这是我的 C 语言个人参考手册。
变更历史
2024-05-24 Fri 首次创建
1 C 版本 #
__STDC_VERSION__ :
- C89/C90:没有定义 __STDC_VERSION__。
- C95:__STDC_VERSION__ 值为 199409L。
- C99:__STDC_VERSION__ 值为 199901L。
- C11:__STDC_VERSION__ 值为 201112L。
- C17/C18:__STDC_VERSION__ 值为 201710L。
使用 gcc 的 -std 选项来指定使用某个版本,如 -std=c90, -std=c99, -std=c11 or -std=c17 :
gcc -std=c11 -pedantic foo.c
gcc -Wall -Wextra -std=c2x -pedantic foo.c
1.1 C99 新增特性 #
C99 标准相较于 C89 标准引入了许多新特性,以下是一个完整列表:
- 新数据类型 :
- `long long int` 类型,至少 64 位。
- `_Bool` 类型,用于布尔值。
- `complex` 和 `imaginary` 类型,用于复数。
- 混合声明和代码 :允许在任何地方声明变量,而不仅限于代码块的开头。
- 复合字面量 :可以在任意位置创建匿名的数组或结构体实例。
- 可变长数组 :允许数组的长度在运行时确定。
- 变量声明的初始值设定项 :允许变量声明时直接初始化。
- 单行注释 :支持 `//` 单行注释。
- 新标准库函数 :
- 包含在 `<tgmath.h>` 中的泛型数学函数。
- 包含在 `<stdbool.h>` 中的布尔类型和常量。
- 包含在 `<complex.h>` 中的复数类型和函数。
- 包含在 `<stdint.h>` 中的固定宽度整数类型。
- 内联函数 :使用 `inline` 关键字定义内联函数。
- 新预处理器指令 :
- `#include` 指令支持通过 `<…>` 和 `""` 引入头文件。
- `_func_` 预定义标识符,表示当前函数的名称。
- 改进的浮点支持 :更好的浮点数支持、四舍五入控制和新的数学库函数。
- 变长宏参数 : 支持变长参数的宏定义。
- 指定初始化 : 允许在初始化数组和结构体时指定索引或成员。
- 变长数组 : 允许数组的长度在运行时确定。
- 支持 `restrict` 关键字 :用于指示指针是唯一访问某个数据对象的方式,以帮助优化。
- 支持 `_STDC_VERSION_` 宏 : 用于检查标准版本。
- 改进的输入输出函数 : 新增的格式化输入输出函数。
示例代码:
#include <stdio.h>
#include <stdbool.h>
#include <complex.h>
#include <tgmath.h>
#include <stdint.h>
// 复合字面量
struct Point {
int x, y;
};
// 内联函数
inline int square(int x) {
return x * x;
}
int main() {
// 混合声明和代码
for (int i = 0; i < 5; i++) {
printf("i = %d\n", i);
}
// 复合字面量
struct Point p = (struct Point){.x = 1, .y = 2};
printf("Point p: (%d, %d)\n", p.x, p.y);
// 可变长数组
int n = 5;
int arr[n];
for (int i = 0; i < n; i++) {
arr[i] = i * i;
}
for (int i = 0; i < n; i++) {
printf("arr[%d] = %d\n", i, arr[i]);
}
// _Bool 类型和 <stdbool.h> 头文件
_Bool flag = true;
printf("flag = %d\n", flag);
// 复数类型和 <complex.h> 头文件
double complex z = 1.0 + 2.0 * I;
printf("Complex z: %.2f + %.2fi\n", creal(z), cimag(z));
// 泛型数学函数
double result = sqrt(4.0);
printf("sqrt(4.0) = %.2f\n", result);
// 指定初始化
int arr2[5] = {[1] = 10, [3] = 20};
for (int i = 0; i < 5; i++) {
printf("arr2[%d] = %d\n", i, arr2[i]);
}
// 变长宏参数
#define PRINT(...) printf(__VA_ARGS__)
PRINT("This is a test: %d\n", 123);
return 0;
}
1.2 C11 新增特性 #
原子操作
- 提供了原子操作和锁自由编程的支持,通过 <stdatomic.h> 头文件。
- 使用 `_Atomic` 类型说明符和相关函数。
多线程支持
- 引入了多线程支持,通过 <threads.h> 头文件。
- 包括 `thrd_t` 类型、`mtx_t` 类型、`cnd_t` 类型等。
泛型选择
- 使用 `_Generic` 关键字,实现类型安全的泛型编程。
静态断言
- 使用 `_Static_assert` 关键字,在编译时进行断言检查。
对齐支持
- 提供了对齐支持,通过 `<stdalign.h>` 头文件。
- 使用 `alignas` 和 `alignof` 关键字。
变长数组的改进
- 更加严格的变长数组初始化和使用规则。
匿名结构体和联合体
- 允许在结构体和联合体中使用匿名成员。
增强的Unicode支持
- 提供了对Unicode字符的支持,通过 <uchar.h> 头文件。
- 引入了 `char16_t` 和 `char32_t` 类型。
内存模型
- 定义了明确的内存模型,提供更好的并发编程支持。
关键字
- 引入了 `no_return` 关键字,指示函数不会返回。
改进的标准库函数
- 新增了一些标准库函数,如 `aligned_alloc`。
边界检查功能
- 提供了边界检查功能,通过 `<stdckdint.h>` 头文件。
K&R 函数声明的废弃
- 废弃了旧的K&R(Kernighan和Ritchie)函数声明方式。
示例代码
#include <stdio.h>
#include <stdatomic.h>
#include <threads.h>
#include <stdalign.h>
#include <uchar.h>
#include <stdlib.h>
// 原子操作示例
atomic_int atomic_var = 0;
// 多线程示例
int thread_func(void *arg) {
atomic_fetch_add(&atomic_var, 1);
return 0;
}
// 静态断言示例
_Static_assert(sizeof(int) == 4, "int size is not 4 bytes");
// 对齐支持示例
struct AlignedStruct {
alignas(16) int x;
alignas(16) int y;
};
int main() {
// 泛型选择示例
#define max(a, b) _Generic((a), \
int: ((a) > (b) ? (a) : (b)), \
double: ((a) > (b) ? (a) : (b)) \
)
int a = 5, b = 10;
printf("max(a, b) = %d\n", max(a, b));
// 对齐支持示例
struct AlignedStruct s;
printf("Alignment of s: %zu\n", alignof(s));
// Unicode 支持示例
char16_t u16_str[] = u"Hello";
char32_t u32_str[] = U"World";
printf("u16_str: %ls\n", (wchar_t *)u16_str);
printf("u32_str: %ls\n", (wchar_t *)u32_str);
// 多线程示例
thrd_t threads[10];
for (int i = 0; i < 10; ++i) {
thrd_create(&threads[i], thread_func, NULL);
}
for (int i = 0; i < 10; ++i) {
thrd_join(threads[i], NULL);
}
printf("atomic_var = %d\n", atomic_var);
return 0;
}
1.3 GNU C 扩展 #
参考: https://gcc.gnu.org/onlinedocs/gcc-13.2.0/gcc.pdf
// 1. 0 长数组(可变长数组);
struct line {
int length;
char contents[0];
};
struct line *thisline = (struct line *)malloc (sizeof (struct line) + this_length);
thisline->length = this_length;
// 2. 变长数组,数组长度可以是变量或表达式,而非常量值;
FILE * concat_fopen (char *s1, char *s2, char *mode)
{
char str[strlen (s1) + strlen (s2) + 1];
strcpy (str, s1);
strcat (str, s2);
return fopen (str, mode);
}
// 3. 数组成员的初始化可以是非常量表达式
foo (float f, float g)
{
float beat_freqs[2] = { f-g, f+g };
/* . . . */
}
// 组合字面量(非 GNU C 扩展,只运行在声明变量时使用字面量来初始化)
struct foo {int a; char b[2];} structure;
// Here is an example of constructing a struct foo with a compound literal:
structure = ((struct foo) {x + y, 'a', 0});
// This is equivalent to writing the following:
{
struct foo temp = {x + y, 'a', 0};
structure = temp;
}
// 也可以对数组使用组合字面量初始化
char **foo = (char *[]) { "x", "y", "z" };
// Compound literals for scalar types and union types are also allowed.
int i = ++(int) { 1 };
// C99 要求静态变量必须用常量来初始化
// 但是 GNU C 允许使用字面量来初始化;
static struct foo x = (struct foo) {1, 'a', 'b'};
static int y[] = (int []) {1, 2, 3};
static int z[] = (int [3]) {1};
// 复合类型的数组初始化:
// 结构体数组
struct point
{
int x, y;
};
struct point point_array[2] = { {4, 5}, {8, 9} };
point_array[0].x = 3;
struct point ptarray[10] = { [2].y = yv2, [2].x = xv2, [0].x = xv0 } // 使用变量作为成员初始值
// 多维数组
int two_dimensions[2][5] = { {1, 2, 3, 4, 5}, {6, 7, 8, 9, 10} };
// 联合数组
union numbers
{
int i;
float f;
};
union numbers number_array [3] = { {3}, {4}, {5} };
// case range,注意 ... 前后的空格是必须的。
case 'A' ... 'Z':
case 1 ... 5:
// 条件运算符忽略操作数
x?:y // 约等于x?x:y, 但是 x 值会被求值一次
GNU C 支持为 Function、Variable、Type 指定 attribute:
-
GNU 和 IBM 扩展语法:
__attribute__ ((attribute-list))) -
可以在整个声明语句之前, 或则声明的标识符名称之后; 对于函数, 在函数完整的声明之前或之后指定 attribute;
-
函数属性:
__attribute__ ((access (read_only, 1)))
int puts (const char*)
void f () __attribute__ ((weak, alias ("__f")));
void* my_memalign (size_t, size_t) __attribute__ ((alloc_align (1)));
#define StrongAlias(TargetFunc, AliasDecl) \
extern __typeof__ (TargetFunc) AliasDecl \
__attribute__ ((alias (#TargetFunc), copy (TargetFunc)));
extern __attribute__ ((alloc_size (1), malloc, nothrow))
void* allocate (size_t);
StrongAlias (allocate, alloc);
int old_fn () __attribute__ ((deprecated));
void fatal () __attribute__ ((noreturn));
- 变量属性:位于标识符之后;
int var_target;
extern int __attribute__ ((alias ("var_target"))) var_alias;
int x __attribute__ ((aligned (16))) = 0;
struct foo { int x[2] __attribute__ ((aligned (8))); };
struct __attribute__ ((aligned (16))) foo
{
int i1;
int i2;
unsigned long long x __attribute__ ((warn_if_not_aligned (16)));
};
struct foo
{
char a;
int x[2] __attribute__ ((packed));
};
struct duart a __attribute__ ((section ("DUART_A"))) = { 0 };
struct duart b __attribute__ ((section ("DUART_B"))) = { 0 };
char stack[10000] __attribute__ ((section ("STACK"))) = { 0 };
int init_data __attribute__ ((section ("INITDATA")));
- 类型属性: 位于标识符之后;
struct __attribute__ ((aligned (8))) S { short f[3]; };
typedef int more_aligned_int __attribute__ ((aligned (8)));
struct __attribute__ ((aligned)) S { short f[3]; };
typedef int T1 __attribute__ ((deprecated));
T1 x;
typedef T1 T2;
T2 y;
typedef T1 T3 __attribute__ ((deprecated));
T3 z __attribute__ ((deprecated));
struct my_unpacked_struct
{
char c;
int i;
};
struct __attribute__ ((__packed__)) my_packed_struct
{
char c;
int i;
struct my_unpacked_struct s;
};
C23 开始支持 [[xxx]] 格式的 attribe 定义,使用 [[]] 语法时, 对于 GNU GCC 相关的 attribute 必须使用
gnu:: 前缀(带前缀的表示 C23 标准 attr).
- https://www.open-std.org/jtc1/sc22/wg21/docs/papers/2008/n2761.pdf
- https://en.cppreference.com/w/c/language/attributes
[[gnu::always_inline]] [[gnu::hot]] [[gnu::const]] [[nodiscard]]
inline int f(); // declare f with four attributes
[[noreturn]] void f()
{
// Some code that does not return
// back the control to the caller
// In this case the function returns
// back to the caller without a value
// This is the reason why the
// warning "noreturn' function does return' arises
}
[[deprecated("Reason for deprecation")]]
// For Class/Struct/Union
struct [[deprecated]] S;
// For Functions
[[deprecated]] void f();
// For namespaces
namespace [[deprecated]] ns{}
// For variables (including static data members)
[[deprecated]] int x;
// Set debug mode in compiler or 'R'
[[maybe_unused]] char mg_brk = 'D';
void process_alert(Alert alert)
{
switch (alert) {
case Alert::Red:
evacuate();
// Compiler emits a warning here
// thinking it is done by mistake
case Alert::Orange:
trigger_alarm();
// this attribute needs semicolon
[[fallthrough]];
// Warning suppressed by [[fallthrough]]
case Alert::Yellow:
record_alert();
return;
case Alert::Green:
return;
}
}
GNU C 支持内联汇编,两种类型:
-
Basic asm:Assembler Instructions Without Operands
asm asm-qualifiers ( AssemblerInstructions )只能在文件全局(top-level)使用,不支持输入、输出参数;
-
Extended Asm - Assembler Instructions with C Expression Operands
asm asm-qualifiers ( AssemblerTemplate
: OutputOperands
[ : InputOperands
[ : Clobbers ] ])
asm asm-qualifiers ( AssemblerTemplate
: OutputOperands
: InputOperands
: Clobbers
: GotoLabels)
示例:
__asm__ ("some instructions"
: /* No outputs. */
: "r" (Offset / 8))
int src = 1;
int dst;
asm ("mov %1, %0\n\t" // %1 %0 引用后面的变量
"add $1, %0"
: "=r" (dst) // 输出
: "r" (src)); // 输入
printf("%d\n", dst);
为汇编中引用的变量定义名称:
uint32_t Mask = 1234;
uint32_t Index;
asm ("bsfl %[aMask], %[aIndex]" // %[aIndex] 引用变量名
: [aIndex] "=r" (Index) // [aIndex] 为变量别名
: [aMask] "r" (Mask)
: "cc");
Clang 支持的 attribute: https://clang.llvm.org/docs/AttributeReference.html
1.4 clang 支持的 C 和 GNU C 扩展 #
参考:
Linux 内核支持使用 clang 来编译。
2 源文件 #
源文件经过 parse 后形成如下类型的 token(称为词法解析):
- 标识符:用来命名 type、variable、struct, union、 enumeration tags, their members, typedef names, labels, or macros 等。
- 关键字
- 字面量
- 整型常量
- 字符常量
- 字符串常量
- C99 支持的复合字面量
- 运算符
- 对操作数进行操作,组成表达式,可以是单目、双目,也可以前缀或后缀。
- 分隔符:用于分割 token。空白也用于分割 token,但它本身不是 token。
- ( ) { } ; , . :
- 空白和注释
- 空白字符:空格、tab、换行、\f 和 \v;
- White space is ignored (outside of string and character constants), and is therefore optional, except when it is used to separate tokens.
#include <stdio.h>
int
main()
{
printf( "hello, world\n" );
return 0;
}
// 等效于
#include <stdio.h> int main(){printf("hello, world\n");return 0;}
解析生成 token 后,需要进行语法分析,形成语句,包括表达式语句、if 语句、for 语句等。
3 数据类型 #
• Primitive Types • Enumerations • Unions • Structures • Arrays: • Pointers: • Incomplete Types: • Type Qualifiers: • Storage Class Specifiers: • Renaming Types:
对于复合类型,如 数组、struct、union 的初始化有两种方式:
- 大括号表达式:大括号中的值必须是常量表达式,而且只能用于初始化,不能用于后续赋值。
- C99 支持的复合字面量 (Compound Literals):字面量中可以使用变量。
复合字面量不仅用于初始化,还可以用于在初始化完 struct/union 后,还可以使用复合字面量对它们赋值,复合字面量还支持指针。
#include <stdio.h>
struct MyStruct {
int a;
float b;
};
int main() {
int val1 = 10;
float val2 = 3.14;
// 使用大括号初始化,只能使用常量表达式
struct MyStruct myStruct1 = {.a = 1, .b = 0.1};
// myStruct1 = {.a = 1, .b = 0.1}; // 错误
// 使用复合字面量初始化,可以使用变量
struct MyStruct myStruct2 = (struct MyStruct){ .a = val1, .b = val2 };
// 赋值,OK
myStruct2 = (struct MyStruct){ .a = val1, .b = 4.5 };
// 打印结构体成员
printf("a: %d, b: %.2f\n", myStruct.a, myStruct.b);
int *p = (int []){1 ,2 ,3 ,4};
printf("%d\n", p[1]); // 2
return 0;
}
数组名不能作为左值使用,所以数组之间不能相互赋值,函数也不能返回数组。但是数组名作为右值使用时,等效为指向首元素的指针。数组作为函数参数时,也等效为指针。
C 类型系统的核心思想是抽象和组合,struct/union/array/pointer 都是由基本类型组合而来的。函数也是语句的组合,语句是表达式或 if/while/for 等组合,表达式是操作符和操作数或表达式的组合。
3.1 基本类型 #
常量(字面量)类型:
// char 是 8 bits 的整型
printf("%d %d\n", 5, '5'); // 5 53
char c = '6';
int x = c; // x has value 54, the code point for '6'
int y = c - '0'; // y has value 6, just like we want
// These two lines are equivalent:
long long int x;
long long x;
// And so are these:
short int x;
short x;
int a = 0x1A2B; // Hexadecimal
int b = 0x1a2b; // Case doesn't matter for hex digits
printf("%x", a); // Print a hex number, "1a2b"
int a = 012;
printf("%o\n", a); // Print an octal number, "12"
int x = 11111; // Decimal 11111
int y = 00111; // Decimal 73 (Octal 111)
int z = 01111; // Decimal 585 (Octal 1111)
int x = 0b101010; // Binary 101010
printf("%d\n", x); // Prints 42 decimal
整型默认为 int,浮点默认为 double,通过给字面量添加 U 和 L 来改变字面量值的类型。
int x = 1234; // int
long int x = 1234L; // long
long long int x = 1234LL // long long
unsigned int x = 1234U;
unsigned long int x = 1234UL;
unsigned long long int x = 1234ULL;
float x = 3.14f;
double x = 3.14;
long double x = 3.14L;
printf("%e\n", 123456.0); // Prints 1.234560e+05
| Type | Suffix |
|---|---|
| int | None |
| long int | L |
| long long int | LL |
| unsigned int | U |
| unsigned long int | UL |
| unsigned long long int | ULL |
| float | F |
| double | None |
| long double | L |
没有 long long double!
I32LP64:
- int/float 32 位;
- long/long long/double/pointer 64 位。
arm64 位系统:
| Type | My Bytes | Minimum Value | Maximum Value |
|---|---|---|---|
| char | 1 | -128 | 127100 |
| signed char | 1 | -128 | 127 |
| short | 2 | -32768 | 32767 |
| int | 4 | -2147483648 | 2147483647 |
| long | 8 | -9223372036854775808 | 9223372036854775807 |
| long long | 8 | -9223372036854775808 | 9223372036854775807 |
| unsigned char | 1 | 0 | 255 |
| unsigned short | 2 | 0 | 65535 |
| unsigned int | 4 | 0 | 4294967295 |
| unsigned long | 8 | 0 | 18446744073709551615 |
| unsigned long long | 8 | 0 | 18446744073709551615 |
limits.h 头文件定义了这些类型的取值范围:
| Type | Min Macro | Max Macro |
|---|---|---|
| char | CHAR_MIN | CHAR_MAX |
| signed char | SCHAR_MIN | SCHAR_MAX |
| short | SHRT_MIN | SHRT_MAX |
| int | INT_MIN | INT_MAX |
| long | LONG_MIN | LONG_MAX |
| long long | LLONG_MIN | LLONG_MAX |
| unsigned char | 0 | UCHAR_MAX |
| unsigned short | 0 | USHRT_MAX |
| unsigned int | 0 | UINT_MAX |
| unsigned long | 0 | ULONG_MAX |
| unsigned long long | 0 | ULLONG_MAX |
浮点类型大小固定(单位 byte):
| Type | sizeof |
|---|---|
| float | 4 |
| double | 8 |
| long double | 16 |
浮点数有效数字的精度的最小值:
| Type | Decimal Digits You Can Store | Minimum | 实际 |
|---|---|---|---|
| float | FLT_DIG | 6 | 7 |
| double | DBL_DIG | 10 | 16 |
| long double | LDBL_DIG | 10 | 16 |
有效数字位数(精度)是指浮点数在表示和计算时能够保持的精确位数。对于单精度和双精度浮点数,有效数字位数是由浮点数的尾数部分(也称为有效数字或分数部分)的位数决定的。具体如下:
- 单精度浮点数(32位):单精度浮点数的结构如下:
- 符号位:1位
- 指数部分:8位
- 尾数部分:23位
- 双精度浮点数(64位):双精度浮点数的结构如下:
- 符号位:1位
- 指数部分:11位
- 尾数部分:52位
有效数字位数的计算
- 单精度浮点数: 尾数部分有23位,但是因为浮点数采用规范化形式,隐藏了一位隐含的1。 因此,总的有效数字位数为24位。 单精度浮点数的有效数字位数大约为
7 位十进制数。(一位十进制大概 3bit,故共 21bits) - 双精度浮点数: 尾数部分有52位,同样包含了一位隐含的1。 因此,总的有效数字位数为53位。 双精度浮点数的有效数字位数大约为
16位十进制数。
浮点数的有效数字位数可以通过以下公式估算,其中,nn 是尾数部分的总位数(包括隐含的1位)。
Decimal Digits≈log10(2n)log10(10)=n⋅log10(2)log10(10)≈n⋅0.3010Decimal Digits≈log10(10)log10(2n)=log10(10)n⋅log10(2)≈n⋅0.3010
/*
0.12345
0.123456
0.1234567
0.12345678
0.123456791 <-- Things start going wrong
0.1234567910
*/
#include <stdio.h>
#include <float.h>
int main(void)
{
// Both these numbers have 6 significant digits, so they can be
// stored accurately in a float:
float f = 3.14159f;
float g = 0.00000265358f;
printf("%.5f\n", f); // 3.14159 -- correct!
printf("%.11f\n", g); // 0.00000265358 -- correct!
// Now add them up
f += g; // 3.14159265358 is what f _should_ be
printf("%.11f\n", f); // 3.14159274101 -- wrong!
}
3.2 C99 bool 和固定宽度整型 #
C99 stdbool.h 提供了 bool 类型和常量。bool 类型占用 1 byte。
#ifndef __STDBOOL_H
#define __STDBOOL_H
#define bool _Bool
#define true 1
#define false 0
#endif /* __STDBOOL_H */
C99 stdint.h 中新增了以下类型,来解决之前 整型大小 不固定的问题:
- int8_t、int16_t、int32_t、int64_t
- uint8_t、uint16_t、uint32_t、uint64_t
- int_least8_t、int_least6_t、int_least32_t、int_least64_t
- int_fast8_t、int_fast6_t、int_fast32_t、int_fast64_t
- uintmax_t、uintptr_t
以及一些类型的最大、最小值:
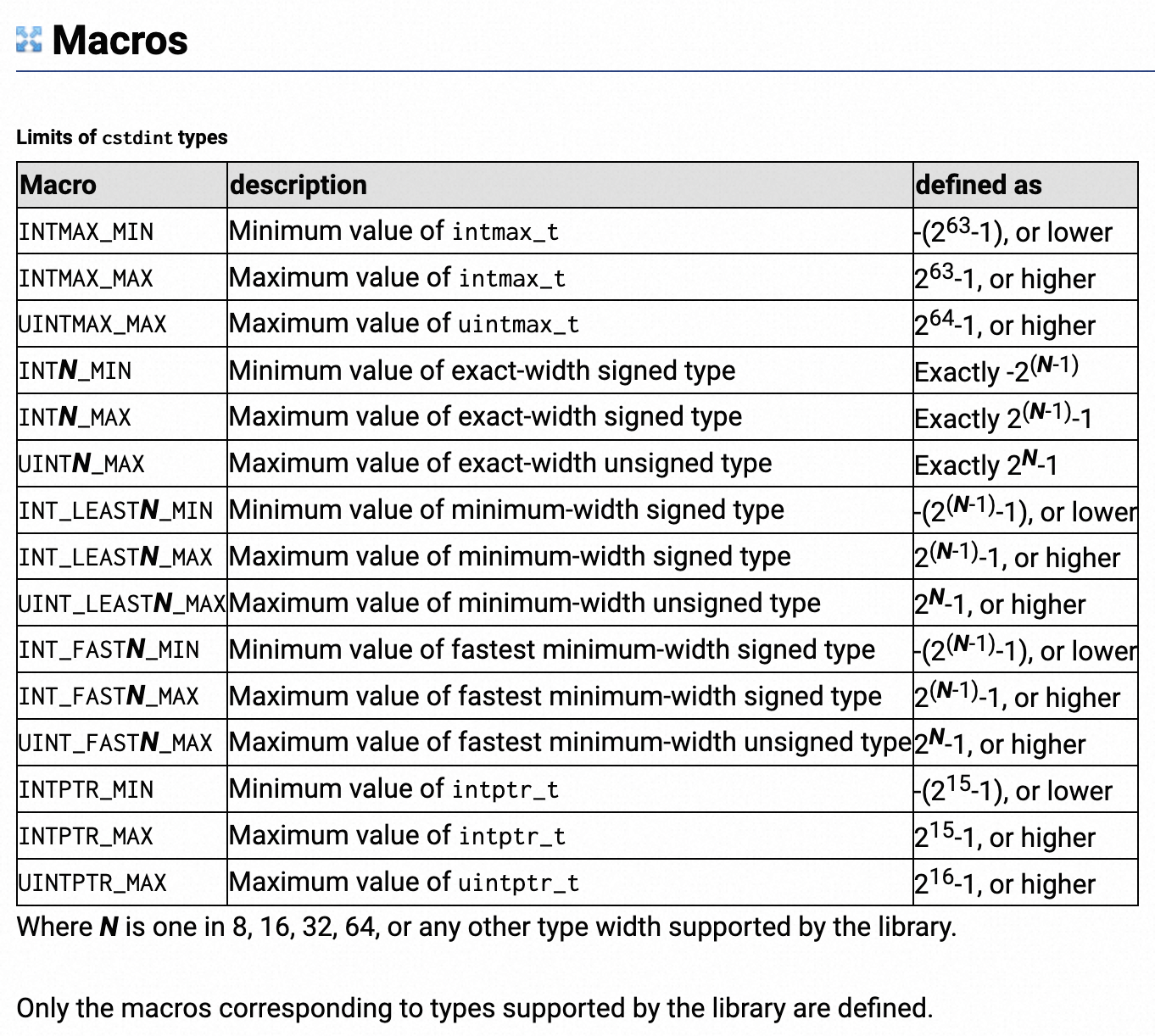
INT8_MAX INT8_MIN UINT8_MAX
INT16_MAX INT16_MIN UINT16_MAX
INT32_MAX INT32_MIN UINT32_MAX
INT64_MAX INT64_MIN UINT64_MAX
INT_LEAST8_MAX INT_LEAST8_MIN UINT_LEAST8_MAX
INT_LEAST16_MAX INT_LEAST16_MIN UINT_LEAST16_MAX
INT_LEAST32_MAX INT_LEAST32_MIN UINT_LEAST32_MAX
INT_LEAST64_MAX INT_LEAST64_MIN UINT_LEAST64_MAX
INT_FAST8_MAX INT_FAST8_MIN UINT_FAST8_MAX
INT_FAST16_MAX INT_FAST16_MIN UINT_FAST16_MAX
INT_FAST32_MAX INT_FAST32_MIN UINT_FAST32_MAX
INT_FAST64_MAX INT_FAST64_MIN UINT_FAST64_MAX
INTMAX_MAX INTMAX_MIN UINTMAX_MAX
对于常量,可以使用下面的宏:
INT8_C(x) UINT8_C(x)
INT16_C(x) UINT16_C(x)
INT32_C(x) UINT32_C(x)
INT64_C(x) UINT64_C(x)
INTMAX_C(x) UINTMAX_C(x)
// Again, these work only with constant integer values.
//For example, we can use one of these to assign constant values like so:
uint16_t x = UINT16_C(12);
intmax_t y = INTMAX_C(3490);
3.3 数组 #
函数内的数组变量是在栈上分配的,需要显式初始化:
#include <stdio.h>
int main(void)
{
int i;
float f[4]; // Declare an array of 4 floats
f[0] = 3.14159; // Indexing starts at 0, of course.
f[1] = 1.41421;
f[2] = 1.61803;
f[3] = 2.71828;
// Print them all out:
for (i = 0; i < 4; i++) {
printf("%f\n", f[i]);
}
}
数组初始化:
- 使用大括号形式进行初始化,大括号中的值必须都是
常量表达式,因为它们都在编译期间求值;- 可以在初始化后,运行期间,进行成员赋值,这时可以使用变量。
- 大括号内指定 index 初始化时, 未指定的 index 值默认初始化为 0;
- 数组名不支持作为左值进行赋值操作,但是可以作为右值使用,这时数组名等效为指针;
- 由于数组名不支持赋值,所以:
- 数组不能作为函数返回值类型。
- 数组之间不能相互赋值,编译器报错类型不匹配:左侧是数组,右侧是指针。
// 全量初始化
int my_array[5] = { 0, 1, 2, 3, 4 }; // 符合字面量,值必须都是常量表达式
// 部分初始化,剩余的部分值都初始化为 0;
int my_array[5] = { 0, 1, 2 };
int my_array[5] = { 0 }; // 所有元素都为 0
// int my_array[5] = {}; // 错误,必须至少指定一个元素的值。
// 指定 index 初始化
int my_array[5] = { [2] 5, [4] 9 };
int my_array[5] = { [2] = 5, [4] = 9 }; // 建议
// GNU 扩展:指定 index range 初始化
int new_array[100] = { [0 ... 9] = 1, [10 ... 98] = 2, 3 };
// 不指定数组长度,自动根据初始化字面量值来计算
int my_array[] = { 0, 1, 2, 3, 4 };
int my_array[] = { 0, 1, 2, [99] = 99 };
// 宏常量表达式作为数组长度
#define COUNT 5
int a[COUNT] = {[COUNT-3]=3, 2, 1};
// 解构数组
struct point
{
int x, y;
};
struct point point_array [3] = { {2, 3}, {4, 5}, {6, 7} };
struct point point_array [3] = { {2}, {4, 5}, {6, 7} };
struct point point_array [3] = { [0]={2}, [1]={4, 5}, [2]={6, 7}};
struct point point_array [3];
point_array[0].x = 2;
point_array[0].y = 3;
GNU C 扩展支持数组长度为变量:
int
my_function (int number)
{
int my_array[number];
…;
}
函数的参数可以是数组类型而且可以指定数组的大小,但是编译器会忽略函数参数中的数组大小, 而是把它转换成指向第一个元素的指针(函数内用 sizeof 获得的是指针的大小而非数组,所以在传递数组时 还要传递元素个数 ):
函数不能返回数组类型,但是可以返回数组的指针,或这包含数组的 struct。- 数组名用作 “右值” 时,会被自动转换为数组的首地址指针;
数组名不能做左值, 所以数组之间不能赋值(但是相同的结构类型对象之间可以直接赋值);
int foo(const int sz[10]);
// 等效于
int foo(const int sz[]);
// 等效于
int foo(const int *sz); // 更常用,明确 sz 为指针。
// 不管使用哪种形式,函数内均可以使用 *(sz+N) 或 sz[N] 的方式来访问数组元素.
int a[2] = {0, 1};
int b[2] = {1, 2};
a = b; // 错误:因为 a 的类型是数组,而 b 做右值是指针,两者类型不匹配。
#include <stdio.h>
void printArray(int arr[]) // 或者 int *attr, arr 都是指针类型
{
printf("Size of Array in Functions: %d\n", sizeof(arr)); // arr 是指针类型,所以 sizeof 值为 8
printf("Array Elements: ");
for (int i = 0; i < 5; i++) {
printf("%d ",arr[i]); // 不管哪种方式,都支持 arr[N]
}
}
int main()
{
int arr[5] = { 10, 20, 30, 40, 50 };
printf("Size of Array in main(): %d\n", sizeof(arr));
printArray(arr);
return 0;
}
#include <stdio.h>
void double_array(int *a, int len)
{
// Multiply each element by 2
// This doubles the values in x in main() since x and a both point
// to the same array in memory!
for (int i = 0; i < len; i++)
a[i] *= 2;
}
int main(void)
{
int x[5] = {1, 2, 3, 4, 5};
double_array(x, 5); // 传递数组的同时,传递数组的长度。
for (int i = 0; i < 5; i++)
printf("%d\n", x[i]); // 2, 4, 6, 8, 10!
}
数组 index 操作 A[i] 等效为 (*((A)+(i))),所以数组名在表达式右边时等效为指针,例如 ptr + N 的结果取决于 ptr 指向的对象类型,+N 表示跳过 N 个该对象类型的地址空间;
int array[10]
int *ptr = array
// array = arrayB // 错误,数组名不能用作左值。
// array[0] == *ptr
// array[N] == *(ptr+N)
// ptr == array == &array[0]
int arr[5] = { 10, 20, 30, 40, 50 };
int* ptr = &arr[0];
for (int i = 0; i < 5; i++) {
printf("%d ", *ptr++); // 后缀单目运算符优先级最高
}
在定义、声明或向函数传递多维数组变量时,除了第一维外需要明确指定其它维:
char *name[]={"Illegal manth", "Jan", "Feb", "Mar"};
char aname[][15] = { "Illegal month", "Jan", "Feb", "Mar" };
| array | function | call function |
|---|---|---|
| int a[5]; | func(int a[]); | func(a); |
| func(int *a); // a[i], *(a+i) | ||
| int a[5]; | func (int (*a)[5]); // a[0][i], *(*a+i) | func(&a); |
| int a[5][5]; | func (int (*a)[5]); // a[i][j], *(*(a+i)+j) | func(a); |
| func (int a[][5]); // a[i][j], *(*(a+i)+j) | func(a); | |
| int a[5][5][5] | func (int a[][5][5]); // a[i][j][k]; | func(a); |
| func (int (*a)[5][5]); // a[i][j][k]; | func(a); | |
| int *a[5]; | func (int *a[]); | func(a); |
| func (int **a); | func(a); |
如果向函数传递的是 int a[2][2] 二维数组名称 a, 则实际传递的是 &a[0], 因为 a[0] 是一维数组, 所以&a[0]
是数组指针, 类型为 int(*)[2], 在声明函数参数时, 可以使用任意一种(除了第第一维可以不指定长度外,其他都需要指定):
- int a[][2];
- int (*a)[2];
#include <stdio.h>
void print_2D_array(int a[2][3]) // 或者 int a[][3]
{
for (int row = 0; row < 2; row++) {
for (int col = 0; col < 3; col++)
printf("%d ", a[row][col]);
printf("\n");
}
}
int main(void)
{
int x[2][3] = {
{1, 2, 3},
{4, 5, 6}
};
print_2D_array(x);
}
类似的三维数组 int c[2][2][2], 在声明函数参数时, 可以使用任意一种:
-
int cc[][2][2];
-
int (*cc)[2][2];
-
c 是一个三维数组的名字, 相当于一个二维数组的指针, 所以 c+1 指向第二个二维数组。
-
cc 是一个指针, 指向一个 2*2 的 int 数组, 当 cc = c 时,
cc 实际指向三维数组 c 的第一个二维数组.
可以将上面的 int cc[] 简单记为 int (*cc) ;
数组名作为右值使用时,等效为一个地址:
- 一维数组:int a[3]; int *p = a; // a 为一维数组名,作为右值是第一个元素的地址
- 二维数组:int a[3][3]
- int (*p)[3] = a; // a 等效为 a+0, 是一个二维数组名,作为右值时表示一个一维数组的首地址指针
- int (*p)[3] = a+1; // a+1 为第二个一维数组的首地址指针
- int *p = a[1]; // a[1] 是一个一维
数组名,作为右值时表示该数组的首地址指针
#include <stdio.h>
int main(void)
{
int a[5] = {11, 22, 33, 44, 55};
int *p;
p = &a[0]; // p points to the array
// Well, to the first element, actually
// 等效为
p = a;
printf("%d\n", *p); // Prints "11"
}
总结:
- 建议函数参数使用 int a[][5][5] 而非 int (*a)[5][5] 的形式;
- 使用 int (*a)[5][5] 的方式和三维数组类似,a[i][j][k];
数组类型的变量定义: extern 也必须声明为数组类型,而不能是指针类型 :
- 原因:编译器需要为 指针变量 分配单独的内存单元,而数组名代表的是一块连续的内存区域, 不能被赋值;
// 数组变量定义
int array[5] = {1, 2, 3};
extern int array[]; // 正确
extern int *array; // 错误,编译时报错
// *(array+i)
多维数组 int c[2][2][3]:
- c 是 3 维数组的数组名,作为右值时是指向一个 2*3 的二维数组的指针, 可以赋值:int (*cp)[2][3] = c;
- c+1 指向第二个 2*3 数组的指针: int (*cp)[2][3] = c+1;
- *(c+1) 或 c[1] 为第二个 2*3 数组: int (*cp)[3] = c[1];
- *(*(c+1) + 1) 或 c[1][1] 为一个 3 个元素的数组:int *c5 = c[1][1];
注意:多维数组的场景下,c+1 为指向一个数组的指针,c[1] 或 *(c+1) 为该数组, 但并不是该数组的第一个元素 。
多维数组的初始化:
// 多维数组字面量初始化, 每一维都是一级 {}
int c[2][2] = {{0,0}, {1,1}};
int b[][3][3] = { // b
{ //b[0]
{1, 2, 3}, // b[0][0]
{1, 2, 3}, // b[0][1]
{1, 2, 3},
},
{
{4, 5, 6}, // b[1][0]
{4, 5, 6},
{4, 5, 6},
}
};
// 也可以打平列出多维数组的所有元素,根据元素数量自动计算第一维的值
// 元素数量必须是后续维度的整数倍(2*2 = 4)
int c[][2][2] = {
0,0,0,0, // c[0]
1,1,1,1, // c[1]
2,2,2,2, // c[2]
};
int a[3][2] = {
{1, 2},
{3}, // Left off the 4!
{5, 6}
};
/* 1 2 */
/* 3 0 */
/* 5 6 */
int a[3][2] = {
{1, 2},
// {3, 4}, // Just cut this whole thing out
{5, 6}
};
/* 1 2 */
/* 5 6 */
/* 0 0 */
// 多维数组也可以打平初始化
int a[3][2] = { 1, 2, 3, 4, 5, 6 };
/* 1 2 */
/* 3 4 */
/* 5 6 */
// 整个数组都是 0
int a[3][2] = {0};
获得数组的大小和元素数量:
int x[12]; // 12 ints
printf("%zu\n", sizeof x); // 48 total bytes
printf("%zu\n", sizeof(int)); // 4 bytes per int
printf("%zu\n", sizeof x / sizeof(int)); // 48/4 = 12 ints!
// x 为指针类型
void foo(int x[12])
{
printf("%zu\n", sizeof x); // 8?! What happened to 48?
printf("%zu\n", sizeof(int)); // 4 bytes per int
printf("%zu\n", sizeof x / sizeof(int)); // 8/4 = 2 ints?? WRONG.
}
C99 开始支持可变长数组 Variable-Length Arrays (VLAs) :C provides a way for you to declare an array whose size is determined at runtime. This gives you the benefits of dynamic runtime sizing like you
get with malloc(), but without needing to worry about free()ing the memory after. Now, a lot of
people don’t like VLAs. They’ve been banned from the Linux kernel, for example.
- 可变长数组在栈上分配,和 malloc() 相比,优点是:不需要手动 free 释放内存,sizeof() 返回数组的内存大小。
- 只能在 block 作用域中,如函数参数或自动变量,但不支持 file 或全局作用域。
- 不支持 static 类型 VLA,不支持用初始化表达式初始化 VLA;不支持在 struct/union 中使用 VLA;
- 可以在 block 作用域中用 typedef 来声明 VLA 类型多维数组;
- sizeof 可以正常使用,但是如果作为函数参数的 VLA, sizeof 返回的指针变量的大小。
#if __STDC_NO_VLA__ == 1
#error Sorry, need VLAs for this program!
#endif
#include <stdio.h>
int main(void)
{
int n;
printf("Enter a number: ");
fflush(stdout);
scanf(" %d", &n);
int v[n]; // 可变长数组, 数组长度可以是个变量, 可实现栈上内存分配(类似于堆上内存分配的 malloc)
// int v[x * 100]; // OK
// 可以正常使用 sizeof,返回数组总大小
size_t num_elems = sizeof v / sizeof v[0];
for (int i = 0; i < n; i++)
v[i] = i * 10;
for (int i = 0; i < n; i++)
printf("v[%d] = %d\n", i, v[i]);
}
void fvla(int m, int C[m][m]) // OK: block scope/auto duration pointer to VLA
{
typedef int VLA[m][m]; // OK: block scope VLA
int D[m]; // OK: block scope/auto duration VLA
// static int E[m]; // Error: static duration VLA
// extern int F[m]; // Error: VLA with linkage
int (*s)[m]; // OK: block scope/auto duration VM
s = malloc(m * sizeof(int)); // OK: s points to VLA in allocated storage
// extern int (*r)[m]; // Error: VM with linkage
static int (*q)[m] = &B; // OK: block scope/static duration VM}
}
VLA 作为函数参数:
- 函数内 VLA 是一个指针,sizeof 返回指针大小。
// 对于使用 VLA 的函数声明, 长度部分可以使用 * 或变量名
void foo(size_t x, int a[*]); // 函数声明
void foo(size_t x, int a[x]); // OK, 函数声明
// 函数定义,必须用变量指定长度
void foo(size_t x, int a[x]) // x 是一个变量, 作为 a 数组的长度, 是一个可变长数组, 编译器自动分配内存
{
printf("%zu\n", sizeof a); // same as sizeof(int*) // 函数内, a 是一个指针变量类型而非数组.
}
VLA 也支持 typedef 运算符,但是定义的数组大小为执行 typedef 时刻变量值:
#include <stdio.h>
int main(void)
{
int w = 10;
typedef int goat[w]; // goat 类型为固定大小的数组 int[10]
// goat is an array of 10 ints
goat x; // 但是还是不能对 gota 进行字面量初始化。
// Init with squares of numbers
for (int i = 0; i < w; i++)
x[i] = i*i;
// Print them
for (int i = 0; i < w; i++)
printf("%d\n", x[i]);
// Now let's change w...
w = 20;
// But goat is STILL an array of 10 ints, because that was the
// value of w when the typedef executed.
}
多维 VLA:
int w = 10;
int h = 20;
int x[h][w];
int y[5][w];
int z[10][w][20];
// 向函数传递多维 VLA 数组
#include <stdio.h>
void print_matrix(int h, int w, int m[h][w])
{
for (int row = 0; row < h; row++) {
for (int col = 0; col < w; col++)
printf("%2d ", m[row][col]);
printf("\n");
}
}
int main(void)
{
int rows = 4;
int cols = 7;
int matrix[rows][cols];
for (int row = 0; row < rows; row++)
for (int col = 0; col < cols; col++)
matrix[row][col] = row * col;
print_matrix(rows, cols, matrix);
}
在使用数组类型的函数参数时,可以 在方括号中 指定 type qualifiters(const、volatile) 和 static 关键字:
- int p[static 4]:static 表示传入的数组 p 至少包含 4 个元素;
- const int a[const 20] 表示 a 类型是 const int * const a,20 会被忽略;
- double a[static restrict 10] 表示 a 数组至少有 10 个元素, 而且只会通过该指针来修改对应内存区域;
// 指针变量的 type qualifiters
int *const p;
int *volatile p;
int *const volatile p;
// etc.
// 数组的 type qualifiters 在方括号内指定
int func(int *const volatile p) {...}
int func(int p[const volatile]) {...}
int func(int p[const volatile 10]) {...}
// static N:表示 p 数组包含至少 4 个元素
int func(int p[static 4]) {...}
int main(void)
{
int a[] = {11, 22, 33, 44};
int b[] = {11, 22, 33, 44, 55};
int c[] = {11, 22};
func(a); // OK! a is 4 elements, the minimum
func(b); // OK! b is at least 4 elements
func(c); // Undefined behavior! c is under 4 elements!
}
int f(const int a[20]) // 20 会被忽略
{
// in this function, a has type const int* (pointer to const int)
}
int g(const int a[const 20]) // 20 会被忽略
{
// in this function, a has type const int* const (const pointer to const int)
}
// restrict 表示只会通过该指针来修改对应内存区域(没有其它方式),编译器可以据此进行优化.
void fadd(double a[static restrict 10], const double b[static restrict 10])
{
for (int i = 0; i < 10; i++) // loop can be unrolled and reordered
{
if (a[i] < 0.0)
break;
a[i] += b[i];
}
}
3.4 字符串 #
C 没有单独的字符串类型,它实际是以 ‘\0’ 结尾的 char 类型数组:
- strlen() 不包含末尾的 ‘\0’;
char string[] = "abcd";
char string[5] = "abcd"; // 数组长度要包含最后的 '\0'
char *string = "abcd";
sring[0] = 'z'; // BAD NEWS: tried to mutate a string literal!
char string[] = {'a', 'b', 'c', 'd', '\0'};
string[0] = 'z'; // No problem
// 初始化字符串数组后,不能再用字符串字面量来修改该数组
char lemon[26] = "custard";
lemon = "steak sauce"; /* Fails! */
常用转移序列:
| Code | Description |
|---|---|
| \n | Newline character—when printing, continue subsequent output on the next line |
| \’ | Single quote—used for a single quote character constant |
| \" | Double quote—used for a double quote in a string literal |
| \\ | Backslash—used for a literal \ in a string or character |
| \a | Alert. This makes the terminal make a sound or flash, or both! |
| \b | Backspace. Moves the cursor back a character. Doesn’t delete the character. |
| \f | Formfeed. This moves to the next “page”, but that doesn’t have much modern meaning. On my system, this behaves like \v. |
| \r | Return. Move to the beginning of the same line. |
| \t | Horizontal tab. Moves to the next horizontal tab stop. On my machine, this lines up on columns that are multiples of 8, but YMMV. |
| \v | Vertical tab. Moves to the next vertical tab stop. On my machine, this moves to the same column on the next line. |
| \? | Literal question mark. Sometimes you need this to avoid trigraphs, as shown below. |
#include <stdio.h>
#include <threads.h>
int main(void)
{
printf("Use \\n for newline\n"); // Use \n for newline
printf("Say \"hello\"!\n"); // Say "hello"!
printf("%c\n", '\''); // '
for (int i = 10; i >= 0; i--) {
printf("\rT minus %d second%s... \b", i, i != 1? "s": "");
fflush(stdout); // Force output to update
// Sleep for 1 second
thrd_sleep(&(struct timespec){.tv_sec=1}, NULL);
}
printf("\rLiftoff! \n");
}
字符或字符串中的数值转义字符:
| \123(1-3 位八进制数,如 \0) | Embed the byte with octal value 123, 3 digits exactly. |
|---|---|
| \x4D(必须是2位) | Embed the byte with hex value 4D, 2 digits. |
| \u2620 (必须是4位) | Embed the Unicode character at code point with hex value 2620, 4 digits. |
| \U0001243F (必须是8位) | Embed the Unicode character at code point with hex value 1243F, 8 digits. |
printf("A\102C\n"); // 102 is `B` in ASCII/UTF-8
printf("\xE2\x80\xA2 Bullet 1\n");
printf("\xE2\x80\xA2 Bullet 2\n");
printf("\xE2\x80\xA2 Bullet 3\n");
空白字符(空格、\t、换行)风格的字符串会被自动连接。
字符串拷贝 strcpy/strncpy:
#include <stdio.h>
#include <string.h>
int main(void)
{
char s[] = "Hello, world!";
char t[100]; // Each char is one byte, so plenty of room
// This makes a copy of the string!
strcpy(t, s); // t 空间要足够大
// We modify t
t[0] = 'z';
// And s remains unaffected because it's a different string
printf("%s\n", s); // "Hello, world!"
// But t has been changed
printf("%s\n", t); // "zello, world!"
3.5 指针 #
地址即指针:
- int a[2]:
- a: 数组 a 元素的首地址,做右值时地址,类型为 int *a;
- &a:指向一个 2 个 int 型数组的指针,类型为 int (*a)[2];
- a[i] 等效为 *(a+i) ,即加偏移后再解引用;
- a[b] 等效为 *(a + b),a 和 b 都可以是表达式,所以更准确的形式:E1[E2] is identical to (*((E1)+(E2)))
指针是针对于单个标识符的,所以建议 * 和标识符连在一起:
int *foo, *bar; /* Two pointers. */
int *baz, quux; /* A pointer and an integer variable. */
常见指针变量类型:
char *name; // name 为指针类型
char *args[4]; // args 为数组类型:4 个元素的数组类型,元素类型为 chart *
char (*args)[4]; // args 为指针类型:指向包含 4 个 char 元素的数组
// max 为函数指针变量,只能指向签名为 int (int, int) 的函数
int (*max)(int, int);
// max 为函数指针类型:定义签名为 int (int, int) 的函数类型
typedef int (*max)(int, int);
指针间的转换:安全的转换如下:
- Converting to intptr_t or uintptr_t.
- Converting to and from void*.
- Converting to and from char* (or signed char*/unsigned char*).
- Converting to and from a pointer to a struct and a pointer to its first member, and vice-versa.
If you cast to a pointer of another type and then access the object it points to, the behavior is
undefined due to something called strict aliasing .
Strict aliasing says you are only allowed to access an object via pointers to compatible types to
that object.
// GOOD
int a = 1;
int *p = &a;
// BAD
int a = 1;
float *p = (float *)&a;
// BAD
int a = 0x12345678;
short b = *((short *)&a); // Violates strict aliasing
// BAD
#include <stdio.h>
#include <stdint.h>
struct words {
int16_t v[2];
};
void fun(int32_t *pv, struct words *pw)
{
for (int i = 0; i < 5; i++) {
(*pv)++;
// Print the 32-bit value and the 16-bit values:
printf("%x, %x-%x\n", *pv, pw->v[1], pw->v[0]);
}
}
int main(void)
{
int32_t v = 0x12345678;
struct words *pw = (struct words *)&v; // Violates strict aliasing
fun(&v, pw);
}
C does make one guarantee, though: you can convert a pointer to a uintptr_t type and you’ll be able
to convert it back to a pointer without losing any data .
- uintptr_t is defined in <stdint.h>
- Additionally, if you feel like being signed, you can use intptr_t to the same effect.
指针变量保存的是内存地址,也是一个整型值(对于 I32LP64 系统来说,int/float 是 32 位,double、long 和 pointer 都是 64 位)。可以使用强制类型转换将一个整型字面量值类型转换为指针:
int *foo = (int *)(0x11111111)
指针的运算:
- 减法运算:不是地址值直接相减的结果,而是
中间包含的元素数量,指针相减后的类型为 <stddef.h> 中定义的ptrdiff_t,可以使用 %td 或 %tX 等来打印; - 加法运算:p++; p+=n; 等的 p 结果是个新地址,是在原来 p 值的基础上增加 n * sizeof(*p) :
int cats[100];
int *f = cats + 20;
int *g = cats + 60;
ptrdiff_t d = g - f; // difference is 40
#include <stdio.h>
int my_strlen(char *s)
{
// Start scanning from the beginning of the string
char *p = s;
// Scan until we find the NUL character
while (*p != '\0')
p++;
// Return the difference in pointers
return p - s;
}
int main(void)
{
printf("%d\n", my_strlen("Hello, world!")); // Prints "13"
}
// 可以使用使用前缀 t 来打印 ptrdiff_t 类型:
printf("%td\n", d); // Print decimal: 40
printf("%tX\n", d); // Print hex: 28
int a[] = {11, 22, 33, 44, 55, 999}; // Add 999 here as a sentinel
int *p = &a[0]; // p points to the 11
while (*p != 999) { // While the thing p points to isn't 999
printf("%d\n", *p); // Print it
p++; // Move p to point to the next int!
}
指针的比较:
- 指针可以使用比较运算符进行比较。对于两个指针,如果它们指向
同一个数组或对象的不同位置,可以进行比较。如果它们指向不同的对象或数组,结果是未定义的。 - C 语言中不允许直接比较
不同类型的指针,除非它们都转换为 void* 类型。
int arr[5] = {1, 2, 3, 4, 5};
int *p1 = &arr[1];
int *p2 = &arr[3];
if (p1 < p2) {
// 合法:p1 和 p2 指向同一个数组的不同位置
}
int x = 10;
int y = 20;
int *p3 = &x;
int *p4 = &y;
if (p3 == p4) {
// 合法,但结果未定义:p3 和 p4 指向不同的对象
}
int *p1;
float *p2;
if (p1 == p2) {
// 错误:不能直接比较不同类型的指针
}
if ((void*)p1 == (void*)p2) {
// 合法:将指针转换为 void* 后进行比较
}
二级指针和多级指针:
- 作为函数参数时,int **p 等效为 int *p[],p 是一个指针,指向一个 int * 类型的内存单元;
- 二级指针的存在意义是在函数内修改二级指针指向的一级指针的值:
int modify(int **p)
{
static int *state = (int *)0x88f9;
*p = state; // 修改一级指针的值
return *p
}
int caller()
{
int *p = NULL;
modify(&p); // 在 modify 函数内修改指针 p 的值
}
const causes the variable to be read-only: after initialization, its value may not be changed. 一旦初始化后就不能修改;
const float pi = 3.14159f;
const 和指针结合使用时,顺序影响语义。
- const int *p; // Can’t modify what p points to
- int const *p; // Can’t modify what p points to, just like the previous line
- int *const p; // We can’t modify “p” with pointer arithmetic
- const int *const p; // Can’t modify p or *p!
char a[] = "abcd";
const char *p = a;
p++; // p 可以修改;
p[0] = 'A'; // Compiler error! Can't change what it points to
int *const p; // We can't modify "p" with pointer arithmetic
p++; // Compiler error!
int x = 10;
int *const p = &x;
*p = 20; // Set "x" to 20, no problem
char **p;
p++; // OK!
(*p)++; // OK!
char **const p;
p++; // Error!
(*p)++; // OK!
char *const *p;
p++; // OK!
(*p)++; // Error!
char *const *const p;
p++; // Error!
(*p)++; // Error!
在进行 const 变量到非 const pointer 复制时,编译器可能警告:
const int x = 20;
int *p = &x;
// ^ ^
// | |
// int* const int*
// initialization discards 'const' qualifier from pointer type target
*p = 40; // Undefined behavior--maybe it modifies "x", maybe not!
sizeof(p) 返回的是 p 指针类型自身的大小,一般为 6 字节。而 sizeof(**p) 返回的是 p 指向的类型的大小。
void *p 指针 :可以保存任意指针类型,一般用作函数参数或返回值,具有如下限制:
- 不能使用指针算术运算;
- 不能使用 * 来 dereference void *;
- 不能使用 -> 运算符;
- 不能使用 p[N] 运算符,因为它也是 dereference 操作。
所以,在实际使用 void *p 前,需要将 p 转换为具体类型的指针。
- 如 malloc() 返回的是 void * 类型指针,可以被赋值给任意类型指针:
- sizeof 的参数可以是类型或表达式,对于类型,必须使用括号包围。
void *memcpy(void *s1, void *s2, size_t n);
void *my_memcpy(void *dest, void *src, int byte_count)
{
// Convert void*s to char*s
char *s = src, *d = dest;
// Now that we have char*s, we can dereference and copy them
while (byte_count--) {
*d++ = *s++;
}
// Most of these functions return the destination, just in case that's useful to the caller.
return dest;
}
// The type of structure we're going to sort
struct animal {
char *name;
int leg_count;
};
// This is a comparison function called by qsort() to help it determine what exactly to sort
// by. We'll use it to sort an array of struct animals by leg_count.
int compar(const void *elem1, const void *elem2)
{
// We know we're sorting struct animals, so let's make both arguments pointers to struct
// animals
const struct animal *animal1 = elem1;
const struct animal *animal2 = elem2;
// Return <0 =0 or >0 depending on whatever we want to sort by.
// Let's sort ascending by leg_count, so we'll return the difference
// in the leg_counts
if (animal1->leg_count > animal2->leg_count)
return 1;
if (animal1->leg_count < animal2->leg_count)
return -1;
return 0;
}
int *p = malloc(sizeof(int));
*p = 12; // Store something there
printf("%d\n", *p); // Print it: 12
free(p); // All done with that memory
int *p = malloc(sizeof *p); // *p is an int, so same as sizeof(int)
void 类型转换:可以避免编译器发出未使用变量的警告:
#include <stdio.h>
#include <threads.h>
#include <stdatomic.h>
atomic_int x;
int thread1(void *arg)
{
// 函数体内未使用 arg 变量,可以转换为 void 类型。
(void)arg;
// 。。。
}
NULL 指针 :C 和操作系统保证 NULL 指针对应的地址 0 永远不可能是有效的地址,所以返回指针的程序都使用特殊的 NULL 指针来表示程序出错。下面几个值是等效的:
- NULL
- 0
- ‘\0’
- (void *)0
int *x;
if ((x = malloc(sizeof(int) * 10)) == NULL) {
printf("Error allocating 10 ints\n");
// do something here to handle it
}
3.6 结构 #
定义 struct 类型和变量:
struct point
{
int x, y;
} first_point, second_point;
struct point
{
int x, y;
};
struct point first_point, second_point; // struct 关键字不可少,但是可以使用 typedef 简化。
初始化:通过字面量初始化的方式,未初始化的成员被自动填充为 0(可以类比 static 变量未初始化时也为0);
struct point
{
int x, y;
};
struct point first_point = { 5, 10 };
struct point first_point = { .y = 10, .x = 5 }; // 建议,因为 value 可以是嵌套初始化,如 .y={1,2},
struct point first_point = { y: 10, x: 5 };
struct point
{
int x, y;
} first_point = { 5, 10 };
struct point
{
int x, y;
};
嵌套初始化: struct foo x = {.a.b.c=12};
struct rectangle
{
struct point top_left, bottom_right;
};
// 使用 {...} 来初始化嵌套的 struct
struct rectangle my_rectangle = { {0, 5}, {10, 0} };
// 或者使用如下模式:
struct spaceship s = {
.manufacturer="General Products",
.ci={
.window_count = 8,
.o2level = 21
}
};
// 或者使用嵌套成员访问 .ci.o2level=21 来初始化
#include <stdio.h>
struct cabin_information {
int window_count;
int o2level;
};
struct spaceship {
char *manufacturer;
struct cabin_information ci;
};
int main(void)
{
struct spaceship s = {
.manufacturer="General Products",
.ci.window_count = 8, // <-- NESTED INITIALIZER!
.ci.o2level = 21
};
printf("%s: %d seats, %d%% oxygen\n",
s.manufacturer, s.ci.window_count, s.ci.o2level);
}
struct 数组初始化:
#include <stdio.h>
struct passenger {
char *name;
int covid_vaccinated; // Boolean
};
#define MAX_PASSENGERS 8
struct spaceship {
char *manufacturer;
struct passenger passenger[MAX_PASSENGERS];
};
int main(void)
{
struct spaceship s = {
.manufacturer="General Products",
.passenger = {
// Initialize a field at a time
[0].name = "Gridley, Lewis",
[0].covid_vaccinated = 0,
// Or all at once
[7] = {.name="Brown, Teela", .covid_vaccinated=1},
}
};
printf("Passengers for %s ship:\n", s.manufacturer);
for (int i = 0; i < MAX_PASSENGERS; i++)
if (s.passenger[i].name != NULL)
printf(" %s (%svaccinated)\n",
s.passenger[i].name,
s.passenger[i].covid_vaccinated? "": "not ");
}
匿名 struct 和 typedef 重定义(不需要再指定 struct 关键字):
// 匿名 struct 也代表一个类型,所以可以定义对应变量
struct { // <-- No name!
char *name;
int leg_count, speed;
} a, b, c; // 3 variables of this struct type
a.name = "antelope";
c.leg_count = 4;
// original name
// |
// v
// |-----------|
typedef struct animal {
char *name;
int leg_count, speed;
} animal; // <-- new name
struct animal y; // This works
animal z; // This also works because "animal" is an alias
// Anonymous struct! It has no name!
// |
// v
// |----|
typedef struct {
char *name;
int leg_count, speed;
} animal; // <-- new name
//struct animal y; // ERROR: this no longer works--no such struct!
animal z; // This works because "animal" is an alias
相同类型的 struct 值之间可以相互赋值,编译器会进行 bit copy(作为对比,array 不能相互赋值),所以对于大的 struct 应该传递指针:
- struct 可以作为函数的参数和返回值;
- struct 变量间可以赋值
- 非 deep-copy,对于指针复制的指针值;
void set_price(struct car *c, float new_price) {
(*c).price = new_price; // Works, but is ugly and non-idiomatic :(
}
struct car a, b;
b = a; // Copy the struct
struct/union 的匿名成员: 可以在结构器上声明某个 union 或 struct 类型但是不指出成员名, 这样后续就可以像使用结构体成员一样来 直接访问其中的 union 或 struct 的成员 .
#include <stdio.h>
struct person {
char *name;
char gender;
int age;
int weight;
struct {
int area_code;
long phone_number;
};
};
int main(void) {
struct person p = {"jim", 'F', 28, 65, {21, 444444}};
printf("%d\n", p.area_code);
return 0;
}
// 类似的, 还有匿名 union 成员
struct person {
char *name;
union {
char gender;
int id;
};
int age;
};
int main(void) {
struct person p = {"jim", 'F', 20};
printf("jim.gender = %c, jim.id = %d\n", jim.gender, jim.id);
return 0;
}
// 更复杂的情况
struct v
{
union // anonymous union
{
struct { int i, j; }; // anonymous structure
struct { long k, l; } w;
};
int m;
} v1;
v1.i = 2; // valid
v1.k = 3; // invalid: inner structure is not anonymous
v1.w.k = 5; // valid
自引用 struct:struct 内部只能使用指针来自引用同类型:
#include <stdio.h>
#include <stdlib.h>
struct node {
int data;
struct node *next; // 指针,不能是 struct node next;
};
int main(void)
{
struct node *head;
// Hackishly set up a linked list (11)->(22)->(33)
head = malloc(sizeof(struct node));
head->data = 11;
head->next = malloc(sizeof(struct node));
head->next->data = 22;
head->next->next = malloc(sizeof(struct node));
head->next->next->data = 33;
head->next->next->next = NULL;
// Traverse it
for (struct node *cur = head; cur != NULL; cur = cur->next) {
printf("%d\n", cur->data);
}
}
struct 指针:指向 struct 的第一个成员,所以可以在两个 struct 间转换:
#include <stdio.h>
struct parent {
int a, b;
};
struct child {
struct parent super; // MUST be first
int c, d;
};
// Making the argument `void*` so we can pass any type into it
// (namely a struct parent or struct child)
void print_parent(void *p)
{
// Expects a struct parent--but a struct child will also work
// because the pointer points to the struct parent in the first
// field:
struct parent *self = p;
printf("Parent: %d, %d\n", self->a, self->b);
}
void print_child(struct child *self)
{
printf("Child: %d, %d\n", self->c, self->d);
}
int main(void)
{
struct child c = {.super.a=1, .super.b=2, .c=3, .d=4};
print_child(&c);
print_parent(&c); // Also works even though it's a struct child!
}
struct 和 union 类型的成员访问:
- 非指针类型: s.field;
- 指针类型: (*p).field 或者 p->field;
可变长数组 :struct 的最后一个成员为长度可变的数组,故称为 Flexible Array Members:
- 传统实现方式:
struct len_string {
int length;
char data[8];
};
struct len_string *s = malloc(sizeof *s + 40);
s->length = 48;
// Copy more than 8 bytes!
strcpy(s->data, "Hello, world!"); // Won't crash. Probably.
// 或者使用编译器扩展的 0 长数组,这样 malloc 分配的额外空间,都可以给 data 成员用。
struct len_string {
int length;
char data[0];
};
struct len_string *s = malloc(sizeof *s + 40);
s->length = 40
// Copy more than 8 bytes!
strcpy(s->data, "Hello, world!"); // Won't crash. Probably.
- C99 为可变长数组增加了正式的支持(不依赖编译器扩展了):不支持可变长数组的字面量初始化;
struct len_string {
int length;
char data[]; // 必须是 struct 最后一个成员,不指定大小;
};
struct len_string *len_string_from_c_string(char *s)
{
int len = strlen(s);
// Allocate "len" more bytes than we'd normally need
struct len_string *ls = malloc(sizeof *ls + len);
ls->length = len;
// Copy the string into those extra bytes
memcpy(ls->data, s, len);
return ls;
}
struct s { int n; double d[]; }; // s.d is a flexible array member
struct s t1 = { 0 }; // OK, d is as if double d[1], but UB to access
struct s t2 = { 1, { 4.2 } }; // error: initialization ignores flexible array
// if sizeof (double) == 8
struct s *s1 = malloc(sizeof (struct s) + 64); // as if d was double d[8]
struct s *s2 = malloc(sizeof (struct s) + 40); // as if d was double d[5]
s1 = malloc(sizeof (struct s) + 10); // now as if d was double d[1]. Two bytes excess.
double *dp = &(s1->d[0]); // OK
*dp = 42; // OK
s1->d[1]++; // Undefined behavior. 2 excess bytes can't be accessed
// as double.
s2 = malloc(sizeof (struct s) + 6); // same, but UB to access because 2 bytes are
// missing to complete 1 double
dp = &(s2->d[0]); // OK, can take address just fine
*dp = 42; // undefined behavior
*s1 = *s2; // only copies s.n, not any element of s.d
// except those caught in sizeof (struct s)
访问:
struct rectangle
{
struct point top_left, bottom_right;
};
struct rectangle my_rectangle;
my_rectangle.top_left.x = 0;
my_rectangle.top_left.y = 5;
my_rectangle.bottom_right.x = 10;
my_rectangle.bottom_right.y = 0;
赋值:
- 相同 struct 类型的两个对象可以相互赋值,编译器会做
field 级别的值拷贝, 所以 struct 类型可以直接作为函数的参数类型和返回值类型:即使是 array 成员, 也会相互拷贝,但是纯 array 变量之间是不支持直接赋值的. - 对于大型 struct,值拷贝消耗比较大,建议用指针;
-
struct padding
在 C 语言中,结构体(struct)的内存对齐和填充(padding)是编译器为了
提高访问速度和兼容硬件架构的要求而进行的。理解结构体的对齐和填充规则有助于编写高效和可靠的代码。-
内存对齐:内存对齐是指数据在内存中的
存储地址必须是其类型大小的整数倍。不同的数据类型有不同的对齐要求。例如:- char 类型通常对齐到 1 字节。
- short 类型通常对齐到 2 字节。
- int 类型通常对齐到 4 字节。
- double 类型通常对齐到 8 字节。
-
结构体的内存对齐和填充规则:结构体内存对齐的主要目的是
确保每个成员变量按照其对齐要求存储在内存中,从而提高访问速度。为了实现对齐,编译器会在结构体成员之间插入填充字节(padding),以及在结构体末尾添加填充字节,以确保结构体的大小是其最大成员对齐要求的倍数。
规则
- 每个成员按其自身的对齐要求进行对齐:如果需要,编译器会在成员前面插入填充字节,以确保成员地址是其对齐要求的整数倍。
- 结构体的总大小是最大对齐要求的倍数:结构体的总大小会被调整为其最大成员对齐要求的倍数,这可能会在结构体的末尾添加填充字节。
示例:考虑以下结构体定义:
struct Example { char a; // 1 字节 int b; // 4 字节 short c; // 2 字节 };编译器会对齐和填充这个结构体,使得其内存布局如下:
Offset Member Size 0 a 1 1-3 padding 3 4 b 4 8-9 c 2 10-11 padding 2总大小为 12 字节,因为 int 类型的对齐要求为 4 字节,而
结构体大小需要是最大对齐要求(4 字节)的倍数。C 标准允许通过
编译器特定的扩展来控制结构体的对齐和填充。以下是一些常见的方式:#pragma pack:#pragma pack 指令可以用来改变结构体的对齐方式。它通常用于在与硬件或网络协议打交道时,确保数据按照特定的对齐方式排列。
#pragma pack(push, 1) // 设置对齐方式为 1 字节边界 struct PackedExample { char a; int b; short c; }; #pragma pack(pop) // 恢复默认对齐方式在这种情况下,PackedExample 结构体的内存布局如下:
Offset Member Size 0 a 1 1-4 b 4 5-6 c 2总大小为 7 字节,因为
所有成员按照 1 字节对齐方式排列。attribute((packed)):GCC 编译器提供了 attribute((packed)) 来控制结构体的对齐方式:
- 与 #pragma pack(1) 类似,这会使 PackedExample 结构体的总大小为 7 字节,
没有任何填充字节。
struct PackedExample { char a; int b; short c; } __attribute__((packed));- 影响和注意事项
- 性能影响:虽然减少填充字节可以节省内存,但不当的对齐方式可能导致性能下降,尤其是在不支持未对齐访问的架构上。
- 兼容性问题:不同编译器对对齐和填充的处理可能有所不同,使用 #pragma pack 或 attribute((packed)) 等编译器特性时,需要注意跨平台兼容性。
示例代码:以下是一个示例代码,展示结构体的对齐和填充:
#include <stdio.h> #include <stddef.h> #pragma pack(push, 1) // 设置对齐方式为 1 字节边界 struct PackedExample { char a; int b; short c; }; #pragma pack(pop) // 恢复默认对齐方式 struct Example { char a; int b; short c; }; int main() { struct Example e; struct PackedExample pe; printf("Size of Example: %zu\n", sizeof(e)); printf("Offset of a: %zu\n", offsetof(struct Example, a)); printf("Offset of b: %zu\n", offsetof(struct Example, b)); printf("Offset of c: %zu\n", offsetof(struct Example, c)); printf("Size of PackedExample: %zu\n", sizeof(pe)); printf("Offset of a: %zu\n", offsetof(struct PackedExample, a)); printf("Offset of b: %zu\n", offsetof(struct PackedExample, b)); printf("Offset of c: %zu\n", offsetof(struct PackedExample, c)); return 0; } -
-
offsetof
由于 struct field 存在 padding,如果要获得 field 的实际偏移量,可以使用 <stddef.h> 中的 offsetof 宏函数:
#include <stdio.h> #include <stddef.h> struct foo { int a; char b; int c; char d; }; int main(void) { printf("%zu\n", offsetof(struct foo, a)); // 返回 size_t 类型,使用 %zu 打印 printf("%zu\n", offsetof(struct foo, b)); printf("%zu\n", offsetof(struct foo, c)); printf("%zu\n", offsetof(struct foo, d)); } /* 0 4 8 12 */或者:
# define OFFSETOF(type, member) ((int)(intptr_t)&(((type *)(void*)0)->member) )- 原理:任意类型都可以和 void 之间相互转换,intptr_t 和 int 间也可以相互转换;
-
Bit Field
bit field 的作用是减少 struct 的空间占用,可以使用 bit filed 来指定 struct field 不占用对应类型的标准大小,而是使用指定的大小:
- 需要是 struct 的整型成员,int, char, long int, etc.
- 总空间大小取决于 field 位数,编译器可能会按需插入 padding;
struct card { unsigned int suit : 2; // 可以赋值:0-3 unsigned int face_value : 4; // 可以赋值:0-15 };the range of an unsigned bit field of N bits is from 0 to 2^N - 1, and the range of a signed bit field of N bits is from -(2^N) / 2 to ((2^N) / 2) - 1.
非相邻的 bit-field 不会被合并, 可能会被自动插入 padding 来对齐;
struct foo { // sizeof(struct foo) == 16 (for me) unsigned int a:1; // since a is not adjacent to c. unsigned int b; unsigned int c:1; unsigned int d; };相邻 bit-field 合并:
struct foo { // sizeof(struct foo) == 12 (for me) unsigned int a:1; unsigned int c:1; unsigned int b; unsigned int d; };建议:Put all your bitfields together to get the compiler to combine them.
unnamed bit-fields:有些 bit-field 并不会使用,只是为了占空间,可以不命名;
struct foo { unsigned char a:2; unsigned char :5; // <-- unnamed bit-field! unsigned char b:1; };zero-width unnamed bit-field:告诉编译器开始使用新的 int 来分配后续的 field:
struct foo { // a 和 b 使用一个 int,c 和 d 使用另一个 int unsigned int a:1; unsigned int b:2; unsigned int :0; // <--Zero-width unnamed bit-field unsigned int c:3; unsigned int d:4; };
3.7 联合 #
union 类型可以定义多个成员,但是它们都共享同一个内存空间,所以一般写入和读取同一个成员才有意义(但是也可以利用该特点来读写不同的成员)。
定义联合类型和变量值:
- union xx 作为一个整体是一个类型(和 struct/enum 类似)。
- 定义时,各成员之间用分号分割;(和 struct/bit-field 类似,但是 enum 成员是逗号分割;)
union numbers
{
int i;
float f;
} first_number, second_number;
union numbers first_number, second_number;
初始化:
union numbers
{
int i;
float f;
};
union numbers first_number = { 5 }; // 初始化第一个成员
union numbers first_number = { f: 3.14159 }; // 初始化指定成员
union numbers first_number = { .f = 3.14159 }; // 建议的方式
union numbers
{
int i;
float f;
} first_number = { 5 };
访问成员:使用 . 或 ->, 和 struct 成员访问类似;
union numbers
{
int i;
float f;
};
union numbers first_number;
first_number.i = 5;
first_number.f = 3.9;
union numbers *second_number =&first_number;
second_number->i = 6;
union 大小为占用最大空间的成员:union 同时只能使用一个成员,所有成员占用同一个地址块,所以写一个成员时会覆盖以前设置的另一个成员值,可能导致后续的访问另一个成员值无效。
- union 不需要 padding,因为只占用最大成员的空间,该成员肯定是对齐的。
// This size of a union is equal to the size of its largest member. Consider the first union example from this section:
union numbers
{
int i;
float f;
};
#include <stdio.h>
union foo {
float b;
short a;
};
int main(void)
{
union foo x;
x.b = 3.14159;
printf("%f\n", x.b); // 3.14159, fair enough
printf("%d\n", x.a); // But what about this?
}
// 3.141590
// 4048
GNU C 扩展: Cast to a Union Type
union foo { int i; double d; };
int x;
double y;
union foo z;
// both x and y can be cast to type union foo and the following assignments
z = (union foo) x;
z = (union foo) y;
// are shorthand equivalents of these
z = (union foo) { .i = x };
z = (union foo) { .d = y };
union 数组:
union numbers
{
int i;
float f;
};
union numbers number_array [3] = { {3}, {4}, {5} };
union numbers number_array [3];
number_array[0].i = 2;
union 中匿名 struct:
struct {
int x, y;
} s;
s.x = 34;
s.y = 90;
printf("%d %d\n", s.x, s.y);
union foo {
struct { // unnamed!
int x, y;
} a;
struct { // unnamed!
int z, w;
} b;
};
union foo f;
f.a.x = 1;
f.a.y = 2;
// 或
f.b.z = 3;
f.b.w = 4;
union 指针:
#include <stdio.h>
union foo { // foo 的这些成员共享同一块内存
int a, b, c, d, e, f;
float g, h;
char i, j, k, l;
};
int main(void)
{
union foo x;
int *foo_int_p = (int *)&x; // 都指向 x 内存的开始
float *foo_float_p = (float *)&x;
x.a = 12;
printf("%d\n", x.a); // 12
printf("%d\n", *foo_int_p); // 12, again
x.g = 3.141592;
printf("%f\n", x.g); // 3.141592
printf("%f\n", *foo_float_p); // 3.141592, again
}
// 反向也 OK
union foo x;
int *foo_int_p = (int *)&x; // Pointer to int field
union foo *p = (union foo *)foo_int_p; // Back to pointer to union
p->a = 12; // This line the same as...
x.a = 12; // this one.
union 中公共初始化序列:
- If you have a union of structs, and all those structs begin with a common initial sequence, it’s valid to access members of that sequence from any of the union members.
#include <stdio.h>
struct common {
int type; // common initial sequence
};
struct antelope {
int type; // common initial sequence
int loudness;
};
struct octopus {
int type; // common initial sequence
int sea_creature;
float intelligence;
};
union animal {
struct common common;
struct antelope antelope;
struct octopus octopus;
};
#define ANTELOPE 1
#define OCTOPUS 2
void print_animal(union animal *x)
{
switch (x->common.type) {
case ANTELOPE:
printf("Antelope: loudness=%d\n", x->antelope.loudness);
break;
case OCTOPUS:
printf("Octopus : sea_creature=%d\n", x->octopus.sea_creature);
printf(" intelligence=%f\n", x->octopus.intelligence);
break;
default:
printf("Unknown animal type\n");
}
}
int main(void)
{
union animal a = {.antelope.type=ANTELOPE, .antelope.loudness=12};
union animal b = {.octopus.type=OCTOPUS, .octopus.sea_creature=1, .octopus.intelligence=12.8};
print_animal(&a);
print_animal(&b);
}
union 中匿名成员:
- 可以直接访问匿名成员;
- Similar to struct, an unnamed member of a union whose type is a union without name is known as anonymous union. Every member of an anonymous union is considered to be a member of the enclosing struct or union keeping their union layout. This applies recursively if the enclosing struct or union is also anonymous.
struct v
{
union // anonymous union
{
struct { int i, j; }; // anonymous structure
struct { long k, l; } w;
};
int m;
} v1;
v1.i = 2; // valid
v1.k = 3; // invalid: inner structure is not anonymous
v1.w.k = 5; // valid
C 函数传入和返回 struct/enum/union(浅拷贝)及它们的指针。(但是不支持返回数组)。
#include <stdio.h>
struct foo {
int x, y;
};
struct foo f(void)
{
return (struct foo){.x=34, .y=90};
}
int main(void)
{
struct foo a = f(); // Copy is made
printf("%d %d\n", a.x, a.y);
}
3.8 枚举 #
枚举成员的名称占据全局全局或 block 命名空间, 不同枚举类型的成员名称不能相同 ,但是 union、struct 的
field 是局限在对应的对象空间。
- enums scope as you’d expect. If at file scope, the whole file can see it. If in a block, it’s local to that block.
enum 和 struct/union 一样,是一种类型,enum 类型的占用空间取决于最大的枚举值,一般未指定时为 unsigned int:
- 枚举值默认为前一个成员值 + 1,第一个成员默认值为 0;
- 两个枚举成员的值可以相同;
enum app_status {PENDING, RUNNING, CANCELD, DONE, FAILED}; // 定义枚举类型
enum app_status {PENDING, RUNNING, CANCELD=10, DONE, FAILED}; // DONE=11,FAILED=12,
// 值可以重复
enum {
X=2,
Y=2,
Z=2
};
enum {
A, // 0, default starting value
B, // 1
C=4, // 4, manually set
D, // 5
E, // 6
F=3 // 3, manually set
G, // 4
H // 5
};
// 最后一个成员后面可以加逗号
enum {
X=2,
Y=18,
Z=-2, // <-- Trailing comma
};
// Declare an enum and some initialized variables of that type:
enum resource { // <-- type is now "enum resource"
SHEEP,
WHEAT,
WOOD,
BRICK,
ORE
} r = BRICK, s = WOOD;
// 匿名 enum
enum {
SHEEP,
WHEAT,
WOOD,
BRICK,
ORE
} r = BRICK, s = WOOD;
使用:
枚举值是编译时常量, 所以成员一般使用大写命名,可以作为数组的大小参数, 以及 switch case 的值;- 不支持取地址操作。
- 枚举值为整型值, 所以可以用在任何需要整型值的地方:
// 定义枚举类型:Named enum, type is "enum resource"
enum resource {
SHEEP,
WHEAT,
WOOD,
BRICK,
ORE
};
// 枚举成员值在 file scope 里可以直接使用
// 声明枚举类型的变量:Declare a variable "r" of type "enum resource"
enum resource r = BRICK; // 枚举成员位于全局作用域,所以可以直接使用。
if (r == BRICK) {
printf("I'll trade you a brick for two sheep.\n");
}
enum color { RED, GREEN, BLUE } c = RED, *cp = &c; // 定义枚举类的同时, 定义两个变量值.
// introduces the type enum color
// the integer constants RED, GREEN, BLUE
// the object c of type enum color
// the object cp of type pointer to enum color
// 枚举值可以作为编译时常量使用.
int myarr[WOOD];
enum color { RED, GREEN, BLUE } r = RED;
switch(r)
{
case RED:
puts("red");
break;
case GREEN:
puts("green");
break;
case BLUE:
puts("blue");
break;
}
enum { TEN = 10 };
struct S { int x : TEN; }; // also OK
// enum 值可以用于需要整型值的地方
enum { ONE = 1, TWO } e;
long n = ONE; // promotion
double d = ONE; // conversion
e = 1.2; // conversion, e is now ONE
e = e + 1; // e is now TWO
#include <stdio.h>
enum Color {
RED,
GREEN,
BLUE
};
int main() {
enum Color color = RED;
// int *pColor = &color; // 可以取枚举变量的地址
// int *pRed = &RED; // 错误:不能取枚举成员的地址
return 0;
}
typedef 重命名:
typedef enum {
SHEEP,
WHEAT,
WOOD,
BRICK,
ORE
} RESOURCE;
RESOURCE r = BRICK;
enum color { RED, GREEN, BLUE };
typedef enum color color_t;
color_t x = GREEN; // OK
可以在 struct/union 成员中定义 enum, 然后在外围还是可以使用的:
struct Element
{
int z;
enum State { SOLID, LIQUID, GAS, PLASMA } state;
} oxygen = { 8, GAS };
// type enum State and its enumeration constants stay visible here, e.g.
void foo(void)
{
enum State e = LIQUID; // OK
printf("%d %d %d ", e, oxygen.state, PLASMA); // prints 1 2 3
}
成员分隔符:
- enum:逗号;
- union/struct/bit-field:分号;
3.9 C99 复合字面量 #
大括号初始化表达式有一定局限性:
- 只能用于初始化,不能用于后续赋值;
- 只能使用常量表达式;
C99 支持复合字面量(Compound Literals),复合字面量可以用于 初始化和后续赋值 结构体、联合体、数组和它们的指针:
- 对于数组,一旦初始化后,不支持作为左值进行赋值,所以不能再用复合字面量赋值。
- struct/union 初始化后,还是可以用复合字面量进行赋值。
- 复合字面量中的值可以是常量表达式或
变量。
复合字面量使用场景:
- 全局或局部变量初始化;
- 变量赋值;
- 函数传参,这时可以省去一个临时变量。
复合字面量也支持取地址操作。
-
结构体 :
struct MyStruct { int a; float b; }; struct MyStruct globalStruct = (struct MyStruct){ .a = 10, .b = 3.14 }; -
联合体 :
union MyUnion { int i; float f; }; union MyUnion globalUnion = (union MyUnion){ .i = 10 }; -
数组 :
int globalArray[] = (int[]){ 1, 2, 3, 4, 5 }; // 只能是初始化时使用,初始化后不能再赋值 -
指针 :
// 结构体示例 struct MyStruct { int a; float b; }; struct MyStruct *globalStructPtr = &(struct MyStruct){ .a = 10, .b = 3.14 }; // 数组示例 int *globalArrayPtr = (int[]){ 1, 2, 3, 4, 5 };
示例代码:
#include <stdio.h>
// 结构体示例
struct MyStruct {
int a;
float b;
};
struct MyStruct globalStruct = (struct MyStruct){ .a = 10, .b = 3.14 };
// 联合体示例
union MyUnion {
int i;
float f;
};
union MyUnion globalUnion = (union MyUnion){ .i = 10 };
// 数组示例
int globalArray[] = (int[]){ 1, 2, 3, 4, 5 };
int *p = (int []){1 ,2 ,3 ,4};
int sum(int p[], int count)
{
int total = 0;
for (int i = 0; i < count; i++)
total += p[i];
return total;
}
// p[] count
// |-----------------| |
int s = sum((int []){1, 2, 3, 4}, 4);
// unnamed struct
#include <stdio.h>
struct coord {
int x, y;
};
void print_coord(struct coord c)
{
printf("%d, %d\n", c.x, c.y);
}
int main(void)
{
struct coord t = {.x=10, .y=20};
print_coord(t); // prints "10, 20"
print_coord((struct coord){.x=10, .y=20}); // prints "10, 20"
}
、`
// pointer to unnamed object
#include <stdio.h>
struct coord {
int x, y;
};
void print_coord(struct coord *c)
{
printf("%d, %d\n", c->x, c->y);
}
int main(void)
{
// Note the &
// |
print_coord(&(struct coord){.x=10, .y=20}); // prints "10, 20"
}
// Pass a pointer to an int with value 3490
foo(&(int){3490});
符合字面量中使用变量:
#include <stdio.h>
struct MyStruct {
int a;
float b;
};
int main() {
int val1 = 10;
float val2 = 3.14;
// 使用复合字面量初始化结构体,可以使用变量
struct MyStruct myStruct = (struct MyStruct){ .a = val1, .b = val2 };
// 打印结构体成员
printf("a: %d, b: %.2f\n", myStruct.a, myStruct.b);
return 0;
}
compound literal 是 block 作用域:
#include <stdio.h>
int *get3490(void)
{
// Don't do this
return &(int){3490};
}
int main(void)
{
printf("%d\n", *get3490()); // INVALID: (int){3490} fell out of scope
}
int *p;
{
p = &(int){10};
}
printf("%d\n", *p); // INVALID: The (int){10} fell out of scope
3.10 隐式类型转换 #
隐式类型转换是编译器自动进行的类型转换,不需要显式地指明转换。以下是隐式类型转换的规则:
- 算术运算中的类型提升
在算术运算中,C 语言会自动将较低精度的类型提升为较高精度的类型,以保证运算的精度和结果的正确性。
- 整型提升:所有的 char/short/enum 等比 int 小的类型在参与运算时会被提升为
int 类型。- 如果 int 类型不能表示 char 和 short 类型的所有值,则提升为 unsigned int。
- 浮点型提升:float 类型在参与运算时会被提升为
double 类型。
int a = ~0xFF // 0xFF 先转换为 int 类型 0x000000FF,再取反,所以结果为 0xFFFFFF00
~0 // 0 被转换为 int,然后再取反,结果为 0xFFFFFFFF
char a = 10;
short b = 20;
int result = a + b; // a 和 b 被提升为 int 类型进行运算
float x = 1.2f;
double y = 2.4;
double result2 = x + y; // x 被提升为 double 类型进行运算
#include <stdio.h>
int main()
{
char a = 30, b = 40, c = 10;
char d = (a * b) / c; // 自动转换为 int 再计算,所以不会计算溢出
printf ("%d ", d);
return 0;
}
- 不同类型的算术运算
当不同类型的操作数进行运算时,C 语言会根据一定的规则将它们转换为相同的类型。
- 整型与浮点型运算:整型会被提升为浮点型。
- 不同大小的整型运算:较小的整型会被提升为较大的整型。
- 如果一个操作数是 long double,另一个操作数将被转换为 long double。
- 如果一个操作数是 double,另一个操作数将被转换为 double。
- 如果一个操作数是 float,另一个操作数将被转换为 float。
- 如果一个操作数是 unsigned long long,另一个操作数将被转换为 unsigned long long。
- 如果一个操作数是 long long,另一个操作数将被转换为 long long。
- 如果一个操作数是 unsigned long,另一个操作数将被转换为 unsigned long。
- 如果一个操作数是 long,另一个操作数将被转换为 long。
- 如果一个操作数是 unsigned int,另一个操作数将被转换为 unsigned int。
int a = 5;
double b = 6.7;
double result = a + b; // a 被提升为 double 类型进行运算
short c = 3;
long d = 4;
long result2 = c + d; // c 被提升为 long 类型进行运算
- 赋值运算中的类型转换
在赋值运算中,右值会被转换为左值的类型。
double a = 3.14;
int b = a; // a 被转换为 int 类型,结果为 3
- 条件表达式中的类型转换
在条件表达式中,两个操作数会被转换为相同的类型。
int a = 5;
double b = 6.7;
double result = (a < b) ? a : b; // a 被提升为 double 类型进行运算
3.11 显式类型转换 #
语法: (type_name) expression
对表达式结果做类型转换:
float x;
int y = 7;
int z = 3;
x = (float) (y / z);
x = (y / (float)z);
Type casting only works with scalar types (that is, integer, floating-point or pointer types)
. Therefore, this is not allowed:
- 不能对 array、struct 类型做强制类型转换,需要先转换为指针类型;
struct fooTag { /* members ... */ };
struct fooTag foo;
unsigned char byteArray[8];
foo = (struct fooType) byteArray; /* Fail! */
void * 指针比较特殊,可以和任何指针类型之间转换:
int x = 10;
void *p = &x; // &x is type int*, but we store it in a void*
int *q = p; // p is void*, but we store it in an int*
# define OFFSETOF(type, member) ((int)(intptr_t)&(((type *)(void*)0)->member) )
- 原理:任意类型都可以和 void 之间相互转换,intptr_t 和 int 间也可以相互转换;
3.12 数值和字符串间转换 #
数值转换为字符串:stdio.h 中的 sprintf/snprintf
#include <stdio.h>
int main(void)
{
char s[10];
float f = 3.14159;
// Convert "f" to string, storing in "s", writing at most 10 characters including the NUL
// terminator
snprintf(s, 10, "%f", f);
printf("String value: %s\n", s); // String value: 3.141590
}
字符串到数组:stdlib.h 中的 atoX 和 strtoX 函数:
| Function | Description |
|---|---|
| atoi | String to int |
| atof | String to float |
| atol | String to long int |
| atoll | String to long long int |
或者(更好的方式):
| Function | Description |
|---|---|
| strtol | String to long int |
| strtoll | String to long long int |
| strtoul | String to unsigned long int |
| strtoull | String to unsigned long long int |
| strtof | String to float |
| strtod | String to double |
| strtold | String to long double |
atox 的问题主要是不能判断返回的 0 是否是真实值还是出错情况。 strtoX 的优点:
- 可以指定输入数据的 base;
- 可以指示是否出错(传入一个 char **p):
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
char *pi = "3.14159";
float f;
f = atof(pi);
printf("%f\n", f);
int x = atoi("what"); // "What" ain't no number I ever heard of。返回值 0.
}
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
char *s = "101010"; // What's the meaning of this number?
// Convert string s, a number in base 2, to an unsigned long int.
unsigned long int x = strtoul(s, NULL, 2);
printf("%lu\n", x); // 42
char *s = "34x90"; // "x" is not a valid digit in base 10!
char *badchar; // 一个字符指针变量
// Convert string s, a number in base 10, to an unsigned long int.
unsigned long int x = strtoul(s, &badchar, 10); // 传入 badchar 的地址,这样 strtoul 在出错时可以修改它的值
// It tries to convert as much as possible, so gets this far:
printf("%lu\n", x); // 34
// But we can see the offending bad character because badchar
// points to it!
printf("Invalid character: %c\n", *badchar); // "x"
char *s = "3490"; // "x" is not a valid digit in base 10!
char *badchar;
// Convert string s, a number in base 10, to an unsigned long int.
unsigned long int x = strtoul(s, &badchar, 10);
// Check if things went well
if (*badchar == '\0') {
printf("Success! %lu\n", x);
} else {
printf("Partial conversion: %lu\n", x);
printf("Invalid character: %c\n", *badchar);
}
}
4 变量声明和定义 #
C 的变量、函数都必须先声明才能使用(注意不是先定义再使用), 声明可以位于全局作用域,声明也可以位于函数内的局部作用域。定义的同时自动声明。
在一行上可以声明多个变量并初始化,注意指针是和标识符结合的:
int a, b, c=0;
int a=0, b=0, c=0;
int *ap=NULL, b=0, *cp=&c; // ap 和 cp 是指针变量,b 是 int 类型变量
int a, b, c;
a=b=c=0; // 赋值是表达式而非语句,故有值,可以传递。
C 允许的重复定义或声明情况(一般在头文件中使用):
- 宏定义,如果重复定义不一致时,编译器警告;
- typedef 类型定义,重复定义必须一致,否则编译器报错;
- 函数原型声明、extern 变量或常量声明:重复声明必须一致,否则编译器报错;
- struct/union/enum 前向声明(incomplete types),在他们的定义之后也能使用前向声明;
C 不允许重复定义的情况(这些定义一般只在 c 文件中定义而不在头文件中使用):
- 常量、变量、函数定义;
- struct/union/enum 类型定义;
局部变量:可以用相同类型的任意表达式初始化;
全局变量:全局变量的初始值会被保存到编译后的可执行程序中,所以必须是编译时可定的常量表达式。用常量表达式(constant expression)来初始化,有如下限制:
- 必须是常量表达式:初始化表达式在编译时可确定。
- 不允许动态内存分配:不能在全局变量初始化中使用动态内存分配函数。
- 不能调用函数:初始化表达式不能调用函数。
C 常量表达式类型包括:
- 字面量常量:整数、浮点数、字符、字符串字面量。
- 枚举常量:在 `enum` 声明中定义的枚举值。
- `sizeof` 表达式。
- `_Alignof` 表达式。
- 常量组合表达式:包含常量操作数的算术或逻辑表达式。
- C99 支持的复合字面量。
注意:上面是对全局变量初始化值的限制(必须是编译时确定的常量表达式),但是 全局变量类型 是没有限制的,基本类型/struct/union/enum/pointer 等都是可以的。
// 宏定义常量和运算。
#define SIZE 10
#define MULTIPLIED_SIZE (SIZE * 2)
#define IS_POSITIVE (SIZE > 0)
// 有效的初始化
int globalInt1 = 10;
float globalFloat1 = 3.14;
char *globalStr1 = "Hello";
// 无效的初始化
int globalInt2 = someFunction(); // 错误:运行时计算
float globalFloat2 = globalInt1 * 2; // 错误:非常量表达式
// 自动初始化为零值
int globalInt3; // 初始化为 0
float globalFloat3; // 初始化为 0.0f
char *globalStr2; // 初始化为 NULL
// struct 类型全局变量初始化:
struct MyStruct {
int a;
float b;
};
struct MyStruct globalStruct = {10, 3.14}; // 有效
struct MyStruct globalStruct2; // 初始化为 {0, 0.0f}
对于全局变量、静态变量,如果未初始化,默认值为 0/NULL/""。但是对于局部变量(自动变量),如果未初始化,值是未定义的。
4 种 Type Qualifiers: const,volatile,restrict,_Atomic
5 种 storage class: auto, extern, register, and static,_Thread_local .
4.1 scope #
C 支持 4 类 scope:
- block scope
- file scope
- function scope
- function prototype scope
Scope:表示标识符的有效性或可见性:声明的标识符从声明的位置开始,到文件结束或函数返回的位置;
- 最佳实践:将全局变量、全局常量、函数签名、typedef 定义、宏定义放到头文件中,然后被其他源文件包含,这样可以实现全局可见。
int foo(double); // declaration
int foo(double x){ return x; } // definition
extern int n; // declaration
int n = 10; // definition
struct X; // declaration
struct X { int n; }; // definition
block scope:
- 变量定义位置:可以位于函数内任意位置(C99 支持),只要在使用前先定义即可。
#include <stdio.h>
int main(void)
{
int a = 12; // Local to outer block, but visible in inner block
if (a == 12) {
int b = 99; // Local to inner block, not visible in outer block
printf("%d %d\n", a, b); // OK: "12 99"
}
printf("%d\n", a); // OK, we're still in a's scope
printf("%d\n", b); // ILLEGAL, out of b's scope
}
变量隐藏:
- the one at the inner scope takes precedence as long as you’re running in the inner scope.
#include <stdio.h>
int main(void)
{
int i = 10;
{
int i = 20;
printf("%d\n", i); // Inner scope i, 20 (outer i is hidden)
}
printf("%d\n", i); // Outer scope i, 10
}
for-loop scope:C11 支持:
for (int i = 0; i < 10; i++)
printf("%d\n", i);
printf("%d\n", i); // ILLEGAL--i is only in scope for the for-loop
label:函数作用域,不能跨函数。
4.2 前向声明 #
前向声明,也称 Incomplete Types,可以用于解决源文件中类型的相互(循环)依赖。
- 前向声明是一个未完成定义的类型,不是外部变量。
下面代码可以正常编译:We never gave a size for a. And we have pointers to structs foo, bar, and baz
that never seem to be declared anywhere. These are examples of incomplete types.
- 必须是指针或 extern 数组。因为即使不知道数组的定义,但是它的指针变量大小是固定的。
int main(void)
{
struct foo *x;
union bar *y;
enum baz *z;
}
An incomplete type is a type the size (i.e. the size you’d get back from sizeof) for which is not known. Another way to think of it is a type that you haven’t finished declaring .
You can have a pointer to an incomplete type, but you can’t dereference it or use pointer arithmetic on it . And you can’t sizeof it.
- incomplete 的主要使用场景是声明一个数组,或者在没有实际定义 struct 时,定义他的一个指针变量;
Incomplte Types 类型:
- Declaring a struct or union with no body makes an incomplete type, e.g.
struct foo;. - enums are incomplete until the closing brace.
- void is an incomplete type.
- Arrays declared extern with no size are incomplete, e.g.:
extern int a[];If it’s a non-extern array with no size followed by an initializer, it’s incomplete until the closing brace of the initializer.
使用场景:
-
struct 自引用:
struct node { int val; struct node *next; // struct node is incomplete, but that's OK! }; struct a { struct b *x; // Refers to a `struct b` }; struct b { struct a *x; // Refers to a `struct a` }; -
header 文件中声明数组变量:
// File: bar.h #ifndef BAR_H #define BAR_H extern int my_array[]; // Incomplete type #endif // File: bar.c int my_array[1024]; // Complete type! // File: foo.c #include <stdio.h> #include "bar.h" // includes the incomplete type for my_array int main(void) { my_array[0] = 10; printf("%d\n", my_array[0]); } // gcc -o foo foo.c bar.c -
header 文件中循环依赖
// 前向声明,该类型实际在其它文件中定义。
struct Rect;
// 同一文件或其它文件可以重复声明。
struct Rect;
// 函数原型声明,使用前向声明的类型 struct Rect。
bool is_in_rect(My_Point point, struct Rect rect);
Completing Incomplete Types: If you have an incomplete type, you can complete it by defining the complete struct, union, enum, or array in the same scope .
struct foo; // incomplete type
struct foo *p; // pointer, no problem
// struct foo f; // Error: incomplete type!
struct foo {
int x, y, z;
}; // Now the struct foo is complete!
struct foo f; // Success!
void *p; // OK: pointer to incomplete type
只有看到了前向声明的完整定义后,函数或表达式才能使用该类型的值。
常见的 Incomplete Type 编译错误消息:
- invalid application of ‘sizeof’ to incomplete type
- invalid use of undefined type
- dereferencing pointer to incomplete type
- Most likely culprit:
you probably forgot to #include the header file that declares the type.
4.3 const #
const causes the variable to be read-only; after initialization, its value may not be changed. 一旦初始化后就不能修改:
const int x = 2;
x = 4; // COMPILER PUKING SOUNDS, can't assign to a constant
void foo(const int x)
{
printf("%d\n", x + 30); // OK, doesn't modify "x"
}
const 和指针结合使用时,顺序影响语义。
- const int *p; // Can’t modify what p points to
- int const *p; // Can’t modify what p points to, just like the previous line
- int *const p; // We can’t modify “p” with pointer arithmetic
- const int *const p; // Can’t modify p or *p!
char a[] = "abcd";
const char *p = a;
p++; // p 可以修改;
p[0] = 'A'; // Compiler error! Can't change what it points to
int *const p; // We can't modify "p" with pointer arithmetic
p++; // Compiler error!
int x = 10;
int *const p = &x;
*p = 20; // Set "x" to 20, no problem
char **p;
p++; // OK!
(*p)++; // OK!
char **const p;
p++; // Error!
(*p)++; // OK!
char *const *p;
p++; // OK!
(*p)++; // Error!
char *const *const p;
p++; // Error!
(*p)++; // Error!
在进行 const 变量到 pointer 复制时,编译器可能警告:
const int x = 20;
int *p = &x;
// ^ ^
// | |
// int* const int*
// initialization discards 'const' qualifier from pointer type target
*p = 40; // Undefined behavior--maybe it modifies "x", maybe not!
4.4 restrict #
restrict 用于 修饰指针类型 , 用于告诉编译器只会用传入的指针对某块内存进行修改, 而不会有其它指针或修改方式, 这样编译器可以做对应优化. 如果用于数组, 表示对数组的各元素有上面的语义;
void f(int n, int * restrict p, int * restrict q)
{
while (n-- > 0)
*p++ = *q++; // none of the objects modified through *p is the same
// as any of the objects read through *q
// compiler free to optimize, vectorize, page map, etc.
}
void g(void)
{
extern int d[100];
f(50, d + 50, d); // OK
f(50, d + 1, d); // Undefined behavior: d[1] is accessed through both p and q in f
}
// restrict 类型的指针可以赋值给非 restrict 类型指针
void f(int n, float * restrict r, float * restrict s)
{
float *p = r, *q = s; // OK
while (n-- > 0)
*p++ = *q++; // almost certainly optimized just like *r++ = *s++
}
restrict is a hint to the compiler that a particular piece of memory will only be accessed by one pointer and never another. (That is, there will be no aliasing of the particular object the restrict
pointer points to.) If a developer declares a pointer to be restrict and then accesses the object it
points to in another way (e.g. via another pointer), the behavior is undefined.
Basically you’re telling C, “Hey—I guarantee that this one single pointer is the only way I access this memory, and if I’m lying, you can pull undefined behavior on me.”
And C uses that information to perform certain optimizations. For instance, if you’re dereferencing
the restrict pointer repeatedly in a loop, C might decide to cache the result in a register and only
store the final result once the loop completes. If any other pointer referred to that same memory
and accessed it in the loop, the results would not be accurate. (Note that restrict has no effect if
the object pointed to is never written to. It’s all about optimizations surrounding writes to memory.)
Let’s write a function to swap two variables, and we’ll use the restrict keyword to assure C that we’ll never pass in pointers to the same thing. And then let’s blow it and try passing in pointers to the same thing.
restrict has block scope, that is, the restriction only lasts for the scope it’s used. If it’s in a
parameter list for a function, it’s in the block scope of that function.
If the restricted pointer points to an array, it only applies to the individual objects in the
array. Other pointers could read and write from the array as long as they didn’t read or write any
of the same elements as the restricted one.
You’re likely to see this in library functions like printf():
int printf(const char * restrict format, ...);
Again, that’s just telling the compiler that inside the printf() function, there will be only one pointer that refers to any part of that format string.
4.5 volatile #
volatile 告诉编译器,相关的读写语句不能被优化掉。场景的场景是 MEMIO 读写设备寄存器时,必须每次都直接读写内存地址代表的设备寄存器,来获取和设置值。编译器不能缓存或优化掉相关的读写语句。
volatile tells the compiler that the variable is explicitly changeable, and seemingly useless
accesses of the variable (for instance, via pointers) should not be optimized away. You might use
volatile variables to store data that is updated via callback functions or signal handlers. Sequence
Points and Signal Delivery.
volatile float currentTemperature = 40.0;
volatile int *p;
4.6 atomic #
https://beej.us/guide/bgc/html/split-wide/chapter-atomics.html
Atomic 修饰符
#include <stdio.h>
#include <stdatomic.h>
int main(void)
{
struct point {
float x, y;
};
_Atomic(struct point) p;
struct point t;
p = (struct point){1, 2}; // Atomic copy
//printf("%f\n", p.x); // Error
t = p; // Atomic copy
printf("%f\n", t.x); // OK!
}
4.7 storage class #
Storage-class specifiers are similar to type quantifiers. They give the compiler more information about the type of a variable.
5 种 storage class:There are four storage class specifiers that you can prepend to your variable declarations which change how the variables are stored in memory:
auto, extern, register, and static,_Thread_local.
auto:对于函数的 local variable,默认就是 auto 的,所以一般不加该关键字。
void foo (int value)
{
auto int x = value;
//…
return;
}
static:和 auto 相反,当用用于函数内部变量时,当函数返回后变量继续有效,后续调用该函数时值为上次设置的值,故称为 static storage duration:
- 函数内的 static 变量只在程序启动时初始化一次(默认初始化为 0),而非调用该函数时初始化。
#include <stdio.h>
void counter(void)
{
static int count = 1; // This is initialized one time
static int foo; // Default starting value is `0`...
static int foo = 0; // So the `0` assignment is redundant
printf("This has been called %d time(s)\n", count);
count++;
}
int main(void)
{
counter(); // "This has been called 1 time(s)"
counter(); // "This has been called 2 time(s)"
counter(); // "This has been called 3 time(s)"
counter(); // "This has been called 4 time(s)"
}
也可以在 top level(非函数内部)对变量或函数声明&定义使用 static,这表还该变量或函数只在这个文件内可见,不同文件的 static 类型变量或函数是不可见的(可以重名),这称为 static linkage:
The extern storage-class specifier gives us a way to refer to objects in other source files. A final
note about extern on functions. For functions, extern is the default, so it’s redundant. You can
declare a function static if you only want it visible in a single source file.
extern 用于变量或函数声明,表示该变量或函数的定义可能位于其它文件或本文件的后面,这样编译时即使没看到它们的定义(在链接时检查),也可以使用他们:
- 对于全局变量或 static 变量,如果没有明确初始化,则为 0 值。
// foo.c
extern int a;
int main(void)
{
printf("%d\n", a); // 37, from bar.c!
a = 99;
printf("%d\n", a); // Same "a" from bar.c, but it's now 99
}
// foo.c
int main(void)
{
extern int a;
printf("%d\n", a); // 37, from bar.c!
a = 99;
printf("%d\n", a); // Same "a" from bar.c, but it's now 99
}
register : This is a keyword to hint to the compiler that this variable is frequently-used, and
should be made as fast as possible to access. The compiler is under no obligation to agree to it.
#include <stdio.h>
int main(void)
{
register int a; // Make "a" as fast to use as possible.
for (a = 0; a < 10; a++)
printf("%d\n", a);
}
register int a;
int *p = &a; // COMPILER ERROR! Can't take address of a register
register int a[] = {11, 22, 33, 44, 55};
int *p = a; // COMPILER ERROR! Can't take address of a[0]
register int a[] = {11, 22, 33, 44, 55};
int a = a[2]; // COMPILER WARNING!
4.8 _Thread_local #
When you’re using multiple threads and you have some variables in either global or static block scope, this is a way to make sure that each thread gets its own copy of the variable. This’ll help you avoid race conditions and threads stepping on each other’s toes.
If you’re in block scope, you have to use this along with either extern or static.
Also, if you include <threads.h>, you can use the rather more palatable thread_local as an alias for the uglier _Thread_local.
More information can be found in the Threads section.
4.9 _Alignas 类型修饰符 #
用于在变量声明时,为类型指定对齐规则的类型修饰符(type specifier)。
C 内置类型修饰符是 _Alignas, 标准库 <stdalign.h> 也提供了更方便使用的 alignas 宏。
Syntax
- _Alignas ( expression ) (1) (since C11)
- alignas ( expression ) (2) (since C23)
- _Alignas ( type ) (3) (since C11)
- alignas ( type ) (4) (since C23)
// 按指定类型大小对齐
char alignas(int) c;
// 按指定大小(或常量表达式)值对齐
char alignas(8) c; // align on 8-byte boundaries
// 使用 <stddef.h> 中指定的类型最大对齐方式
char alignas(max_align_t) c;
例子:
#include <stdalign.h>
#include <stdio.h>
// every object of type struct sse_t will be aligned to 16-byte boundary (note: needs support for DR
// 444)
struct sse_t
{
alignas(16) float sse_data[4];
};
// every object of type struct data will be aligned to 128-byte boundary
struct data
{
char x;
alignas(128) char cacheline[128]; // over-aligned array of char,
// not array of over-aligned chars
};
int main(void)
{
printf("sizeof(data) = %zu (1 byte + 127 bytes padding + 128-byte array)\n", sizeof(struct data));
printf("alignment of sse_t is %zu\n", alignof(struct sse_t));
alignas(2048) struct data d; // this instance of data is aligned even stricter
(void)d; // suppresses "maybe unused" warning
}
4.10 alignof and _Alignof 运算符 #
返回任意 类型(而非表达式) 的对齐字节数,参数为类型名称,返回值为 size_t 类型(定义在 <stddef.h>),需要使用 %zu 来打印。
- _Alignof: since C11, 是内置操作符号;
- alignof: since C23, 由 <stdalign.h> 定义的 alignof macro;
示例:
#include <stdalign.h>
#include <stdio.h> // for printf()
#include <stddef.h> // for max_align_t
struct t {
int a;
char b;
float c;
};
int main(void)
{
printf("char : %zu\n", alignof(char));
printf("short : %zu\n", alignof(short));
printf("int : %zu\n", alignof(int));
printf("long : %zu\n", alignof(long));
printf("long long : %zu\n", alignof(long long));
printf("double : %zu\n", alignof(double));
printf("long double: %zu\n", alignof(long double));
printf("struct t : %zu\n", alignof(struct t));
printf("max_align_t: %zu\n", alignof(max_align_t));
}
在 MacOS 上的执行结果:
char : 1
short : 2
int : 4
long : 8
long long : 8
double : 8
long double: 16
struct t : 16
max_align_t: 16
4.11 typedef 语句 #
typedef 语句用于定义重命名类型,typedef 是文件作用域,可以在多个文件中重复定义,但是定义类型必须一致。
typedef int antelope; // Make "antelope" an alias for "int"
antelope x = 10; // Type "antelope" is the same as type "int"
struct animal {
char *name;
int leg_count, speed;
};
// original name new name
// | |
// v v
// |-----------| |----|
typedef struct animal animal;
struct animal y; // This works
animal z; // This also works because "animal" is an alias
typedef float app_float;
// and
app_float f1, f2, f3;
typedef int *intptr;
int a = 10;
intptr x = &a; // "intptr" is type "int*"
// Make type five_ints an array of 5 ints
typedef int five_ints[5];
five_ints x = {11, 22, 33, 44, 55};
用于给类型重命名,可以重复定义,但是需要确保定义一致:
typedef int int_t; // declares int_t to be an alias for the type int
typedef char char_t, *char_p, (*fp)(void); // declares char_t to be an alias for char
// char_p to be an alias for char*
// fp to be an alias for char(*)(void)
// A typedef for a VLA can only appear at block scope. The length of the array is evaluated each
// time the flow of control passes over the typedef declaration, as opposed to the declaration of
// the array itself:
void copyt(int n)
{
typedef int B[n]; // B is a VLA, its size is n, evaluated now
n += 1;
B a; // size of a is n from before +=1
int b[n]; // a and b are different sizes
for (int i = 1; i < n; i++)
a[i-1] = b[i];
}
// typedef name may be an incomplete type, which may be completed as usual:
typedef int A[]; // A is int[]
A a = {1, 2}, b = {3,4,5}; // type of a is int[2], type of b is int[3]
typedef struct tnode tnode; // tnode in ordinary name space
// is an alias to tnode in tag name space
struct tnode {
int count;
tnode *left, *right; // same as struct tnode *left, *right;
}; // now tnode is also a complete type
tnode s, *sp; // same as struct tnode s, *sp;
typedef struct { double hi, lo; } range;
range z, *zp;
// array of 5 pointers to functions returning pointers to arrays of 3 ints
int (*(*callbacks[5])(void))[3]
// same with typedefs
typedef int arr_t[3]; // arr_t is array of 3 int
typedef arr_t* (*fp)(void); // pointer to function returning arr_t*
fp callbacks[5];
#if defined(_LP64)
typedef int wchar_t;
#else
typedef long wchar_t;
#endif
5 运算符和表达式 #
• Expressions: • Assignment Operators: • Incrementing and Decrementing: • Arithmetic Operators: • Complex Conjugation: • Comparison Operators: • Logical Operators: • Bit Shifting: • Bitwise Logical Operators: • Pointer Operators: • The sizeof Operator: • Type Casts: • Array Subscripts: • Function Calls as Expressions: • The Comma Operator: • Member Access Expressions: • Conditional Expressions: • Statements and Declarations in Expressions: • Operator Precedence: • Order of Evaluation:
An expression consists of at least one operand and zero or more operators. Operands are typed
objects such as constants, variables, and function calls that return values.
表达式是 至少包含一个操作数+可选的运算符 组成,表达式可以组合形成更复杂的表达式:
- 运算符具有优先级和结合性规则。
- 通过括号 () 来调整计算优先级。
47
2 + 2
cosine(3.14159) /* We presume this returns a floating point value. */
( 2 * ( ( 3 + 10 ) - ( 2 * 6 ) ) )
表达式的是一种计算逻辑,一般是为了获得计算结果,但有时不关注结果而是利用计算过程中产生的副作用(如文件读写)。
运算符:除了常规的算术、关系、逻辑、位运算外,还有:
- 赋值运算符:赋值运算符的结果还是值,所以可以链式赋值。
- 自增、自减运算符;
- sizeof 运算符;
- 类型转换运算符;
- 数组下标运算符;
- 指针运算符;
- 函数调用表达式
- 成员访问表达式
- 条件表达式
5.1 逗号运算符 #
在 C 语言中,逗号运算符是一个顺序点,它允许在一个表达式中执行多个操作, 并返回最后一个操作的结果 。逗号运算符的语法为 (expression1, expression2),它首先计算 expression1,然后计算 expression2,并返回
expression2 的值。
逗号运算符用于分割相关的表达式,如前一个表达式值影响后一个表达式值:
x++, y = x * x;
// 更一般的是在声明中使用逗号运算符
/* Using the comma operator in a for statement. */
for (x = 1, y = 10; x <=10 && y >=1; x++, y--)
{
// …
}
// 使用逗号运算符的函数调用,传给函数的第二个参数实际为 x
foo(x, (y=47, x), z);
5.2 sizeof 运算符 #
sizeof 是一个运算符,可以返回类型或任意表达式的结果大小,如果操作数是类型,则必须要使用括号包含:
size_t a = sizeof(int);
size_t b = sizeof(float);
size_t c = sizeof(5);
size_t d = sizeof(5.143);
size_t e = sizeof a;
// 定义一个指针变量 n,然后使用 sizeof *n 来获得表达式 *n 值类型的大小。
int *n = malloc(sizeof *n);
#include <stddef.h>
#include <stdio.h>
static const int values[] = { 1, 2, 48, 681 };
#define ARRAYSIZE(x) (sizeof x/sizeof x[0]) // 这两个 sizeof 运算符的参数都是表达式
int main (int argc, char *argv[])
{
size_t i;
for (i = 0; i < ARRAYSIZE(values); i++)
{
printf("%d\n", values[i]);
}
return 0;
}
sizeof 不能正确计算两类类型的大小:
- 含有 zero size array 的 struct 大小;
- 作为函数参数的数组;
sizeof 的结果类型是 size_t (在 stddef.h 中定义),对应一个 unsigned int 类型。
sizeof 运算符在编译时求值, 结果是编译时常量 ,所以可以用于初始化全局变量(必须用常量表达式初始化)。
You can use the sizeof operator to obtain the size (in bytes) of the data type of its operand. The
operand may be an actual type specifier (such as int or float), as well as any valid expression
. When the operand is a type name, it must be enclosed in parentheses. Here are some examples:
The result of the sizeof operator is of a type called size_t, which is defined in the header file
<stddef.h>. size_t is an unsigned integer type, perhaps identical to unsigned int or unsigned long int ; it varies from system to system. The size_t type is often a convenient type for a loop index,
since it is guaranteed to be able to hold the number of elements in any array; this is not the case
with int, for example.
The sizeof operator can be used to automatically compute the number of elements in an array:
#include <stddef.h> // size_t
#include <stdio.h>
static const int values[] = { 1, 2, 48, 681 };
#define ARRAYSIZE(x) (sizeof x/sizeof x[0]) // 传入的 x 必须是数组名,而不能是它的指针
int main (int argc, char *argv[])
{
size_t i;
for (i = 0; i < ARRAYSIZE(values); i++)
{
printf("%d\n", values[i]);
}
return 0;
}
There are two cases where this technique does not work. The first is where the array element has
zero size (GCC supports zero-sized structures as a GNU extension). The second is where the array is
in fact a function parameter (see Function Parameters).
5.3 offsetof 运算符 #
Defined in header <stddef.h>
#define offsetof(type, member) /*implementation-defined*/
返回值类型是 <stddef.h> 中定义的 size_t 类型.
#include <stdio.h>
#include <stddef.h>
struct S {
char c;
double d;
};
int main(void)
{
printf("the first element is at offset %zu\n", offsetof(struct S, c));
printf("the double is at offset %zu\n", offsetof(struct S, d));
5.4 条件运算符 #
a ? b : c
Expressions b and c must be compatible . That is, they must both be
- arithmetic types(自动类型转换)
- compatible
struct or uniontypes pointersto compatible types (one of which might be the NULL pointer)
Alternatively, one operand is a pointer and the other is a void* pointer.
5.5 运算符优先级和结合性 #
对于一个操作数 + 运算符组成的表达式,计算顺序是由运算符的优先级决定的,即一个操作数两边有两个运算符时,先按照高优先级运算符计算,当操作数两边运算符优先级一致时,按照结合性(自左向右,或自右向左)来计算。
优先级:后缀运算符 》单目运算符 》乘性 》加性 》左右移动 》关系 》逻辑 》 位运算符 》三目 》赋值 》逗号。例如:foo = *p++; 等效于 foo = *(p++);
优先级:
- Function calls, array subscripting, and membership access operator expressions.
- Unary operators, including logical negation, bitwise complement, increment, decrement, unary positive, unary negative, indirection operator, address operator, type casting, and sizeof expressions. When several unary operators are consecutive, the later ones are nested within the earlier ones: !-x means !(-x).
- Multiplication, division, and modular division expressions.
- Addition and subtraction expressions.
- Bitwise shifting expressions.
- Greater-than, less-than, greater-than-or-equal-to, and less-than-or-equal-to
- expressions.
- Equal-to and not-equal-to expressions.
- Bitwise AND expressions.
- Bitwise exclusive OR expressions.
- Bitwise inclusive OR expressions.
- Logical AND expressions.
- Logical OR expressions.
- Conditional expressions (using ?:). When used as subexpressions, these are evaluated right to left.
- All assignment expressions, including compound assignment. When multiple assignment statements appear as subexpressions in a single larger expression, they are evaluated right to left.
- Comma operator expressions.
5.6 side effects #
表达式计算(求值)的目录是获得计算结果,但有时表达式计算目的并不是获得结算结果,而是求值过程中的副作用(side effects):
- 修改一个对象;
- 读写一个文件;
- 调用其它产生上面副作用的函数;
编译器在编译程序时,可能会调整指令的顺序(不一定和源文件一致),但是需要确保副作用能符合预期的完成。
编译器为了确保副作用按照正确的顺序产生,C89/C90 定义了一些 sequence points:
- a call to a function (after argument evaluation is complete)
- the end of the left-hand operand of the and operator &&
- the end of the left-hand operand of the or operator ||
- the end of the left-hand operand of the comma operator ,
- the end of the first operand of the ternary operator a ? b : c
- the end of a full declarator 2
- the end of an initialisation expression
- the end of an expression statement (i.e. an expression followed by ;)
- the end of the controlling expression of an if or switch statement
- the end of the controlling expression of a while or do statement
- the end of any of the three controlling expressions of a for statement
- the end of the expression in a return statement
- immediately before the return of a library function
- after the actions associated with an item of formatted I/O (as used for example with the strftime or the printf and scanf famlies of functions).
- immediately before and after a call to a comparison function (as called for example by qsort)
At a sequence point, all the side effects of previous expression evaluations must be complete, and no side effects of later evaluations may have taken place.
This may seem a little hard to grasp, but there is another way to consider this. Imagine you wrote a
library (some of whose functions are external and perhaps others not) and compiled it, allowing
someone else to call one of your functions from their code. The definitions above ensure that, at
the time they call your function, the data they pass in has values which are consistent with the behaviour specified by the abstract machine , and any data returned by your function has a state
which is also consistent with the abstract machine. This includes data accessible via pointers
(i.e. not just function parameters and identifiers with external linkage).
The above is a slight simplification, since compilers exist that perform whole-program optimisation at link time. Importantly however, although they might perform optimisations, the visible side effects of the program must be the same as if they were produced by the abstract machine.
Between two sequence points,
- an object may have its stored value modified
at most onceby the evaluation of an expression - the prior value of the object shall be
read onlyto determine the value to be stored.
所以下面两个表达式(语句)是不允许的:
i = ++i + 1;
int x=0; foo(++x, ++x)
5.7 求值顺序未定 #
在 C 语言中,编译器对表达式中 子表达式的求值顺序没有明确的规定 。因此,你不能假设子表达式会按照你认为的自然顺序进行求值。
- 求值顺序的非确定性
C 标准对某些表达式的求值顺序没有明确规定,这使得不同编译器或不同编译选项可能会以不同的顺序计算子表达式。 求值顺序的非确定性意味着在一个表达式中,哪部分先求值并不总是确定的 。
int x = 10;
int y = (x + 1) * (x + 2);
在这个表达式中,编译器可能先计算 (x + 1),也可能先计算 (x + 2)。虽然这在这个简单的例子中并不影响最终结果, 但在更复杂的表达式中可能会导致不同的行为 。
- 副作用和求值顺序
副作用是指表达式在求值过程中对存储器状态的改变,例如变量赋值、函数调用等。如果一个表达式中包含副作用且依赖于求值顺序,结果可能会变得不可预测。
int i = 1;
int result = (i++) + (i++);
在这个例子中,i 的值在表达式计算过程中发生变化,但 C 标准并没有规定 i++ 的求值顺序。因此,result 的值可能会因编译器的不同而不同。
- 函数参数求值顺序
在函数调用中, 函数参数的求值顺序同样是未定义的 ,这意味着参数的求值顺序取决于编译器的实现。
void foo(int a, int b) {
printf("a: %d, b: %d\n", a, b);
}
int main() {
int x = 1;
foo(x++, x++);
return 0;
}
在这个例子中,foo(x++, x++) 中的两个 x++ 的求值顺序未定义,因此 foo 函数接收到的参数值是不可预测的。
- 确保确定性的方法
为了确保代码的可预测性和正确性, 应该避免在同一个表达式中使用多个具有副作用的子表达式 。可以通过拆分复杂表达式、避免依赖未定义的求值顺序来确保代码行为的一致性。
改写上面的例子,使其行为确定:
int i = 1;
int a = i++;
int b = i++;
int result = a + b;
// 或者
int x = 1;
int a = x++;
int b = x++;
foo(a, b);
总结
- 求值顺序未定义:C 语言标准不规定某些表达式中子表达式的求值顺序。
- 副作用:在同一表达式中使用多个具有副作用的子表达式可能会导致不可预测的行为。
- 函数参数求值顺序:函数参数的求值顺序未定义,不同编译器可能产生不同的结果。
- 确保确定性:通过拆分复杂表达式和避免依赖未定义求值顺序来确保代码的确定性和可读性。
5.8 Order of Evaluation #
The correspondence between the program you write and the things the computer actually does are
specified in terms of side effects and sequence points .
6 语句 #
表达式的是一种计算逻辑,一般是为了获得计算结果,但有时不关注结果而是利用计算过程中产生的副作用(如文件读写)。
运算符:除了常规的算术、关系、逻辑、位运算外,还有:
- 赋值运算符:赋值运算符的结果还是值,所以可以链式赋值。
- 自增、自减运算符;
- sizeof 运算符;
- 类型转换运算符;
- 数组下标运算符;
- 指针运算符;
- 函数调用表达式
- 成员访问表达式
- 条件表达式
运算符 + 操作数 -》表达式 -》语句。
语句:执行计算、流程控制等。
- 最常见的语句是表达式语句,即以分号结尾的表达式。
- block 语句创建新的 scope,可以包含多个语句。
表达式语句需要以分号结尾,但是不是每个语句都以分号结尾,例如 if/switch/while 等。
// 表达式语句
5;
2 + 2;
10 >= 9;
x++;
y = x + 25; // 赋值运算符
puts ("Hello, user!");
*cucumber;
You write statements to cause actions and to control flow within your programs. You can also write
statements that do not do anything at all, or do things that are uselessly trivial.
• Expression Statements: 在表达式结尾添加分号,就是表达式语句。
剩下的这些语句用于流程控制、分支跳转等:• Labels: • The if Statement: • The switch Statement: • The while Statement: • The do Statement: • The for Statement: • Blocks: • The Null Statement: • The goto Statement: • The break Statement: • The continue Statement: • The return Statement: • The typedef Statement:
6.1 switch #
switch 语法:
- test 和各分支的 compare-xx 都是
表达式; - 所有表达式的结果必须都是
整型,而且 case 分支的 campare-x 表达式结果必须是整型常量;
switch (test)
{
case compare-1:
if-equal-statement-1
case compare-2:
if-equal-statement-2
…
default:
default-statement
}
匹配某个 case 后,默认执行该 case 和剩余 case 中的指令,除非遇到了 break:
int x = 0;
switch (x)
{
case 0:
puts ("x is 0");
case 1:
puts ("x is 1");
default:
puts ("x is something else");
}
/* 输出: */
/* x is 0 */
/* x is 1 */
/* x is something else */
// 解决办法:
switch (x)
{
case 0:
puts ("x is 0");
break;
case 1:
puts ("x is 1");
break;
default:
puts ("x is something else");
break;
}
作为 GNU C 扩展,case 支持范围匹配:case low … high:
case 'A' ... 'Z':
case 1 ... 5:
// 而不是:
// case 1...5:
6.2 Blocks #
A block is a set of zero or more statements enclosed in braces. Blocks are also known as compound statements.
for (x = 1; x <= 10; x++)
{
if ((x % 2) == 0)
{
printf ("x is %d\n", x);
printf ("%d is even\n", x);
}
else
{
printf ("x is %d\n", x);
printf ("%d is odd\n", x);
}
}
You can declare variables inside a block; such variables are local to that block. In C89,
declarations must occur before other statements, and so sometimes it is useful to introduce a block
simply for this purpose:
{
int x = 5;
printf ("%d\n", x);
}
printf ("%d\n", x); /* Compilation error! x exists only
in the preceding block. */
6.3 goto #
goto 是函数作用域:goto label 的 label 必须位于同一个函数中,label 位置无限制,如 goto 语句之前或之后。
- setjmp、longjmp 实现跨函数的跳转,如从深层次嵌套的调用栈跳转到先前 setjmp 定义的位置。
// continue
for (int i = 0; i < 3; i++) {
for (int j = 0; j < 3; j++) {
for (int k = 0; k < 3; k++) {
printf("%d, %d, %d\n", i, j, k);
goto continue_i; // Now continuing the i loop!!
}
}
continue_i: ;
}
// break
for (int i = 0; i < 3; i++) {
for (int j = 0; j < 3; j++) {
printf("%d, %d\n", i, j);
goto break_i; // Now breaking out of the i loop!
}
}
break_i:
printf("Done!\n");
// 重试中断的系统调用
retry:
byte_count = read(0, buf, sizeof(buf) - 1); // Unix read() syscall
if (byte_count == -1) { // An error occurred...
if (errno == EINTR) { // But it was just interrupted
printf("Restarting...\n");
goto retry;
}
goto 带来的变量作用域问题:编译器告警 warning: ‘x’ is used uninitialized in this function
goto label;
{
int x = 12345;
label:
printf("%d\n", x);
};
{
int x = 10;
label:
printf("%d\n", x);
}
goto label;
//解决办法
goto label;
{
int x;
label:
x = 12345;
printf("%d\n", x);
}
7 函数 #
• Function Declarations: • Function Definitions: • Calling Functions: • Function Parameters: • Variable Length Parameter Lists: • Calling Functions Through Function Pointers: • The main Function: • Recursive Functions: • Static Functions: • Nested Functions:
函数声明:可以重复声明但是需要确保声明的函数签名是一致的。
- 函数声明的 extern 关键字可以省略;
- 函数必须指定返回类型。如果没有返回值,必须使用 void。如果不需要输入参数则也使用 void 而不是空参数列表 ();
- 函数声明可以位于任意作用域,但是函数定义只能位于全局作用域;
- 函数声明时可以不指定参数名称,但是一定要指定各类型;
int function(void);
void func(void);
函数定义:整个程序只能定义一次,否则会编译时报错。
编译器不为函数声明分配存储空间,而主要用来进行编译时检查。但是编译器为函数定义分配存储空间,来保存编译函数后生成的指令,所以函数名或函数指针都是指向函数第一条指令的内容地址, 和普通指针相比,函数指针可以进行函数调用 。
- 函数指针和数据指针是不兼容的(但是可以强制转换):Function pointers and data pointers are not compatible, in the sense that you cannot expect to store the address of a function into a data pointer, and then copy that into a function pointer and call it successfully. It might work on some systems, but it’s not a portable technique.
如果先不声明函数,而是直接调用,则编译器会自动推断出一个函数原型:
- 入参:根据传入的参数列表自动来定;
- 出参:固定为 int;
这个推断的原型可能和后续函数定义不一致,这样编译器会告警:implicit declaration of function ‘myFunction’ [-Wimplicit-function-declaration]
#include <stdio.h>
int main() {
int result = myFunction(5); // myFunction 未声明
printf("Result: %d\n", result);
return 0;
}
/*
编译时会产生如下警告或错误(具体取决于编译器和标准):
gcc -Wall -o test test.c
test.c: In function 'main':
test.c:4:16: warning: implicit declaration of function 'myFunction' [-Wimplicit-function-declaration]
4 | int result = myFunction(5);
| ^~~~~~~~~~~
*/
作为 GNU C 扩展,可以在函数内定义嵌套函数,嵌套函数必须位于函数的开始的变量定义位置,位于其他表达式语句之前;
int factorial (int x)
{
int factorial_helper (int a, int b)
{
if (a < 1)
{
return b;
}
else
{
return factorial_helper ((a - 1), (a * b));
}
}
return factorial_helper (x, 1);
}
函数返回值:
- 支持的返回值类型:
- 基本类型:整型 (int, short, long, char 等),浮点型 (float, double 等),指针类型 (int*, char* 等);
- void 类型: 表示函数没有返回值。这通常用于不需要返回任何值的函数。
- struct/enum/union 类型,对于 struct 进行的浅拷贝;
- 指针类型:指向基本数据类型、结构体、联合体、void 等的指针。
- 不支持的返回值类型:
不能返回数组类型。但可以返回指向数组的指针或通过结构体封装数组。- 不能返回另一个函数类型,但可以返回函数指针。
// 可以是一个函数指针:
// 错误
int *(int, int) myfunc(int, int)
// 正确,func 是一个函数,输入参数是 int,int,返回的是一个 int(*)(int, int) 类型的函数指针;
int (**func(int, int))(int, int)
// 可以是一个指向数组的指针:
// func 是一个函数,输入参数是 int,int,返回的是一个 int(*)[4] 类型的指针数组;
int (**func(int, int))[4]
// 可以是一个数组指针:
// 变量定义:func 是一个函数指针变量,输入参数是 int,int,返回的是指向 4 个 int 元素的数组指针: int (*)[4]
int (*func(int, int))[4] // 变量定义:func 是一个函数指针变量
// 变量声明:func 是一个函数指针变量
extern int (*func(int, int))[4]
// C 不支持直接返回数组类型,故报错:error: function cannot return array type 'int[4]'
// int (func(int, int))[4];
// 解决办法:返回指向数组的指针;
// 变量定义:func 是一个指向函数指针的变量,该函数输入是 int,int,输出是指向 4 个 int 元素的数组指针:int(*)[4]
int (*func(int, int))[4];
// 变量声明
extern int (*func(int, int))[4];
// 返回一个函数指针
int add(int a, int b) { return a + b; }
int (*getAddFunc())(int, int) {
return add;
}
static 函数:函数默认是全局作用域,同一个函数只能有一个唯一定义。但是 static 函数是 file 作用域,只在该函数有效,其他源文件不能使用它,所以不同源文件可以定义同名的 static 函数。
函数调用是一个表达式,可以用在需要表达式或值的任何地方。
- 函数参数是 paas by value 而非 paas by refer;
- 编译器在传参时会根据形参做自动类型转换;
函数指针:函数名作为右值时代表函数体的首地址指针,后续调用时就会执行函数体的指令。
- 函数名作为右值使用时,max 和 &max 等效,都为函数体的首地址指针。
- 定义函数指针变量时,变量名必须是一个指针类型,否则不能和函数原型声明区分开;
// 函数原型声明(可选 extern,因为函数声明不能嵌套,只能是 extern 的)
int max(int a, int b);
// 函数定义(包含函数体)
int max(int a, int b) {return a>b?a:b;}
// 函数指针变量声明:与函数原型声明的差异在于,maxb 是必须是一个指针类型。
int (*maxb)(int, int);
// 函数指针变量赋值
maxb = max; // 或者:maxb = &max
// 函数指针类型定义: maxb 也必须是一个指针类型
typedef int (*maxb)(int, int);
maxb mymax = max; // 或者:maxb mymax = &max;
#include <stdio.h>
// 函数定义,编译器分配存储空间,报错函数的指令
// foo 代表该空间的首地址
void foo (int i)
{
printf ("foo %d!\n", i);
}
void bar (int i)
{
printf ("%d bar!\n", i);
}
void message (void (*func)(int), int times)
{
int j;
for (j=0; j<times; ++j)
func (j); /* (*func) (j); would be equivalent. */
}
void example (int want_foo)
{
// pf 是一个指针,指向 void (*)(int) 函数
void (*pf)(int) = &bar; /* The & is optional. */
if (want_foo)
pf = foo;
message (pf, 5);
}
函数指针数组:
- 不支持函数数组,但支持函数指针数组;
// C 也不支持定义函数数组,error: 'fa' declared as array of functions of type 'int (int, int)'//
// int (fa[4])(int, int);
// 解决办法:使用函数指针数组;
// 变量定义:fa 是一个 4 元素的数组,数组的元素为函数指针:int (*) (int, int)
int(*fa[4])(int, int);
// 注意:上面的 fa 是一个数组定义,对于外部变量声明,需要加 extern 前缀
extern int(*fa[4])(int, int);
复杂函数声明举例: void (**signal(int, void(**)(int)))(int)
- signal 是一个函数,输入参数为 int, void(*)(int), 其中第二个参数为函数指针类型,它的输入为 int,无输出;
- signal 函数的输出为 void(*)(int) ,即返回一个函数指针类型,输入为 int,无输出;
- 分析技巧:
- 先看标识符,如 signal 右侧如果有括号则说明是函数指针。
- 确认函数的输入,往右看:signal(int, void(*)(int));
- 确认函数的输出:往左看,将 signal 和输入去掉,获得函数的返回值:void (*)(int), 说明是函数指针;
7.1 可变参数 #
- When you call
va_start(), you need to pass inthe last named parameter(the one just before the …) so it knows where to start looking for the additional arguments. - And when you call
va_arg()to get the next argument, you have to tell it the type of argument to get next.
So the standard progression is:
- va_start() to initialize your va_list variable
- Repeatedly va_arg() to get the values
- va_end() to deinitialize your va_list variable
#include <stdio.h>
#include <stdarg.h>
int add(int count, ...) // 可变长参数的函数,最后一个参数值必须是 ...
{
int total = 0;
va_list va;
va_start(va, count); // Start with arguments after "count"
for (int i = 0; i < count; i++) {
int n = va_arg(va, int); // Get the next int
total += n;
}
va_end(va); // All done
return total;
}
int main(void)
{
printf("%d\n", add(4, 6, 2, -4, 17)); // 6 + 2 - 4 + 17 = 21
printf("%d\n", add(2, 22, 44)); // 22 + 44 = 66
}
使用标准库的 vprintf 来自定义 printf 函数, 其他接受 va_list 参数类型的 v 开头的函数:These functions
start with the letter v, such as vprintf(), vfprintf(), vsprintf(), and vsnprintf(). Basically all
your printf() golden oldies except with a v in front.
#include <stdio.h>
#include <stdarg.h>
int my_printf(int serial, const char *format, ...) // 可变长参数的函数,最后一个参数值必须是 ...
{
va_list va;
// Do my custom work
printf("The serial number is: %d\n", serial);
// Then pass the rest off to vprintf()
va_start(va, format);
int rv = vprintf(format, va); // vprintf 使用 va_list
va_end(va);
return rv;
}
int main(void)
{
int x = 10;
float y = 3.2;
my_printf(3490, "x is %d, y is %f\n", x, y);
}
7.2 inline 函数 #
对于频繁执行的函数,可以定义为 inline 类型,这样在编译器在对该函数调用的位置会进行代码展开,从而省去了函数调用的开销(如传参,返回等),适合于对性能有要求的场景,但是会增加可执行文件的大小。
inline 函数是文件作用域,不同文件可以定义同名的 inline 函数。但是 inline 也只是告诉编译器尽量进行优化,但实际是否优化不一定。
static inline int add(int x, int y) {
return x + y;
最佳实践:The short answer is define the inline function as static in the file that you need it. And
then use it in that one file. And you never have to worry about the rest of it.
- inline 典型的用法是和 static 连用,否则会有一堆意想不到的问题。
去掉了 static 修饰符后,如果没有开启优化编译 gcc 链接程序时会出错:
- 不带 static 的 inline 函数必须开优化编译;
- 不带 static 的 inline 函数不能引用 static 变量;
- inline 函数内定义的 static 变量必须是 const 类型;
#include <stdio.h>
// 去掉了 static 声明
inline int add(int x, int y)
{
return x + y;
}
int main(void)
{
printf("%d\n", add(1, 2));
}
static int b = 13;
inline int add(int x, int y)
{
return x + y + b; // BAD -- can't refer to b
}
inline int add(int x, int y)
{
// static int b = 13; // BAD -- can't define static
static const int b = 13; // OK -- static const
return x + y + b;
}
如果同时在不同文件中定义了同名的 inline 和不带 inline 函数,则链接时使用哪一个,取决于是否开启了编译优化:
- 如果开启了编译优化,则定义 inline 函数的文件使用 inline 版本,其他文件使用不带 inline 修饰的版本;
- 如果没有开启编译优化,则只使用不带 inline 函数版本;
7.3 noreturn 和 _Noreturn 函数 #
告诉编译器函数不会 return,通过一些其他机制退出,如 exit()/abrt(), 这样编译器在调用函数时可以进行优化。
- 方式1: 使用
_Noreturn内置关键字; - 方式2: 使用
<stdnoreturn.h>中的 noreturn 宏定义(建议);
#include <stdio.h>
#include <stdlib.h>
#include <stdnoreturn.h>
noreturn void foo(void) // This function should never return!
{
printf("Happy days\n");
exit(1); // And it doesn't return--it exits here!
}
int main(void)
{
foo();
}
If the compiler detects that a noreturn function could return, it might warn you, helpfully.
7.4 命令行参数和环境变量 #
C 程序的执行入口是 main 函数, 该函数的返回值或退出值被执行环境所捕获, 作为程序的退出码.
- 从 elf 二进制或汇编的角度看, 程序真正的执行入口是 _start 标记的 .text section.
- C 在链接可执行程序时, 会在 main 函数前后插入控制例程, 也就是 C 库提供了 _start 标记, 它来调用 main() 函数, 函数返回后执行一些清理动作.
main 函数的返回值只能是 int 类型,如果没有 return 该 int 则默认为 0:
- argv 的最后一项是 NULL:argv[argc] == NULL
int main(void); // void 是必须的,表示没有输入参数
int main(int argc, char **argv); // int main(int argc, char *argv[])
// stdlib.h 提供了 environ 变量定义和操作函数
extern char **environ;
// 或者, 非标的情况
int main(int argc, char **argv, char **environ) ;
environ:
#include <stdio.h>
extern char **environ; // MUST be extern AND named "environ"
int main(void)
{
for (char **p = environ; *p != NULL; p++) {
printf("%s\n", *p);
}
// Or you could do this:
for (int i = 0; environ[i] != NULL; i++) {
printf("%s\n", environ[i]);
}
}
// 或者使用 getenv()
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
char *val = getenv("FROTZ"); // Try to get the value
// Check to make sure it exists
if (val == NULL) {
printf("Cannot find the FROTZ environment variable\n");
return EXIT_FAILURE;
}
printf("Value: %s\n", val);
}
7.5 程序退出 #
C 各种 exit/terminal/resource cleanup 相关函数都位于 <stdlib.h> 库中。
- atexit
- registers a function to be called on exit() invocation(function)
- exit
- 调用 atexit() 注册的函数,并刷新和关闭 IO 流。
- _exit
- 不调用 atexit() 注册的函数,不刷新和关闭标准 IO 流;
- _Exit(C99)
- 和 POSIX 的 _exit 类似,但是 C99 标准,不刷新和关闭标准 IO 流;
- abort
- causes abnormal program termination (without cleaning up)(function)
- quick_exit (C11)
- causes normal program termination without completely cleaning up (function)
- at_quick_exit (C11)
- registers a function to be called on quick_exit invocation(function)
- EXIT_SUCCESS/EXIT_FAILURE
- indicates program execution execution status(macro constant)
stdlib.h 定义了两个标准返回值枚举:
| Status | Description |
|---|---|
| EXIT_SUCCESS or 0 | Program terminated successfully. |
| EXIT_FAILURE | Program terminated with an error. |
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char **argv)
{
if (argc != 3) {
printf("usage: mult x y\n");
return EXIT_FAILURE; // Indicate to shell that it didn't work
}
printf("%d\n", atoi(argv[1]) * atoi(argv[2]));
return 0; // same as EXIT_SUCCESS, everything was good.
}
正常退出:When you exit a program normally, all open I/O streams are flushed and temporary files removed . Basically it’s a nice exit where everything gets cleaned up and handled. It’s what you
want to do almost all the time unless you have reasons to do otherwise.
- 文件关闭 :打开的文件不会被关闭。
- 动态内存释放 :分配的动态内存不会被释放。
- 临时文件删除 :临时文件不会被删除。
- 自定义清理函数 :通过 `atexit()` 注册的清理函数不会被调用。
正常退出的情况:
- main 函数返回, 如显式 return,或函数结束,这时相当于 return 0;
- 调用 exit(N) 函数,可以为 exit() 注册一些 exit handlers 函数, 在 main return 或调用 exit() 时执行:
#include <stdio.h>
#include <stdlib.h>
void on_exit_1(void)
{
printf("Exit handler 1 called!\n");
}
void on_exit_2(void)
{
printf("Exit handler 2 called!\n");
}
int main(void)
{
atexit(on_exit_1);
atexit(on_exit_2);
printf("About to exit...\n");
}
/* About to exit... */
/* Exit handler 2 called! */
/* Exit handler 1 called! */
Quicker Exits with quick_exit() : This is similar to a normal exit, except:
- Open files might not be flushed.
- Temporary files might not be removed.
- atexit() handlers won’t be called.
But there is a way to register exit handlers: call at_quick_exit() analogously to how you’d call
atexit().
#include <stdio.h>
#include <stdlib.h>
void on_quick_exit_1(void)
{
printf("Quick exit handler 1 called!\n");
}
void on_quick_exit_2(void)
{
printf("Quick exit handler 2 called!\n");
}
void on_exit(void)
{
printf("Normal exit--I won't be called!\n");
}
int main(void)
{
at_quick_exit(on_quick_exit_1);
at_quick_exit(on_quick_exit_2);
atexit(on_exit); // This won't be called
printf("About to quick exit...\n");
quick_exit(0);
}
/* About to quick exit... */
/* Quick exit handler 2 called! */
/* Quick exit handler 1 called! */
直接退出,不做任何清理操作:
- 调用 _exit(N)/_Exit(N) 函数;
其他程序退出方式:
-
assert() :不做任何清理操作,它会立即终止程序,并生成一个核心转储文件(如果系统配置允许)。
goats -= 100; assert(goats >= 0); // Can't have negative goats -
abort(): 等效于收到 SIGABRT 信号。
8 参考 #
- Beej’s Guide to C Programming: https://beej.us/guide/bgc/html/split-wide/index.html
- GNU C Language Intro and Reference Manual: https://lists.gnu.org/archive/html/info-gnu/2022-09/msg00005.html
- The Development of the C Language: https://www.bell-labs.com/usr/dmr/www/chist.html