, c is i32 in the processing of the function foo.
Caveat: This description is obviously informal. Making it more precise is expected to proceed as part of a general effort to specify the Rust type checker more precisely.
21.6 Unsize trait #
https://doc.rust-lang.org/std/marker/trait.Unsize.html
Unsized 是一个 marker trait, 只能是编译器自动实现,日常主要用到的是两种:
- 数组 [T; N] 实现了 Unsize<[T]>, 这意味着 &[T;N] 可以赋值给 &[T] 类型;
- trait object: 如果 value 实现了 MyTrait, 则可以将
value赋值给dyn MyTrait, 如:- let u: &dyn MyTrait = &value;
- let u: Box<dyn MyTrait> = Box::new(value);
pub trait Unsize<T> where T: ?Sized, { }
Types that can be “unsized” to a dynamically-sized type. For example, the sized array type [i8; 2]
implements Unsize<[i8]> and Unsize<dyn fmt::Debug> .
All implementations of Unsize are provided automatically by the compiler. Those implementations are:
- Arrays
[T; N]implementUnsize<[T]>. - A type implements
Unsize<dyn Trait + 'a>if all of these conditions are met:- The type implements
Trait. - Trait is object safe.
- The type is sized.
- The type outlives ‘a.
- The type implements
Structs Foo<..., T1, ..., Tn, ...>implementUnsize<Foo<..., U1, ..., Un, ...>>where any number of (type and const) parameters may be changed if all of these conditions are met:- Only the last field of Foo has a type involving the parameters T1, …, Tn.
- All other parameters of the struct are equal.
- Field<T1, …, Tn>: Unsize<Field<U1, …, Un>>, where Field<…> stands for the actual type of the struct’s last field.
Unsize is used along with ops::CoerceUnsized to allow “user-defined” containers such as Rc to contain dynamically-sized types . See the DST coercion RFC and the nomicon entry on coercion for
more details.
21.7 CoerceUnsized trait #
https://doc.rust-lang.org/std/ops/trait.CoerceUnsized.html
pub trait CoerceUnsized<T> where T: ?Sized, { }
CoerceUnsized 是 marker trait, 提供指针类型(含智能指针),如 &T/&mutT/*const T/*mut T/Box<T>/Rc<T>/Arc<T> ,以及包装器类型,如 Cell<T>/RefCell<T>/Pin<T>,到另一个类型 unsized 类型 U 提供 unsized coerce 。
T 和 U 都是 ?Sized.- &T 可以 unsized coerce 到 &U 或 *const U;
- &mut T 可以 unsized coerce 到 &mut U 或 *mut U 或 &U 或 *const U;
- 裸指针间 unsized 转换;
- 智能指针间转换,如 Box/Rc/Arc<T> 到 Box/Rc/Arc<U>;
- 智能指针的包装器类型,如 Cell/Pin<Box<T>> 到 Cell/Pin<Box<U>>;
常见的 unsized 类型转变由 Unsized trait 标记, 而且只能有编译器实现 ,只有两个,:
- slice [T], 如 arrary [T; N] 到 [T] 的 unsized 转变;
- trait object, 如 value 实现了 trait,则可以 unsized 转变为 Box<dyn trait> 或 dyn trait;
自定义类型可以通过实现 CoerceUnsized trait 来提供自身的指针、指针指针或 wrapper 类型到 unsized 类型的转变;
// &T 可以 unsized coerce 到 &U 或 *const U
impl<'a, 'b, T, U> CoerceUnsized<&'a U> for &'b T where 'b: 'a, T: Unsize<U> + ?Sized, U: ?Sized,
impl<'a, T, U> CoerceUnsized<*const U> for &'a T where T: Unsize<U> + ?Sized, U: ?Sized,
// &mut T 可以 unsized coerce 到 &mut U 或 *mut U 或 &U 或 *const U
impl<'a, T, U> CoerceUnsized<*mut U> for &'a mut T where T: Unsize<U> + ?Sized, U: ?Sized,
impl<'a, T, U> CoerceUnsized<&'a mut U> for &'a mut T where T: Unsize<U> + ?Sized, U: ?Sized,
impl<'a, 'b, T, U> CoerceUnsized<&'a U> for &'b mut T where 'b: 'a, T: Unsize<U> + ?Sized, U: ?Sized,
impl<'a, T, U> CoerceUnsized<*const U> for &'a mut T where T: Unsize<U> + ?Sized, U: ?Sized,
// 裸指针间转换
impl<T, U> CoerceUnsized<*const U> for *const T where T: Unsize<U> + ?Sized, U: ?Sized,
impl<T, U> CoerceUnsized<*const U> for *mut T where T: Unsize<U> + ?Sized, U: ?Sized,
impl<T, U> CoerceUnsized<*mut U> for *mut T where T: Unsize<U> + ?Sized, U: ?Sized,
// 智能指针间转换,如 Box<T> 到 Box<U>.
// Ref 是 RefCell.borrow() 返回的类型, RefMut 是 RefCell.borrow_mut() 返回的类型;
impl<'b, T, U> CoerceUnsized<Ref<'b, U>> for Ref<'b, T> where T: Unsize<U> + ?Sized, U: ?Sized,
impl<'b, T, U> CoerceUnsized<RefMut<'b, U>> for RefMut<'b, T> where T: Unsize<U> + ?Sized, U: ?Sized,
impl<T, U, A> CoerceUnsized<Box<U, A>> for Box<T, A> where T: Unsize<U> + ?Sized, A: Allocator, U: ?Sized,
impl<T, U, A> CoerceUnsized<Rc<U, A>> for Rc<T, A> where T: Unsize<U> + ?Sized, A: Allocator, U: ?Sized,
impl<T, U, A> CoerceUnsized<Arc<U, A>> for Arc<T, A> where T: Unsize<U> + ?Sized, A: Allocator, U: ?Sized,
impl<T, U> CoerceUnsized<NonNull<U>> for NonNull<T> where T: Unsize<U> + ?Sized, U: ?Sized,
// 智能指针的包装器类型,如 Cell<Box<T>> 到 Cell<Box<U>>.
impl<Ptr, U> CoerceUnsized<Pin<U>> for Pin<Ptr> where Ptr: CoerceUnsized<U>,
impl<T, U> CoerceUnsized<Cell<U>> for Cell<T> where T: CoerceUnsized<U>,
impl<T, U> CoerceUnsized<RefCell<U>> for RefCell<T> where T: CoerceUnsized<U>,
impl<T, U> CoerceUnsized<SyncUnsafeCell<U>> for SyncUnsafeCell<T> where T: CoerceUnsized<U>,
impl<T, U> CoerceUnsized<UnsafeCell<U>> for UnsafeCell<T> where T: CoerceUnsized<U>,
impl<T, U, A> CoerceUnsized<Weak<U, A>> for std::rc::Weak<T, A> where T: Unsize<U> + ?Sized, A: Allocator, U: ?Sized,
impl<T, U, A> CoerceUnsized<Weak<U, A>> for std::sync::Weak<T, A> where T: Unsize<U> + ?Sized, A: Allocator, U: ?Sized,
注意:Option 没有实现 CoerceUnsized,所以不能实现 Option<T> 到 Option<U> 的转换:
trait X {
fn x(&mut self);
}
struct XX;
impl X for XX {
fn x(&mut self) {
todo!()
}
}
struct C<'a> {
mut_ref: Option<&'a mut dyn X>,
}
fn main() {
// Box <dyn X > 等效于 Box <dyn X + 'static>,所以 b 的实际类型是 Option<Box<dyn X + 'static>>
let mut b: Option<Box<dyn X>> = Some(Box::new(XX));
// as_deref_mut() 的签名是: pub fn as_deref_mut(&mut self) -> Option<&mut <T as Deref>::Target>
// where T: DerefMut,所以 b.as_deref_mut() 的结果类型是 Option<&'a mut(dyn X + 'static)>.
// 重点来了: Option<T> 是不支持协变到 Option<U> 的, 所以 Option<&'a mut(dyn X + 'static)> 不能协
// 变到 mut_ref 要求的 Option<&'a mut(dyn X + 'a).
// match 匹配 Some(x) 之所以 OK, 是因为 x 此时的类型已经是 &'a mut(dyn X + 'static) 了,而标准库
// 实现了 impl<'a, T, U> CoerceUnsized<&'a mut U> for &'a mut T where T: Unsize<U> + ?Sized, U:
// ?Sized,当 T 是 unsized 的 dyn X + 'static 且 U 是 dyn X + 'a 时, 满足上面的 where 约束, 所以
// 支持 &'a mut(dyn X + 'static) 到 &'a mut(dyn X + 'a) 的 unsized 协变, 所以下面的 match 表达式
// 可以执行成功.
// error[E0597]: `b` does not live long enough
// let c = C {
// mut_ref: b.as_deref_mut(),
// };
let c = match b.as_deref_mut() {
None => C { mut_ref: None },
Some(x) => C { mut_ref: Some(x) },
};
}
其它例子:
// 以下是使用 CoerceUnsized trait 实现的 type coercion 的转换.
//
// 满足 CoerceUnsized<Ptr<U>> for Ptr<T> where T: Unsize<U> + ?Sized 时,
// Ptr<T> 可以 type coercion 到 Ptr<U>, 这里的 Ptr 类型是:
//
// &'b T 或 &'b mut T 或 Ref<'b, T> 或 RefMut<'b, T> 或 *mut T 或 *const T 或 Cell<T> 或 RefCell<T>或 Box<T, A> 或 Rc<T, A> 或 Arc<T, A>,
//
// 但不包含 Result 或 Option
// [T; N] -> [T]
let bo: Box<[i32]> = Box::new([1, 2, 3]);
// 1i32 实现了 dyn std::fmt::Display 和 dyn std::any::Any, 所以 1i32 可以 unsized coercion 到 trait object
// trait object 有两种形式
// 1. &dyn Trait
let dsd: &dyn std::fmt::Display = &1i32;
// 2. Box<dyn Trait>
let bo: Box<dyn std::fmt::Display> = Box::new(1i32);
let bo: Box<dyn std::any::Any> = Box::new(1i32);
let bo: Box<&dyn std::fmt::Display> = Box::new(&1i32);
// 以下也是 CoerceUnsized trait 实现的 type coercion 的转换. U 需要是 unsized type.
// &T -> &U
let u: &dyn std::fmt::Display = &123i32;
// &mut T -> &U
let u: &dyn std::fmt::Display = &mut 123i32;
// &mut T -> &mut U
let u: &mut dyn std::fmt::Display = &mut 123i32;
// &T -> *const U
let u: *const dyn std::fmt::Display = &123i32;
// &mut T -> *const U
let u: *const dyn std::fmt::Display = &mut 123i32;
// &mut T -> *mut U
let u: *mut dyn std::fmt::Display = &mut 123i32;
22 iterator #
Iterator trait 定义:
pub trait Iterator {
type Item;
fn next(&mut self) -> Option<Self::Item>;
// 其他都是缺省实现的方法。
}
可以直接在自定义类型上实现迭代器,如 impl Iterator for ReadDir,也可以通过类型的方法返回一个实现迭代器的对象(惯例是 Iter/IterMut/IntoIter),惯例的方法名是:
- iter(&self): 返回的类型惯例是 Iter,迭代返回的是 &T 类型;
- iter_mut(&mut self): 返回的类型惯例是 IterMut,迭代返回的是 &mut T 类型;
- into_iter(self): 返回的迭代器对象惯例类型是 IntoIter,转移了被迭代对象的所有权,迭代返回的是 T 类型;
for-in 循环的对象需要实现 std::iter::IntoIterator,也就是对象的 into_iter() 返回一个 Iterator, 但是也可以给被迭代对象加 &obj 或 &mut obj 来让 for-in 使用 iter/iter_mut:
当迭代它们的引用类型时,返回的元素是引用类型,这是由于标准库 为 &HashMap/&mut HashMap/HashMap 类型分别实现 了对应的 IntoIterator:
// https://doc.rust-lang.org/src/std/collections/hash/map.rs.html#2173-2182
#[stable(feature = "rust1", since = "1.0.0")]
impl<'a, K, V, S> IntoIterator for &'a HashMap<K, V, S> {
type Item = (&'a K, &'a V);
type IntoIter = Iter<'a, K, V>; // Iter 是 HashMap 定义的实现 Iterator trait 的类型
#[inline]
#[rustc_lint_query_instability]
fn into_iter(self) -> Iter<'a, K, V> {
self.iter()
}
}
#[stable(feature = "rust1", since = "1.0.0")]
impl<'a, K, V, S> IntoIterator for &'a mut HashMap<K, V, S> {
type Item = (&'a K, &'a mut V);
type IntoIter = IterMut<'a, K, V>; // IterMut 是 HashMap 定义的实现 Iterator trait 的类型
#[inline]
#[rustc_lint_query_instability]
fn into_iter(self) -> IterMut<'a, K, V> {
self.iter_mut()
}
}
#[stable(feature = "rust1", since = "1.0.0")]
impl<K, V, S> IntoIterator for HashMap<K, V, S> {
type Item = (K, V);
type IntoIter = IntoIter<K, V>; // IntoIter 是 HashMap 定义的实现 Iterator trait 的类型
/// Creates a consuming iterator, that is, one that moves each key-value
/// pair out of the map in arbitrary order. The map cannot be used after
/// calling this.
///
/// # Examples
///
/// ```
/// use std::collections::HashMap;
///
/// let map = HashMap::from([
/// ("a", 1),
/// ("b", 2),
/// ("c", 3),
/// ]);
///
/// // Not possible with .iter()
/// let vec: Vec<(&str, i32)> = map.into_iter().collect();
/// ```
#[inline]
#[rustc_lint_query_instability]
fn into_iter(self) -> IntoIter<K, V> {
IntoIter { base: self.base.into_iter() }
}
}
Rust 为实现了 Iterator 的类型自动实现了 IntoIterator ,所以可以使用 for i in vec.iter() {println!("{i}")};
#[rustc_const_unstable(feature = "const_intoiterator_identity", issue = "90603")]
#[stable(feature = "rust1", since = "1.0.0")]
impl<I: Iterator> IntoIterator for I {
type Item = I::Item;
type IntoIter = I;
#[inline]
fn into_iter(self) -> I {
self
}
}
Vec<T>,[T; N],HashSet<T> 等实现了 IntoIterator:
let mut v = vec![1, 2, 3];
for i in &v {
println!("{i}")
}
for in in &mut v {
println!("{i}")
}
for i in v {
println!("{i}");
}
// v 不可再访问
注意:
- 如果直接在自定义类型上实现迭代器,如 impl Iterator for ReadDir,则在 ReadDir 上调用一些 self 迭代器方法,如 readDir.take(3) 后,readDir 将失效。
- 但是如果在 iter()/iter_mut() 返回的迭代器对象上调用 take() 方法,消耗的是迭代器本身,原对象还可以正常方法;
- 由于 into_iter() 会转移对象所有权,迭代也是直接放回元素本身,所以 take() 返回并消耗对象。
消耗迭代器的方式:
- for-in 循环: 需要对象实现 std::iter::IntoIterator trait;
- Iterator trait 定义的泛型方法大部分都是消耗 self,如 iter.sum()/map() 等;
- 绝大部分迭代器方法使用 self,所以
调用后迭代器对象所有权发生转移。
for-in 循环器默认使用的是 IntoIter 迭代器,它会消耗被迭代对象的元素。可以通过 &obj 或 &mut obj 来使用 Iter 或 IterMut 迭代器;
let mut array = [1, 2, 3];
// IntoIter
for n in array { // n 为 uint
println!(n);
}
// 迭代后 array 不能再使用
// Iter
for n in &array { // n 为 &uint
println!(n);
}
// 迭代后 array 可以使用
// IterMut
for n in &mut array { // n 为 &mut uint
println!(n);
}
for-in 迭代器也可以使用 pattern match 来展开迭代变量:
let mut array = [(1, 2, 3), (4, 5, 6)];
for (a, b, &c) in &array { // &c 匹配引用类型,所以 c 是引用类型
println!("{} {} {}", a, b, *c);
}
迭代器适配器(iterator adaptor)是 Iterator trait 上定义的方法,它一般会消耗旧 Iterator (这些适配器方法的输入绝大大部分是 self)并返回新的 Iterator。Iterator 都是 lazy 的,必须被消耗时才能干活,如调用 collect() 方法;
- collect() 返回的是一个实现了 FromIterator<Self::Item> trait 的对象;
- 标准库的容器类型,如 Vec/HastSet/HashMap 都实现了 FromIterator trait,可以从可迭代对象生成容器元素。
#[derive(PartialEq, Debug)]
struct Shoe {
size: u32,
style: String,
}
// 由于返回一个 Vec<Shoe> ,所以需要 into_iter() 返回的 IntoIter 迭代器。
fn shoes_in_size(shoes: Vec<Shoe>, shoe_size: u32) -> Vec<Shoe> {
shoes.into_iter().filter(|s| s.size == shoe_size).collect()
}
pub trait Iterator {
type Item;
fn collect<B: FromIterator<Self::Item>>(self) -> B where Self: Sized,
{
FromIterator::from_iter(self)
}
}
// https://doc.rust-lang.org/std/iter/trait.FromIterator.html
pub trait FromIterator<A>: Sized {
// Required method
fn from_iter<T>(iter: T) -> Self
where T: IntoIterator<Item = A>;
}
// Vec<T> 实现了 FromIterator<T> trait, 所以 collect() 方法可以返回该类型对象:
let v1: Vec<i32> = vec![1, 2, 3];
let v2: Vec<&i32> = v1.iter().map(|x| x + 1).collect(); // iter() 返回 &32, 所以最终 collect() 返回的是 &i32.
assert_eq!(v2, vec![2, 3, 4]);
// 另一个例子
impl Config {
pub fn build(
mut args: impl Iterator<Item = String>, // Vec<String> 实现了该 trait
) -> Result<Config, &'static str> {
args.next();
let query = match args.next() {
Some(arg) => arg,
None => return Err("Didn't get a query string"),
};
let file_path = match args.next() {
Some(arg) => arg,
None => return Err("Didn't get a file path"),
};
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
fn main() {
let config = Config::build(env::args()).unwrap_or_else(|err| {
eprintln!("Problem parsing arguments: {err}");
process::exit(1);
});
// --snip--
}
Option/Result 是 enum 类型,但是也支持迭代(实现了 IntoIterator),效果如一个或 0 个元素。
let turing = Some("Turing");
let mut logicians = vec!["Curry", "Kleene", "Markov"];
logicians.extend(turing); // Option 实现了 IntoIterator, 因此可以传入 .extend() 方法中
// 也可以传入 chain() 方法中
let turing = Some("Turing");
let logicians = vec!["Curry", "Kleene", "Markov"];
for logician in logicians.iter().chain(turing.iter()) {
println!("{logician} is a logician");
}
Rust range 表达式是一系列支持迭代的 std::ops::RangeXX struct 类型的语法糖:
1..2; // std::ops::Range
3..; // std::ops::RangeFrom
..4; // std::ops::RangeTo
..; // std::ops::RangeFull
5..=6; // std::ops::RangeInclusive
..=7; // std::ops::RangeToInclusive
let x = std::ops::Range {start: 0, end: 10};
let y = 0..10;
assert_eq!(x, y);
22.1 迭代器方法 #
// Required method
fn next(&mut self) -> Option<Self::Item>;
// 返回下一个 N 个元素的数组,N 的数量可以指定或推导
fn next_chunk<const N: usize>( &mut self ) -> Result<[Self::Item; N], IntoIter<Self::Item, N>> where Self: Sized
let mut iter = "lorem".chars();
assert_eq!(iter.next_chunk().unwrap(), ['l', 'o']); // N is inferred as 2
assert_eq!(iter.next_chunk().unwrap(), ['r', 'e', 'm']); // N is inferred as 3
assert_eq!(iter.next_chunk::<4>().unwrap_err().as_slice(), &[]); // N is explicitly 4
let quote = "not all those who wander are lost";
let [first, second, third] = quote.split_whitespace().next_chunk().unwrap(); // 自动推导
assert_eq!(first, "not");
assert_eq!(second, "all");
assert_eq!(third, "those");
// 返回迭代器中剩下元素的下界和上界
fn size_hint(&self) -> (usize, Option<usize>) { ... }
// 返回迭代器中元素数量(消耗)
fn count(self) -> usize where Self: Sized { ... }
// 返回最后一个元素(消耗)
fn last(self) -> Option<Self::Item> where Self: Sized { ... }
// 前进迭代器 n 个元素
fn advance_by(&mut self, n: usize) -> Result<(), NonZero<usize>> { ... }
#![feature(iter_advance_by)]
use std::num::NonZeroUsize;
let a = [1, 2, 3, 4];
let mut iter = a.iter();
assert_eq!(iter.advance_by(2), Ok(()));
assert_eq!(iter.next(), Some(&3));
assert_eq!(iter.advance_by(0), Ok(()));
assert_eq!(iter.advance_by(100), Err(NonZeroUsize::new(99).unwrap())); // only `&4` was skipped
// 返回第 n 个元素(0 开始)
fn nth(&mut self, n: usize) -> Option<Self::Item> { ... }
let a = [1, 2, 3];
let mut iter = a.iter();
assert_eq!(iter.nth(1), Some(&2));
assert_eq!(iter.nth(1), None); // 调用 nth(n) 多次并不重复返回
assert_eq!(iter.nth(10), None);
// 返回一个新的迭代器,每次返回原始迭代器的 +step 后的元素
fn step_by(self, step: usize) -> StepBy<Self> where Self: Sized { ... }
let a = [0, 1, 2, 3, 4, 5];
let mut iter = a.iter().step_by(2);
assert_eq!(iter.next(), Some(&0)); // 第一个元素
assert_eq!(iter.next(), Some(&2)); // +2
assert_eq!(iter.next(), Some(&4));
assert_eq!(iter.next(), None);
// 将两个迭代器合并为一个,先迭代自身再迭代传入的 other, 迭代的元素 Item 类型要一致
fn chain<U>(self, other: U) -> Chain<Self, <U as IntoIterator>::IntoIter> where Self: Sized, U: IntoIterator<Item = Self::Item> { ... }
let a1 = [1, 2, 3];
let a2 = [4, 5, 6];
let mut iter = a1.iter().chain(a2.iter());
assert_eq!(iter.next(), Some(&1));
assert_eq!(iter.next(), Some(&2));
assert_eq!(iter.next(), Some(&3));
assert_eq!(iter.next(), Some(&4));
assert_eq!(iter.next(), Some(&5));
assert_eq!(iter.next(), Some(&6));
assert_eq!(iter.next(), None);
// 从两个迭代器返回一个新的迭代器,每次各返回一个值,直到某个迭代器完成
fn zip<U>(self, other: U) -> Zip<Self, <U as IntoIterator>::IntoIter> where Self: Sized, U: IntoIterator { ... }
let a1 = [1, 2, 3];
let a2 = [4, 5, 6];
let mut iter = a1.iter().zip(a2.iter());
assert_eq!(iter.next(), Some((&1, &4)));
assert_eq!(iter.next(), Some((&2, &5)));
assert_eq!(iter.next(), Some((&3, &6)));
assert_eq!(iter.next(), None);
let enumerate: Vec<_> = "foo".chars().enumerate().collect();
let zipper: Vec<_> = (0..).zip("foo".chars()).collect();
assert_eq!((0, 'f'), enumerate[0]);
assert_eq!((0, 'f'), zipper[0]);
assert_eq!((1, 'o'), enumerate[1]);
assert_eq!((1, 'o'), zipper[1]);
assert_eq!((2, 'o'), enumerate[2]);
assert_eq!((2, 'o'), zipper[2]);
// 在迭代器元素间插入一个 separator 元素(需要实现 Clone)
fn intersperse(self, separator: Self::Item) -> Intersperse<Self> where Self: Sized, Self::Item: Clone
#![feature(iter_intersperse)]
let hello = ["Hello", "World", "!"].iter().copied().intersperse(" ").collect::<String>();
assert_eq!(hello, "Hello World !");
let mut a = [0, 1, 2].iter().intersperse(&100);
assert_eq!(a.next(), Some(&0)); // The first element from `a`.
assert_eq!(a.next(), Some(&100)); // The separator.
assert_eq!(a.next(), Some(&1)); // The next element from `a`.
assert_eq!(a.next(), Some(&100)); // The separator.
assert_eq!(a.next(), Some(&2)); // The last element from `a`.
assert_eq!(a.next(), None); // The iterator is finished.
// 使用指定的闭包函数插入分隔符
fn intersperse_with<G>(self, separator: G) -> IntersperseWith<Self, G> where Self: Sized, G: FnMut() -> Self::Item
// 使用指定的闭包函数来处理每一个元素(消耗原迭代器),函数结果形成另一个可迭代对象
fn map<B, F>(self, f: F) -> Map<Self, F> where Self: Sized, F: FnMut(Self::Item) -> B { ... }
let a = [1, 2, 3];
let mut iter = a.iter().map(|x| 2 * x);
assert_eq!(iter.next(), Some(2));
assert_eq!(iter.next(), Some(4));
assert_eq!(iter.next(), Some(6));
assert_eq!(iter.next(), None);
// 对每一个元素调用指定的闭包函数(消耗迭代器)
fn for_each<F>(self, f: F) where Self: Sized, F: FnMut(Self::Item) { ... }
use std::sync::mpsc::channel;
let (tx, rx) = channel();
(0..5).map(|x| x * 2 + 1).for_each(move |x| tx.send(x).unwrap());
let v: Vec<_> = rx.iter().collect();
assert_eq!(v, vec![1, 3, 5, 7, 9]);
// 使用 predicate 过滤元素,返回为 true 的元素的迭代器(predicate 的参数是元素的借用)
fn filter<P>(self, predicate: P) -> Filter<Self, P> where Self: Sized, P: FnMut(&Self::Item) -> bool { ... }
let a = [0, 1, 2];
let mut iter = a.iter().filter(|x| **x > 1); // need two *s! 和 map() 不同,filter 闭包函数的参数是 &T 类型。
assert_eq!(iter.next(), Some(&2));
assert_eq!(iter.next(), None);
let a = [0, 1, 2];
let mut iter = a.iter().filter(|&x| *x > 1); // both & and *
assert_eq!(iter.next(), Some(&2));
assert_eq!(iter.next(), None);
let a = [0, 1, 2];
let mut iter = a.iter().filter(|&&x| x > 1); // two &s
assert_eq!(iter.next(), Some(&2));
assert_eq!(iter.next(), None);
// 对迭代元素值执行 f 闭包,返回结果为 Some(value) 的 value 迭代器
fn filter_map<B, F>(self, f: F) -> FilterMap<Self, F> where Self: Sized, F: FnMut(Self::Item) -> Option<B> { ... }
let a = ["1", "two", "NaN", "four", "5"];
let mut iter = a.iter().filter_map(|s| s.parse().ok());
assert_eq!(iter.next(), Some(1));
assert_eq!(iter.next(), Some(5));
assert_eq!(iter.next(), None);
// 等效为 filter().map()
let a = ["1", "two", "NaN", "four", "5"];
let mut iter = a.iter().map(|s| s.parse()).filter(|s| s.is_ok()).map(|s| s.unwrap());
assert_eq!(iter.next(), Some(1));
assert_eq!(iter.next(), Some(5));
assert_eq!(iter.next(), None);
// 返回 (i, value) 的迭代器,i 的类型为 usize
fn enumerate(self) -> Enumerate<Self> where Self: Sized { ... }
let a = ['a', 'b', 'c'];
let mut iter = a.iter().enumerate();
assert_eq!(iter.next(), Some((0, &'a')));
assert_eq!(iter.next(), Some((1, &'b')));
assert_eq!(iter.next(), Some((2, &'c')));
assert_eq!(iter.next(), None);
// 返回一个迭代器,它的 peek/peek_mut 返回下一个迭代元素,但是并不消费迭代元素
fn peekable(self) -> Peekable<Self> where Self: Sized { ... }
let xs = [1, 2, 3];
let mut iter = xs.iter().peekable();
// peek() lets us see into the future
assert_eq!(iter.peek(), Some(&&1));
assert_eq!(iter.next(), Some(&1));
assert_eq!(iter.next(), Some(&2));
// we can peek() multiple times, the iterator won't advance
assert_eq!(iter.peek(), Some(&&3));
assert_eq!(iter.peek(), Some(&&3));
assert_eq!(iter.next(), Some(&3));
// after the iterator is finished, so is peek()
assert_eq!(iter.peek(), None);
assert_eq!(iter.next(), None);
// 迭代时一直忽略元素,直到 predicte 返回 false(包含返回 false 的元素)
fn skip_while<P>(self, predicate: P) -> SkipWhile<Self, P> where Self: Sized, P: FnMut(&Self::Item) -> bool { ... }
let a = [-1i32, 0, 1];
let mut iter = a.iter().skip_while(|x| x.is_negative());
assert_eq!(iter.next(), Some(&0));
assert_eq!(iter.next(), Some(&1));
assert_eq!(iter.next(), None);
// 注意:一旦 predicate 返回 false,后续就不再对元素进行判断
let a = [-1, 0, 1, -2];
let mut iter = a.iter().skip_while(|x| **x < 0);
assert_eq!(iter.next(), Some(&0));
assert_eq!(iter.next(), Some(&1));
// while this would have been false, since we already got a false,
// skip_while() isn't used any more
assert_eq!(iter.next(), Some(&-2));
assert_eq!(iter.next(), None);
// 当 predicate 返回 true 时,返回元素。但是一旦返回 false,则忽略后续的元素。
fn take_while<P>(self, predicate: P) -> TakeWhile<Self, P> where Self: Sized, P: FnMut(&Self::Item) -> bool { ... }
let a = [-1i32, 0, 1];
let mut iter = a.iter().take_while(|x| x.is_negative());
assert_eq!(iter.next(), Some(&-1));
assert_eq!(iter.next(), None);
// 一旦 predicate 返回 false,就不再返回后续的元素。
let a = [-1, 0, 1, -2];
let mut iter = a.iter().take_while(|x| **x < 0);
assert_eq!(iter.next(), Some(&-1));
// We have more elements that are less than zero, but since we already
// got a false, take_while() isn't used any more
assert_eq!(iter.next(), None);
// 持续对每个元素应用 predicate,直到它返回 None(也就是 predicate 返回 some 时继续)
fn map_while<B, P>(self, predicate: P) -> MapWhile<Self, P> where Self: Sized, P: FnMut(Self::Item) -> Option<B> { ... }
let a = [-1i32, 4, 0, 1];
let mut iter = a.iter().map_while(|x| 16i32.checked_div(*x));
assert_eq!(iter.next(), Some(-16));
assert_eq!(iter.next(), Some(4));
assert_eq!(iter.next(), None);
// 忽略前 n 个元素
fn skip(self, n: usize) -> Skip<Self> where Self: Sized { ... }
let a = [1, 2, 3];
let mut iter = a.iter().skip(2);
assert_eq!(iter.next(), Some(&3));
assert_eq!(iter.next(), None);
// 只获取前 n 个元素
fn take(self, n: usize) -> Take<Self> where Self: Sized { ... }
let v = [1, 2];
let mut iter = v.into_iter().take(5);
assert_eq!(iter.next(), Some(1));
assert_eq!(iter.next(), Some(2));
assert_eq!(iter.next(), None);
// 返回一个迭代器,每次迭代返回 f 闭包执行的结果 Some,当闭包 f 返回 None 时停止迭代
fn scan<St, B, F>(self, initial_state: St, f: F) -> Scan<Self, St, F> where Self: Sized, F: FnMut(&mut St, Self::Item) -> Option<B> { ... }
let a = [1, 2, 3, 4];
let mut iter = a.iter().scan(1, |state, &x| {
// each iteration, we'll multiply the state by the element ...
*state = *state * x;
// ... and terminate if the state exceeds 6
if *state > 6 {
return None;
}
// ... else yield the negation of the state
Some(-*state)
});
assert_eq!(iter.next(), Some(-1));
assert_eq!(iter.next(), Some(-2));
assert_eq!(iter.next(), Some(-6));
assert_eq!(iter.next(), None);
// 先对元素进行 map F 操作,F 返回一个迭代器,然后对各 map 结果迭代器进行 flat
fn flat_map<U, F>(self, f: F) -> FlatMap<Self, U, F> where Self: Sized, U: IntoIterator, F: FnMut(Self::Item) -> U
let words = ["alpha", "beta", "gamma"];
// chars() returns an iterator
let merged: String = words.iter().flat_map(|s| s.chars()).collect();
assert_eq!(merged, "alphabetagamma");
// 返回一个将可迭代元素打平的迭代器
fn flatten(self) -> Flatten<Self> where Self: Sized, Self::Item: IntoIterator
let data = vec![vec![1, 2, 3, 4], vec![5, 6]];
let flattened = data.into_iter().flatten().collect::<Vec<u8>>();
assert_eq!(flattened, &[1, 2, 3, 4, 5, 6]);
// Option/Result 也是可迭代的,所以可以使用 flatten() 处理
let options = vec![Some(123), Some(321), None, Some(231)];
let flattened_options: Vec<_> = options.into_iter().flatten().collect();
assert_eq!(flattened_options, vec![123, 321, 231]);
let results = vec![Ok(123), Ok(321), Err(456), Ok(231)];
let flattened_results: Vec<_> = results.into_iter().flatten().collect();
assert_eq!(flattened_results, vec![123, 321, 231]);
// flatten 只会打平一级
let d3 = [[[1, 2], [3, 4]], [[5, 6], [7, 8]]];
let d2 = d3.iter().flatten().collect::<Vec<_>>();
assert_eq!(d2, [&[1, 2], &[3, 4], &[5, 6], &[7, 8]]);
let d1 = d3.iter().flatten().flatten().collect::<Vec<_>>();
assert_eq!(d1, [&1, &2, &3, &4, &5, &6, &7, &8]);
// 先将元素按照 N 分组 window(window 间元素有重合),然后再对每个 window 的元素执行 f 闭包,如果元
// 素少于 N 则返回空迭代器
fn map_windows<F, R, const N: usize>(self, f: F) -> MapWindows<Self, F, N> where Self: Sized, F: FnMut(&[Self::Item; N]) -> R { ... }
#![feature(iter_map_windows)]
let strings = "abcd".chars()
.map_windows(|[x, y]| format!("{}+{}", x, y)) // &['a', 'b'], &['b', 'c'] and &['c', 'd']
.collect::<Vec<String>>();
assert_eq!(strings, vec!["a+b", "b+c", "c+d"]);
#![feature(iter_map_windows)]
let mut it = [0.5, 1.0, 3.5, 3.0, 8.5, 8.5, f32::NAN].iter()
.map_windows(|[a, b]| a <= b);
assert_eq!(it.next(), Some(true)); // 0.5 <= 1.0
assert_eq!(it.next(), Some(true)); // 1.0 <= 3.5
assert_eq!(it.next(), Some(false)); // 3.5 <= 3.0
assert_eq!(it.next(), Some(true)); // 3.0 <= 8.5
assert_eq!(it.next(), Some(true)); // 8.5 <= 8.5
assert_eq!(it.next(), Some(false)); // 8.5 <= NAN
assert_eq!(it.next(), None);
// 返回一个新迭代器,终止于原迭代器返回的第一个 None,用于防止原迭代器不规范的实现
fn fuse(self) -> Fuse<Self> where Self: Sized { ... }
// 对迭代的每一个元素执行闭包操作
fn inspect<F>(self, f: F) -> Inspect<Self, F> where Self: Sized, F: FnMut(&Self::Item) { ... }
// let's add some inspect() calls to investigate what's happening
let sum = a.iter()
.cloned()
.inspect(|x| println!("about to filter: {x}"))
.filter(|x| x % 2 == 0)
.inspect(|x| println!("made it through filter: {x}"))
.fold(0, |sum, i| sum + i);
println!("{sum}");
// borrow 但不转移 Self,迭代器可以继续使用
fn by_ref(&mut self) -> &mut Self where Self: Sized { ... }
let mut words = ["hello", "world", "of", "Rust"].into_iter();
// Take the first two words.
let hello_world: Vec<_> = words.by_ref().take(2).collect(); // 不转移 words
assert_eq!(hello_world, vec!["hello", "world"]);
// Collect the rest of the words. We can only do this because we used `by_ref` earlier.
let of_rust: Vec<_> = words.collect(); // words 还可以继续使用
assert_eq!(of_rust, vec!["of", "Rust"]);
// 使用 B 的 FromIterator trait 来从自身迭代器元素生成 B 类型对象
fn collect<B>(self) -> B where B: FromIterator<Self::Item>, Self: Sized
let doubled: Vec<i32> = a.iter() .map(|&x| x * 2) .collect();
assert_eq!(vec![2, 4, 6], doubled);
let a = [1, 2, 3];
let doubled = a.iter().map(|x| x * 2).collect::<Vec<i32>>();
assert_eq!(vec![2, 4, 6], doubled);
// 检查 Result 列表
let results = [Ok(1), Err("nope"), Ok(3), Err("bad")];
let result: Result<Vec<_>, &str> = results.iter().cloned().collect();
// gives us the first error
assert_eq!(Err("nope"), result);
let results = [Ok(1), Ok(3)];
let result: Result<Vec<_>, &str> = results.iter().cloned().collect();
// gives us the list of answers
assert_eq!(Ok(vec![1, 3]), result);
// 允许失败的 collect,主要用于将迭代元素是 Option<T> 转换为 Option<Collector<T>> 类型
fn try_collect<B>( &mut self ) -> ::TryType where Self: Sized, Self::Item: Try, <Self::Item as Try>::Residual: Residual<B>, B: FromIterator<<Self::Item as Try>::Output> { ... }
#![feature(iterator_try_collect)]
let u = vec![Some(1), Some(2), Some(3)];
let v = u.into_iter().try_collect::<Vec<i32>>();
assert_eq!(v, Some(vec![1, 2, 3]));
// 将 Self 迭代的元素添加到传入的 collection 中
fn collect_into<E>(self, collection: &mut E) -> &mut E where E: Extend<Self::Item>, Self: Sized { ... }
#![feature(iter_collect_into)]
let a = [1, 2, 3];
let mut vec: Vec::<i32> = vec![0, 1];
a.iter().map(|&x| x * 2).collect_into(&mut vec);
a.iter().map(|&x| x * 10).collect_into(&mut vec);
assert_eq!(vec, vec![0, 1, 2, 4, 6, 10, 20, 30]);
// 使用 f 将迭代器元素分两组,分别为返回 true/false 的元素
fn partition<B, F>(self, f: F) -> (B, B) where Self: Sized, B: Default + Extend<Self::Item>, F: FnMut(&Self::Item) -> bool { ... }
let a = [1, 2, 3];
let (even, odd): (Vec<_>, Vec<_>) = a
.into_iter()
.partition(|n| n % 2 == 0);
assert_eq!(even, vec![2]);
assert_eq!(odd, vec![1, 3]);
// 原地修改 self,前一半部分为 true,后一半为 false,返回 true 元素数量
fn partition_in_place<'a, T, P>(self, predicate: P) -> usize where T: 'a, Self: Sized + DoubleEndedIterator<Item = &'a mut T>, P: FnMut(&T) -> bool { ... }
#![feature(iter_partition_in_place)]
let mut a = [1, 2, 3, 4, 5, 6, 7];
// Partition in-place between evens and odds
let i = a.iter_mut().partition_in_place(|&n| n % 2 == 0);
assert_eq!(i, 3);
assert!(a[..i].iter().all(|&n| n % 2 == 0)); // evens
assert!(a[i..].iter().all(|&n| n % 2 == 1)); // odds
// 返回 self 是否按照 predicate 排序
fn is_partitioned<P>(self, predicate: P) -> bool where Self: Sized, P: FnMut(Self::Item) -> bool { ... }
#![feature(iter_is_partitioned)]
assert!("Iterator".chars().is_partitioned(char::is_uppercase));
assert!(!"IntoIterator".chars().is_partitioned(char::is_uppercase));
fn try_fold<B, F, R>(&mut self, init: B, f: F) -> R where Self: Sized, F: FnMut(B, Self::Item) -> R, R: Try<Output = B>
fn try_for_each<F, R>(&mut self, f: F) -> R where Self: Sized, F: FnMut(Self::Item) -> R, R: Try<Output = ()>
// 将迭代器值按照 F 进行聚合,同时传入初始值,返回最后的结果
fn fold<B, F>(self, init: B, f: F) -> B where Self: Sized, F: FnMut(B, Self::Item) -> B { ... }
let a = [1, 2, 3];
// the sum of all of the elements of the array
let sum = a.iter().fold(0, |acc, x| acc + x);
assert_eq!(sum, 6);
// 和 fold 类似,但是使用第一个值作为初始值
fn reduce<F>(self, f: F) -> Option<Self::Item> where Self: Sized, F: FnMut(Self::Item, Self::Item) -> Self::Item { ... }
let reduced: i32 = (1..10).reduce(|acc, e| acc + e).unwrap();
assert_eq!(reduced, 45);
// Which is equivalent to doing it with `fold`:
let folded: i32 = (1..10).fold(0, |acc, e| acc + e);
assert_eq!(reduced, folded);
fn try_reduce<F, R>( &mut self, f: F ) -> >::TryType where Self: Sized, F: FnMut(Self::Item, Self::Item) -> R, R: Try<Output = Self::Item>, <R as Try>::Residual: Residual<Option<Self::Item>>
// 迭代的所有元素满足 f
fn all<F>(&mut self, f: F) -> bool where Self: Sized, F: FnMut(Self::Item) -> bool { ... }
// 迭代的任一元素满足 f
fn any<F>(&mut self, f: F) -> bool where Self: Sized, F: FnMut(Self::Item) -> bool { ... }
// 返回 predicate 为 true 的第一个元素或 None;对比:position() 返回元素的 index
fn find<P>(&mut self, predicate: P) -> Option<Self::Item> where Self: Sized, P: FnMut(&Self::Item) -> bool { ... }
let a = [1, 2, 3];
let mut iter = a.iter();
assert_eq!(iter.find(|&&x| x == 2), Some(&2));
// we can still use `iter`, as there are more elements.
assert_eq!(iter.next(), Some(&3));
// 对迭代器元素执行 f,返回第一个 f 结尾为 Some(B) 的 Option<B>,等效于 iter.filter_map(f).next().
fn find_map<B, F>(&mut self, f: F) -> Option<B> where Self: Sized, F: FnMut(Self::Item) -> Option<B> { ... }
let a = ["lol", "NaN", "2", "5"];
let first_number = a.iter().find_map(|s| s.parse().ok());
assert_eq!(first_number, Some(2));
fn try_find<F, R>( &mut self, f: F ) -> >::TryType where Self: Sized, F: FnMut(&Self::Item) -> R, R: Try<Output = bool>, <R as Try>::Residual: Residual<Option<Self::Item>> { ... }
// 查找满足 predicate 的元素,返回它的 index。对比:find() 返回元素本身。
fn position<P>(&mut self, predicate: P) -> Option<usize> where Self: Sized, P: FnMut(Self::Item) -> bool { ... }
let a = [1, 2, 3];
assert_eq!(a.iter().position(|&x| x == 2), Some(1));
assert_eq!(a.iter().position(|&x| x == 5), None);
fn rposition<P>(&mut self, predicate: P) -> Option<usize> where P: FnMut(Self::Item) -> bool, Self: Sized + ExactSizeIterator + DoubleEndedIterator
fn max(self) -> Option<Self::Item> where Self: Sized, Self::Item: Ord
fn min(self) -> Option<Self::Item> where Self: Sized, Self::Item: Ord
// 根据 f 闭包返回的结果来找最大值
fn max_by_key<B, F>(self, f: F) -> Option<Self::Item> where B: Ord, Self: Sized, F: FnMut(&Self::Item) -> B
let a = [-3_i32, 0, 1, 5, -10];
assert_eq!(*a.iter().max_by_key(|x| x.abs()).unwrap(), -10);
// 根据 compare 函数的返回值来找最大值
fn max_by<F>(self, compare: F) -> Option<Self::Item> where Self: Sized, F: FnMut(&Self::Item, &Self::Item) -> Ordering { ... }
let a = [-3_i32, 0, 1, 5, -10];
assert_eq!(*a.iter().max_by(|x, y| x.cmp(y)).unwrap(), 5);
fn min_by_key<B, F>(self, f: F) -> Option<Self::Item> where B: Ord, Self: Sized, F: FnMut(&Self::Item) -> B { ... }
fn min_by<F>(self, compare: F) -> Option<Self::Item> where Self: Sized, F: FnMut(&Self::Item, &Self::Item) -> Ordering { ... }
// 返回迭代器的反向迭代器
fn rev(self) -> Rev<Self> where Self: Sized + DoubleEndedIterator { ... }
let a = [1, 2, 3];
let mut iter = a.iter().rev();
assert_eq!(iter.next(), Some(&3));
assert_eq!(iter.next(), Some(&2));
assert_eq!(iter.next(), Some(&1));
assert_eq!(iter.next(), None);
// 迭代器迭代返回 (A, B), 然后返回两个分别是 A 、B 聚合后的对象。A,B
fn unzip<A, B, FromA, FromB>(self) -> (FromA, FromB) where FromA: Default + Extend<A>, FromB: Default + Extend<B>, Self: Sized + Iterator<Item = (A, B)>
let a = [(1, 2), (3, 4), (5, 6)];
let (left, right): (Vec<_>, Vec<_>) = a.iter().cloned().unzip();
assert_eq!(left, [1, 3, 5]);
assert_eq!(right, [2, 4, 6]);
// you can also unzip multiple nested tuples at once
let a = [(1, (2, 3)), (4, (5, 6))];
let (x, (y, z)): (Vec<_>, (Vec<_>, Vec<_>)) = a.iter().cloned().unzip();
assert_eq!(x, [1, 4]);
assert_eq!(y, [2, 5]);
assert_eq!(z, [3, 6]);
// 使用元素的 Copy 对象来返回一个新的迭代器,特别适合从 &T 返回 T
fn copied<'a, T>(self) -> Copied<Self> where T: 'a + Copy, Self: Sized + Iterator<Item = &'a T> { ... }
let a = [1, 2, 3];
let v_copied: Vec<_> = a.iter().copied().collect();
// copied is the same as .map(|&x| x)
let v_map: Vec<_> = a.iter().map(|&x| x).collect();
assert_eq!(v_copied, vec![1, 2, 3]);
assert_eq!(v_map, vec![1, 2, 3]);
// 使用元素的 Clone 对象来返回一个新的迭代器,适合 从 &T 返回 T
fn cloned<'a, T>(self) -> Cloned<Self> where T: 'a + Clone, Self: Sized + Iterator<Item = &'a T>
let a = [1, 2, 3];
let v_cloned: Vec<_> = a.iter().cloned().collect();
// cloned is the same as .map(|&x| x), for integers
let v_map: Vec<_> = a.iter().map(|&x| x).collect();
assert_eq!(v_cloned, vec![1, 2, 3]);
assert_eq!(v_map, vec![1, 2, 3]);
// 循环返回迭代器的元素
fn cycle(self) -> Cycle<Self> where Self: Sized + Clone { ... }
let a = [1, 2, 3];
let mut it = a.iter().cycle();
assert_eq!(it.next(), Some(&1));
assert_eq!(it.next(), Some(&2));
assert_eq!(it.next(), Some(&3));
assert_eq!(it.next(), Some(&1));
assert_eq!(it.next(), Some(&2));
assert_eq!(it.next(), Some(&3));
assert_eq!(it.next(), Some(&1));
// 返回一个迭代器,每次迭代返回 N 个元素的数组。
fn array_chunks<const N: usize>(self) -> ArrayChunks<Self, N> where Self: Sized { ... }
// 返回元素的 sum,可能会 panic。Option/Result 也实现了 Sum
fn sum<S>(self) -> S where Self: Sized, S: Sum<Self::Item> { ... }
let a = [1, 2, 3];
let sum: i32 = a.iter().sum();
assert_eq!(sum, 6);
// 返回元素的乘积
fn product<P>(self) -> P where Self: Sized, P: Product<Self::Item> { ... }
fn factorial(n: u32) -> u32 {
(1..=n).product()
}
assert_eq!(factorial(0), 1);
assert_eq!(factorial(1), 1);
assert_eq!(factorial(5), 120);
// 比较两个迭代的各元素,元素必须实现 Ord trait(所以不能比较 float 值)
fn cmp<I>(self, other: I) -> Ordering where I: IntoIterator<Item = Self::Item>, Self::Item: Ord, Self: Sized { ... }
use std::cmp::Ordering;
assert_eq!([1].iter().cmp([1].iter()), Ordering::Equal);
assert_eq!([1].iter().cmp([1, 2].iter()), Ordering::Less);
assert_eq!([1, 2].iter().cmp([1].iter()), Ordering::Greater);
// 使用指定的 cmp 闭包函数来比较两个迭代器的元素
fn cmp_by<I, F>(self, other: I, cmp: F) -> Ordering where Self: Sized, I: IntoIterator, F: FnMut(Self::Item, <I as IntoIterator>::Item) -> Ordering { ... }
#![feature(iter_order_by)]
use std::cmp::Ordering;
let xs = [1, 2, 3, 4];
let ys = [1, 4, 9, 16];
assert_eq!(xs.iter().cmp_by(&ys, |&x, &y| x.cmp(&y)), Ordering::Less);
assert_eq!(xs.iter().cmp_by(&ys, |&x, &y| (x * x).cmp(&y)), Ordering::Equal);
assert_eq!(xs.iter().cmp_by(&ys, |&x, &y| (2 * x).cmp(&y)), Ordering::Greater);
// 与 cmp 相比,partial_cmp可以比较实现 PartialOrd trait 的值,如 float64
fn partial_cmp<I>(self, other: I) -> Option<Ordering> where I: IntoIterator, Self::Item: PartialOrd<<I as IntoIterator>::Item>, Self: Sized { ... }
fn partial_cmp_by<I, F>(self, other: I, partial_cmp: F) -> Option<Ordering> where Self: Sized, I: IntoIterator, F: FnMut(Self::Item, <I as IntoIterator>::Item) -> Option<Ordering> { ... }
// 比较两个迭代器的元素,返回 ture/false
fn eq<I>(self, other: I) -> bool where I: IntoIterator, Self::Item: PartialEq<<I as IntoIterator>::Item>, Self: Sized { ... }
fn eq_by<I, F>(self, other: I, eq: F) -> bool where Self: Sized, I: IntoIterator, F: FnMut(Self::Item, <I as IntoIterator>::Item) -> bool { ... }
fn ne<I>(self, other: I) -> bool where I: IntoIterator, Self::Item: PartialEq<<I as IntoIterator>::Item>, Self: Sized { ... }
fn lt<I>(self, other: I) -> bool where I: IntoIterator, Self::Item: PartialOrd<<I as IntoIterator>::Item>, Self: Sized { ... }
fn le<I>(self, other: I) -> bool where I: IntoIterator, Self::Item: PartialOrd<<I as IntoIterator>::Item>, Self: Sized { ... }
fn gt<I>(self, other: I) -> bool where I: IntoIterator, Self::Item: PartialOrd<<I as IntoIterator>::Item>, Self: Sized { ... }
fn ge<I>(self, other: I) -> bool where I: IntoIterator, Self::Item: PartialOrd<<I as IntoIterator>::Item>, Self: Sized { ... }
// 判断迭代器的元素是否已排序
fn is_sorted(self) -> bool where Self: Sized, Self::Item: PartialOrd { ... }
fn is_sorted_by<F>(self, compare: F) -> bool where Self: Sized, F: FnMut(&Self::Item, &Self::Item) -> bool { ... }
fn is_sorted_by_key<F, K>(self, f: F) -> bool where Self: Sized, F: FnMut(Self::Item) -> K, K: PartialOrd { ... }
22.2 std::iter::FromIterator #
从输入的迭代器 iter 创建一个 Self 对象(取决于实现该 Fromiterator 的对象类型), 输入的 iter 是 IntoIterator 类型,所以会转义 iter 对象的所有权。
迭代器的泛型方法 collect<T>() 会自动调用 T::from_iter(self) 方法来生成 T 对象。
// file:///Users/zhangjun/.rustup/toolchains/nightly-x86_64-apple-darwin/share/doc/rust/html/std/iter/trait.FromIterator.html
pub trait FromIterator<A>: Sized {
// Required method
fn from_iter<T>(iter: T) -> Self
where T: IntoIterator<Item = A>;
}
// 示例
let five_fives = std::iter::repeat(5).take(5);
let v = Vec::from_iter(five_fives);
assert_eq!(v, vec![5, 5, 5, 5, 5]);
// collect() 函数默认自动使用 FromIterator<A> trait
let five_fives = std::iter::repeat(5).take(5);
let v: Vec<i32> = five_fives.collect(); // 等效于:Vec<i32>::from_iter(five_fives)
assert_eq!(v, vec![5, 5, 5, 5, 5]);
实现 FromIterator<T> 的类型:
- impl<K, V> FromIterator<(K, V)> for BTreeMap<K, V>
- impl<T> FromIterator<T> for BTreeSet<T> where T: Ord,
- impl<T> FromIterator<T> for Vec<T>
// file:///Users/zhangjun/.rustup/toolchains/nightly-x86_64-apple-darwin/share/doc/rust/html/std/iter/trait.FromIterator.html#implementors
impl FromIterator<char> for String
impl FromIterator<()> for ()
use std::io::*;
let data = vec![1, 2, 3, 4, 5];
let res: Result<()> = data.iter()
.map(|x| writeln!(stdout(), "{x}"))
.collect();
assert!(res.is_ok());
impl FromIterator<Box<str>> for String
impl FromIterator<OsString> for OsString
impl FromIterator<String> for String
impl<'a> FromIterator<&'a char> for String
impl<'a> FromIterator<&'a str> for String
impl<'a> FromIterator<&'a OsStr> for OsString
impl<'a> FromIterator<Cow<'a, str>> for String
impl<'a> FromIterator<Cow<'a, OsStr>> for OsString
impl<'a> FromIterator<char> for Cow<'a, str>
impl<'a> FromIterator<String> for Cow<'a, str>
impl<'a, 'b> FromIterator<&'b str> for Cow<'a, str>
impl<'a, T> FromIterator<T> for Cow<'a, [T]> where T: Clone,
impl<A, E, V> FromIterator<Result<A, E>> for Result<V, E> where V: FromIterator<A>,
impl<A, V> FromIterator<Option<A>> for Option<V> where V: FromIterator<A>,
impl<I> FromIterator<I> for Box<[I]>
impl<K, V> FromIterator<(K, V)> for BTreeMap<K, V> where K: Ord,
impl<K, V, S> FromIterator<(K, V)> for HashMap<K, V, S>
where K: Eq + Hash, S: BuildHasher + Default,
impl<P: AsRef<Path>> FromIterator<P> for PathBuf
impl<T> FromIterator<T> for BTreeSet<T> where T: Ord,
impl<T> FromIterator<T> for BinaryHeap<T>
where
T: Ord,
impl<T> FromIterator<T> for LinkedList<T>
impl<T> FromIterator<T> for VecDeque<T>
impl<T> FromIterator<T> for Rc<[T]>
impl<T> FromIterator<T> for Arc<[T]>
impl<T> FromIterator<T> for Vec<T>
impl<T, S> FromIterator<T> for HashSet<T, S>
where
T: Eq + Hash,
S: BuildHasher + Default,
impl FromIterator<TokenStream> for TokenStream
impl FromIterator<TokenTree> for TokenStream
23 package/crate/module #
package 是 cargo 项目的定义,一般包含一个 crate,而一个 crate 只能是 binary、library、 procedure_macro 类型:
- 只能包含 0-1 个 library crate, 可以包含任意数量的 binary crate, 但至少必须包含一个 lib 或 bin crate;
- 创建 lib crate:
cargo new xx - 创建 bin crate:
cargo new --bin xx
crate 是 Rust 的编译、发布、版本化、加载的单元: rustc some_file.rs 中的 some_file.rs 是 crate file.
crate root 是 Rust 编译器开始编译的地方, 是 crate 的根 module;
- src/main.rs: binary crate 的 crate root,crate 名称与 package 名称相同;
- src/lib.rs: library crate 的 crate root(一个 package 包含 0-1 个 library crate),crate 名称与 package 名相同;
- use 或 pub 使用
crate标识符来引用 root crate module 中的 item,如 use crate::xxx 就表示引用 crate root 下的 xxx item;
# A binary
cargo new foo
# A library
cargo new --lib bar
.
├── bar
│ ├── Cargo.toml
│ └── src
│ └── lib.rs
└── foo
├── Cargo.toml
└── src
└── main.rs
# bin 目录下的文件名分别为单独的 binary, 可以通过 cargo 的 --bin my_other_bin 来指定
foo
├── Cargo.toml
└── src
├── main.rs
└── bin
└── my_other_bin.rs
foo
├── Cargo.toml
├── src
│ └── main.rs
│ └── lib.rs
└── tests # 集成测试
├── my_test.rs
└── my_other_test.rs
crate file 可以使用 mod 声明来引用其它 mod 中 item 对象, 该 mod 可以是单独的文件或当前文件中定义, mod 可以嵌套。
- src/<module_name>.rs // module 单文件
- src/<module_name>/mod.rs // module 目录,该目录下必须有一个 mod.rs 文件。
父 module 中的元素, 不管是否 public, 都可以在自身和子 module 中使用, 但是不能在父 module (递归向上) 和其它非子 module 中使用。
在 Rust 2015 以后版本, 基本上不需要再使用 extern crate xx 了, 因为 rustc 会从 Cargo.toml 中获得外部依赖的 crate。
- rustc 自带的 crate 如 alloc/test/proc_macro 只能 extern crate 来声明:
extern crate alloc;
use alloc::rc::Rc;
crate 名称是不允许有短横杠的,但是 Cargo package 名称可能包含短横杠,所以 Cargo.toml 中指定的 package name 可以包含短横杠,但是在使用 extern crate 或 use 来引用 package 中的 crate 时,需要将短横杠替换为下划线:
// Importing the Cargo package hello-world
extern crate hello_world; // hyphen replaced with an underscore
extern crate foo as _ // 表示不使用 foo crate 中的 item,只做链接
module 引入了一级 namespace, 其中的 item 需要使用 module::item 来访问.
- module 是在一个 crate 内部,用于将代码进行分组;
- 增加可读性,易于复用;
- 控制项目(item)的可见性。
- module 可以嵌套,可以包含其他 item,如 struct/enum/常量/trait/函数等定义;
module 中 item 的可见性:
- pub fn
- pub (in path::to::module): pub(in crate::my_mod), 对指定的 crate 开放;
- pub (self):: 只对当前 module 开放; 等效于不加 pub;
- pub (super):: 只对父 module 开放;
- pub(crate):: 只对当前 crate 开放;
// A module named `my_mod`
mod my_mod {
// Items in modules default to private visibility.
fn private_function() {
println!("called `my_mod::private_function()`");
}
// Use the `pub` modifier to override default visibility.
pub fn function() {
println!("called `my_mod::function()`");
}
// Items can access other items in the same module, even when private.
pub fn indirect_access() {
print!("called `my_mod::indirect_access()`, that\n> ");
private_function();
}
// Modules can also be nested
pub mod nested {
pub fn function() {
println!("called `my_mod::nested::function()`");
}
#[allow(dead_code)]
fn private_function() {
println!("called `my_mod::nested::private_function()`");
}
// Functions declared using `pub(in path)` syntax are only visible within the given
// path. `path` must be a parent or ancestor module
pub(in crate::my_mod) fn public_function_in_my_mod() {
print!("called `my_mod::nested::public_function_in_my_mod()`, that\n> ");
public_function_in_nested();
}
// Functions declared using `pub(self)` syntax are only visible within the current module,
// which is the same as leaving them private
pub(self) fn public_function_in_nested() {
println!("called `my_mod::nested::public_function_in_nested()`");
}
// Functions declared using `pub(super)` syntax are only visible within
// the parent module
pub(super) fn public_function_in_super_mod() {
println!("called `my_mod::nested::public_function_in_super_mod()`");
}
}
pub fn call_public_function_in_my_mod() {
print!("called `my_mod::call_public_function_in_my_mod()`, that\n> ");
nested::public_function_in_my_mod();
print!("> ");
nested::public_function_in_super_mod();
}
// pub(crate) makes functions visible only within the current crate
pub(crate) fn public_function_in_crate() {
println!("called `my_mod::public_function_in_crate()`");
}
// Nested modules follow the same rules for visibility
mod private_nested {
#[allow(dead_code)]
pub fn function() {
println!("called `my_mod::private_nested::function()`");
}
// Private parent items will still restrict the visibility of a child item,
// even if it is declared as visible within a bigger scope.
#[allow(dead_code)]
pub(crate) fn restricted_function() {
println!("called `my_mod::private_nested::restricted_function()`");
}
}
}
fn function() {
println!("called `function()`");
}
fn main() {
// Modules allow disambiguation between items that have the same name.
function();
my_mod::function();
// Public items, including those inside nested modules, can be
// accessed from outside the parent module.
my_mod::indirect_access();
my_mod::nested::function();
my_mod::call_public_function_in_my_mod();
// pub(crate) items can be called from anywhere in the same crate
my_mod::public_function_in_crate();
}
module 可以通过 #[path] attribute 来指定它的文件路径:
- module 也可以使用 #[cfg_attr] 来指定在 match 条件的情况下,为 module 添加一些 attr,比如上面的 path attr:
#[path = "thread_files"]
mod thread {
// Load the `local_data` module from `thread_files/tls.rs` relative to this source
// file's directory.
#[path = "tls.rs"]
mod local_data;
}
mod inline {
#[path = "other.rs"]
mod inner;
}
// 在 target_os = "linux" 的情况下,添加 #[path = "linux.rs"] 属性,表示西面 mod os 的文件是 linux.rs;
#[cfg_attr(target_os = "linux", path = "linux.rs")]
#[cfg_attr(target_os = "linux", cfg_attr(feature = "multithreaded", some_other_attribute))]
#[cfg_attr(windows, path = "windows.rs")]
mod os;
#[cfg_attr(feature = "magic", sparkles, crackles)]
fn bewitched() {}
// 等效于:在 feature = "magic" 的情况下,添加下面两个 attr
#[sparkles]
#[crackles]
fn bewitched() {}
可以使用 self 或 super 来访问当前 module 或父 module 的 item:
fn function() {
println!("called `function()`");
}
mod cool {
pub fn function() {
println!("called `cool::function()`");
}
}
mod my {
fn function() {
println!("called `my::function()`");
}
mod cool {
pub fn function() {
println!("called `my:🆒:function()`");
}
}
pub fn indirect_call() {
// Let's access all the functions named `function` from this scope!
print!("called `my::indirect_call()`, that\n> ");
// The `self` keyword refers to the current module scope - in this case `my`.
// Calling `self::function()` and calling `function()` directly both give the same
// result, because they refer to the same function.
self::function(); // self 表示当前 module
function();
self::cool::function(); // 当前 module 的子 module cool
super::function();
// This will bind to the `cool::function` in the *crate* scope.
// In this case the crate scope is the outermost scope.
{
use crate::cool::function as root_function; // create 表示当前 module 所在的 create
root_function();
}
}
}
fn main() {
my::indirect_call();
}
路径 path:为了在 Rust 模块中找到某个 item,需要使用路径,路径使用 :: 分割,路径有两种形式:
- 绝对路径:从 crate root 开始,使用 use crate::module::item;
- crate 表示本 crate 的根 module,比如 lib.rs 或 bin.rs 中的 item;
- 相对路径:从当前 module 开始,使用 self/super 或当前 module 的标识符;
use 语句: 将某个标识符和一个 full path 绑定, 后续可以直接使用标识符:
- use xx::yy 中的 xx 是相对于当前 module 的, 可以是子 module 或 item, 如果都不存在则 xx 是 crate 名称;
- use self::item 导入当前 module 的 item;
- yse super::item 导入父 module 的 item;
- use crate::module::item 中的 crate 表示当前 module 所在的 crate;
- 开头表示使用外部 crate image;
- use crate::module_1::module_2::*; 引入 module_2 下的所有 item;
- use super::item as sitem; 使用 as 指定的标识符 sitem 来引用 super::item;
use crate::deeply::nested::{
my_first_function,
my_second_function,
AndATraitType
};
fn main() {
my_first_function();
}
// 使用 use..as 对绑定重命名
// Bind the `deeply::nested::function` path to `other_function`.
use deeply::nested::function as other_function;
fn function() {
println!("called `function()`");
}
mod deeply {
pub mod nested {
pub fn function() {
println!("called `deeply::nested::function()`");
}
}
}
fn main() {
// Easier access to `deeply::nested::function`
other_function();
println!("Entering block");
{
// This is equivalent to `use deeply::nested::function as function`.
// This `function()` will shadow the outer one.
use crate::deeply::nested::function;
// `use` bindings have a local scope. In this case, the
// shadowing of `function()` is only in this block.
function();
println!("Leaving block");
}
function();
}
// 使用 pub use 将绑定在当前 create module 重新 export
pub use deeply::nested::function as other_function;
pub use 可以将当前导入的 item 在本 moudule 中重新导出, 这样其他 crate 导入该 module 时也可以使用这些 item.
- 常见的情况是 module 开发者将嵌套很深的 item 通过 pub use 在 crate root module 导出,这样使用者就不需要使用很长、很深的 use path 到导入该 item;
- pub use 导出的 item 在 module 的 cargo doc 中的 “Reexports” 部分展示;
缺省情况下 Rust 标准库被自动导入到 crate root module,可以使用 std 来引用它中的 item。同时隐式的为std 使用 macro_use attribute 来导入 std 库中 macro_export 的所有宏。同时 core 也被导入到 create root module。
通过在 crate level 添加 #![no_std] attr 可以避免上面隐式自动导入 std 和它的 macro,而只会导入 core create 以及他的 macro。使用 #![no_std] attr 只是关闭了自动导入 std 和它的 macro,代码还是可以使用 extern crate std; 来显示导入和链接的。
注:可以使用 https://github.com/dtolnay/cargo-expand 来展开 macro 代码:
- 也可以使用
cargo build --verbose来看到展开的代码:
// cat src/main.rs
#[derive(Debug)]
struct S;
fn main() {
println!("{:?}", S);
}
// 展开:$ cargo expand
// 可见:编译器自动导入了 std crate 和 std prelude
#![feature(prelude_import)]
#[prelude_import]
use std::prelude::v1::*;
#[macro_use]
extern crate std;
struct S;
#[automatically_derived]
#[allow(unused_qualifications)]
impl ::core::fmt::Debug for S {
fn fmt(&self, f: &mut ::core::fmt::Formatter) -> ::core::fmt::Result {
match *self {
S => {
let mut debug_trait_builder = f.debug_tuple("S");
debug_trait_builder.finish()
}
}
}
}
fn main() {
{
::std::io::_print(::core::fmt::Arguments::new_v1(
&["", "\n"],
&match (&S,) {
(arg0,) => [::core::fmt::ArgumentV1::new(arg0, ::core::fmt::Debug::fmt)],
},
));
};
}
24 async #
Future trait:
- poll 方法的 self 类型是 Pin<&mut Self>,表示一旦开始 pool 时 Self 的地址必须是固定的,不能再被转移,这是为了确保 Future 对象内部保存的栈地址继续有效;
- cx 参数的 Context 封装了 waker,当 poll Pending 时 Future 的实现可以保存该 waker(一般是在一个辅助线程中),然后当条件满足时调用 waker 来唤醒 async executor 来重新 poll 自己。
trait Future {
type Output;
// For now, read `Pin<&mut Self>` as `&mut Self`.
fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output>;
}
enum Poll<T> {
Ready(T),
Pending,
}
同步函数或方法也可以返回 impl Future,执行该函数时只是返回一个 Future 对象:
- impl Trait 只能用于
普通函数或方法的返回值,不能用于 trait 中关联函数或方法的返回值。
fn read_to_string(&mut self, buf: &mut String) -> impl Future<Output = Result<usize>>;
为了方便实现异步函数,Rust 提供了 async fn:
- async fn 内部可以使用 .await 表达式,但是普通函数不行。
- async fn 的返回值被封装为 Future。
- 执行该函数只会返回一个 Future,需要使用 await 表达式来 poll 结果。
- async 不能用于 trait 中的函数,需要使用
async_trate crate来实现。
async fn example(x: &str) -> usize {
x.len()
}
// 等效于
fn example<'a>(x: &'a str) -> impl Future<Output = usize> + 'a {
async move { x.len() }
}
use async_std::io::prelude::*;
use async_std::net;
async fn cheapo_request(host: &str, port: u16, path: &str) -> std::io::Result<String>
{
let mut socket = net::TcpStream::connect((host, port)).await?;
let request = format!("GET {} HTTP/1.1\r\nHost: {}\r\n\r\n", path, host);
socket.write_all(request.as_bytes()).await?;
socket.shutdown(net::Shutdown::Write)?;
let mut response = String::new();
socket.read_to_string(&mut response).await?;
Ok(response)
}
// 调用该函数时,返回一个 Future
let response = cheapo_request(host, port, path);
async fn 内部可以通过 await poll 其他异步函数,所以 async executor 在执行 async fn 的过程中,可能会多次暂停,暂停的位置是各 .await 表达式(这些 .await 位置也是异步运行时的 yield point ),每次暂停都会返回一个新的 Future 对象,它封装了暂停位置依赖的上下文对象:栈变量、函数参数等,后续可能被调度到其他线程上运行。所以, async fn 需要实现 Send+'static , 也就是函数内跨 .await 的对象都需要是 Send +
‘static 的。
Rust 支持 trait 中定义 async fn,但是一旦 trait 包含 async fn, 就不能使用 trait object ,解决办法是使用基于宏的 async-trait crate 解决方法:在 trait 和该 trait 的实现上添加 #[async_trait] 属性宏即可。
pub trait Trait {
async fn f(&self);
}
// 编译报错:
pub fn make() -> Box<dyn Trait> {
unimplemented!()
}
// async_trait 提供了 attr macro 来解决这个问题
use async_trait::async_trait;
#[async_trait]
trait Advertisement {
async fn run(&self);
}
struct Modal;
#[async_trait]
impl Advertisement for Modal {
// async 方法/函数中可以使用 await 表达式
async fn run(&self) {
self.render_fullscreen().await;
for _ in 0..4u16 {
remind_user_to_join_mailing_list().await;
}
self.hide_for_now().await;
}
}
// 后续可以使用:Vec<Box<dyn Advertisement + Sync>> or &[&dyn Advertisement],
Rust 还提供返回 Future 的 async block,可以在 async block 中使用 .await,也可以 .await 它的返回值:
- 在 async block 中使用 ? 来传播错误或 return 来返回值时,都是 async block 的返回,而不是它所在的函数返回。
- async block 可以和闭包一样捕获环境中的对象(借用或 move),也可以指定
async move来获得对象的所有权,这时 async block 返回的 Future 具有 ‘static lifetime。
use async_std::net;
use async_std::task;
// serve_one 是一个 Future<Output=Result>,只有当 .await 或 poll 它时才会执行 async block 中的代码。
let serve_one = async {
let listener = net::TcpListener::bind("localhost:8087").await?; // ? 是 async block 返回,结果是 Err.
let (mut socket, _addr) = listener.accept().await?;
// Talk to client on `socket`.
};
pub async fn many_requests(requests: Vec<(String, u16, String)>) -> Vec<std::io::Result<String>>
{
let mut handles = vec![];
for (host, port, path) in requests {
handles.push(
task::spawn_local(
// 使用 async move 来获取 host、path 的所有权。
async move {
cheapo_request(&host, port, &path).await
}
));
}
//...
}
aysnc block 没有指定返回值类型的机制,在编译时可能出错,解决办法:为 Ok 指定它所属的 Enum Result 类型:
let input = async_std::io::stdin();
// future 是 Future<Output=Result>
let future = async {
let mut line = String::new();
// This returns `std::io::Result<usize>`.
input.read_line(&mut line).await?; // ? 是 async block 返回,结果是 std::io::Result<usize>.
println!("Read line: {}", line);
// Ok(()) // 错误
Ok::<(), std::io::Error>(()) // 正确,指定 Ok 所属的 Result 类型
// 或者
std::result::Result::<(), std::io::Error>::Ok;
};
由于 async block 返回一个 Future,故可以使用它为同步函数返回 impl Future 的对象:
use std::io;
use std::future::Future;
fn cheapo_request(host: &str, port: u16, path: &str) -> impl Future<Output = io::Result<String>> + 'static
{
let host = host.to_string();
let path = path.to_string();
async move {
// 捕获了 host、path 的所有权
//... use &*host, port, and path ...
} // 所有权转移到返回的 Future 对象中
}
异步运行时将 async fn 或 async block 作为一个调度和执行的单元,称为异步任务 async task :
- block_on(): 当前线程来运行异步任务, 是同步代码和异步代码的分界点;
- task::spawn_local(): 在 block_on() 所在的线程空闲时运行异步任务;
- task::spawn(): 在一个线程池中立即运行异步任务;
- task::spawn_blocking():立即创建一个线程来运行指定的
同步函数。
同步代码和异步代码的结合点是 block_on(): block_on() 是一个 同步函数 ,所以不能在 async fn 中调用
block_on() 而需要调用 .await,它在当前线程上 poll 传入的 Future 对象 ,直到 Ready 返回值,如果是
Pending 且没有其他 aysnc task 可以 poll,则 block_on() 会 sleep。
fn main() -> std::io::Result<()> {
use async_std::task;
let response = task::block_on(cheapo_request("example.com", 80, "/"))?;
println!("{}", response);
Ok(())
}
block_on() 在当前线程 poll 传入的 Future 对象,为了能在该线程中同时 poll 其它 Future,可以使用 spawn_local():
- 可以多次调用 spawn_local(),它将传入的 Future 添加到 block_on() 线程所处理的 task pool 中,当 block_on() 处理某个 task pending 时,会从该 pool 中获取下一个 Future task 进行 poll;
- spawn_local() 返回 JoinHandle 类型,它实现了 Future trait,可以进行 await 来获得最终值;
- 如果一个 task 执行时间很长,会导致 block_on 没有机会执行其他 task,从而引起性能问题;
//!
//! ```cargo
//! [dependencies]
//! async-std = { version = "1", features = ["unstable"] }
//! ```
fn main() {
}
pub async fn many_requests(requests: Vec<(String, u16, String)>) -> Vec<std::io::Result<String>>
{
use async_std::task;
let mut handles = vec![];
for (host, port, path) in requests {
handles.push(task::spawn_local(cheapo_request(&host, port, &path))); // 这些 request 被单线程并发执行
}
let mut results = vec![];
for handle in handles {
results.push(handle.await); // 串行等待 handle 返回最终值
}
results
}
spawn_local() 要求传入的 Future 是 ‘static 的(因为是单线程执行,所以不要求实现 Send+Sync),这是由于该 Future 的 执行时机是不确定的 ,如果不.await 它返回的 handle,则有可能 many_requests() 函数返回了,但是 Future 还没有被执行,从而导致引用失效。
解决办法:
- 传入一个 async 辅助函数,它拥有对应的参数值,这样该函数就实现了 ‘static;
- 使用 async move {} 来捕获对象,这样该 block 返回的 Future 也实现了 ‘static;
async fn cheapo_owning_request(host: String, port: u16, path: String) -> std::io::Result<String> {
cheapo_request(&host, port, &path).await
}
for (host, port, path) in requests {
handles.push(task::spawn_local(cheapo_owning_request(host, port, path)));
}
// 在单线程中并发发起多个 request
let requests = vec![
("example.com".to_string(), 80, "/".to_string()),
("www.red-bean.com".to_string(), 80, "/".to_string()),
("en.wikipedia.org".to_string(), 80, "/".to_string()),
];
let results = async_std::task::block_on(many_requests(requests));
for result in results {
match result {
Ok(response) => println!("{}", response),
Err(err) => eprintln!("error: {}", err),
}
}
spawn() 是在一个专门 poll Future 的线程池(tokio 称为 worker thread 或 core thread)中并发执行 async task:
- spawn() 和 spawn_local() 一样,也返回 JoinHandler,JoinHandler 实现了 Future,可以 .await 获得结果。但是它不依赖调用 block_on() 来 poll,而是执行候该函数后立即开始被 poll;
- 由于传给 spawn() 的 Future 可能被线程池中任意线程执行,而且在暂停恢复候可能会在另一个线程中运行,所以不能使用线程本地存储变量(解决办法是使用 task_local! 宏),同时 Future 捕获的对象必须具有
Future + Send + 'static语义,这样这些变量才能安全的 move 到其他线程执行。(类似于 std:🧵:spawn() 对闭包的要求)。
use async_std::task;
let mut handles = vec![];
for (host, port, path) in requests {
handles.push(task::spawn(
async move {
cheapo_request(&host, port, &path).await
}
));
}
// 错误:reluctant() 返回的 Future 没有实现 Send。
use async_std::task; use std::rc::Rc;
async fn reluctant() -> String {
let string = Rc::new("ref-counted string".to_string());
some_asynchronous_thing().await; // Rc 跨 await
format!("Your splendid string: {}", string)
}
task::spawn(reluctant());
// 解决办法:将不支持 Send 的变量隔离在单独的 await 所在的 block。
async fn reluctant() -> String {
let return_value = {
let string = Rc::new("ref-counted string".to_string());
format!("Your splendid string: {}", string)
};
some_asynchronous_thing().await;
return_value
}
另一个常见的错误是 Box<dyn std::error::Error> 对象不支持 Send,比如 some_fallible_thing() 的返回值 Result 有效性是整个 match 表达式,所以跨越了 Ok 分支的 await, 这时 Result 如果不是 Send 就报错:
// Not recommended!
type GenericError = Box<dyn std::error::Error>;
type GenericResult<T> = Result<T, GenericError>;
fn some_fallible_thing() -> GenericResult<i32> {
//...
}
// This function's future is not `Send`...
async fn unfortunate() {
// ... because this call's value ...
match some_fallible_thing() {
Err(error) => {
report_error(error);
}
Ok(output) => {
// ... is alive across this await ...
use_output(output).await;
}
} }
// ... and thus this `spawn` is an error.
async_std::task::spawn(unfortunate());
解决办法是:重新定义 Error, 添加 Send Bound,‘static 是 Box<dyn Trait> 默认的 lifetime,可以不添加。
type GenericError = Box<dyn std::error::Error + Send + Sync + 'static>;
type GenericResult<T> = Result<T, GenericError>;
spawn_blocking() 是异步运行时用来解决可能会阻塞或长时间运行(CPU 消耗性)的任务问题,它的参数是一个 =
同步闭包函数= ,它会立即创建一个 新的线程来执行 (tokio 中称为 blocking thread,该线程也组成线程池,在过期前可以被重复利用),同时返回一个 Future,可以 await 结果。
async fn verify_password(password: &str, hash: &str, key: &str) -> Result<bool, argonautica::Error>
{
// Make copies of the arguments, so the closure can be 'static.
let password = password.to_string();
let hash = hash.to_string();
let key = key.to_string();
async_std::task::spawn_blocking(move || {
argonautica::Verifier::default()
.with_hash(hash)
.with_password(password)
.with_secret_key(key)
.verify()
}).await }
// 对于长时间运行的任务,可以主动 yield
while computation_not_done() {
// ... do one medium-sized step of computation ...
async_std::task::yield_now().await;
}
异步 Stream:
use async_chat::FromServer;
async fn handle_replies(from_server: net::TcpStream) -> ChatResult<()> {
let buffered = io::BufReader::new(from_server);
// 返回一个 Stream
let mut reply_stream = utils::receive_as_json(buffered);
// 迭代 Stream,await poll 迭代的元素
while let Some(reply) = reply_stream.next().await {
match reply? {
FromServer::Message { group_name, message } => {
println!("message posted to {}: {}", group_name,
message);
}
FromServer::Error(message) => {
println!("error from server: {}", message);
} }
}
Ok(()) }
async_std 为 Future 扩展的 .race() 方法可以同时运行两个 Future,当任意一个 Ready 时返回:
use async_std::task;
fn main() -> ChatResult<()> {
let address = std::env::args().nth(1).expect("Usage: client ADDRESS:PORT");
task::block_on(async {
let socket = net::TcpStream::connect(address).await?;
socket.set_nodelay(true)?;
let to_server = send_commands(socket.clone());
let from_server = handle_replies(socket);
from_server.race(to_server).await?;
Ok(())
})
}
// 而不是这样:会先等待 to_server 完成,再等待 form_server. 而不是等待任意一个完成
let to_server = task::spawn(send_commands(socket.clone()));
let from_server = task::spawn(handle_replies(socket));
to_server.await?;
from_server.await?;
每个 await 都是 Rust 执行异步 poll 的时间点(yield point),默认情况下 task 可以被 execeutor 调度到其它 thread 中执行,所以 async fn 中涉及跨 await 的对象,都需要是能 Send 的。await 表达式的执行效果等效为:
match operand.into_future() {
mut pinned => loop {
let mut pin = unsafe { Pin::new_unchecked(&mut pinned) };
match Pin::future::poll(Pin::borrow(&mut pin), &mut current_context) {
Poll::Ready(r) => break r,
Poll::Pending => yield Poll::Pending,
}
}
}
如果在 async 中使用跨 await 的 Mutex,则应该使用异步感知的 Mutex:
- 所谓异步感知指的是后续加锁如果失败,则 yield 当前任务,防止单线程死锁。
// https://tokio.rs/tokio/tutorial/shared-state
use std::sync::{Mutex, MutexGuard};
async fn increment_and_do_stuff(mutex: &Mutex<i32>) {
let mut lock: MutexGuard<i32> = mutex.lock().unwrap();
*lock += 1;
do_something_async().await;
} // lock goes out of scope here
报错:std::sync::MutexGuard 没有实现 Send:
error: future cannot be sent between threads safely
--> src/lib.rs:13:5
|
13 | tokio::spawn(async move {
| ^^^^^^^^^^^^ future created by async block is not `Send`
|
::: /playground/.cargo/registry/src/github.com-1ecc6299db9ec823/tokio-0.2.21/src/task/spawn.rs:127:21
|
127 | T: Future + Send + 'static,
| ---- required by this bound in `tokio::task::spawn::spawn`
|
= help: within `impl std::future::Future`, the trait `std::marker::Send` is not implemented for `std::sync::MutexGuard<'_, i32>`
note: future is not `Send` as this value is used across an await
--> src/lib.rs:7:5
|
4 | let mut lock: MutexGuard<i32> = mutex.lock().unwrap();
| -------- has type `std::sync::MutexGuard<'_, i32>` which is not `Send`
...
7 | do_something_async().await;
| ^^^^^^^^^^^^^^^^^^^^^^^^^^ await occurs here, with `mut lock` maybe used later
8 | }
| - `mut lock` is later dropped here
解决办法:
async fn increment_and_do_stuff(mutex: &Mutex<i32>) {
{
let mut lock: MutexGuard<i32> = mutex.lock().unwrap();
*lock += 1;
} // lock goes out of scope here
do_something_async().await;
}
或者使用异步库提供的 Mutex 类型:
use async_std::sync::Mutex;
pub struct Outbound(Mutex<TcpStream>);
impl Outbound {
pub fn new(to_client: TcpStream) -> Outbound {
Outbound(Mutex::new(to_client))
}
pub async fn send(&self, packet: FromServer) -> ChatResult<()> {
let mut guard = self.0.lock().await;
utils::send_as_json(&mut *guard, &packet).await?;
guard.flush().await?;
Ok(())
} }
编译器为 async fn/async block 创建匿名 Future 实现类型:
use std::task::Waker;
struct MyPrimitiveFuture {
//...
waker: Option<Waker>,
}
impl Future for MyPrimitiveFuture {
type Output = ...;
fn poll(mut self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<...> {
// ...
if ... future is ready ... {
return Poll::Ready(final_value);
}
// Save the waker for later.
self.waker = Some(cx.waker().clone());
Poll::Pending
}
}
// 当这个自定义 Future 可以被 Poll 时,会通过内部的 self.waker 来告知 async executor 再次 poll
// If we have a waker, invoke it, and clear `self.waker`.
if let Some(waker) = self.waker.take() {
waker.wake();
}
spawn_blocking() 的简单参考实现:
- 传入的闭包是
同步函数,必须实现 Send + ‘static; - 内部创建一个线程来执行业务逻辑,结束候通过调用 waker 来通知 executor 完成;
pub fn spawn_blocking<T, F>(closure: F) -> SpawnBlocking<T> where
F: FnOnce() -> T,
F: Send + 'static,
T: Send + 'static,
{
let inner = Arc::new(Mutex::new(Shared { value: None, waker: None, }));
std::thread::spawn({
let inner = inner.clone();
move || {
let value = closure();
let maybe_waker = {
let mut guard = inner.lock().unwrap();
guard.value = Some(value);
guard.waker.take()
};
if let Some(waker) = maybe_waker {
waker.wake();
}
} });
SpawnBlocking(inner)
}
// 为自定义 SpawnBlocking 实现 Future
use std::future::Future;
use std::pin::Pin;
use std::task::{Context, Poll};
impl<T: Send> Future for SpawnBlocking<T> { type Output = T;
fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<T> {
let mut guard = self.0.lock().unwrap(); if let Some(value) = guard.value.take() {
return Poll::Ready(value); }
guard.waker = Some(cx.waker().clone());
Poll::Pending
}
}
block_on() 的实现:
- 使用 Parker 机制来实现 waker;
- 传入的 Future 在 loop poll 前,必须使用 pin!(future) 来转换为同名但类型为 Pin<&mut F> 的对象, pin!() 创建的 Pin 会获得 future 的所有权,而且确保该对象的栈内存地址不会再发生变化;
- future.poll() 会获得 Pin 对象的所有权,这样不能在 loop 中使用,使用 future.as_mut() 返回一个新的 Pin 对象来解决该问题。
use waker_fn::waker_fn; // Cargo.toml: waker-fn = "1.1"
use futures_lite::pin; // Cargo.toml: futures-lite = "1.11"
use crossbeam::sync::Parker; // Cargo.toml: crossbeam = "0.8"
use std::future::Future;
use std::task::{Context, Poll};
fn block_on<F: Future>(future: F) -> F::Output {
let parker = Parker::new();
let unparker = parker.unparker().clone();
let waker = waker_fn(move || unparker.unpark());
let mut context = Context::from_waker(&waker);
pin!(future);
loop {
match future.as_mut().poll(&mut context) {
Poll::Ready(value) => return value,
Poll::Pending => parker.park(),
}
} }
当 async task panic 时,可以通过 .await 返回的 Error 来判断:
use tokio::task::JoinError;
pub async fn run() {
let handle = tokio::spawn(work());
if let Err(e) = handle.await {
if let Ok(reason) = e.try_into_panic() {
// The task has panicked We resume unwinding the panic, thus propagating it to the
// current thread
panic::resume_unwind(reason);
}
}
}
pub async fn work() {
// [...]
}
async Stream: 是异步返回一系列值的机制, 类似与 Rust 标准库中的迭代器,当前 Stream 还不是 Rust 标准库的一部分。 feature-core crate 提供了 Stream trait 的定义。
poll_next() 方法返回值:
- Ready<Some(Item)>: 返回下一个值;
- Ready<None>: Stream 结束;
- Pending: 值不 Ready;
pub trait Stream {
type Item;
// Required method
fn poll_next( self: Pin<&mut Self>, cx: &mut Context<'_> ) -> Poll<Option<Self::Item>>;
// Provided method
fn size_hint(&self) -> (usize, Option<usize>) { ... }
}
Stream 的主要使用方是 tokio, tokio_stream crate 提供了便于循环迭代 Stream 的 StreamExt trait:
pub trait StreamExt: Stream {
// Provided methods
fn next(&mut self) -> Next<'_, Self> where Self: Unpin { ... }
fn try_next<T, E>(&mut self) -> TryNext<'_, Self> where Self: Stream<Item = Result<T, E>> + Unpin { ... }
fn map<T, F>(self, f: F) -> Map<Self, F> where F: FnMut(Self::Item) -> T, Self: Sized { ... }
fn map_while<T, F>(self, f: F) -> MapWhile<Self, F> where F: FnMut(Self::Item) -> Option<T>, Self: Sized { ... }
fn then<F, Fut>(self, f: F) -> Then<Self, Fut, F> where F: FnMut(Self::Item) -> Fut, Fut: Future, Self: Sized fn merge<U>(self, other: U) -> Merge<Self, U> where U: Stream<Item = Self::Item>, Self: Sized { ... }
fn filter<F>(self, f: F) -> Filter<Self, F> where F: FnMut(&Self::Item) -> bool, Self: Sized { ... }
fn filter_map<T, F>(self, f: F) -> FilterMap<Self, F> where F: FnMut(Self::Item) -> Option<T>, Self: Sized { ... }
fn fuse(self) -> Fuse<Self> where Self: Sized { ... }
fn take(self, n: usize) -> Take<Self> where Self: Sized { ... }
fn take_while<F>(self, f: F) -> TakeWhile<Self, F> where F: FnMut(&Self::Item) -> bool, Self: Sized { ... }
fn skip(self, n: usize) -> Skip<Self> where Self: Sized { ... }
fn skip_while<F>(self, f: F) -> SkipWhile<Self, F> where F: FnMut(&Self::Item) -> bool, Self: Sized { ... }
fn all<F>(&mut self, f: F) -> AllFuture<'_, Self, F> where Self: Unpin, F: FnMut(Self::Item) -> bool { ... }
fn any<F>(&mut self, f: F) -> AnyFuture<'_, Self, F> where Self: Unpin, F: FnMut(Self::Item) -> bool { ... }
fn chain<U>(self, other: U) -> Chain<Self, U> where U: Stream<Item = Self::Item>, Self: Sized { ... }
fn fold<B, F>(self, init: B, f: F) -> FoldFuture<Self, B, F> where Self: Sized, F: FnMut(B, Self::Item) -> B
fn collect<T>(self) -> Collect<Self, T> where T: FromStream<Self::Item>, Self: Sized { ... }
fn timeout(self, duration: Duration) -> Timeout<Self> where Self: Sized { ... }
fn timeout_repeating(self, interval: Interval) -> TimeoutRepeating<Self> where Self: Sized { ... }
fn throttle(self, duration: Duration) -> Throttle<Self> where Self: Sized { ... }
fn chunks_timeout( self, max_size: usize, duration: Duration ) -> ChunksTimeout<Self> where Self: Sized { ... }
fn peekable(self) -> Peekable<Self> where Self: Sized { ... }
}
示例:
// 示例1
use futures::stream::StreamExt;
let a = tokio_stream::iter(vec![1, 3, 5]);
let b = tokio_stream::iter(vec![2, 4, 6]);
// use the fully qualified call syntax for the other trait:
let merged = tokio_stream::StreamExt::merge(a, b);
// use normal call notation for futures::stream::StreamExt::collect
let output: Vec<_> = merged.collect().await;
assert_eq!(output, vec![1, 2, 3, 4, 5, 6]);
Stream 没有实现迭代器, 不支持 for-in 迭代, 只能在 StreamExt 的基础上使用 while-let 循环来迭代:
// 示例2
use tokio_stream::{self as stream, StreamExt};
#[tokio::main]
async fn main() {
let mut stream = stream::iter(vec![0, 1, 2]);
while let Some(value) = stream.next().await {
println!("Got {}", value);
}
}
tokio_stream 提供的函数:
- empty
- Creates a stream that yields nothing.
- iter
- Converts an Iterator into a Stream which is always ready to yield the next value.
- once
- Creates a stream that emits an element exactly once.
- pending
- Creates a stream that is never ready
use tokio_stream::{self as stream, StreamExt};
let mut stream = stream::iter(vec![17, 19]);
assert_eq!(stream.next().await, Some(17));
assert_eq!(stream.next().await, Some(19));
assert_eq!(stream.next().await, None);
25 macro #
macro 可以用来简化重复的代码编写任务、实现特定的 DSL,编译时代码生成等。例如:
- 创建 Vec 的 vec![] 宏;
- 为数据结构添加各种 trait 支持的 #[derive(Debug, Default, …)];
- 条件编译 #[cfg(test)] 宏;
macro 还可以实现实现一些普通函数不支持的特性,如 Rust 函数不支持可变数量的参数,但是使用宏可以实现,如 println!()。
macro 分为两类:
- 声明宏(macro_rules!):编译期间对代码模版做简单替换,比如 vec!、println! 等
- 过程宏(Procedural Macros):编译期间生成代码,分为 function、attribute、deriver 三种类型。
在调用宏前,必须将宏定义引入到当前作用域中,如定义宏或使用 use 导入宏,而函数则可以在任意位置定义并在任意位置使用。
marcro 调用有三种形式,他们之间都是等价的:marco!(xx), marcro![xxx], macro!{xx},惯例是:
- 函数传参调用场景使用 () 形式,如 println!();
- 字面量初始化使用 [] 形式,如 vec![0; 4];
宏是支持递归定义的,但是递归的层次有限制,默认是 64,可以通过 attr 来自定义:
#![recursion_limit = "256"]
25.1 声明宏(macro_rules!) #
声明宏使用一系列模式来对输入参数/代码进行匹配,生成代码, 语法规则如下:
- 宏名称后面可以使用 (xx), [xx], {xx} 三种格式来定义 body,三种方式是等价的;
- body 中各 rule 使用分号分割;
- rule 格式:MacroMatcher => MacroTranscriber,MacroMatcher 有三种等价格式: (xx), [xx], {xx};
- MacroMatch 主要的两种格式:
- $(IDENTIFIER): MacroFragSpec; 例如 $expression:expr;
- $(IDENTIFIER) MacroRepSep?MacroRepOp, 表示重复匹配,其中为可选的 MacroRepSep 重复分隔符, MacroRepOp 为重复类型字符,例如 $($expression:expr),+
macro_rules! 示例:
macro_rules! say_what {
($expression:expr) => {
println!("You said: {}", $expression);
};
}
fn main() {
say_what!("I'm learning macros");
}
macro_rules! create_function {
($func_name:ident) => {
fn $func_name() {
println!("You called {:?}()", stringify!($func_name));
}
};
}
create_function!(foo);
create_function!(bar);
macro_rules! print_result {
($expression:expr) => {
println!("{:?} = {:?}", stringify!($expression), $expression);
};
}
fn main() {
foo();
bar();
print_result!(1u32 + 1);
// Recall that blocks are expressions too!
print_result!({
let x = 1u32;
x * x + 2 * x - 1 // 该表达式的结果
});
}
这里的 $expression:expr 是一个捕获表达式,它匹配任何 Rust 表达式,并将其作为参数传递给宏。expr 的类型如下:
- item: an Item
- block: a BlockExpression
- stmt: a Statement without the trailing semicolon (except for item statements that require semicolons)
- pat_param: a PatternNoTopAlt
- pat: at least any PatternNoTopAlt, and possibly more depending on edition
- expr: an Expression
- ty: a Type
- ident: an IDENTIFIER_OR_KEYWORD or RAW_IDENTIFIER
- path: a TypePath style path
- tt: a TokenTree (a single token or tokens in matching delimiters (), [], or {})
- meta: an Attr, the contents of an attribute
- lifetime: a LIFETIME_TOKEN
- vis: a possibly empty Visibility qualifier
- literal: matches -?LiteralExpression
可以定义多个 pattern 来实现 overload:
// `test!` will compare `$left` and `$right` in different ways depending on how you invoke it:
macro_rules! test {
// Arguments don't need to be separated by a comma. Any template can be used!
($left:expr; and $right:expr) => {
println!("{:?} and {:?} is {:?}",
stringify!($left),
stringify!($right),
$left && $right)
};
// ^ each arm must end with a semicolon.
($left:expr; or $right:expr) => {
println!("{:?} or {:?} is {:?}",
stringify!($left),
stringify!($right),
$left || $right)
};
}
fn main() {
test!(1i32 + 1 == 2i32; and 2i32 * 2 == 4i32);
test!(true; or false);
}
在参数列表中 macro 使用 $(…),+ 语法来表示重复匹配其中的逗号为可选的分隔符,在 body 中使用 $($xx),+ 来引用匹配的重复。
- * — indicates any number of repetitions.
-
- — indicates any number but at least one.
- ? — indicates an optional fragment with zero or one occurrence.
// `find_min!` will calculate the minimum of any number of arguments.
macro_rules! find_min {
// Base case:
($x:expr) => ($x);
// `$x` followed by at least one `$y,`
($x:expr, $($y:expr),+) => (
// Call `find_min!` on the tail `$y`
std::cmp::min($x, find_min!($($y),+))
)
}
fn main() {
println!("{}", find_min!(1));
println!("{}", find_min!(1 + 2, 2));
println!("{}", find_min!(5, 2 * 3, 4));
}
// 重复和展开可以是多次的。
({ $($key:tt : $value:tt),* }) => { {
let mut fields = Box::new(HashMap::new());
$( fields.insert($key.to_string(), json!($value)); )* // 展开为多条 insert 方法调用。
Json::Object(fields)
} };
定义 macro 时一般使用引用来捕获对象,否则调用该宏时会转移对象所有权:
macro_rules! assert_eq {
($left:expr, $right:expr) => ({ // 匹配对象,这里的 $left 只是匹配,不是实际的变量值(没有赋值的过程)
match (&$left, &$right) { // 对象引用
(left_val, right_val) => {
if !(left_val == right_val) {
panic!("assertion failed" /* ... */);
} }
} });
}
使用 macro 来减少重复的例子(DRY):
use std::ops::{Add, Mul, Sub};
macro_rules! assert_equal_len {
// The `tt` (token tree) designator is used for operators and tokens.
($a:expr, $b:expr, $func:ident, $op:tt) => {
assert!($a.len() == $b.len(),
"{:?}: dimension mismatch: {:?} {:?} {:?}",
stringify!($func),
($a.len(),),
stringify!($op),
($b.len(),));
};
}
macro_rules! op {
($func:ident, $bound:ident, $op:tt, $method:ident) => {
fn $func<T: $bound<T, Output=T> + Copy>(xs: &mut Vec<T>, ys: &Vec<T>) {
assert_equal_len!(xs, ys, $func, $op);
for (x, y) in xs.iter_mut().zip(ys.iter()) {
*x = $bound::$method(*x, *y);
// *x = x.$method(*y);
}
}
};
}
// Implement `add_assign`, `mul_assign`, and `sub_assign` functions.
op!(add_assign, Add, +=, add);
op!(mul_assign, Mul, *=, mul);
op!(sub_assign, Sub, -=, sub);
mod test {
use std::iter;
macro_rules! test {
($func:ident, $x:expr, $y:expr, $z:expr) => {
#[test]
fn $func() {
for size in 0usize..10 {
let mut x: Vec<_> = iter::repeat($x).take(size).collect();
let y: Vec<_> = iter::repeat($y).take(size).collect();
let z: Vec<_> = iter::repeat($z).take(size).collect();
super::$func(&mut x, &y);
assert_eq!(x, z);
}
}
};
}
// Test `add_assign`, `mul_assign`, and `sub_assign`.
test!(add_assign, 1u32, 2u32, 3u32);
test!(mul_assign, 2u32, 3u32, 6u32);
test!(sub_assign, 3u32, 2u32, 1u32);
}
使用 macro 实现 DSL:
macro_rules! calculate {
(eval $e:expr) => {
{
let val: usize = $e; // Force types to be unsigned integers
println!("{} = {}", stringify!{$e}, val);
}
};
}
fn main() {
calculate! {
eval 1 + 2 // hehehe `eval` is _not_ a Rust keyword!
}
calculate! {
eval (1 + 2) * (3 / 4)
}
}
使用 macro 实现可变参数:
macro_rules! calculate {
// The pattern for a single `eval`
(eval $e:expr) => {
{
let val: usize = $e; // Force types to be integers
println!("{} = {}", stringify!{$e}, val);
}
};
// Decompose multiple `eval`s recursively
(eval $e:expr, $(eval $es:expr),+) => {{
calculate! { eval $e }
calculate! { $(eval $es),+ }
}};
}
fn main() {
calculate! { // Look ma! Variadic `calculate!`!
eval 1 + 2,
eval 3 + 4,
eval (2 * 3) + 1
}
}
25.2 过程宏(Procedural Macros) #
procedural macro 允许 在编译时运行一个 func 来创建 Rust 语法扩展(从一个 AST 到另一个 AST),包括三种形式:
- Function-like macros - custom!(…)
- Derive macros - #[derive(CustomDerive)]
- Attribute macros - #[CustomAttribute]
函数宏: 函数宏看起来和普通函数类似,但它们可以接受和返回 Rust 的 token:
// 声明 proc_macro 是外部 crate(由于 Cargo.toml 中定义了外部 crate dependences,所以一般情况下不需
// 要声明 extern crate,但是 proc_macro 是编译器带出的 crate 且没有在 dependences 中指定,所以需要单
// 独声明)
extern crate proc_macro;
use proc_macro::TokenStream;
#[proc_macro]
pub fn make_answer(_item: TokenStream) -> TokenStream {
"fn answer() -> u32 { 42 }".parse().unwrap()
}
// 使用
extern crate proc_macro_examples;
use proc_macro_examples::make_answer; // 导入函数宏
make_answer!();
fn main() {
println!("{}", answer());
}
derive 宏: derive 宏允许你为任何 struct/enum/union 自动实现特定的 trait 。
// 定义
extern crate proc_macro;
use proc_macro::TokenStream;
#[proc_macro_derive(AnswerFn)]
pub fn derive_answer_fn(_item: TokenStream) -> TokenStream {
"fn answer() -> u32 { 42 }".parse().unwrap()
}
// 使用
extern crate proc_macro_examples;
use proc_macro_examples::AnswerFn; // 导入定义的 derive 宏
#[derive(AnswerFn)]
struct Struct;
fn main() {
assert_eq!(42, answer());
}
derive macros 可以包含一些 helper attr,也就是在启用某个 derive attr 的情况下才生效的子attribute,这些 helper attr 不需要通过 use 引入到作用域:
// 定义
#[proc_macro_derive(HelperAttr, attributes(helper))]
pub fn derive_helper_attr(_item: TokenStream) -> TokenStream {
TokenStream::new()
}
// 使用
#[derive(HelperAttr)]
struct Struct {
#[helper]
field: ()
}
attribute macros: 属性宏类似于 derive宏,但它们不仅限于实现 trait。derive 宏只能用于结构体或枚举类型,属性宏可以用在其他类型上,比如函数。
- attr macros 不同于上面不需要导入的 helper attrs,它们需要明确导入。
// my-macro/src/lib.rs
#[proc_macro_attribute]
pub fn show_streams(attr: TokenStream, item: TokenStream) -> TokenStream {
println!("attr: \"{}\"", attr.to_string());
println!("item: \"{}\"", item.to_string());
item
}
// 使用
// src/lib.rs
extern crate my_macro;
use my_macro::show_streams; // 需要导入 attr macros
#[show_streams]
fn invoke1() {}
// out: attr: ""
// out: item: "fn invoke1() {}"
// 带参数的 attr macro,参数可以是各种语法格式
#[show_streams(bar)]
fn invoke2() {}
// out: attr: "bar"
// out: item: "fn invoke2() {}"
#[show_streams(multiple => tokens)]
fn invoke3() {}
// out: attr: "multiple => tokens"
// out: item: "fn invoke3() {}"
#[show_streams { delimiters }]
fn invoke4() {}
// out: attr: "delimiters"
// out: item: "fn invoke4() {}"
过程宏只能在单独的 proc-macro 类型的 crate package 中定义,包名也要以 derive 结尾:
- 编译器使用 Cargo.toml 中定义的 lib.proc-macro=true 来标识该 crate 是 proc-macro crate type.
- 编译器提供的 crate type 类型: https://doc.rust-lang.org/reference/linkage.html
- RFC 参考: https://rust-lang.github.io/rfcs/1566-proc-macros.html
.
├── Cargo.lock
├── Cargo.toml
├── hello_macro_derive
│ ├── Cargo.toml
│ └── src
│ └── lib.rs
└── src
├── lib.rs
└── main.rs
在单独的 crate package 中
定义过程宏的解答: A proc macro has to be compiled for the host such that
rustc can dlopen them, but non-proc macro crates have to be compiled for the target such that they
can be linked into the target executable or dynamic library. When host can be different from the
target, this implies that the proc macro and non-proc macro definitions have to be in separate
crates.
修改 hello_macro/Cargo.toml 文件,在 src/main.rs 引用 hello_macro_derive 包的内容:
[dependencies]
hello_macro_derive = { path = "../hello_macro/hello_macro_derive" }
# 也可以使用下面的相对路径
# hello_macro_derive = { path = "./hello_macro_derive" }
定义过程宏: 在 hello_macro_derive/Cargo.toml 文件中添加以下内容:
[lib]
# 链接 rustc 工具链提供的 proc-macro 库 libproc_macro, 同时也表明该 crate 是 proc macro 类型。
proc-macro = true
[dependencies] # 定义过程宏依赖的包
syn = "1.0"
quote = "1.0"
其次,在 hello_macro_derive/src/lib.rs 中添加如下代码:
use proc_macro::TokenStream;
use syn;
use syn::DeriveInput;
use quote::quote;
#[proc_macro_derive(HelloMacro)]
pub fn hello_macro_derive(input: TokenStream) -> TokenStream {
// 基于 Input 构建 AST 语法树
let ast: DeriveInput = syn::parse(input).unwrap();
impl_hello_macro(&ast)
}
fn impl_hello_macro(ast: &syn:: DeriveInput) -> TokenStream {
// 获取结构体、枚举标识
let name = &ast.ident;
let gen = quote! {
// 为目标结构体或枚举自动实现特征
impl HelloMacro for #name {
fn hello_macro() {
println!("Hello, Macro! My name is {}!", stringify!(#name));
}
}
};
gen.into()
}
libproc_macro 是随 rustc 编译器一起安装的,由 proc_macro crate 提供的库:
- ~/.rustup/{toolchain}/libexec/rust-analyzer-proc-macro-srv 用于 rust-analyzer 来对 proc macro 进行 expand 分析(也即获得 proc macro 展开后的代码).
- rustc 提供了 proc-macro server 的功能, 但是 rust-analyzer 也提供了该功能: https://fasterthanli.me/articles/proc-macro-support-in-rust-analyzer-for-nightly-rustc-versions
zj@a:~/docs$ ls -l ~/.rustup/toolchains/nightly-x86_64-apple-darwin/lib/rustlib/x86_64-apple-darwin/lib/libproc_macro-ce17747687ef7ea0.rlib
-rw-r--r-- 1 zhangjun 4.5M 3 4 19:09 /Users/zhangjun/.rustup/toolchains/nightly-x86_64-apple-darwin/lib/rustlib/x86_64-apple-darwin/lib/libproc_macro-ce17747687ef7ea0.rlib
zj@a:~/docs$ ls -l ~/.rustup/toolchains/nightly-x86_64-apple-darwin/libexec/
total 1.4M
-rwxr-xr-x 1 zhangjun 1.4M 3 4 19:09 rust-analyzer-proc-macro-srv*
# The main rust-analyzer process and the proc-macro server communicate over a JSON interface
# https://fasterthanli.me/articles/proc-macro-support-in-rust-analyzer-for-nightly-rustc-versions
# libpm-e886d9f9eaf24619.so 是编译后的 proc-macro crate lib
$ echo '{"ListMacros":{"dylib_path":"target/debug/deps/libpm-e886d9f9eaf24619.so"}}' | ~/.cargo/bin/rust-analyzer proc-macro
{"ListMacros":{"Ok":[["do_thrice","FuncLike"]]}}
由于 rustc 内置的 proc_macro create 提供的 API 只能在 procedure macro 类型 crate 中使用, 所以不能在 build.rs 和 main.rs 等场景中使用它们, 同时也不能用来进行测试,所以社区引入了 proc-macro2 crate,它是 rustc 内置 proc_macro create 的封装(wrapper), 主要提供如下两个特性:
- Bring proc-macro-like functionality to other contexts like build.rs and main.rs.
- Make procedural macros unit testable.
proc-macro2 在 serde/tokio-marcros 等项目中广泛使用。
25.3 macro_use/macro_export #
macro 的 scope 包含 textual scope 和 path-base scope。
如果只使用标识符来引用 macro 则默认是 textual scope,如果使用 path 语法来引用 macro 则是 path-base scope。
use lazy_static::lazy_static; // 导入外部的 macro,该 macro 需要通过 #{macro_expose} 暴露。
macro_rules! lazy_static { // 上下文中重定义该 macro
(lazy) => {};
}
lazy_static!{lazy} // 使用上下文中定义的 macro 版本
self::lazy_static!{} // Path-based lookup ignores our macro, finds imported one.
textual scope 的特点:
- 依赖于定义的位置,如 module、fn 内部等;
- 父 module 定义的 macro 可以在子 module 中直接使用(类似于其他 item 也是同样的效果);
- 可以重复定义 macro,最后的生效:
//// src/lib.rs
mod has_macro {
// m!{} // Error: m is not in scope.
macro_rules! m {
() => {};
}
m!{} // OK: appears after declaration of m.
mod uses_macro;
}
// m!{} // Error: m is not in scope.
//// src/has_macro/uses_macro.rs
m!{} // OK: appears after declaration of m in src/lib.rs
// 重复定义时,最后一次生效
macro_rules! m {
(1) => {};
}
m!(1);
mod inner {
m!(1);
macro_rules! m {
(2) => {};
}
// m!(1); // Error: no rule matches '1'
m!(2);
macro_rules! m {
(3) => {};
}
m!(3);
}
m!(1);
// 可以在 fn 里定义 macro
fn foo() {
// m!(); // Error: m is not in scope.
macro_rules! m {
() => {};
}
m!();
}
// m!(); // Error: m is not in scope.
导入外部宏定义 ,可以使用 use path 或 #[macro_use] attr:
- 位于 mod 前时,将 module 中定义的所有 marco 在 module 外部生效(不支持指定 macro 列表);
- 位于 extern crate 前时,从其它 crate 导入
所有macro 定义,或指定导入的 macro 列表;- 其它 crate 必须使用 #[macro_export] 来导出 macro 后才能被 macro_use;
// 将 mod 中定义的所有宏导出到 root crate,后续可以在所有子 module 中使用。
#[macro_use]
mod inner {
macro_rules! m {
() => {};
}
}
m!(); // root crate 可用
// 导入 crate 中所有宏
#[macro_use]
extern crate lazy_static;
// 导入 crate 中的 lazy_static 宏
#[macro_use(lazy_static)]
extern crate lazy_static;
// 使用 use 导入 crate 中的特定宏
use serde::{Serialize, Deserialize};
#[derive(Serialize, Deserialize)]
struct MyStruct {
field1: String,
field2: i32,
}
#[macro_export] attr 可以 将 macro 定义导出到 crate root scope ,进而可以使用 path-based scope 的语法来使用它(未 export 时是 textural scoped),Rust 2018 开始支持该特性:
- #[macro_export] 标记的 macro 始终是 pub 的,其他 crate 可以直接使用 use 来 by path 导入他们或者使用 macro_use 来导入他们:
self::m!(); // OK
m!(); // OK: Path-based lookup finds m in the current module.
mod inner {
super::m!();
crate::m!();
}
mod mac {
#[macro_export]
macro_rules! m { // 将 m 导出到 root crate
() => {};
}
}
crate 内部的 macro 相互引用:macro A 定义内部可以使用同 crate 定义的其他 macro B,但是如果在其他 crate 只导入 macro A 而未导入 macro B 的话,会导致扩展错误。
解决办法:在 macro A 内部使用绝对 path 来引用它使用的对象或类型。$crate 是只能在 macro 定义中使用的一个变量,它是 macro 定义所在的 module 的 root crate,可以用来引用依赖的 macro B,同时 macro B 也必须被 macro_export:
//// Definitions in the `helper_macro` crate.
#[macro_export]
macro_rules! helped {
// () => { helper!() } // This might lead to an error due to 'helper' not being in scope.
() => { $crate::helper!() }
}
#[macro_export]
macro_rules! helper {
() => { () }
}
//// Usage in another crate. Note that `helper_macro::helper` is not imported!
use helper_macro::helped; // 由于 helped 由 macro_export,所以,其他 crate 可以使用 use 来直接导入使用
fn unit() {
helped!();
}
// 由于 $crate 是本 crate root,所以如果要引用其他定义,则需要使用包含中间 module 的完整引用路径。同
// 时引用的 item 也必须是 pub 的。
pub mod inner {
#[macro_export]
macro_rules! call_foo {
() => { $crate::inner::foo() }; // 必须使用完整路径
}
pub fn foo() {} // 必须是 pub 的
}
在使用 #[macro_export] 时可以添加 local_inner_macros 参数,这样会自动对内部调用的 macro 添加 $crate:: 前缀:
#[macro_export(local_inner_macros)]
macro_rules! helped {
() => { helper!() } // Automatically converted to $crate::helper!().
}
#[macro_export]
macro_rules! helper {
() => { () }
}
25.4 常用 macro #
file!(), line!(), column!() file!()
expands to a string literal: the current filename. line!() and column!() expand to u32 literals giving the current line and column (counting from 1). If one macro calls another, which calls another, all in different files, and the last macro calls file!(), line! (), or column!(), it will expand to indicate the location of the first macro call.
stringify!(…tokens…)
Expands to a string literal containing the given tokens. The assert! macro uses this to generate an error message that includes the code of the assertion. Macro calls in the argument are not expanded: stringify!(line!()) expands to the string “line!()”. Rust constructs the string from the tokens, so there are no line breaks or comments in the string.
concat!(str0, str1, …)
Expands to a single string literal made by concatenating its arguments. Rust also defines these macros for querying the build environment:
cfg!(…)
Expands to a Boolean constant, true if the current build configuration matches the condition in parentheses.
env!(“VAR_NAME”)
Expands to a string: the value of the specified environment variable at compile time. If the variable doesn’t exist, it’s a compilation error. This would be fairly worthless except that Cargo sets several interesting environment variables when it compiles a crate. For example, to get your crate’s current version string, you can write: let version = env!(“CARGO_PKG_VERSION”); A full list of these environment variables is included in the Cargo documentation.
option_env!(“VAR_NAME”)
This is the same as env! except that it returns an Option<&‘static str> that is None if the specified variable is not set.
include!(“file.rs”)
Expands to the contents of the specified file, which must be valid Rust code—either an expression or a sequence of items.
include_str!(“file.txt”)
Expands to a &‘static str containing the text of the specified file. You can use it like this: const COMPOSITOR_SHADER: &str = include_str!("../resources/compositor.glsl"); If the file doesn’t exist or is not valid UTF-8, you’ll get a compilation error.
include_bytes!(“file.dat”)
This is the same except the file is treated as binary data, not UTF-8 text. The result is a &‘static [u8].
todo!(), unimplemented!()
These are equivalent to panic!(), but convey a different intent. unimplemented!() goes in if clauses, match arms, and other cases that are not yet handled. It always panics. todo!() is much the same, but conveys the idea that this code simply has yet to be written; some IDEs flag it for notice.
matches!(value, pattern)
Compares a value to a pattern, and returns true if it matches, or false otherwise. It’s equivalent to writing: match value { pattern => true, _ => false } If you’re looking for an exercise in basic macro-writing, this is a good macro to replicate—especially since the real implementation, which you can see in the standard library documentation, is quite simple.
25.5 attribute macro #
attribute 有两种形式:
- #[outer_attribute], 直接对紧接者的 item 有效;
- #![inner_attribute], 对 enclosing item, 一般是 module 或 crate
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
#![allow(unused_variables)]
fn main() {
let x = 3;
}
attribute 可以带参数:
- #[attribute = “value”]
- #[attribute(key = “value”)]
- #[attribute(value)]
- #[attribute(value, value2)]
- #[attribute(value, value2, value3, value4, value5)]
常见 attribute:
- nightly-only experimental API: 需要使用 #![feature(API_NAME)] 来启用 nightly 实验性 APIs:
- 需要安装 nightly toolchain;
#![feature(iter_next_chunk)]
let mut iter = "lorem".chars();
assert_eq!(iter.next_chunk().unwrap(), ['l', 'o']); // N is inferred as 2
assert_eq!(iter.next_chunk().unwrap(), ['r', 'e', 'm']); // N is inferred as 3
assert_eq!(iter.next_chunk::<4>().unwrap_err().as_slice(), &[]); // N is explicitly 4
let quote = "not all those who wander are lost";
let [first, second, third] = quote.split_whitespace().next_chunk().unwrap();
assert_eq!(first, "not");
assert_eq!(second, "all");
assert_eq!(third, "those");
- #[allow(dead_code)]: 运行未使用的代码(如变量声明, 函数定义).
// Nested modules follow the same rules for visibility
mod private_nested {
#[allow(dead_code)]
pub fn function() {
println!("called `my_mod::private_nested::function()`");
}
}
- #![allow(unused_variables)]:
#![allow(unused_variables)]
fn main() {
let x = 3; // This would normally warn about an unused variable.
}
- #[cfg(…)] 条件编译: unix, windows, target_arch = “x86_64”, target_os = “linux”, feature = “robots” (自定义 feature);
// This function only gets compiled if the target OS is linux
#[cfg(target_os = "linux")]
fn are_you_on_linux() {
println!("You are running linux!");
}
// And this function only gets compiled if the target OS is *not* linux
#[cfg(not(target_os = "linux"))]
fn are_you_on_linux() {
println!("You are *not* running linux!");
}
fn main() {
are_you_on_linux();
println!("Are you sure?");
if cfg!(target_os = "linux") {
println!("Yes. It's definitely linux!");
} else {
println!("Yes. It's definitely *not* linux!");
}
}
// rustc --cfg some_condition custom.rs && ./custom
#[cfg(some_condition)] // 自定义 cfg
fn conditional_function() {
println!("condition met!");
}
fn main() {
conditional_function();
}
- #[test]
// 在 mod 前添加 cfg test attr, 表明这一个 module 中的代码只在 test 时编译使用, 可以避免编译器未使用代码的警告.
#[cfg(test)]
mod tests
{
fn roughly_equal(a: f64, b: f64) -> bool { (a - b).abs() < 1e-6
}
#[test]
fn trig_works() {
use std::f64::consts::PI;
assert!(roughly_equal(PI.sin(), 0.0));
}
}
#[test]
#[allow(unconditional_panic, unused_must_use)]
#[should_panic(expected="divide by zero")]
fn test_divide_by_zero_error() {
1 / 0; // should panic!
}
25.6 宏染色 hygienic macro #
在定义宏时,可能会出现宏实现的代码和宏上下文相互影响的情况:
// 宏定义 body 中定义了一个 fields 临时变量
({ $($key:tt : $value:tt),* }) => { {
let mut fields = Box::new(HashMap::new());
$( fields.insert($key.to_string(), json!($value)); )*
Json::Object(fields)
} };
// 在使用宏时,宏的参数中也使用了上下文中同名的变量
let fields = "Fields, W.C.";
let role = json!({
"name": "Larson E. Whipsnade",
"actor": fields
}
);
// 直接做宏展开时就有问题
let fields = "Fields, W.C.";
let role = {
let mut fields = Box::new(HashMap::new());
fields.insert("name".to_string(), Json::from("Larson E. Whipsnade"));
fields.insert("actor".to_string(), Json::from(fields));
Json::Object(fields)
};
解决办法:使用类似与颜色标记的方式将宏定义的代码和宏参数的变量区分开来,并对宏定义内部的变量自动重命名从而防止和宏参数内部的变量冲突。如果在宏定义代码中确实要使用外部的变量,则需要通过宏参数传递的形式传到宏内部。《— 被称为:hygienic macro
- hygienic 仅限于宏定义中的 local variable 和 arguments,对于宏定义中使用其他对象类型,如 Box/HashMap等,宏不会重命名。
hygienic 带来的问题:宏定义 body 不能直接使用上下文中的变量:
macro_rules! setup_req {
() => {
let req = ServerRequest::new(server_socket.session()); }
}
fn handle_http_request(server_socket: &ServerSocket) {
setup_req!(); // declares `req`, uses `server_socket`
// ...
// code that uses `req`
}
解决办法:将依赖的上下文变量通过参数的形式传递到宏定义中:
macro_rules! setup_req {
($req:ident, $server_socket:ident) => {
let $req = ServerRequest::new($server_socket.session());
}
}
fn handle_http_request(server_socket: &ServerSocket) {
setup_req!(req, server_socket);
// ...
// code that uses `req`
}
25.7 调试宏 #
- 使用 cargo build –verbose 来查看编译过程,比如 rustc 命令,然后将 rustc 命令复制出来,添加选项 -Z unstable-options – pretty expanded 手动执行;这时会将 expanded code 打印出来,但是如果代码有语法错误,则不行;
- 使用 cargo-expand 工具命令;
- 开启 #![feature(log_syntax)] ,然后使用 log_syntax!() 来打印传入的值;
- 开启 #![feature(trace_macros)],然后在需要打印 macro 的地方插入 trace_macros!(true); ,结束后插入 trace_macros!(false);
- 对于 emacs,安装了 eglot-x package 后,可以使用命令 M-x eglot-x-expand-macro 来展开宏;
26 raw pointer #
裸指针的 unsafe 特性:
- 允许忽略借用规则,可以
同时拥有指向同一个内存地址的可变和不可变指针,或者拥有指向同一个地址的多个可变指针; - 不能保证总是指向有效的内存地址;
- 允许为空;
裸指针的主要使用场景是 FFI(如 C 函数的指针类型需要 raw pointer 来声明和传递参数)、硬件、高效性能优化等;
两种 raw pointer 类型:
- A
*mut Tis a raw pointer to a T that permits modifying its referent. - A
*const Tis a raw pointer to a T that only permits reading its referent.
创建 raw pointer:通过引用创建裸指针,可以在安全代码内合法地创建裸指针,但只能在 unsafe block 中解引用裸指针。
- 使用 as 操作符将引用转换为 raw pointer 时(称为 type coercing),需要确保对象是 live 的,而且不通过
引用(而只使用 raw pointer)来访问同一个内存,也就是引用和 raw pointer 存取不能交叉。
let mut num = 5;
// 有效的裸指针,可以同时创建的不可变和可变裸指针
let r1 = &num as *const i32;
let r2 = &mut num as *mut i32;
// 可能无效的裸指针
let address = 0x012345usize;
let r = address as *const i32;
let my_num: i32 = 10;
let my_num_ptr: *const i32 = &my_num; // 引用类型自动 type coercing 到 raw pointer
let mut my_speed: i32 = 88;
let my_speed_ptr: *mut i32 = &mut my_speed;
let mut x = 10;
let ptr_x = &mut x as *mut i32; // as 运算符将借用转换为 raw pointer
let y = Box::new(20);
let ptr_y = &*y as *const i32;
unsafe {
*ptr_x += *ptr_y;
}
assert_eq!(x, 30);
fn very_trustworthy(shared: &i32) {
unsafe {
// Turn the shared reference into a mutable pointer.
// This is undefined behavior.
let mutable = shared as *const i32 as *mut i32;
*mutable = 20;
}
}
// 只能在 unsafe block 中解引用裸指针
unsafe {
println!("r1 is: {}", *r1);
println!("r2 is: {}", *r2);
}
如果要获得 boxed value 的 raw pointer,需要解引用 Box,这并不会获得原始值的 ownership;
- Box<T> 的 into_raw() 函数消耗 Box 的同时返回一个 raw pointer:
let my_num: Box<i32> = Box::new(10);
let my_num_ptr: *const i32 = &*my_num; // &*my_num 的结果是 &i32,可以转换为 *const i32
let mut my_speed: Box<i32> = Box::new(88);
let my_speed_ptr: *mut i32 = &mut *my_speed;
let my_speed: Box<i32> = Box::new(88);
let my_speed: *mut i32 = Box::into_raw(my_speed);
// By taking ownership of the original `Box<T>` though we are obligated to put it together later to
// be destroyed.
unsafe {
drop(Box::from_raw(my_speed));
}
使用宏函数 std::ptr::addr_of!() 和 std::ptr::addr_of_mut!() 来返回 express 的 raw pointer:
- packed struct:默认情况下,struct 对象的 field 会通过 pading 来对齐。通过添加 packed attr,可以关闭 struct field padding 对齐机制,这样 struct 的某个 field 可能是未对齐的。
- 对于未对齐的 filed,是不能创建引用的,但是通过 addr_of!() 和 addr_of_mut!() 宏是可以创建
未对齐的 raw pointer。
#[derive(Debug, Default, Copy, Clone)]
#[repr(C, packed)]
struct S {
aligned: u8,
unaligned: u32,
}
let s = S::default();
let p = std::ptr::addr_of!(s.unaligned); // not allowed with coercion
// 可以使用 libc 的 malloc 和 free 来管理 raw pointer:
#[allow(unused_extern_crates)]
extern crate libc;
use std::mem;
unsafe {
let my_num: *mut i32 = libc::malloc(mem::size_of::<i32>()) as *mut i32;
if my_num.is_null() {
panic!("failed to allocate memory");
}
libc::free(my_num as *mut libc::c_void);
}
其他创建 raw pointer 方式:
- 很多类型提供了 as_ptr() 和 as_mut_ptr() 方法来返回他的 raw pointer.
- Owning 指针类型, 如 Box/Rc/Arc 提供 into_raw() 和 from_raw() 方法来生成 raw pointer 或从 raw pointer 创建对象.
- 也可以从 int 创建 raw pointer, 但是非常不安全.
通过 raw pointer 的 *ptr = data 来保存对象时,会对 ptr 指向的 old value 调用 drop 。但是通过裸指针的
write() 方法或 std::ptr::write() 来写入新对象时,并不会 drop old value。
raw pointer 本身可以是 unaligned 或 null,但是当解引用 raw pointer 时, 他必须是 non-null 和 aligned : aligned 是指指针的地址如 *const T 是 std::mem::align_of::<T>() 的倍数。
裸指针可以为 null:
- 创建 null 指针:
- std::ptr::null::<T>() 对应 *const T;
- std::ptr::null_mut::<T>() 对应 *mut T;
- 检查 null 指针:使用 is_null/as_ptr/as_mut_ptr 方法;
fn option_to_raw<T>(opt: Option<&T>) -> *const T {
match opt {
None => std::ptr::null(),
Some(r) => r as *const T
}
}
assert!(!option_to_raw(Some(&("pea", "pod"))).is_null());
assert_eq!(option_to_raw::<i32>(None), std::ptr::null());
raw pointer 的一些限制:
- 必须显示解引用,(*raw).field 或 (*raw).method(…);
- raw pointer 不支持 Deref;
- raw pointer 的比较运算,如 == 或 <, 比较的是指针地址, 而非他指向的内容;
- raw pointer 没有实现 Display, 但是实现了 Debug 和 Pointer;
- 不支持 raw pointer 的算术运算符, 但是可以使用库函数来进行运算;
- raw pointer 没有实现 Send/Sync, 不能跨线程或 async spawn 中使用.
let trucks = vec!["garbage truck", "dump truck", "moonstruck"];
let first: *const &str = &trucks[0];
let last: *const &str = &trucks[2];
assert_eq!(unsafe { last.offset_from(first) }, 2);
assert_eq!(unsafe { first.offset_from(last) }, -2);
// as 运算符支持将引用转换为 raw pointer(反过来不支持), 但是可能需要多次转换
&vec![42_u8] as *const String; // error: invalid conversion
&vec![42_u8] as *const Vec<u8> as *const String; // permitted
Rust 的 array/slice/vector 都是连续的内存地址块,每个元素占用固定大小的(std::mem::size_of<T>)内存。
fn offset<T>(ptr: *const T, count: isize) -> *const T where T: Sized
{
let bytes_per_element = std::mem::size_of::<T>() as isize;
let byte_offset = count * bytes_per_element;
(ptr as isize).checked_add(byte_offset).unwrap() as *const T
}
裸指针 *const T 和 *mut T 的方法( 标准库的 std::ptr module 也提供了一些方法来操作 raw pointer):
- 指针是否为 null
- pub fn is_null(self) -> bool
- 将指针转换为 U 的指针
- pub const fn cast<U>(self) -> *const U
- 返回指定 count 对象的偏移指针
- pub const unsafe fn offset(self, count: isize) -> *const T
- 计算相对于指定指针的对象数量
- pub const unsafe fn offset_from(self, origin: *const T) -> isize
- 计算增加 count 对象的偏移指针
- pub const unsafe fn add(self, count: usize) -> *const T
- 计算减少 count 对象的偏移指针
- pub const unsafe fn sub(self, count: usize) -> *const T
- 读取 raw pointer 的内容,但是不 move self
- pub const unsafe fn read(self) -> T
- 拷贝 count * size_of<T>() bytes,src 和 dest 地址可以重叠
- pub const unsafe fn copy_to(self, dest: *mut T, count: usize)
- 写入 T 值,但是不 read & drop 原来的值
- pub unsafe fn write(self, val: T)
- 替换 T 值,但是不 read & drop 原来的值
- pub unsafe fn replace(self, src: T) -> T
- 交换两个地址的值
- pub unsafe fn swap(self, with: *mut T)
impl<T> *const T where T: ?Sized,
pub fn is_null(self) -> bool
let s: &str = "Follow the rabbit";
let ptr: *const u8 = s.as_ptr();
assert!(!ptr.is_null());
// Casts to a pointer of another type.
pub const fn cast<U>(self) -> *const U
pub const fn cast_mut(self) -> *mut T
pub fn with_metadata_of<U>(self, meta: *const U) -> *const U where U: ?Sized,
// Gets the “address” portion of the pointer. This is similar to self as usize
pub fn addr(self) -> usize
pub fn expose_addr(self) -> usize
// Creates a new pointer with the given address. This performs the same operation as an addr as ptr cast
pub fn with_addr(self, addr: usize) -> *const T
// Creates a new pointer by mapping self’s address to a new one. This is a convenience for
// with_addr, see that method for details.
pub fn map_addr(self, f: impl FnOnce(usize) -> usize) -> *const T
// Decompose a (possibly wide) pointer into its data pointer and metadata components.
pub fn to_raw_parts(self) -> (*const (), <T as Pointee>::Metadata)
// Returns None if the pointer is null, or else returns a shared reference to the value wrapped in
// Some. If the value may be uninitialized, as_uninit_ref must be used instead.
pub unsafe fn as_ref<'a>(self) -> Option<&'a T>
pub unsafe fn as_uninit_ref<'a>(self) -> Option<&'a MaybeUninit<T>>
let ptr: *const u8 = &10u8 as *const u8;
unsafe {
if let Some(val_back) = ptr.as_ref() {
println!("We got back the value: {val_back}!");
}
}
// Calculates the offset from a pointer. count is in units of T; e.g., a count of 3 represents a
// pointer offset of 3 * size_of::<T>() bytes.
//
// offset 的起始地址和加了 count*size 的结束地址都必须位于已分配对象的内存范围内,否则是 UB。
pub const unsafe fn offset(self, count: isize) -> *const T
let s: &str = "123";
let ptr: *const u8 = s.as_ptr();
unsafe {
println!("{}", *ptr.offset(1) as char);
println!("{}", *ptr.offset(2) as char);
}
// Calculates the offset from a pointer in bytes. count is in units of bytes.
pub const unsafe fn byte_offset(self, count: isize) -> *const T
// wrapping_offset 和 offset 相比,不要求起始和结束地址都位于已分配对象的内存范围内。
pub const fn wrapping_offset(self, count: isize) -> *const T
pub const fn wrapping_byte_offset(self, count: isize) -> *const T
// Iterate using a raw pointer in increments of two elements
let data = [1u8, 2, 3, 4, 5];
let mut ptr: *const u8 = data.as_ptr();
let step = 2;
let end_rounded_up = ptr.wrapping_offset(6);
// This loop prints "1, 3, 5, "
while ptr != end_rounded_up {
unsafe {
print!("{}, ", *ptr);
}
ptr = ptr.wrapping_offset(step);
}
pub fn mask(self, mask: usize) -> *const T
// Calculates the distance between two pointers. The returned value is in units of T: the distance
// in bytes divided by mem::size_of::<T>(). This is equivalent to (self as isize - origin as isize)
// / (mem::size_of::<T>() as isize),
pub const unsafe fn offset_from(self, origin: *const T) -> isize
pub const unsafe fn byte_offset_from<U>(self, origin: *const U) -> isize where U: ?Sized,
let a = [0; 5];
let ptr1: *const i32 = &a[1];
let ptr2: *const i32 = &a[3];
unsafe {
assert_eq!(ptr2.offset_from(ptr1), 2);
assert_eq!(ptr1.offset_from(ptr2), -2);
assert_eq!(ptr1.offset(2), ptr2);
assert_eq!(ptr2.offset(-2), ptr1);
}
// Calculates the distance between two pointers, where it’s known that self is equal to or greater
// than origin. The returned value is in units of T: the distance in bytes is divided by
// mem::size_of::<T>().
//
// add/sub/sub_ptr() 的关系:
// ptr.sub_ptr(origin) == count
// origin.add(count) == ptr
// ptr.sub(count) == origin
pub unsafe fn sub_ptr(self, origin: *const T) -> usize
pub fn guaranteed_eq(self, other: *const T) -> Option<bool>
pub fn guaranteed_ne(self, other: *const T) -> Option<bool>
// Calculates the offset from a pointer (convenience for .offset(count as isize)). count is in units
// of T; e.g., a count of 3 represents a pointer offset of 3 * size_of::<T>() bytes.
pub const unsafe fn add(self, count: usize) -> *const T
pub const unsafe fn byte_add(self, count: usize) -> *const T
let s: &str = "123";
let ptr: *const u8 = s.as_ptr();
unsafe {
println!("{}", *ptr.add(1) as char);
println!("{}", *ptr.add(2) as char);
}
// Calculates the offset from a pointer (convenience for .offset((count as
// isize).wrapping_neg())). count is in units of T; e.g., a count of 3 represents a pointer offset
// of 3 * size_of::<T>() bytes.
pub const unsafe fn sub(self, count: usize) -> *const T
pub const unsafe fn byte_sub(self, count: usize) -> *const T
pub const fn wrapping_add(self, count: usize) -> *const T
pub const fn wrapping_byte_add(self, count: usize) -> *const T
pub const fn wrapping_sub(self, count: usize) -> *const T
pub const fn wrapping_byte_sub(self, count: usize) -> *const T
// Reads the value from self without moving it. This leaves the memory in self unchanged. See
// ptr::read for safety concerns and examples.
pub const unsafe fn read(self) -> T
pub unsafe fn read_volatile(self) -> T
pub const unsafe fn read_unaligned(self) -> T
// Copies count * size_of<T> bytes from self to dest. The source and destination may overlap. NOTE:
// this has the same argument order as ptr::copy. See ptr::copy for safety concerns and examples.
pub const unsafe fn copy_to(self, dest: *mut T, count: usize)
pub const unsafe fn copy_to_nonoverlapping(self, dest: *mut T, count: usize)
pub fn align_offset(self, align: usize) -> usize
pub fn is_aligned(self) -> bool
pub fn is_aligned_to(self, align: usize) -> bool
// *mut T 类型是在 *const T 的方法基础上,增加了一些 write 相关的方法
impl<T> *mut T where T: ?Sized,
// ...
pub unsafe fn as_mut<'a>(self) -> Option<&'a mut T>
pub unsafe fn as_uninit_mut<'a>(self) -> Option<&'a mut MaybeUninit<T>>
// ...
// Executes the destructor (if any) of the pointed-to value. See ptr::drop_in_place for safety
// concerns and examples.
pub unsafe fn drop_in_place(self)
// Overwrites a memory location with the given value without reading or dropping the old value. See
// ptr::write for safety concerns and examples.
pub unsafe fn write(self, val: T)
pub unsafe fn write_bytes(self, val: u8, count: usize)
pub unsafe fn write_volatile(self, val: T)
pub unsafe fn write_unaligned(self, val: T)
pub unsafe fn replace(self, src: T) -> T
pub unsafe fn swap(self, with: *mut T)
pub fn align_offset(self, align: usize) -> usize
pub fn is_aligned(self) -> bool
pub fn is_aligned_to(self, align: usize) -> bool
27 FFI #
Foreign Function 必须在 extern {} block 中声明, external block 中可以定义 static 变量和函数声明(不含 body,如 Rust 要调用的 C 库的全局变量或函数声明),编译器再根据 ABI 或 #[link(name=“crypto”)] attr macro 来链接到具体的库实现上。
- link kind 支持:dylib、static、framework(MacOS)、raw-dylib(windows);
- 对于 static link,可以使用 bundle 机制来将依赖的 static lib 打包到二进制中;
use std::fmt;
use num::Complex;
extern "C" {
fn foo(x: i32, ...);
fn with_name(format: *const u8, args: ...);
}
#[link(name = "crypto")]
extern {
// …
}
#[link(name = "CoreFoundation", kind = "framework")]
extern {
// …
}
#[link(wasm_import_module = "foo")]
extern {
// …
}
// this extern block links to the libm library
#[cfg(target_family = "windows")]
#[link(name = "msvcrt")]
extern {
// this is a foreign function that computes the square root of a single precision complex number
fn csqrtf(z: Complex) -> Complex;
fn ccosf(z: Complex) -> Complex;
}
#[cfg(target_family = "unix")]
#[link(name = "m")]
extern {
// this is a foreign function that computes the square root of a single precision complex number
fn csqrtf(z: Complex) -> Complex;
fn ccosf(z: Complex) -> Complex;
}
// Since calling foreign functions is considered unsafe, it's common to write safe wrappers around
// them.
fn cos(z: Complex) -> Complex {
unsafe { ccosf(z) }
}
fn main() {
// z = -1 + 0i
let z = Complex { re: -1., im: 0. };
// calling a foreign function is an unsafe operation
let z_sqrt = unsafe { csqrtf(z) };
println!("the square root of {:?} is {:?}", z, z_sqrt);
// calling safe API wrapped around unsafe operation
println!("cos({:?}) = {:?}", z, cos(z));
}
// Minimal implementation of single precision complex numbers
#[repr(C)]
#[derive(Clone, Copy)]
struct Complex {
re: f32,
im: f32,
}
impl fmt::Debug for Complex {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
if self.im < 0. {
write!(f, "{}-{}i", self.re, -self.im)
} else {
write!(f, "{}+{}i", self.re, self.im)
}
}
}
当通过 FFI 调用的其他语言出现 excception/panic 时, Rust 不会进行栈展开, 而是可能直接推出:
- 如果 Rust 非主线程发生 panic, 默认是栈展开, 而不会导致程序直接退出的.
- 参考: https://doc.rust-lang.org/nomicon/ffi.html
Rust 的 std::os::raw 提供了 C 类型的 Rust 表示,这些 c_ 开头的类型其实是 Rust 原始类型的 alias, 比如 c_char 是 i8/u8 的别名.
- Rust 的 usize/isize 对应 C 的 size_t 和 ptrdiff_t;
- Rust 的 raw pointer 如 *mut T 和 *const T 对应 C 的指针类型;
| C type | Corresponding std::os::raw type |
|---|---|
| short | c_short |
| int | c_int |
| long | c_long |
| long long | c_longlong |
| unsigned short | c_ushort |
| unsigned, unsigned int | c_uint |
| unsigned long | c_ulong |
| unsigned long long | c_ulonglong |
| char | c_char |
| signed char | c_schar |
| unsigned char | c_uchar |
| float | c_float |
| double | c_double |
| void *, const void * | *mut c_void, *const c_void |
C 类型的 Rust 表示:
// C 类型
enum tag { FLOAT = 0, INT =1, };
union number { float f; short i; };
struct tagged_number { tag t; number n; };
// 对应的 Rust 类型
#[repr(C)] // #[repr(i16)] 表示使用 int16 来保存 enum
#[allow(non_camel_case_types)]
enum Tag { Float = 0, Int = 1 }
#[repr(C)]
union FloatOrInt { f: f32, i: i32, }
#[repr(C)]
struct Value { tag: Tag, union: FloatOrInt }
#[repr(C)]
pub struct git_error {
pub message: *const c_char,
pub klass: c_int
}
fn is_zero(v: Value) -> bool {
use self::Tag::*;
unsafe {
match v {
Value { tag: Int, union: FloatOrInt { i: 0 } } => true,
Value { tag: Float, union: FloatOrInt { f: num } } => (num == 0.0),
_ => false }
} }
Rust 的 extern block 中的代码使用 C 惯例来传参和返回值, 都是 unsafe 函数.
use std::os::raw::c_char;
extern {
// 使用 Rust 的 raw pointer 来表示 C 函数的指针
fn strlen(s: *const c_char) -> usize;
static environ: *mut *mut c_char; // C 库中的全局变量 extern char **environ;
}
// 然后就可以调用 extern block 中的函数:
use std::ffi::CString;
// 从 Rust &str 创建 CString,然后转换为 *const c_char 类型,传递给 C 函数
let rust_str = "I'll be back";
let null_terminated = CString::new(rust_str).unwrap();
unsafe {
assert_eq!(strlen(null_terminated.as_ptr()), 12);
if !environ.is_null() && !(*environ).is_null() {
let var = CStr::from_ptr(*environ);
println!("first environment variable: {}", var.to_string_lossy())
}
}
通过 #[link] 来链接指定库的变量或函数:
use std::os::raw::c_int;
// Rust 使用系统连接器,如 linux 的 ld, 传递 -lgit2 参数
#[link(name = "git2")]
extern {
pub fn git_libgit2_init() -> c_int;
pub fn git_libgit2_shutdown() -> c_int;
}
fn main() {
unsafe {
git_libgit2_init();
git_libgit2_shutdown();
}
}
如果 git2 lib 被安装到非系统库目录, 则 Rust 编译器调用 ld 时可能会找不到该库, 解决办法是使用 build
script: 在 Cargo.toml 文件的同级目录下创建名为 build.rs 文件, 内容如下:
- build.rs 输出供后续 cargo build 所需的编译参数字符串,例如上面输出的是链接 C 库时搜索的目录。
fn main() {
println!(r"cargo:rustc-link-search=native=/home/jimb/libgit2-0.25.1/build");
}
上面只解决了链接时查找共享库的问题, 在运行时有可能还是找不到动态库,解决办法是设置环境变量:
export LD_LIBRARY_PATH=/home/jimb/libgit2- 0.25.1/build:$LD_LIBRARY_PATH
对于 Mac 而言是设置 DYLD_LIBRARY_PATH.
对于 Rust 而言, 如果一个 crate 是专用于调用 C 库的 Rust 代码, 则该 crate 的命名惯例是 LIB-sys , 其中
LIB 是 C 库的名称. 该 crate 中的内容:
- C 库(动态或静态) 文件;
- 在 extern block 中声明的 C 库中的变量或函数的 Rust 表示;
bindgen crate 提供了根据 C 库 header 文件自动生成 Rust extern block 的功能;
#![allow(non_camel_case_types)]
use std::os::raw::{c_int, c_char, c_uchar};
#[link(name = "git2")]
extern {
pub fn git_libgit2_init() -> c_int;
pub fn git_libgit2_shutdown() -> c_int;
pub fn giterr_last() -> *const git_error;
pub fn git_repository_open(out: *mut *mut git_repository, path: *const c_char) -> c_int;
pub fn git_repository_free(repo: *mut git_repository);
pub fn git_reference_name_to_id(out: *mut git_oid, repo: *mut git_repository, reference: *const c_char) -> c_int;
pub fn git_commit_lookup(out: *mut *mut git_commit, repo: *mut git_repository, id: *const git_oid) -> c_int;
pub fn git_commit_author(commit: *const git_commit) -> *const git_signature;
pub fn git_commit_message(commit: *const git_commit) -> *const c_char;
pub fn git_commit_free(commit: *mut git_commit);
}
#[repr(C)]
pub struct git_repository {
_private: [u8; 0]
}
#[repr(C)]
pub struct git_commit {
_private: [u8; 0]
}
#[repr(C)]
pub struct git_error {
pub message: *const c_char,
pub klass: c_int
}
pub const GIT_OID_RAWSZ: usize = 20;
#[repr(C)]
pub struct git_oid {
pub id: [c_uchar; GIT_OID_RAWSZ]
}
pub type git_time_t = i64;
#[repr(C)]
pub struct git_time {
pub time: git_time_t,
pub offset: c_int
}
#[repr(C)]
pub struct git_signature {
pub name: *const c_char,
pub email: *const c_char,
pub when: git_time
}
use std::ffi::CStr;
use std::os::raw::c_int;
fn check(activity: &'static str, status: c_int) -> c_int {
if status < 0 {
unsafe {
let error = &*raw::giterr_last();
println!("error while {}: {} ({})",
activity,
CStr::from_ptr(error.message).to_string_lossy(),
error.klass);
std::process::exit(1);
}
}
status
}
check("initializing library", raw::git_libgit2_init());
unsafe fn show_commit(commit: *const raw::git_commit) {
let author = raw::git_commit_author(commit);
let name = CStr::from_ptr((*author).name).to_string_lossy();
let email = CStr::from_ptr((*author).email).to_string_lossy();
println!("{} <{}>\n", name, email);
let message = raw::git_commit_message(commit);
println!("{}", CStr::from_ptr(message).to_string_lossy());
}
// 主程序
use std::ffi::CString; use std::mem;
use std::ptr;
use std::os::raw::c_char;
fn main() {
let path = std::env::args().skip(1).next().expect("usage: git-toy PATH");
let path = CString::new(path).expect("path contains null characters");
unsafe {
check("initializing library", raw::git_libgit2_init());
let mut repo = ptr::null_mut();
check("opening repository", raw::git_repository_open(&mut repo, path.as_ptr()));
let c_name = b"HEAD\0".as_ptr() as *const c_char;
let oid = {
let mut oid = mem::MaybeUninit::uninit(); // 创建一个未初始化的内存区域
check("looking up HEAD", repo, c_name));
};
raw::git_reference_name_to_id(oid.as_mut_ptr(), oid.assume_init()
};
let mut commit = ptr::null_mut();
check("looking up commit", raw::git_commit_lookup(&mut commit, repo, &oid));
show_commit(commit);
raw::git_commit_free(commit);
raw::git_repository_free(repo);
check("shutting down library", raw::git_libgit2_shutdown());
}
C 常见的情况是, 传递一个指针, 然后函数内的逻辑来修改指针指向的内容. Rust 提供了
std::mem::MaybeUninit<T> 类型, 他告诉编译器为 T 分配内存, 但是不做任何处理, 直到后续明确告诉他可以安全地操作这一块内存区域. MaybeUninit<T> 拥有这一块内存区域, 编译器不会做一些优化和操作, 从而避免非预期的行为:
- MaybeUninit.as_mut_ptr() 返回这个内存区域的 *mut T 指针, 可以将他传递给 FFI 函数使用;
- 然后调用 MaybeUninit.assume_init() 来将内存区域标记为已初始化;
也可以将 Rust 代码编译为 C 动态库,然后被其它 Rust 程序或 C/C++ 等程序调用,这需要在 Rust 函数签名前添加:extern “C”,以及 #[no_mangle] 属性
- #[no_mangle] 用于指示 Rust 编译器不要对该函数改名,从而让其它语言能正确识别该 Rust 函数。
- 该 Rust 函数不需要标记为 unsafe。
#[no_mangle]
pub extern "C" fn call_from_c() {
println!("Just called a Rust function from C!");
}
如果是 Rust 程序调用 C 库函数,可以使用 dlopen2 crate。
27.1 How to build a plugin system in Rust #
https://www.arroyo.dev/blog/rust-plugin-systems#implementing-a-c-interface
Implementing a C interface
So how do you go about building a C ABI in Rust? There are a number of limitations and rules to follow to safely call functions over a C FFI boundary.
Designing our types
The first thing we need to think about is data—the stuff getting passed between the host and plugin
code. Rust gives us many powerful tools for modeling data, including structs, enums, tuples, various
data structures… and we’re going to have to give nearly all of them up. To correctly and reliably
pass data over a C FFI boundary, we have to follow some very limiting rules.
Rule 1: repr(C)
Our first issue is that Rust’s data layout is ABI dependent, and can (and does) change with
different versions of the compiler. So we get to the first rule of building a C interface: all data needs to be #[repr(C)] .
At this point I’d like to introduce an extremely helpful resource for anyone straying from the cosy, warm cottage of safe Rust and out into the deep dark night of unsafe: the Rustonomicon. It helpfully disclaims responsibility for potentially “UNLEASHING INDESCRIBABLE HORRORS THAT SHATTER YOUR PSYCHE AND SET YOUR MIND ADRIFT IN THE UNKNOWABLY INFINITE COSMOS.”
With that warning in mind, its section on data layout and repr can be found here.
Repr annotations allow developers to specify specific data layouts for structs and enums, where the
default is “whatever the Rust compiler wants to do and thinks is efficient.” There are several
support layouts, but the rules for repr(C) is pretty simple: just do whatever C does. A
lovecraftian monster
Staring too long into the abyss of unsafe Rust can have interesting consequences
To use alternative representations, we can create a data type (struct or enum) and annotate it like this:
#[repr(C)]
struct MyData {
a: f32,
b: i64,
c: u8
}
This struct demonstrates why #[repr(C)] is important. Compiling this code using the nightly-only
rustc option -Zprint-type-sizes we can see that we end up with completely different layouts for
#[repr(Rust)] and #[repr(C)]:
// #[repr(Rust)]
print-type-size type: `MyData`: 16 bytes, alignment: 8 bytes
print-type-size field `.b`: 8 bytes
print-type-size field `.a`: 4 bytes
print-type-size field `.c`: 1 bytes
// #[repr(C)]
print-type-size type: `MyData`: 24 bytes, alignment: 8 bytes
print-type-size field `.a`: 4 bytes
print-type-size padding: 4 bytes
print-type-size field `.b`: 8 bytes, alignment: 8 bytes
print-type-size field `.c`: 1 bytes
print-type-size end padding: 7 bytes
In fact, the Rust representation is much more efficient, taking up only 16 bytes instead of 24 bytes
for the C representation. This is because Rust is free to reorder the fields to reduce the number of
padding bytes needed to align to 8 bytes. C on the other hand will always lay out fields in order
with predictable padding rules, which we see in the second version.
That example struct stuck to simple, primitive data types. And that leads into rule number 2:
Rule 2: all data must be FFI safe
While #[repr(C)] allows us to create structs and enums that can be passed across an FFI boundary, that property is not recursive—that is, it controls the layout of fields within the struct, but doesn’t affect the representation of the fields themselves.
In fact, we are quite limited in what data types are FFI safe. This is not a well documented area of
Rust, but an incomplete list of FFI safe types includes:
- Primitive Types: u8, u16, u32, u64, i8, i16, i32, i64, usize, isize, f32, f64, and bool.
- Pointers:
Raw pointersconst T and mut T; safe wrappers for nullable pointers like Option<NonNull<T>> - C-compatible Enums: Enums with explicitly defined repr(C).
- C-compatible Structs: Structs with repr(C) and containing only FFI-safe types.
- Slices: [T], const [T], and mut [T] when length is provided separately.
So no passing String, Vec, HashMap, or random data types from your favorite Rust crate. However, we
do have tools for passing some useful types of data with a little bit of transformation. The
std::ffi package includes CString and CStr which are owned and borrowed null-terminated C-style
strings. Similarly, we can pass Vec by converting it into a raw pointer + length + capacity and then
back again.
Exporting functions
Once we’ve decided on our data types, we’re ready to design our actual API, by exporting C-compatible functions. A C FFI function is a bare Rust function with
- A
#[no_mangle]annotation, which tells rustc to name the symbol asexactly the function name, instead of rewriting it (or “mangling”) to ensure uniqueness and include useful metadata - The
extern "C"keyword, which tells rustc toexport the function for external use using the C ABIAll arguments and a return type that are FFI safe3, as described above
So putting that together, we can export a C FFI function with the following definition
#[no_mangle]
extern "C" fn add(a: u32, b: u32) -> u32 {
a + b
}
Within the plugin code, we can use almost any Rust construct or features, so long as nothing leaks into the type signature.
The biggest exception is panic. Rust’s default panicking behavior is unwinding, which means we
travel up the call stack until we hit either a catch_unwind call (which stops the unwinding) or the
top stack frame for the thread, in which case the thread exits. But this is a Rust-specific feature,
part of the unstable Rust ABI. Unwinding can't cross a C FFI boundary without risking undefined
behavior.
The words 'Don't Panic'
And important rule for hitchhiking across the galaxy and crossing FFI boundaries
There are two ways to handle this: either we need to compile our plugin code with panic='abort'
(which causes the process to terminate on panic) or we need to ensure that the plugin cannot panic. But even if we can ensure our own code is panic-free4, how can we make sure our
plugin-writing-users do the same?
One answer is to use a plugin interface with a top-level catch_unwind call that converts panics into
an Error enum across the FFI boundary.
Compiling our plugin
Our plugin will be a library crate that’s built as a shared object, in a binary format that depends
on our operating system (.so on Linux, .dll on Windows, .dylib on MacOS).
By default, Rust compiles libraries as an rlib artifact, which is a Rust-specific static library
format. To tell it to instead build a dynamic system library that can be linked by other languages,
we’ll use the cdylib type. This can be specified in a Cargo.toml by setting the lib.crate-type
option, like this:
[package]
name = "my-plugin"
version = "1.0.0"
edition = "2021"
[lib]
crate-type = ["cdylib"]
Calling FFI functions
There are two different ways we might link and call plugin code across an FFI: at program start
time, or dynamically as the program is executing. In either case, we’ll use the extern keyword again
but without a function body in order to tell the host side what the function signature is.
If we know the name of the library at compile time, Rust provides built-in support for loading system libraries using the [link] annotation. It looks like this:
#[link(name = "my_plugin")]
extern "C" {
fn add(a: u32, b: u32) -> u32;
}
fn main() {
unsafe { add(1, 5) };
}
Rust will look for a shared library with the name my_plugin (for example, on Linux it will look for /usr/lib/my_plugin.so, /usr/local/lib/my_plugin.so, etc.) and attempt to link it at program start time, and will fail if it can’t find the library. The function can be called like any other (unsafe) Rust function5.
But for a plugin system, having to know the name of the library at compile time (and ensuring that
it’s installed in a system location) is somewhat limiting. Instead, we can turn to dynamic loading.
The interfaces for dynamic library loading are OS-specific, but there are several crates that can
handle the cross-platform boilerplate for us. The two most popular are libloading and dlopen2. For
Arroyo we decided to use dlopen2 which has a nicer interface and stronger guarantees around thread
safety.
In dlopen2, we can define structs for each of our plugin interfaces. They look like this:
#[derive(WrapperApi)]
pub struct PluginInterface {
add: extern "C" fn(a: u32, b: u32) -> u32,
}
// A plugin can be loaded and called like this:
let container: Container<PluginInterface> = unsafe {
Container::load(dylib_path).unwrap()
};
unsafe { container.add(1, 3) }
Putting it all together
So that was a lot of theory. Let’s put it into practice with a complete example! We’ll be working off a (very simplified) example plugin system found in this repo. Clone it locally to try this out yourself. https://github.com/mwylde/rust-plugin-tutorial
The code is divided into two parts: the plugin, which compiles to a shared object, and the host,
which loads the plugin. (In a real system, you’d likely want a few more components, including a
common library to share definitions between the plugin and host, and a macro to do code generation,
but we’re keeping this relatively simple.)
Designing the interface
Before we can start writing code, we need to decide on the contract between the plugin and the
host. For this example, we’ll adopt a flexible contract that supports a variable number of arguments
of various common data types, as would be needed for a UDF system.
The plugin interface has two methods:
extern "C" fn plugin_metadata() -> PluginMetadata,
extern "C" fn plugin_entrypoint(args: *const PluginValue, args_len: usize) -> PluginResult
The metadata function is called by the host to determine the number and types of the arguments the
plugin expects, and the type of the data it returns, while the entrypoint function is called to
actually execute the plugin’s logic.
As discussed in detail above, all of our data types need to be FFI-safe. For example, the
PluginMetadata type looks like this:
#[repr(C)]
#[derive(Copy, Clone)]
pub enum PluginType {
Bool,
Int,
UInt,
Double,
String,
}
#[repr(C)]
pub struct PluginMetadata {
// should have a static lifetime
pub name: *const i8,
pub arg_types: *const PluginType, // Vec<PluginType> 内存区域的指针
pub arg_types_len: usize, // Vec 中对象数量
pub return_type: PluginType,
}
Note that instead of of passing a String for the name, we pass a *const i8, which represents a
null-terminated C-style string. Instead of a Vec<PluginType> for the args, we pass a pointer to some memory and a length.
For the entrypoint function, we’ll need to pass our actual data to the plugin. That relies on an array of values of the type PluginValue:
#[repr(C)]
pub enum PluginValue {
Bool(bool),
Int(i64),
UInt(u64),
Double(f64),
// All strings are owned by the host
String(*const i8),
}
For primitives, we can use them as-is as all Rust primitives are FFI-safe. However, strings again
need special attention. We have two typical options for passing strings: we can pass Rust-style
strings (with an array of chars and a length) or C-styles strings (whose end is determined by a null
byte). While the former are much safer and generally preferred in modern APIs, for C interfaces the
latter is more common as it’s more easily supported by languages with a C FFI.
Beyond the format of the data, we also need to consider ownership6. Once memory is allocated,
exactly one part of our code (in this case, one side of the host/plugin divide) needs to own that
memory. PluginValues are both created by the host (to provide data) and by the plugin (to return its
result), but to simplify the memory management we have documented that in both cases the host owns the memory and is responsible for freeing it. This does mean the plugin code needs to be careful
never to create an owned-object from the memory (in this case, a CString) which would free it on
drop.
Finally, we have our return type, which is just an FFI-safe Result type with a CString error message:
#[repr(C)]
pub enum PluginResult {
Ok(PluginValue),
// Null-terminated c-string; he host is responsible for freeing this value
Err(*mut i8),
}
Now that we have our common interface, let’s see how they’re used. We’ll start with the plugin.
We’re using two different types of raw pointers here: *mut and *const. Why is that? What’s the
difference? In the context of FFI, the answer is: not much. The choice of mut vs const doesn’t
affect the generated code, and you can freely cast between them.
However, they are useful for documenting intent and ownership across an FFI boundary. Using *const tells the calling code that they shouldn’t modify the data behind the pointer, and probably shouldn’t free it, while *mut indicates that it’s ok to modify the data and can also communicate ownership.
We’re playing a bit fast-and-loose here, because we’re using a single data type (PluginValue) for both our arguments—which the host creates and owns—and our return value, which the plugin creates but transfers to the host, so we opt for *const to tell the plugin not to modify or free its arguments. However, on the host side we then have to cast it to *mut so that we can take ownership.
The plugin
We’re going to implement a simple plugin that takes in two arguments, a string and a number, and will return the string repeated that number of times: f(“cool”, 3) ⇒ “coolcoolcool” .
The plugin is responsible for building a shared library, so we need to tell Cargo that’s what we
want. We do that by specifying the crate type as cdylib, a C-compatible dynamic library. Our
Cargo.toml looks like this:
[package]
name = "plugin"
version = "0.1.0"
edition = "2021"
[lib]
crate-type = ["cdylib"]
Next is our src/lib.rs file. This will contain implementations of the plugin interface documented above.
The first function we need to implement is plugin_metadata(), which is pretty straightforward, telling the host about our arguments and our return type:
#[no_mangle]
pub extern "C" fn plugin_metadata() -> PluginMetadata {
PluginMetadata {
name: "repeat\0".as_ptr() as *const i8,
arg_types: [PluginType::String, PluginType::UInt].as_ptr(),
arg_types_len: 2,
return_type: PluginType::String,
}
}
Next we’ll implement our plugin’s unique logic, in this case repeating a string N times. I find it easiest to separate this out from the boilerplate that’s involved in converting to and from FFI types, so that when we’re developing the logic we can stay in safe, normal Rust land.
fn repeat_impl(input: &str, count: u64) -> String {
input.repeat(count as usize)
}
Nice and simple. Unfortunately, we still need the complex code to bridge the FFI and Rust worlds. For this example, it looks like this:
#[no_mangle]
pub extern "C" fn plugin_entrypoint(args: *const PluginValue, args_len: usize) -> PluginResult {
// first we need to check if the arguments are valid
if args_len != 2 {
return plugin_error("args_len should be 2");
}
let PluginValue::String(string) = (unsafe { &*args.offset(0) }) else {
return plugin_error("arg0 is invalid; expected String");
};
let PluginValue::UInt(count) = (unsafe { &*args.offset(1) }) else {
return plugin_error("arg1 is invalid; expected UInt");
};
let string = match unsafe { CStr::from_ptr(*string) }.to_str() {
Ok(value) => value,
Err(_) => {
return plugin_error("arg0 is invalid; expected valid UTF-8 string");
}
};
// then we can call our logic with the converted arguments and re-wrap them in our Result type,
// catching any panics that might occur so that they don't cross the FFI boundary
match catch_unwind(|| repeat_impl(string, *count)) {
Ok(value) => PluginResult::Ok(
PluginValue::String(CString::new(value).unwrap().into_raw())),
Err(_) => plugin_error("function panicked"),
}
}
Making your users write all of this unsafe boilerplate for every plugin isn’t great UX, so you may
want to use a macro or just wrapper code (if you don’t need to support multiple types). You can see
the macro for the Arroyo plugin system
here.
https://github.com/ArroyoSystems/arroyo/blob/master/crates/arroyo-udf/arroyo-udf-macros/src/lib.rs
The host
The Host from ‘The Host’
The host is a normal Rust application, created with cargo new. It has one dependency, dlopen2, which
we’ll use to dynamically load our plugin:
[dependencies]
dlopen2 = { version = "0.7.0", features = ["derive"] }
The meat is in src/main.rs, which builds our binary. We need to repeat the definitions (or include them from a common library), but we’ll also include one more, an owned version of PluginValue:
pub enum OwnedPluginValue {
Bool(bool),
Int(i64),
UInt(u64),
Double(f64),
String(CString),
}
impl PluginValue {
pub fn to_owned(self) -> OwnedPluginValue {
match self {
PluginValue::Bool(b) => OwnedPluginValue::Bool(b),
PluginValue::Int(i) => OwnedPluginValue::Int(i),
PluginValue::UInt(u) => OwnedPluginValue::UInt(u),
PluginValue::Double(d) => OwnedPluginValue::Double(d),
PluginValue::String(s) => {
OwnedPluginValue::String(
unsafe { CString::from_raw(s as *mut i8) })
}
}
}
}
This owned struct will allow us to ensure that values returned from the plugin (and the arguments we
send it) are eventually freed.
Next, we’ll define the plugin interface using dlopen2’s WrapperApi macro:
#[derive(WrapperApi)]
struct PluginApi {
plugin_metadata: unsafe extern "C" fn() -> PluginMetadata,
plugin_entrypoint: unsafe extern "C" fn(args: *const PluginValue, args_len: usize) -> PluginResult,
}
This let’s us conveniently bundle up all of the plugin functions into a struct which we can store and pass around our application.
Now we’re ready to load the plugin and call it. I’ll spare you the details of CLI argument processing (which you can see in the full example file). Here’s the meat of it:
// load the plugin via the dlopen2's Container API
let container: Container<PluginApi> = unsafe { Container::load(&args[1]) }.expect("Could not load plugin");
// get the metadata, which will tell us which arguments to expect
let metadata: PluginMetadata = unsafe { container.plugin_metadata() };
// read the arguments from the command line
let mut call_args: Vec<PluginValue> = vec![];
for (i, arg) in args[2..].iter().enumerate() {
match unsafe { *metadata.arg_types.add(i) } {
PluginType::Bool => {
call_args.push(PluginValue::Bool(
arg.parse().expect("Invalid bool")))
}
//...
}
}
// call the plugin function
let result = unsafe {
container.plugin_entrypoint(call_args.as_ptr(), call_args.len())
};
// take ownership and drop the arguments to free their memory
drop(call_args.into_iter().map(|t| t.to_owned()));
// print out the result or error to the user
match result {
PluginResult::Ok(value) => {
println!("Plugin returned: {}", value.to_owned());
}
PluginResult::Err(err) => {
eprintln!("{}", unsafe { CString::from_raw(err) }.to_string_lossy());
std::process::exit(1);
}
}
Let’s plug in some stuff!!!
Here we are. After more than 5000 words, we’re going to actually dynamically load some Rust code. A hand plugging a plug into a socket
uhh… not like that
If you want to follow along, check out the example repo
$ git clone https://github.com/mwylde/rust-plugin-tutorial.git
Then we’re going to build both the plugin and host
$ cd rust-plugin-tutorial/plugin && cargo build
$ cd ../host && cargo build
Now we should have a dynamic library in plugin/target/debug and a host binary in host/target/debug. The dynamic library will be named something like “libplugin.dylib,”“libplugin.so,” or “libplugin.dll” depending on your operating system. Note which it is, then invoke the host like this:
$ host/target/debug/host plugin/target/debug/libplugin.dylib cool 3
Loaded plugin repeat
Plugin returned: coolcoolcool
If all went well, you should see the output from your plugin code (and no pesky segfaults).
Wrapping up
So that’s the background for how we built our plugin system, and how you can build your own.
Recapping a bit:
- We defined our data types as enums and structs of FFI-safe types
- We defined a plugin interface, as #[no_mangle] extern “C” functions consuming and returning those data types
- We used dlopen2 to load and call our plugin interface from the host
In part 2 of this series, we’ll cover how this works in a real, production plugin system, including support for async functions. (If you’re impatient, all of the code can be found here.)
28 testing #
Rust 提供了如下测试类型:
- Unit testing;
- Doc testing;
- Integration testing;
Rust 的 Cargo.toml 中为 testing 提供了单独的依赖配置: dev-dependencies
# standard crate data is left out
[dev-dependencies]
pretty_assertions = "1"
Unit testing: 单元测试即函数:
- 使用 #[cfg(test)] 来注解 test module,该 module 在 cargo build 时会被忽略(减少代码体积),而只有运行 cargo test 时才被编译和执行;
- 使用 #[test] 来注解 test 函数;
- test 函数内部使用 assert!()/assert_eq!()/assert_ne!()/Result 等来报告错误,assert 宏支持格式化字符串消息。
- 单元测试 module/func 和源码在同一个文件或目录, 运行测试 private code(但是集成测试在不同 crate, 只能测试 public 接口);
pub fn add(a: i32, b: i32) -> i32 {
a + b
}
// This is a really bad adding function, its purpose is to fail in this example.
#[allow(dead_code)]
fn bad_add(a: i32, b: i32) -> i32 {
a - b
}
#[cfg(test)]
mod tests {
// Note this useful idiom: importing names from outer (for mod tests) scope.
use super::*;
#[test]
fn test_add() {
assert_eq!(add(1, 2), 3);
}
#[test]
fn test_bad_add() {
// This assert would fire and test will fail.
// Please note, that private functions can be tested too!
assert_eq!(bad_add(1, 2), 3);
}
}
使用 cargo test 来运行测试:
$ cargo test
running 2 tests
test tests::test_bad_add ... FAILED
test tests::test_add ... ok
failures:
---- tests::test_bad_add stdout ----
thread 'tests::test_bad_add' panicked at 'assertion failed: `(left == right)`
left: `-1`,
right: `3`', src/lib.rs:21:8
note: Run with `RUST_BACKTRACE=1` for a backtrace.
failures:
tests::test_bad_add
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out
Rust 2018 版本的单元测试函数支持返回 Result 来报错, 这样可以使用 ?
fn sqrt(number: f64) -> Result<f64, String> {
if number >= 0.0 {
Ok(number.powf(0.5))
} else {
Err("negative floats don't have square roots".to_owned())
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn test_sqrt() -> Result<(), String> {
let x = 4.0;
assert_eq!(sqrt(x)?.powf(2.0), x);
Ok(())
}
}
单元测试也支持 panic!() , 使用 expected 匹配 panic 消息的字符串;
pub fn divide_non_zero_result(a: u32, b: u32) -> u32 {
if b == 0 {
panic!("Divide-by-zero error");
} else if a < b {
panic!("Divide result is zero");
}
a / b
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn test_divide() {
assert_eq!(divide_non_zero_result(10, 2), 5);
}
#[test]
#[should_panic]
fn test_any_panic() {
divide_non_zero_result(1, 0);
}
#[test]
#[should_panic(expected = "Divide result is zero")]
fn test_specific_panic() {
divide_non_zero_result(1, 10);
}
}
也可以为 test 函数添加 #[ignore] 来忽略测试:
- 在常规 cargo test 时忽略这些 test。可以使用 cargo test – –ignored 来只运行这些被忽略的测试。
pub fn add(a: i32, b: i32) -> i32 {
a + b
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn test_add() {
assert_eq!(add(2, 2), 4);
}
#[test]
fn test_add_hundred() {
assert_eq!(add(100, 2), 102);
assert_eq!(add(2, 100), 102);
}
#[test]
#[ignore]
fn ignored_test() {
assert_eq!(add(0, 0), 0);
}
}
Rsut 源码中的 document comment 使用 Markdown 语法, 支持嵌入代码块, 这些代码别编译和文档测试:
/// First line is a short summary describing function.
///
/// The next lines present detailed documentation. Code blocks start with
/// triple backquotes and have implicit `fn main()` inside
/// and `extern crate <cratename>`. Assume we're testing `doccomments` crate:
///
/// ```
/// let result = doccomments::add(2, 3);
/// assert_eq!(result, 5);
/// ```
pub fn add(a: i32, b: i32) -> i32 {
a + b
}
/// Usually doc comments may include sections "Examples", "Panics" and "Failures".
///
/// The next function divides two numbers.
///
/// # Examples
///
/// ```
/// let result = doccomments::div(10, 2);
/// assert_eq!(result, 5);
/// ```
///
/// # Panics
///
/// The function panics if the second argument is zero.
///
/// ```rust,should_panic
/// // panics on division by zero
/// doccomments::div(10, 0);
/// ```
pub fn div(a: i32, b: i32) -> i32 {
if b == 0 {
panic!("Divide-by-zero error");
}
a / b
}
单元测试 module/func 和源码在同一个文件, 特殊允许测试 private code. 但是集成测试在不同 crate, 只能测试 public 接口, 集成测试的代码位于 tests 目录下:
- 由于是会编译为单独的 binary,所以不需要像单元测试那样 使用#[cfg(test)] 来区分 test 代码。
// src/lib.rs
// Define this in a crate called `adder`.
pub fn add(a: i32, b: i32) -> i32 {
a + b
}
// tests/integration_test.rs
#[test]
fn test_add() {
assert_eq!(adder::add(3, 2), 5);
}
pub fn add_two(a: i32) -> i32 {
internal_adder(a, 2)
}
fn internal_adder(a: i32, b: i32) -> i32 {
a + b
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn internal() {
assert_eq!(4, internal_adder(2, 2));
}
}
集成测试:
- 集成测试是完全位于被测试 crate 的外部,目的是测试被测试库的多个部分能否正确的一起工作,所以覆盖率很重要;
- 集成测试位于 tests 目录下,各文件对应一个单独的集成测试,可以包含子 module。
// tests/common/mod.rs:
pub fn setup() {
// some setup code, like creating required files/directories, starting
// servers, etc.
}
// tests/integration_test.rs
// importing common module.
mod common;
// 不再需要 #cfg[test] 注解了。
#[test]
fn test_add() {
// using common code.
common::setup();
assert_eq!(adder::add(3, 2), 5);
}
cargo test 时默认使用 多线程并发运行 所有测试(单元+集成)函数,同时也会运行 doc comment 中的测试:
- cargo test
会生成一个可执行程序,所以为 cargo test 指定参数时,包含两部分:- cargo test 命令本身的参数:直接放到 test 命令后;
- 编程生成的 test 程序的参数:放到 – 分割符号后面,如 cargo test – –ignored;
例如:
- 运行匹配关键字的特殊函数/module 名称:cargo test KEYWORD,注意只能指定一个关键字;
- 单线程运行测试任务:cargo test – –test-threads=1
- test 时默认捕获 println!() 输出,只有当 test 出错时才显示。可以指定 cargo test – –nocapture 来不捕获函数输出,显示所有内容。
- cargo test – –ignored:只运行被忽略的测试。
- 只运行指定文件中的集成测试:cargo test –test integrated_test_file_name
$ cargo test
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out
Doc-tests doccomments
running 3 tests
test src/lib.rs - add (line 7) ... ok
test src/lib.rs - div (line 21) ... ok
test src/lib.rs - div (line 31) ... ok
test result: ok. 3 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out
如果项目只有 binary 而没有 lib,则不能运行集成测试,解决办法是将 binary 中的逻辑拆解到 lib 中。
参考:
29 unsafe #
unsafe {} 块注解用于指示编译器忽略一些严格的安全检查(而不是忽略所有检查), 主要使用场景:
- 解构 raw pointers;
- 调用 FFI 函数;
- 调用 unsafe 函数或方法;
- 存取 static mut 全局变量;
- 实现 unsafe trait;
通过使用 unsafe 关键字,可以将 Rust 安全代码和非安全代码建立边界,调用者或开发者需要关注非安全代码的使用前提和影响,从而确保使用时没有未定义的行为。
- 一般来说 unsafe fun/block/trait 都是有特殊的使用前提的,使用方需要保证满足这些约束,防止出现未定义的行为。
- 调用 unsafe 代码带来的影响可以在调用前后,调用前:没有满足 unsafe 代码的前提约束, 调用后:unsafe 代码的结果是不可信的、未定义的,对程序后续的逻辑或功能都有影响;
- 尽量使用安全代码,这样 Rust 的编译器、type checker、borrow checker 和其他的静态 checker会详细检查代码的合法性,但是 unsafe 代码不会有这些安全性优势,需要开发者自己来保证。
raw pointer:
fn main() {
let mut a: usize = 0;
let ptr = &mut a as *mut usize;
unsafe {
*ptr.offset(3) = 0x7ffff72f484c;
}
}
// $ cargo build
// Compiling unsafe-samples v0.1.0
// Finished debug [unoptimized + debuginfo] target(s) in 0.44s
// $ ../../target/debug/crash
// crash: Error: .netrc file is readable by others.
// crash: Remove password or make file unreadable by others. Segmentation fault (core dumped)
unsafe block:
- 可以调用 unsafe 函数;
- 可以解引用 raw pointer;(安全代买可以创建、转移、比较 raw pointer,但是不能解引用和赋值 raw pointer);
- 访问 union 类型的 field;
- 访问 static mut 变量;
- 使用 FFI 访问其他语言函数库定义的变量、类型和函数;
unsafe {
String::from_utf8_unchecked(ascii) // from_utf8_unchecked 是 unsaft 函数,只能在 unsafe 上下文中调用
}
// 想要调用的外部函数接口
extern "C" {
fn abs(input: i32) -> i32;
}
fn main() {
unsafe {
println!("Absolute value of -3 according to C: {}", abs(-3));
}
}
// 读写可变静态变量都需要使用 unsafe block/function
static mut COUNTER: u32 = 0;
fn add_to_count(inc: u32) {
unsafe {
COUNTER += inc;
}
}
fn main() {
add_to_count(3);
unsafe {
println!("COUNTER: {}", COUNTER);
}
}
unsafe function 是添加了 unsafe 标识的函数,它的 body 对应是 unsafe block。
- unsafe 和普通函数完全一样,只是用 unsafe 标记后,表示调用该函数需要满足一些先决条件。
- 只能治啊 unsafe function/block 中调用 unsafe 函数。
pub unsafe fn from_bytes_unchecked(bytes: Vec<u8>) -> Ascii {
Ascii(bytes)
}
// 使用 unsafe 特性实现的安全函数
use std::slice;
fn split_at_mut(slice: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32]) {
let len = slice.len();
let ptr = slice.as_mut_ptr();
assert!(mid <= len);
unsafe {
(slice::from_raw_parts_mut(ptr, mid),
slice::from_raw_parts_mut(ptr.offset(mid as isize), len - mid))
}
}
use std::slice;
let address = 0x01234usize;
let r = address as *mut i32;
let slice : &[i32] = unsafe {
slice::from_raw_parts_mut(r, 10000)
};
常见的做法是:将 unsafe block 封装在 safe 函数中。
unsafe trait 是添加了 unsafe 标识的 trait,在 impl 它时,也必须添加 unsafe 标识:
- unsafe trait 实际上是表明该 trait 的定义或实现有一些前提约束,Rust 编译器无法检查,需要开发者来保证。
// 定义 unsafe trait
pub unsafe trait Zeroable {}
// 实现 unsafe trait
unsafe impl Zeroable for u8 {}
unsafe impl Zeroable for i32 {}
unsafe impl Zeroable for usize {}
// and so on for all the integer types
// 使用 unsafe trait,不一定需要 unsafe 函数
use core::nonzero::Zeroable;
fn zeroed_vector<T>(len: usize) -> Vec<T> where T: Zeroable
{
let mut vec = Vec::with_capacity(len);
unsafe {
std::ptr::write_bytes(vec.as_mut_ptr(), 0, len);
vec.set_len(len);
}
vec
}
30 unsafe union #
union 是将一块内存区域可以按照不同的类型进行解释的类型:
union FloatOrInt {
f: f32,
i: i32,
}
在创建 union 对象时,必须指定某一个 field,但是后续可以按照其他 field 的类型来解释以前给 union 的赋值:
let mut one = FloatOrInt { i: 1 };
assert_eq!(unsafe { one.i }, 0x00_00_00_01);
one.f = 1.0;
assert_eq!(unsafe { one.i }, 0x3F_80_00_00);
union 类型的大小取决于最大 field 的空间需求,比如下面 union 的大小为 64 bytes:
union SmallOrLarge {
s: bool,
l: u64
}
必须在 unsafe 中访问 union field:
let u = SmallOrLarge { l: 1337 };
println!("{}", unsafe {u.l}); // prints 1337
这是由于 union 不像 enum,内存模型不包含 tag,所以编译器不知道存入和访问的字段值。
可以使用 #[repr(C)] 来设置 union 使用 C 的内存布局:
#[repr(C)]
union SignExtractor {
value: i64,
bytes: [u8; 8]
}
fn sign(int: i64) -> bool {
let se = SignExtractor { value: int};
println!( "{:b} ({:?})", unsafe { se.value }, unsafe { se.bytes });
unsafe { se.bytes[7] >= 0b10000000 }
}
assert_eq!(sign(-1), true);
assert_eq!(sign(1), false);
assert_eq!(sign(i64::MAX), false);
assert_eq!(sign(i64::MIN), true);
union 用不同的方式来解释同一块内存区域,编译器不知道如何 Drop union 对象,所以各 field 必须都必须是实现 Copy 的类型。如果要保存 String 类型,则可以参考 std::mem::ManuallyDrop。
可以使用 match pattern 来匹配 union,但是每个 pattern 只能包含一个 field:
- 如果只指定 filed 但是没有值,则一定可以匹配成功。
unsafe {
match u {
SmallOrLarge { s: true } => { println!("boolean true"); } // 如果按照 s 来解释,能够匹配 true
SmallOrLarge { l: 2 } => { println!("integer 2"); } // 如果按照 l 来解释,能够匹配 2
_ => { println!("something else"); }
}
}
borrow uinon 某个 filed 等效于 borrow 整个 union,所以在 borrow 某个 field 后就不能再 borrow 其他 field。