类型 #
- 基础类型:
Boolean, Numeric, Textual, Never; - 序列类型:
Tuple, Array, Slice; - 自定义类型:
Struct, Enum, Union; - 函数类型:
Functions, Closures; - 指针类型:
References, Raw pointers, Function pointers; - Trait 类型:
Trait objects, impl Trait;
注:String、Vec 是标准库类型,而非语言内置类型。
栈变量类型:
- 基础类型;
Array/Struct/Tuple/Enum/Union等;
由于 Array 在栈上分配,所以在 async 场景,由于每个 .await 位置都会返回一个保存栈变量的 Future 对象,为了避免每次大量栈内存拷贝开销,应该使用堆类型,如 Vec,来保持大对象。
堆变量类型:
- 字符串:
String; - 容器:
Vec/HashMap/HashSet; - 切片:
Slice; - 智能指针:
Box/Rc/Arc/Cell/RefCell;
// 在栈上创建一个 1000 个 i32 类型元素的数组
let a = [0; 1000];
// 转移数组的所有权到 a2,由于 a 分配在栈上,这里做了一次栈内存拷贝
let a2 = a;
// 在堆上分配一个数组,ab 的栈内存为 usize 大小的指针
let ab = Box::new([0; 1000]);
// 转移 ab 的所有权到 ab2,只是一个 usize 内存的拷贝,堆内存没有拷贝
let ab2 = ab;
切片类型对象 &[T] 可以从 Array 或 Vec<T> 或 String 或 &str 或其它 slice 对象创建出来,而且指向相同的堆内存, 所以是它们高效操作的类型。
Rust 的 Type 类型定义可以参考 https://doc.rust-lang.org/reference/types.html#grammar-Type,常见的复杂类型 Type 如下:
- Parenthesized types:
type T<'a> = &'a (dyn Any + Send); - Impl trait:
fn foo(arg: impl Trait + Send + 'static) {} - Trait objects:
dyn Trait + Send + Sync + 'static - Qualified paths:
<S as T1>::f() - Function pointer types:
type Binop = fn(i32, i32) -> i32;
类型内存布局 #
Rust 类型内存布局:
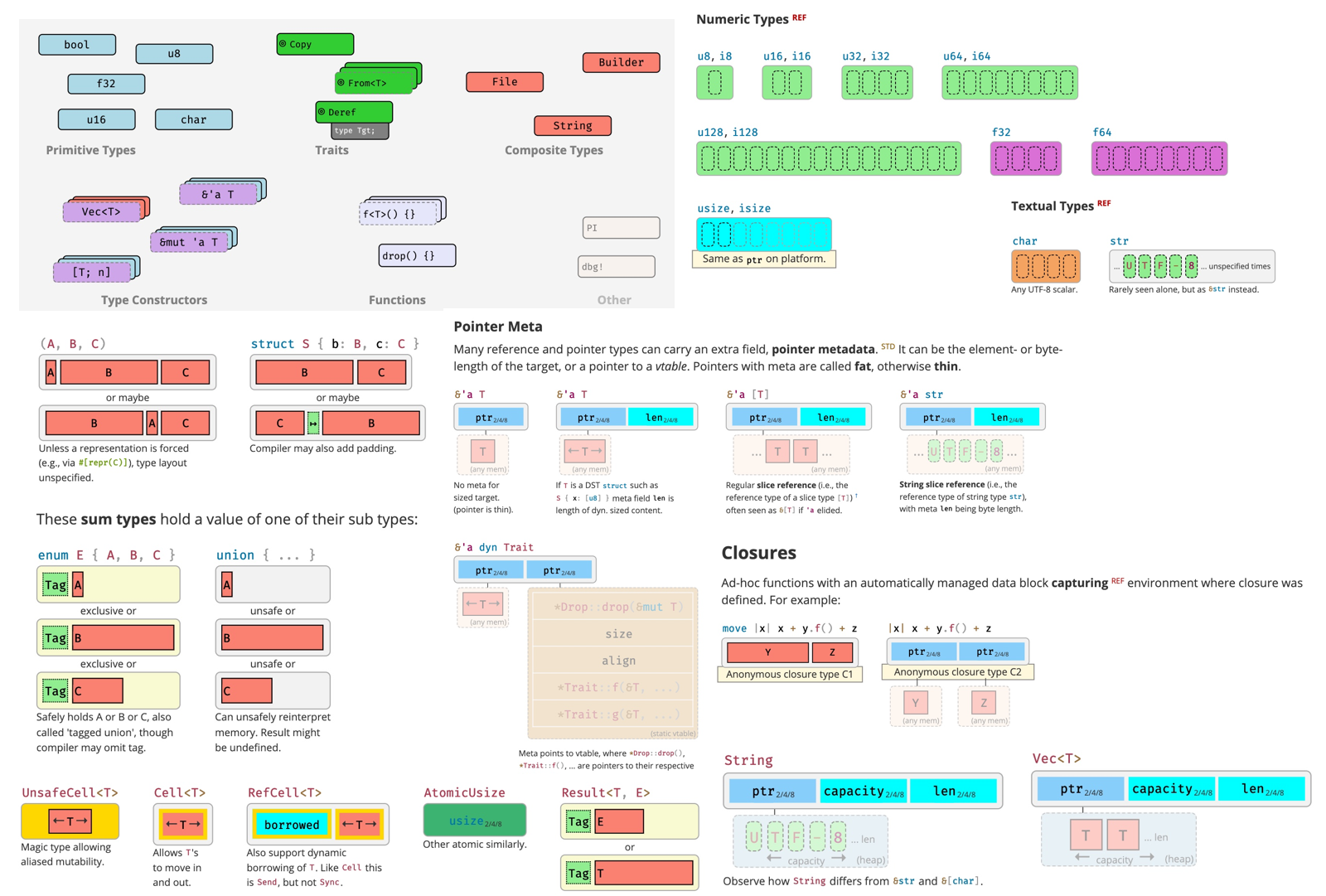
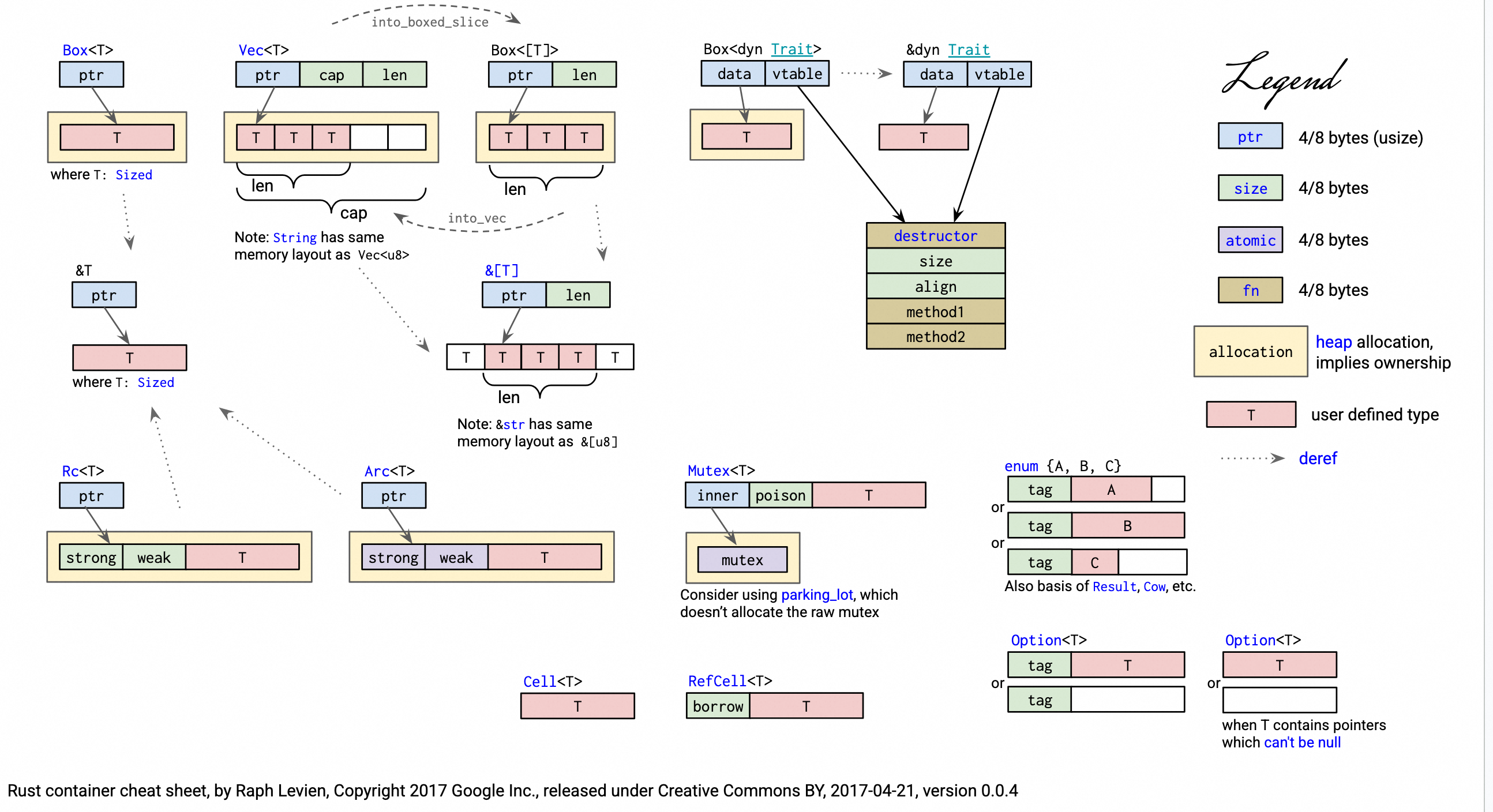
参考:
类型别名 #
类型别名(type alias)并没有引入新类型,可以按照原类型的方式使用别名类型:
// Meters 是 u32 的类型别名,支持 u32 类型的所有操作。
type Meters = u32;
let x: u32 = 5;
let y: Meters = 5;
println!("x + y = {}", x + y);
// 使用类型别名提升代码可读性。
type Thunk = Box<dyn Fn() + Send + 'static>;
let f: Thunk = Box::new(|| println!("hi"));
fn takes_long_type(f: Thunk) {}
fn returns_long_type() -> Thunk {}
// 类型别名支持泛型参数
type Result<T> = std::result::Result<T, std::io::Error>;
在定义 trait、自定义类型时,使用类型别名语法来定义关联类型:
trait Iterator {
// 使用类型别名语法来定义关联类型和它的缺省类型,关联类型也只是使用 trait 进行限界。
type Item: std::fmt::Display = i32;
fn next(&mut self) -> Option<Self::Item>;
}
scalar #
Scalar 类型:
- 有符号整型:
i8, i16, i32, i64, i128, isize,默认推断i32 - 无符号整型:
u8, u16, u32, u64, u128, usize - 浮点类型:
f32, f64, 默认推断f64 - 字符: Unicode 字符 (占用 4 byte, UTF-32),如
'a', 'α','∞' - 布尔类型
bool:true/false, 占用 1 byte - 单元类型(
unit type):类型和唯一的值都是() - Never:
!
单元类型 () 示例:
// 函数没有显式定义返回值时,等效于返回 ():fn print_message() -> () {
fn print_message() {
println!("Hello, world!");
}
fn main() {
// 打印地址相同, 说明是唯一类型值
println!("{:p}, {:p}", &(), &());
print_message();
// 显式使用单元类型和单元值
let my_unit: () = ();
// 函数参数接受单元类型值
take_unit(());
// 泛型类型也可以使用单元类型
let result: Result<(), &str> = Ok(());
match result {
Ok(_) => println!("Operation was successful."),
Err(e) => println!("Error occurred: {}", e),
}
}
数值字面量可以加类型后缀, 如 23u8, 12.3f64 ,数字/类型后缀之间可以加下划线, 如 2_3_u8 等效于 23u8 。
支持 0b/0o/0x 整型(只能使用小写字母前缀)。
let logical: bool = true;
let a_float: f64 = 1.0;
let an_integer = 5i32;
// 缺省推断:整型推断为 i32,浮点数推断为 f64
let default_float = 3.0; // f64
let default_integer = 7; // i32
// 浮点取模运算, 截断除法
let remainder = 43.0 % 5.0;
// 类型推导(从后续的赋值语句推导出类型为 i64)。
let mut inferred_type = 12;
inferred_type = 4294967296i64;
let mut mutable = 12;
mutable = 21;
// Error! The type of a variable can't be changed.
//mutable = true;
// 变量可以被 shodow(重新定义类型和可变性)
let mutable = true;
整数溢出 #
- 执行
debug构建时,整数溢出会触发panic。 - 执行
release构建时,整数溢出会导致环绕(wrapping)而不报错。
可以使用 wrapping_XX()、checking_XX() 等方法来明确溢出的行为:
| 方法名 | 语义描述 | 返回类型 | 适用场景 |
|---|---|---|---|
wrapping_add() 等 |
溢出时截断(wrap-around,取模), 环回 0 值 | 返回计算结果值 | 性能敏感、不关心溢出的算法 |
checked_add() 等 |
溢出时返回 None,否则 Some(result) | Option<T> |
需要检测和处理溢出 |
overflowing_add() 等 |
返回元组 (值, 是否溢出标志) | (T, bool) |
既需要结果又需判断是否溢出 |
saturating_add() 等 |
溢出时饱和到最大值或最小值(如 u8 最大为 255,溢出就返回 255) | 返回计算结果值 | 常用于图像、信号处理等场景 |
// u8: 0-255
let x: u8 = 255;
let y: u8 = x.wrapping_add(1);
println!("y: {}", y);
// 输出: y: 0
as 类型转换 #
Rust 不会为原始类型做隐式转换,需要使用 as 表达式来显式转换。as 是后缀运算符,优先级非常高。
内置函数 len() 默认返回 usize 类型,可以使用 as 运算符将其它类型转换为 usize 类型。
浮点数转换为整数时,小数部分将被截断(不进行四舍五入)。
let integer: u32 = 5;
let float: f64 = 3.0;
let int_to_float = integer as f64; // 5.0
let float_to_int = float as u32; // 3,截断取整
let float = 97.123_f32;
let integer: u8 = float as u8;
// let c1: char = float as char; // 浮点数不能转换为 char,报错:只有 u8 才能转换为 char
let c2 = integer as char; // 将 integer 解释为 unicode point
as 可以用于原始类型(primitive)和 type coercion 类型的转换,以及裸指针和借用之间的转换;
// 错误:
// let val: Box<dyn Any + 'a> = *val as Box<dyn Any + 'a>;
// OK:circle 可以 usized 协变到 dyn Circle
let circle = Box::new(circle) as Box<dyn Circle>;
// OK: 裸指针间转换
let a = *const [u16] as *const [u8]
// 将裸指针转换为 usize
let ptr_num_cast = ptr as *const i32 as usize;
// 将裸指针转换为借用:&T, &mut T, *const T 和 *mut T 内存布局是一致的,所以可以转换。
let ptr: *mut i32 = &mut 0;
let ref_casted = unsafe { &mut *ptr };
// 将 &mut T 转换为 &mut U:
let ptr = &mut 0;
let val_casts = unsafe { &mut *(ptr as *mut i32 as *mut u32) };
let s = Selector { elements: vec!["good", "bad", "ugly"], current: 2 };
show_it_generic(&s as &str); // 使用 as 类型转换, 根据 Deref 转换为 &str
as 表达式支持的详细列表参考:https://doc.rust-lang.org/reference/expressions/operator-expr.html#r-expr.as.pointer
&MaybeUninit<T>、&mut MaybeUninit<T>、&T、 &mut T、*const T、*mut T 的内存布局、大小、对齐都一致,可以使用 as 表达式相互转换:
// as 表达式支持的转换类型:https://doc.rust-lang.org/reference/expressions/operator-expr.html#r-expr.as.pointer
// 将裸指针转换为 usize
let ptr_num_cast = ptr as *const i32 as usize;
// 将裸指针转换为借用
// 这是因为 &T, &mut T, *const T 和 *mut T 内存布局是一致的,所以可以转换。
let ptr: *mut i32 = &mut 0;
let ref_casted = unsafe { &mut *ptr };
// 将 &mut T 转换为 &mut U:
let ptr = &mut 0;
let val_casts = unsafe { &mut *(ptr as *mut i32 as *mut u32) };
// 将 &[MaybeUninit<u8>] 转换为 *const MaybeUninit<u8>, 然后使用 as 转换为裸指针
let ma = [MaybeUninit<u8>; 32];
let mas: &[MaybeUninit<u8>] = ma;
let mac = unsafe {mas.as_ptr() as *const u8 as *mut u8} // *const T 可以转换为 *mut T
复杂类型使用 From/Into/TryFrom/TryInto/AsRef/AsMut 等 trait 来进行类型转换:
from():用于确保无风险的转换,因为它转换失败时会 panic;try_from():返回Result类型,当转换失败时(因为类型溢出或数据丢失)返回错误,可以显式检查和处理;
// From/Into 由标准库 prelude 自动导入,不需要手动导入,但其它 Trait,如 TryInto,需要显式导入。
use std::convert::TryInto;
fn main() {
let decimal = 65.4321_f64;
// 使用 TryInto trait 的 try_into 方法进行安全转换。
let integer: u8 = decimal.try_into().unwrap_or_default();
// 使用 From trait 进行结果检查的安全转换。
let integer_from = u8::from(42);
let string_from = String::from("just for test");
// 字符串的 parse::<T>() 方法可以将字符串解析转换为其它类型值,parse() 方法基于 FromStr trait 实现。
let i77 = "123".parse::<i32>().unwrap();
let i77: i32 = "123".parse().unwrap();
}
各种 Scalar 字面量有对应的 Rust 标准库类型,可以调用它们的方法:
fn main(){
let integer_from = u8::from(42);
// 下面的数值都加上了类型后缀,这是因为在调用方法的时需要知道值的类型才能找到它的方法实现:
println!("{}", 3_u8.pow(2)); // 9
println!("{}", (-3_i32).abs()); // 3
println!("{}", 45i32.count_ones()); // 4:计算45的二进制中有多少个1
}
文本类型 #
文本(textual)类型:char/str/String/OsStr/OsString/CStr/CString/Path/PathBuf。
char 是 4 字节(byteds)的 Unicode 字符码点 (UTF-32)。
使用 as 将 char 字符码点转换为 u8、u32 整型值。
as 只能从 u8 转换为 char,但可以使用 std::char::from_u32() 将整型码点值转换为 char:
let emoji: char = '😂';
let chinese_character: char = '中';
let word = "Rust语言";
for ch in word.chars() {
println!("{}", ch);
}
// 将字符转换为对应的 Unicode 码点
let unicode_codepoint = '🦀' as u32;
println!("The Unicode code point of '🦀' is: U+{:X}", unicode_codepoint);
let character_from_codepoint = std::char::from_u32(unicode_codepoint).unwrap_or_default();
println!("The character from code point U+{:X} is: '{}'", unicode_codepoint, character_from_codepoint);
str #
str 是一块连续的 u8 字节内存,保存 UTF-8 编码的字符串。
&str 的内存布局和 &[u8] 一致,&mut str 的内存布局和 &mut [u8] 一致,所以可以使用 as 表达式将 &str 转换为 &[u8] 类型;
使用 &str、Box<str> 而不是 &[u8]、Box<[u8]> 来表示字符串,主要是它们带有额外的保证,即数据必须是有效的 UTF-8 编码。
str 编译时大小未知(DST,动态大小类型),故一般不能直接作为变量类型,而使用固定大小类型的 &str 或智能指针 Box<str>/Cow<str>/Rc<str> 类型。
&str 和 Box<str>/Cow<str>/Rc<str> 是 fat pointer 类型,占两个 usize 空间,包括内存区域指针和 byte 数量。
//let s: str = "hello, world"; // 错误,str 不能直接作为类型
let s: &str = "hello, world"; // OK
let hello_world = "Hello, World!";
// 等效于
let hello_world: &'static str = "Hello, world!";
// 使用 &'static str 可以避免为 struct 指定 lifetime 参数
struct Anime {
name: &'static str,
bechdel_pass: bool
};
let aria = Anime {
name: "Aria: The Animation",
bechdel_pass: true
};
// &str 不能自动协变到 &[u8], 可以使用 as_bytes() 转换为 &[u8]
let bytes = "bors".as_bytes();
assert_eq!(b"bors", bytes);
// 字符串字面量是 &'static str 类型
let story = "Once upon a time...";
let ptr = story.as_ptr(); // 返回指向连续内存区域的 raw pointer:*const u8
let len = story.len(); // byte 数量
assert_eq!(19, len);
// 从 raw pointer 构建 slice
let s = unsafe {
// 由于 ptr 是 *const u8 类型,所以返回的 slice 是 &[u8] 类型
let slice = slice::from_raw_parts(ptr, len);
// 从 &[u8] 创建 &str
str::from_utf8(slice)
};
assert_eq!(s, Ok(story));
// 使用智能指针保存 str
let boxed: Box<str> = Box::from("hello");
assert_eq!(Cow::from("eggplant"), Cow::Borrowed("eggplant"));
let shared: Rc<str> = Rc::from("statue");
// 从 &str 创建 Vec<u8>
assert_eq!(Vec::from("123"), vec![b'1', b'2', b'3']);
// 在堆上分配字符串内存,s 拥有该对象,当 s 被 drop 时,堆内存也被释放
let s: Box<str> = "hello, world".into();
// Box<str> 实现了 Deref<Target=str>, 所以 &Box<str> 等效于 &str
greetings(&s);
其它:
b'x':存的是 ASCII code point,为 u8 类型,如104 == b'h';b"xyz": byte string,只能存 ASCII 字符串,对应&[u8; N]类型,如&[b'x', b'y',b'z'];r###"\a\b\c"###: raw string,不对字符串内容转义,后面的 # 数量可变, 但只能使用连续的 # 字符;br##"\a\b\c\t\n"##: raw byte string,只能存 ASCII 内容,类型为&[u8; N], 不对字串转义,必须以br开头而不能是rb;c"hello":C string,以 NULL 结尾的 C 字符串。cr#"hello"#:raw C string,以 NULL 结尾的 C 原生字符串。
b"byte string" 和 rb"asdaf" 类型是 &[u8; N],可以自动的被 type coercion 到 &[u8]:
let method = b"GET";
assert_eq!(method, &[b'G', b'E', b'T']);
// 错误的情况
assert_eq!(method, &['G', 'E', 'T']); // 类型是 &[char] 而非 &[u8]
assert_eq!(method, &[b"G", b"E", b"T"]); // 类型是 &[&[u8]] 而非 &[u8]
字符串可以包含换行和转义字符,默认左对齐(数字默认右对齐):
- 转义字符:
\xaF, \n, \r, \t, \\, \0, \', \", \u{0}, \u{00}, …, \u{000000} - 支持十六进制转义字符
\xaF,但不支持二进制和八进制转义字符。
let s1 = String::from("hello,");
// 字符串显示默认左对齐(数字是右对齐),显示: #hello, #
println!("#{:20.20}#", s1);
当字符串行尾以 \ 结束时会删除换行和下一行前序的空白字符:
let message = "To: jimb\r\n\
From: superego <[email protected]>\r\n\
\r\n\
Did you get any writing done today?\r\n\
When will you stop wasting time plotting fractals?
\r\n";
for header in message.lines().take_while(|l| !l.is_empty()) {
println!("{}" , header);
}
// 输出:
//To: jimb
//From: superego <[email protected]>
如果要保留行首的空格可以使用原始字符串:
let message = r"To: jimb
From: superego <[email protected]>
Did you get any writing done today?
When will you stop wasting time plotting fractals?
";
Rust 不支持连续字符串的自动拼接,需要使用 concat!() 宏或 ["abc", "def"].concat() 方法。
let message = concat!("To: jimb\r\n", " From: superego <[email protected]>\r\n",
"\r\n",
" Did you get any writing done today?\r\n",
" When will you stop wasting time plotting fractals?\r\n");
String 和 &str 的索引(index)操作返回 str, 所以需要在对结果进行借用,如 &mystr[..]。
要保证 &s[i..j] 的 i..j 是有效的字符边界,否则 panic,可以使用 non-panicking 的 get(i..j) 方法。
s[i] 是禁止的,因为 String/&str 是 UTF-8 编码,返回单个 byte (u8) 是无意义的。
let s = String::from("hello world");
let hello = &s[0..5]; // &str 类型
println!("{}", hello);
let s = "hello";
// println!("The first letter of s is {}", s[0]); // 错误,&str 不支持 s[i];
// 使用 as_bytes() 方法将 String/&str 转换为 &[u8], index 操作返回 u8:
let s = "hello";
assert_eq!(s.as_bytes()[0], 104);
assert_eq!(s.as_bytes()[0], b'h');
let s = "💖💖💖💖💖";
assert_eq!(s.as_bytes()[0], 240);
内存布局:
String:三部分:指向堆内存的指针,内存的长度(bytes),内存的容量(bytes),是可变长度类型;&str:两部分:指向堆内存的指针,内存的长度(bytes);
String 和 &str 都是严格 UTF-8 编码,但是对于操作系统文件名或路径,可能不是有效的 UTF-8 编码字符串,所以 Rust 引入了 std::ffi::OsStr/OsString 类型:
OsStr: 类似于 str,是 unsized type,一般需要以&OsStr/Box<OsStr>使用,不可改变;OsString: 类似于 String,是 sized type,是 OsStr 的 Owned 类型,可变。它实现了Deref<target = OsStr>;
use std::ffi::OsStr;
let os_str = OsStr::new("foo");
// OsStr 的方法:
pub fn as_encoded_bytes(&self) -> &[u8]
pub fn into_os_string(self: Box<OsStr>) -> OsString // 消耗自身
pub fn make_ascii_lowercase(&mut self)
pub fn to_os_string(&self) -> OsString
pub fn to_str(&self) -> Option<&str>
pub fn to_string_lossy(&self) -> Cow<'_, str>
std::ffi::CStr 和 std::ffi::CString 是 C 风格的、以 NULL 终止的字符串,主要在和 C 代码交互时使用:
c"hello":以 NULL 结尾的 C 原生字符串;cr#"hello"#:以 NULL 结尾的 C 原生字符串,不支持转义字符;
use std::ffi::CString;
use std::ffi::c_char;
fn main() {
let s = String::from("Hello, world!");
let cs = CString::new(s).unwrap();
let p = cs.as_ptr() as *const c_char;
println!("Address: {:?}", p);
}
str 方法:
- len() : 返回 byte 数量
- as_bytes() -> &[u8]
- as_ptr()/as_mut_ptr():返回 raw pointer:
*const u8和*mut u8 - get()/get_mut(): 安全返回子串, 不会 panic,参数是一个 index range
- chars()/bytes():返回 char 或 byte 的迭代器
- split_whitespace(): 返回空白字符分割的子串迭代器,连续的空白字符等效为一个
- lines(): 返回行迭代器,行尾不包括换行
- contains()/starts_with()/ends_with(): 检查 pattern,pattern 支持多种类型
- find()/rfind(): 返回匹配 pattern 的 index
- match()/rmatch(): 返回匹配 pattern 的子串迭代器
- trim_XX()/strip_XX(): 删除空格、删除前后缀
- parse::
(): 将字符串转换为 T 类型,T 必须要实现 FromStr trait - replace(): 将 pattern 替换为子串
- into_string()/to_string(): 将 &str 转换为 String
// 返回字符串的 bytes(而非字符)数量
pub const fn len(&self) -> usize
let len = "foo".len();
assert_eq!(3, len); // 字节长度
assert_eq!("ƒoo".chars().;l(), 3); // 字符数量
pub const fn is_empty(&self) -> bool
pub fn is_char_boundary(&self, index: usize) -> bool
// Finds the closest x not exceeding index where is_char_boundary(x) is true.
pub fn floor_char_boundary(&self, index: usize) -> usize
pub fn ceil_char_boundary(&self, index: usize) -> usize
#![feature(round_char_boundary)]
let s = "❤️🧡💛💚💙💜";
assert_eq!(s.len(), 26);
assert!(!s.is_char_boundary(13));
let closest = s.floor_char_boundary(13);
assert_eq!(closest, 10);
assert_eq!(&s[..closest], "❤️🧡");
// 转换为 slice
pub const fn as_bytes(&self) -> &[u8]
pub unsafe fn as_bytes_mut(&mut self) -> &mut [u8]
let bytes = "bors".as_bytes();
assert_eq!(b"bors", bytes);
let mut s = String::from("Hello");
let bytes = unsafe { s.as_bytes_mut() };
assert_eq!(b"Hello", bytes);
// 转换为 raw pointer
pub const fn as_ptr(&self) -> *const u8
pub fn as_mut_ptr(&mut self) -> *mut u8
let s = "Hello";
let ptr = s.as_ptr(); // *const u8
// 安全返回一个子字符串 &str(不 panic),如果不在字符串边界则返回 None
pub fn get<I>(&self, i: I) -> Option<&<I as SliceIndex<str>>::Output> where I: SliceIndex<str>
pub fn get_mut<I>( &mut self, i: I) -> Option<&mut <I as SliceIndex<str>>::Output> where I: SliceIndex<str>
let v = String::from("🗻∈🌏");
assert_eq!(Some("🗻"), v.get(0..4));
assert!(v.get(1..).is_none());
assert!(v.get(..8).is_none());
assert!(v.get(..42).is_none());
// 返回一个子字符串 &str,调用者确保传入的 index 范围是有效的,否则会 panic
pub unsafe fn get_unchecked<I>(&self, i: I) -> &<I as SliceIndex<str>>::Output where I: SliceIndex<str>
pub unsafe fn get_unchecked_mut<I>( &mut self, i: I ) -> &mut <I as SliceIndex<str>>::Output where I: SliceIndex<str>
// 分割字符串
pub fn split_at(&self, mid: usize) -> (&str, &str)
pub fn split_at_mut(&mut self, mid: usize) -> (&mut str, &mut str)
pub fn split_at_checked(&self, mid: usize) -> Option<(&str, &str)>
pub fn split_at_mut_checked( &mut self, mid: usize ) -> Option<(&mut str, &mut str)>
// 返回字符串的 char 或 byte 迭代器
pub fn chars(&self) -> Chars<'_>
pub fn char_indices(&self) -> CharIndices<'_>
pub fn bytes(&self) -> Bytes<'_>
// 返回空白字符分割的子字符串迭代器, 多个连续空白字符视为一个
pub fn split_whitespace(&self) -> SplitWhitespace<'_>
pub fn split_ascii_whitespace(&self) -> SplitAsciiWhitespace<'_>
// 返回的迭代器对象必须是 mut 类型,因为迭代时会修改它的内部状态
let mut iter = " Mary had\ta\u{2009}little \n\t lamb".split_whitespace();
assert_eq!(Some("Mary"), iter.next());
assert_eq!(Some("had"), iter.next());
assert_eq!(Some("a"), iter.next());
assert_eq!(Some("little"), iter.next());
assert_eq!(Some("lamb"), iter.next());
assert_eq!(None, iter.next());
assert_eq!("".split_whitespace().next(), None);
assert_eq!(" ".split_whitespace().next(), None);
// 返回行迭代器,如果是空行则返回空字符串,不包括行尾的换行
pub fn lines(&self) -> Lines<'_>
pub fn lines_any(&self) -> LinesAny<'_>
let text = "foo\nbar\n\r\nbaz";
let mut lines = text.lines();
assert_eq!(Some("foo"), lines.next());
assert_eq!(Some("bar"), lines.next());
assert_eq!(Some(""), lines.next());
assert_eq!(Some("baz"), lines.next());
assert_eq!(None, lines.next());
pub fn encode_utf16(&self) -> EncodeUtf16<'_>
// 是否包含 pattern
pub fn contains<'a, P>(&'a self, pat: P) -> bool where P: Pattern<'a>
// 是否以 pattern 开始或结束
pub fn starts_with<'a, P>(&'a self, pat: P) -> bool where P: Pattern<'a>
pub fn ends_with<'a, P>(&'a self, pat: P) -> bool where P: Pattern<'a>, <P as Pattern<'a>>::Searcher: ReverseSearcher<'a>
// find 返回匹配 pattern 的 index,如果为找到则返回 None
pub fn find<'a, P>(&'a self, pat: P) -> Option<usize> where P: Pattern<'a>
pub fn rfind<'a, P>(&'a self, pat: P) -> Option<usize> where P: Pattern<'a>, <P as Pattern<'a>>::Searcher: ReverseSearcher<'a>
// 拆分字符串为可迭代的子串 &str
pub fn split<'a, P>(&'a self, pat: P) -> Split<'a, P> where P: Pattern<'a>
pub fn split_inclusive<'a, P>(&'a self, pat: P) -> SplitInclusive<'a, P> where P: Pattern<'a>
pub fn split_terminator<'a, P>(&'a self, pat: P) -> SplitTerminator<'a, P> where P: Pattern<'a>
pub fn splitn<'a, P>(&'a self, n: usize, pat: P) -> SplitN<'a, P> where P: Pattern<'a>
pub fn split_once<'a, P>(&'a self, delimiter: P) -> Option<(&'a str, &'a str)> where P: Pattern<'a>
pub fn rsplit<'a, P>(&'a self, pat: P) -> RSplit<'a, P> where P: Pattern<'a>, <P as Pattern<'a>>::Searcher: ReverseSearcher<'a>
pub fn rsplit_terminator<'a, P>(&'a self, pat: P) -> RSplitTerminator<'a, P> where P: Pattern<'a>, <P as Pattern<'a>>::Searcher: ReverseSearcher<'a>
pub fn rsplitn<'a, P>(&'a self, n: usize, pat: P) -> RSplitN<'a, P> where P: Pattern<'a>, <P as Pattern<'a>>::Searcher: ReverseSearcher<'a>
pub fn rsplit_once<'a, P>(&'a self, delimiter: P) -> Option<(&'a str, &'a str)> where P: Pattern<'a>, <P as Pattern<'a>>::Searcher: ReverseSearcher<'a>
let v: Vec<&str> = "Mary had a little lamb".split(' ').collect();
assert_eq!(v, ["Mary", "had", "a", "little", "lamb"]);
let v: Vec<&str> = "".split('X').collect();
assert_eq!(v, [""]);
let v: Vec<&str> = "lionXXtigerXleopard".split('X').collect();
assert_eq!(v, ["lion", "", "tiger", "leopard"]);
// 返回匹配 pattern 的子字符串迭代器
pub fn matches<'a, P>(&'a self, pat: P) -> Matches<'a, P> where P: Pattern<'a>
pub fn match_indices<'a, P>(&'a self, pat: P) -> MatchIndices<'a, P> where P: Pattern<'a>
pub fn rmatches<'a, P>(&'a self, pat: P) -> RMatches<'a, P> where P: Pattern<'a>, <P as Pattern<'a>>::Searcher: ReverseSearcher<'a>
pub fn rmatch_indices<'a, P>(&'a self, pat: P) -> RMatchIndices<'a, P> where P: Pattern<'a>, <P as Pattern<'a>>::Searcher: ReverseSearcher<'a>
let v: Vec<&str> = "abcXXXabcYYYabc".matches("abc").collect();
assert_eq!(v, ["abc", "abc", "abc"]);
let v: Vec<&str> = "1abc2abc3".matches(char::is_numeric).collect();
assert_eq!(v, ["1", "2", "3"]);
// 删除(执行多次)start/end 两端的空格
pub fn trim(&self) -> &str
pub fn trim_start(&self) -> &str
pub fn trim_end(&self) -> &str
// 删除(执行多次)两端匹配的 pattern
pub fn trim_matches<'a, P>(&'a self, pat: P) -> &'a str where P: Pattern<'a>, <P as Pattern<'a>>::Searcher: DoubleEndedSearcher<'a>
pub fn trim_start_matches<'a, P>(&'a self, pat: P) -> &'a str where P: Pattern<'a>
pub fn trim_end_matches<'a, P>(&'a self, pat: P) -> &'a str where P: Pattern<'a>, <P as Pattern<'a>>::Searcher: ReverseSearcher<'a>
// 删除开头的前缀,最多删除一次
pub fn strip_prefix<'a, P>(&'a self, prefix: P) -> Option<&'a str> where P: Pattern<'a>
pub fn strip_suffix<'a, P>(&'a self, suffix: P) -> Option<&'a str> where P: Pattern<'a>, <P as Pattern<'a>>::Searcher: ReverseSearcher<'a>
// 将字符串转换为其他类型 F,F 类型需要实现 FromStr trait。
pub fn parse<F>(&self) -> Result<F, <F as FromStr>::Err> where F: FromStr
pub const fn is_ascii(&self) -> bool
pub const fn as_ascii(&self) -> Option<&[AsciiChar]>
pub fn eq_ignore_ascii_case(&self, other: &str) -> bool
pub fn make_ascii_uppercase(&mut self)
pub fn make_ascii_lowercase(&mut self)
pub const fn trim_ascii_start(&self) -> &str
pub const fn trim_ascii_end(&self) -> &str
pub const fn trim_ascii(&self) -> &str
pub fn escape_debug(&self) -> EscapeDebug<'_>
pub fn escape_default(&self) -> EscapeDefault<'_>
pub fn escape_unicode(&self) -> EscapeUnicode<'_>
pub fn into_boxed_bytes(self: Box<str>) -> Box<[u8]>
pub fn into_string(self: Box<str>) -> String
pub fn replace<'a, P>(&'a self, from: P, to: &str) -> String where P: Pattern<'a>
pub fn replacen<'a, P>(&'a self, pat: P, to: &str, count: usize) -> String where P: Pattern<'a>
pub fn repeat(&self, n: usize) -> String
pub fn to_lowercase(&self) -> String
pub fn to_uppercase(&self) -> String
pub fn to_ascii_uppercase(&self) -> String
pub fn to_ascii_lowercase(&self) -> String
find/match/trim() 方法的 Pattern 参数类型:
| Pattern type | Match condition |
|---|---|
| &str | 子字符串 |
| char | 单字符 |
| &[char] | slice 中任意单字符 |
| F: FnMut(char) -> bool | F 返回 true 的字符 |
| &&str | 子字符串 |
| &String | 子字符串 |
// &str
assert_eq!("abaaa".find("ba"), Some(1));
assert_eq!("abaaa".find("bac"), None);
// char
assert_eq!("abaaa".find('a'), Some(0));
assert_eq!("abaaa".find('b'), Some(1));
assert_eq!("abaaa".find('c'), None);
// 注:参数是 &[char; N] 类型,而不是 &[u8; N]
assert_eq!("ab".find(&['b', 'a']), Some(0));
assert_eq!("abaaa".find(&['a', 'z']), Some(0));
assert_eq!("abaaa".find(&['c', 'd']), None);
// &[char]
// ['b', 'a'] 的 [..] 的优先级比 & 高,所以实际是先 index 返回 [char] 再 & 返回 &[char]
assert_eq!("ab".find(&['b', 'a'][..]), Some(0));
assert_eq!("abaaa".find(&['a', 'z'][..]), Some(0));
assert_eq!("abaaa".find(&['c', 'd'][..]), None);
// FnMut(char) -> bool
assert_eq!("abcdef_z".find(|ch| ch > 'd' && ch < 'y'), Some(4));
assert_eq!("abcddd_z".find(|ch| ch > 'd' && ch < 'y'), None);
let v: Vec<&str> = "1abc2abc3".matches(char::is_numeric).collect();
FromStr trait: 从 &str 来生成各种类型的值:
- Rust 基本类型都实现了该 trait,如整数、浮点数、bool、char、String、PathBuf、IpAddr、SocketAddr、Ipv4Addr、Ipv6Addr 等;
- 被泛型方法
&str.parse::<T>()隐式调用;
pub trait FromStr: Sized {
type Err;
// Required method
fn from_str(s: &str) -> Result<Self, Self::Err>;
}
// str 的 parse<F>() 泛型方法:
pub fn parse<F>(&self) -> Result<F, <F as FromStr>::Err> where F: FromStr
let four: u32 = "4".parse().unwrap();
assert_eq!(4, four);
let four = "4".parse::<u32>();
assert_eq!(Ok(4), four);
// Error
let nope = "j".parse::<u32>();
assert!(nope.is_err());
String #
&str 和 String 间转换:
String -> &str:String.as_str();&str -> Strig:String::from("Sunfei")或"Sunface".to_string();
创建 String:
- &str.to_string()
- &str.to_owned()
- format!()
- Array/slice/Vec 的 .concat() 和 .join() 方法
- String::from()/String::from_utf8() 方法
let error_message = "too many pets".to_string();
assert_eq!(format!("{}°{:02}′{:02}′′N", 24, 5, 23), "24°05′23′′N".to_string());
let bits = vec!["veni", "vidi", "vici"];
assert_eq!(bits.concat(), "venividivici");
assert_eq!(bits.join(", "), "veni, vidi, vici");
let hello = String::from("Hello, world!");
let mut hello = String::from("Hello, ");
hello.push('w');
hello.push_str("orld!");
let sparkle_heart = vec![240, 159, 146, 150];
let sparkle_heart = String::from_utf8(sparkle_heart).unwrap();
assert_eq!("💖", sparkle_heart);
let s = "hello";
let third_character = s.chars().nth(2);
assert_eq!(third_character, Some('l'));
let noodles = "noodles".to_string();
let oodles = &noodles[1..]; // String/str 的 slice 操作返回 str,需要再借用返回 &str
String 可以 +/+= &str, 但是不支持 &str 之间的 +/+= 以及 &str + String 的操作:
let mut ss = String::from("abcd");
ss += " def"; // OK: String + &str
// 错误:`+` cannot be used to concatenate a `&str` with a `String`
// " def" + ss;
" def".to_owned() + &ss; // OK
let s1 = String::from("hello,");
let s2 = String::from("world!");
let s3 = s1 + &s2; // let s3 = s1.clone() +&s2;
assert_eq!(s3, "hello,world!");
//println!("{}", s1); // s1 已经在上面的 + 操作被 move, 导致继续使用 s1 出错。
String 底层是 Vec<u8>, 使用连续的堆内存来保存字符串,它的栈内存布局包括三部分,可以使用 as_ptr()/len()/capacity() 来获取它们的值:
- 指向堆连续内存的地址;
- 内存 byte 长度;
- 内存 byte 容量(因为 String 是可变长的);
let story = String::from("Once upon a time...");
// Prevent automatically dropping the String's data
let mut story = std::mem::ManuallyDrop::new(story);
let ptr = story.as_mut_ptr();
let len = story.len();
let capacity = story.capacity();
assert_eq!(19, len);
let s = unsafe { String::from_raw_parts(ptr, len, capacity) } ;
assert_eq!(String::from("Once upon a time..."), s);
String 实现了 Deref<Target=str>, 所以 String 类型可以使用 str 定义的所有方法,在需要 &str 类型的地方可以传入 &String。
String 方法:
- new()/with_capacity()
- len()/capacity()/is_empty()
- from_utf8_XX()
- into_raw_parts()/from_raw_parts()
- into_bytes()/into_boxed_str()/as_bytes()/as_str()/as_mut_str()
- push()/push_str()
- reserve()/shrink_to()/truncate()/clear()
- pop()/remove()/retaion()
- insert()/insert_str()
- drain()/clear()
// 空 String
pub const fn new() -> String
// 指定初始容量的空 String
pub fn with_capacity(capacity: usize) -> String
// 从 Vec<u8> 创建 String
pub fn from_utf8(vec: Vec<u8>) -> Result<String, FromUtf8Error>
pub unsafe fn from_utf8_unchecked(bytes: Vec<u8>) -> String
// 从 &[u8] 创建 String
pub fn from_utf8_lossy(v: &[u8]) -> Cow<'_, str>
pub fn from_utf16(v: &[u16]) -> Result<String, FromUtf16Error>
pub fn from_utf16_lossy(v: &[u16]) -> String
pub fn from_utf16le(v: &[u8]) -> Result<String, FromUtf16Error>
pub fn from_utf16le_lossy(v: &[u8]) -> String
pub fn from_utf16be(v: &[u8]) -> Result<String, FromUtf16Error>
pub fn from_utf16be_lossy(v: &[u8]) -> String
let sparkle_heart = vec![240, 159, 146, 150];
let sparkle_heart = String::from_utf8(sparkle_heart).unwrap();
assert_eq!("💖", sparkle_heart);
// raw pointer 互操作
pub unsafe fn from_raw_parts(buf: *mut u8, length: usize, capacity: usize ) -> String
pub fn into_raw_parts(self) -> (*mut u8, usize, usize)
// 转换为 Vec<u8>, &[u8], &str
pub fn into_bytes(self) -> Vec<u8> // 消耗自身
pub unsafe fn as_mut_vec(&mut self) -> &mut Vec<u8>
pub fn into_boxed_str(self) -> Box<str>
pub fn as_bytes(&self) -> &[u8]
pub fn as_str(&self) -> &str
pub fn as_mut_str(&mut self) -> &mut str
// 添加或指定位置插入 char 或 &str,自动调整容量。
pub fn push(&mut self, ch: char)
pub fn push_str(&mut self, string: &str)
pub fn extend_from_within<R>(&mut self, src: R) where R: RangeBounds<usize>
pub fn insert(&mut self, idx: usize, ch: char)
pub fn insert_str(&mut self, idx: usize, string: &str)
// 返回容量和长度
pub fn capacity(&self) -> usize
pub fn len(&self) -> usize
pub fn is_empty(&self) -> bool
// 修改长度
pub fn reserve(&mut self, additional: usize)
pub fn reserve_exact(&mut self, additional: usize)
pub fn try_reserve(&mut self, additional: usize) -> Result<(), TryReserveError>
pub fn try_reserve_exact( &mut self, additional: usize) -> Result<(), TryReserveError>
pub fn shrink_to_fit(&mut self)
pub fn shrink_to(&mut self, min_capacity: usize)
pub fn truncate(&mut self, new_len: usize)
pub fn clear(&mut self)
// 删除 char
pub fn pop(&mut self) -> Option<char> // 为空时返回 None
pub fn remove(&mut self, idx: usize) -> char
pub fn remove_matches<P, 'a>(&'a mut self, pat: P) where P: for<'x> Pattern<'x>
// 保留 f 返回 true 的字符
pub fn retain<F>(&mut self, f: F) where F: FnMut(char) -> bool
let mut s = String::from("f_o_ob_ar");
s.retain(|c| c != '_');
assert_eq!(s, "foobar");
pub fn split_off(&mut self, at: usize) -> String
// 删除指定范围的字符,返回删除字符串的迭代器
pub fn drain<R>(&mut self, range: R) -> Drain<'_> where R: RangeBounds<usize>
let mut s = String::from("α is alpha, β is beta");
let beta_offset = s.find('β').unwrap_or(s.len());
let t: String = s.drain(..beta_offset).collect();
assert_eq!(t, "α is alpha, ");
assert_eq!(s, "β is beta");
s.drain(..);
assert_eq!(s, "");
pub fn replace_range<R>(&mut self, range: R, replace_with: &str) where R: RangeBounds<usize>
pub fn leak<'a>(self) -> &'a mut str
[u8] #
String 和 &str 的 as_bytes() 方法都返回 &[u8]。
b"xxx" 的类型是 &[u8; N],可以自动被 unsized coercion 到 &[u8]:
// impl [u8]
// 检查 [u8] 各元素是否是 ascii
pub const fn is_ascii(&self) -> bool
pub const fn as_ascii(&self) -> Option<&[AsciiChar]>
pub const unsafe fn as_ascii_unchecked(&self) -> &[AsciiChar]
pub fn eq_ignore_ascii_case(&self, other: &[u8]) -> bool
pub fn make_ascii_uppercase(&mut self)
pub fn make_ascii_lowercase(&mut self)
pub fn escape_ascii(&self) -> EscapeAscii<'_>
let s = b"0\t\r\n'\"\\\x9d";
let escaped = s.escape_ascii().to_string();
assert_eq!(escaped, "0\\t\\r\\n\\'\\\"\\\\\\x9d");
pub const fn trim_ascii_start(&self) -> &[u8]
pub const fn trim_ascii_end(&self) -> &[u8]
pub const fn trim_ascii(&self) -> &[u8]
#![feature(byte_slice_trim_ascii)]
assert_eq!(b" \t hello world\n".trim_ascii_start(), b"hello world\n");
assert_eq!(b" ".trim_ascii_start(), b"");
assert_eq!(b"".trim_ascii_start(), b"");
[u8] 的 as_ascii() 返回 [AsciiChar] 类型:
impl [AsciiChar]
pub const fn as_str(&self) -> &str
pub const fn as_bytes(&self) -> &[u8]
数组 #
array 是同类型元素的列表, 在栈上分配的固定长度的连续内存空间,用 [T; N] 表示,N 必须是编译时常量表达式。
// 声明一个有 5 个 i32 整数的数组
let numbers: [i32; 5] = [1, 2, 3, 4, 5];
// 声明一个有 5 个元素都是 0 的数组,表达式右侧 [Value; N] 的 Value 类型必须实现 Copy
let zeroes: [i32; 5] = [0; 5];
let mut values: [i32; 3] = [10, 20, 30];
// 数组支持 index 操作
values[1] = 25;
println!("values: {:?}", values);
println!("The array has {} elements.", values.len());
Rust 数组和集合的元素索引都从 0 开始, index 必须小于 len(), 否则 panic。
索引操作是通过 Index/IndexMut trait 来实现的,这两个 trait 的方法都返回的是对象的借用,但是 Rust 会将 a[i] 或 a[i..j] 操作自动解引用后返回对象,如 a[i] 等效于 *a.index(i)。这样做的好处是:实现 IndexMut trait 后,可以使用赋值表达式 a[i] = 3; 对返回的对象进行赋值。
a[start..end] 返回一个 dynamic size 的 slice 类型 [T],故一般使用 &a[start..end] :
- index 操作
a[i]的优先级高于 &; a[start..end]切片操作并不拷贝数组的堆内存, 也不拥有任何数据,而只是共享借用array/Vec的数据,所以很高效。
array [T;N] 可以被 unsized type coercion 到 slice [T],所以 &[T;N] 可以被自动隐式转换为 &[T]。
let arr = [1, 2, 3, 4, 5];
// a[1..3] 返回的类型为 [i32], &a[1..3] 返回的类型为 &[i32]
let slice = &a[1..3];
// &[i32; 2] 类型会被自动转换为 &[i32],所以两者可以直接比较
assert_eq!(slice, &[2, 3]);
// 创建一个包含整个数组的 slice
let slice_whole = &arr[..];
let a = [1, 2, 3, 4, 5];
// 一个接受切片作为参数的函数
fn sum(slice: &[i32]) -> i32 {
let mut total = 0;
for i in slice {
total += i;
}
total
}
fn main() {
let arr = [1, 2, 3, 4, 5];
let result = sum(&arr[1..4]);
println!("The sum of the part of the array is: {}", result);
}
array 支持 for-in 迭代,结果为数组元素 T。也可以调用数组的 iter()/iter_mut()/into_inter() 方法返回对应的迭代器。
fn main() {
let mut numbers: [i32; 5] = [1, 2, 3, 4, 5];
// numbers.iter()/numbers.iter_mut()/numbers.into_iter()
for number in numbers {
println!("number: {}", number);
}
}
对于 slice 的借用类型进行迭代时:
&[T]:迭代结果为&T;&mut [T]:迭代结果为&mut T;
array [T; N] 的 index 操作 &a[m..n] 结果为 &[T],故迭代结果为 &T:
数组元素的转移 #
Rust 不允许部分转移 Array/Vec/Slice/HashMap/HashSet 中的元素,但是全部转移是 OK 的(如通过迭代),所以如果元素类型不支持 Copy 则索引操作后的赋值转移会失败:
- 允许部分转移
struct/tuple/union中的成员或元素,被转移的成员不能再读取; - 如果对象类型没有实现
Copy trait,即使持有&mut借用也不能转移内部的对象;
解决办法:
- 使用
std::mem::replace():在持有对象&mut的情况下,用同类型对象替换(返回元素 T); - 使用
slice patternmatch 来提取; - 使用
std::mem::take()来返回值(原始值类型需要实现Default trait,将原始值设置为缺省值);
// 全部 move,OK!
fn move_away(_: String)
let [john, roa] = ["John".to_string(), "Roa".to_string()];
move_away(john);
move_away(roa);
// 部分 move,失败!
struct Buffer<T> {
buf: Vec<T>
}
impl<T> Buffer<T> {
fn replace_index(&mut self, i: usize, v: T) -> T {
// error: cannot move out of dereference of `&mut`-pointer
// self.buf[i] 返回对象,如果 T 没有实现 Copy 则为转移,而 Rust 不支持使用 &mut 来转移内部的对象。
let t = self.buf[i];
self.buf[i] = v;
t
}
}
// 解决办法:std::mem::replace 对 &mut 对象替换, 返回替换前的对象
impl<T> Buffer<T> {
fn replace_index(&mut self, i: usize, v: T) -> T {
std::mem::replace(&mut self.buf[i], v)
}
}
另一种常见解法:在 Array/Vec 中保存 Option<T> 类型值,如 Vec<Option<T>>, 如果要删除某个元素,调用 Option::take() 即可(不转移原始值,而是设置为 None)。
数组实现的 trait #
如果元素类型实现了如下 trait,则数组也实现了对应 trait:
- Copy,Clone
- Debug(数组没有实现 Display trait)
- IntoIterator:
[T; N], &[T; N] and &mut [T; N] - PartialEq, PartialOrd, Eq, Ord
- Hash
- AsRef, AsMut
- Borrow, BorrowMut
// 打印实现了 Debug trait 的数组
println!("numbers: {:?}", numbers);
println!("zeroes: {:?}", zeroes);
数组自动转换为 &[T] #
[T; N] 可以被隐式 unsize type coerce 到 [T], 也即 &[T; N] 可以被隐式自动转换为 &[T],所以数组可以调用 slice 的所有方法。
- 数组并没有实现
Deref trait,所以上面的自动转换不是Deref的行为(Vec<T>实现了Deref<Target=[T]>)。 - 反过来, slice
[T]是 dynamic size(unsize), 不能反向 coerce 到有限大小的数组。
// 左边是类型, 右边是初始化表达式!
let mut array: [i32; 3] = [0; 3];
// 数组 [i32; 3] 可以被 type coerce 到 [T], 所以 &[i32; 3] 可以被赋值给 &[i32]
let numbers: &[i32] = &[0, 1, 2];
print_type_of(&numbers);
// numbers 是 &[i32; 3] 类型,函数传参时被自动转换为 &[i32] 类型
let numbers = &[0, 1, 2];
print_type_of(&numbers);
// number 虽然前面没有加 &, 但它本身是 &[i32] 类型, 所以迭代后元素 n 是 &32 类型.
for n in numbers {
print_type_of(&n);
}
// 传入的 v 值是 &T 类型,返回 T 的类型
fn print_type_of<T>(v: &T) -> String {
format!("{}", std::any::type_name_of_val(v))
}
// 数组的 index 操作返回元素本身。但是数组和 Vec 不允许部分 move,所以如果对象没有实现 Copy,则 numbers[0] 会因转移对象而失败。
print_type_of(&numbers[0]); // i32
// 由于数组可以 unsized coerced 到 slice,所以下面的表达式是 OK 的
// A heap-allocated array, coerced to a slice
let boxed_array: Box<[i32]> = Box::new([1, 2, 3]);
使用 slice.try_into().unwrap() 或 <ArrayType>::try_from(slice).unwrap() 来在相同长度的 slice 和 array 之间转换:
let mut bytes: [u8; 3] = [1, 0, 2];
let bytes_head: [u8; 2] = <[u8; 2]>::try_from(&mut bytes[0..2]).unwrap();
assert_eq!(1, u16::from_le_bytes(bytes_head));
let bytes_tail: [u8; 2] = (&mut bytes[1..3]).try_into().unwrap();
assert_eq!(512, u16::from_le_bytes(bytes_tail));
array 方法:
- array 转为 slice:as_slice()/as_mut_slice(),或者通过 index 操作,如
&a[i..j]; - 获得各元素引用的数组:each_ref/each_mut();
//impl<T, const N: usize> [T; N]
pub fn map<F, U>(self, f: F) -> [U; N] where F: FnMut(T) -> U
pub fn try_map<F, R>( self, f: F, ) -> ::TryType where F: FnMut(T) -> R, R: Try, <R as Try>::Residual: Residual<[<R as Try>::Output; N]>
pub const fn as_slice(&self) -> &[T]
pub fn as_mut_slice(&mut self) -> &mut [T]
pub fn each_ref(&self) -> [&T; N]
pub fn each_mut(&mut self) -> [&mut T; N]
// 将数组拆分为指定长度 M 的数组
pub fn split_array_ref<const M: usize>(&self) -> (&[T; M], &[T])
pub fn split_array_mut<const M: usize>(&mut self) -> (&mut [T; M], &mut [T])
pub fn rsplit_array_ref<const M: usize>(&self) -> (&[T], &[T; M])
pub fn rsplit_array_mut<const M: usize>(&mut self) -> (&mut [T], &mut [T; M])
//impl<T, const N: usize> [MaybeUninit<T>; N]
pub const fn transpose(self) -> MaybeUninit<[T; N]>
// u8 数组
// impl<const N: usize> [u8; N]
pub const fn as_ascii(&self) -> Option<&[AsciiChar; N]>
pub const unsafe fn as_ascii_unchecked(&self) -> &[AsciiChar; N]
// array 转为 Vec
impl<T, const N: usize> From<&[T; N]> for Vec<T> where T: Clone
impl<T, const N: usize> From<&mut [T; N]> for Vec<T> where T: Clone
array 实现的 trait:
// array 实现的 trait
impl<T, const N: usize> AsMut<[T]> for [T; N]
impl<T, const N: usize> AsRef<[T]> for [T; N]
impl<T, const N: usize> Borrow<[T]> for [T; N]
impl<T, const N: usize> BorrowMut<[T]> for [T; N]
// array 转为容器类型
impl<K, V, const N: usize> From<[(K, V); N]> for BTreeMap<K, V> where K: Ord
impl<K, V, const N: usize> From<[(K, V); N]> for HashMap<K, V, RandomState> where K: Eq + Hash
impl<T, const N: usize> From<[T; N]> for BTreeSet<T> where T: Ord
impl<T, const N: usize> From<[T; N]> for BinaryHeap<T> where T: Ord
impl<T, const N: usize> From<[T; N]> for HashSet<T, RandomState> where T: Eq + Hash
impl<T, const N: usize> From<[T; N]> for LinkedList<T>
impl<T, const N: usize> From<[T; N]> for Vec<T>
impl<T, const N: usize> From<[T; N]> for VecDeque<T>
// array 转为智能指针
impl<T, const N: usize> From<[T; N]> for Arc<[T]>
impl<T, const N: usize> From<[T; N]> for Box<[T]>
impl<T, const N: usize> From<[T; N]> for Rc<[T]>
impl<'a, T, const N: usize> From<&'a [T; N]> for Cow<'a, [T]> where T: Clone
impl From<[u16; 8]> for IpAddr
impl From<[u16; 8]> for Ipv6Addr
impl From<[u8; 16]> for IpAddr
impl From<[u8; 16]> for Ipv6Addr
impl From<[u8; 4]> for IpAddr
impl From<[u8; 4]> for Ipv4Addr
impl<T> From<(T,)> for [T; 1]
impl<T> From<(T, T, T, T, T, T, T, T, T, T, T, T)> for [T; 12]
impl<T> From<[T; 1]> for (T,)
impl<T> From<[T; 9]> for (T, T, T, T, T, T, T, T, T)
切片 slice #
slice 代表一块连续的内存区域(和 array 类似),用 [T] 表示,是编译时大小未知的类型。
作为变量/函数输入/输出参数类型来使用时, 一般使用编译时固定大小的 &[T] 或 Box<[T]> 类型:
- 虽然编译时大小未知,但
.len()返回元素数量; &[T]、Box<[u8]>、Rc<[u8]>是大小固定为 2 usize 的fat pointer,包含指向内存区域的指针和元素数量(非 byte 数量);
let pointer_size = std::mem::size_of::<&u8>();
assert_eq!(2 * pointer_size, std::mem::size_of::<&[u8]>());
assert_eq!(2 * pointer_size, std::mem::size_of::<*const [u8]>());
// slice 的智能指针也是 2 usize
assert_eq!(2 * pointer_size, std::mem::size_of::<Box<[u8]>>());
assert_eq!(2 * pointer_size, std::mem::size_of::<Rc<[u8]>>());
Box<T>/Rc<T> 的大小,取决于 T 类型:
- 基本类型,如 i32,
Box<i32>占用 1 usize 大小,表示内存地址 - slice 类型,如
Box<[i32]>占用 2 usize 大小,分别是内存地址和元素数量; - dyn Trait 类型,如
Box<dyn std::error::Error>占用 3 usize 大小;
创建 slice &[T]:
- array/Vec 的 range index 操作返回
[T], 如v[0..2],v[..], 但因 slice 大小未知,一般需要借用,如&v[..]。
Vec<T> 实现了 Deref<Target=[T]>, 故 &Vec<T> 可以被隐式转换为 &[T],在需要 &[T] 类型的地方可以传入 &Vec<T> 类型。
[T; N] 可以被 unsized type coercing 到 [T](非 Deref 实现), 所以 &[T; N] 可以被隐式转换为 &[T]。
所以,array 和 Vec 对象都可以调用 slice 的方法。
let vec = vec![1, 2, 3];
let int_slice = &vec[..];
// 由于 Vec<T> 实现了 Deref<Target=[T]>,所以 &Vec<i32> 可以被赋值给 &[i32] 类型
let int_slice: &[i32] = &vec;
let mut x = [1, 2, 3];
let x = &mut x[..];
x[1] = 7; // x 实现了 IndexMut trait,所以可以赋值修改
assert_eq!(x, &[1, 7, 3]);
// 由于数组 [i32; 3] 可以被 unsized coerce 到 [T], 所以 &[i32; 3] 可以被赋值给 &[i32]
let numbers: &[i32] = &[0, 1, 2];
print_type_of(&numbers);
for n in numbers {
print_type_of(&n); // n 的类型是 &i32
}
// i32,切片引用的支持 index 操作,返回元素本身
print_type_of(&numbers[0]);
let str_slice: &[&str] = &["one", "two", "three"];
fn read_slice(slice: &[usize]) {}
let v = vec![0, 1];
read_slice(&v); // Deref 自动转换
let u: &[usize] = &v; // Deref 自动转换
let u: &[_] = &v; // 自动推断 slice 类型
s[i] 返回 s 的元素值,而非它的引用,所以支持将 s[i] 作为左值使用:
s[i]底层使用的 s 类型实现的Index/IndexMut trait,左值自动调用的是IndexMut trait实现。
let mut x = [1, 2, 3];
let x = &mut x[..];
x[1] = 7;
for-in 迭代 &[T] 时返回 &T 类型元素,迭代 &mut [T] 时返回 &mut T 类型元素:
// &[0, 1, 2] 的类型是 &[i32; 3] 被 unsized coerce 自动转换为 &[i32]
let numbers: &[i32] = &[0, 1, 2];
for n in numbers { // n 是 &i32 类型
println!("{n} is a number!");
}
let mut scores: &mut [i32] = &mut [7, 8, 9];
for score in scores { // score 是 &mut i32 类型.
*score += 1;
}
对 array/slice 进行 index 操作时,如果超过了 length,则会 panic。解决办法: 使用安全的 .get() 方法,它返回一个 Option。
get()方法的参数类型是SliceIndex<[T]>,Range<usize>/RangeFull/RangeFrom<usize>等均实现了该 trait。get()方法的返回类型是&T。
for i in 0..xs.len() + 1 {
match xs.get(i) {
Some(xval) => println!("{}: {}", i, xval),
None => println!("Slow down! {} is too far!", i),
}
}
let v = [10, 40, 30];
assert_eq!(Some(&40), v.get(1));
assert_eq!(Some(&[10, 40][..]), v.get(0..2));
assert_eq!(None, v.get(3));
assert_eq!(None, v.get(0..4));
数组 slice 的 flatten #
impl<T, const N: usize> [[T; N]]
pub const fn flatten(&self) -> &[T]
#![feature(slice_flatten)]
assert_eq!([[1, 2, 3], [4, 5, 6]].flatten(), &[1, 2, 3, 4, 5, 6]);
assert_eq!(
[[1, 2, 3], [4, 5, 6]].flatten(),
[[1, 2], [3, 4], [5, 6]].flatten(),
);
let slice_of_empty_arrays: &[[i32; 0]] = &[[], [], [], [], []];
assert!(slice_of_empty_arrays.flatten().is_empty());
let empty_slice_of_arrays: &[[u32; 10]] = &[];
assert!(empty_slice_of_arrays.flatten().is_empty());
slice 方法 #
- 由于 array 可以被 unsized coerce 到
[T], 而Vec<T>实现了Deref<Target=[T]>, 所以 array/Vec 可以调用 slice 的所有方法。 - 不能直接迭代 slice, 而是调用它的
iter() 或 iter_mut()方法返回的迭代器;(但是 Array 可以直接迭代) - concat()/join(&sep) 方法用于数组的数组,将数组的元素打平或加入新的分隔符;
assert_eq!([[1,2], [3,4]].concat(), vec![1,2,3,4]);assert_eq!([[1,2], [3,4]].join(&0), vec![1,2,0,3,4]);
- chunks() 返回指定长度的
&[T]的迭代器;
impl<T> [T]
// 返回元素数量(而非 byte 数量)
pub const fn len(&self) -> usize
pub const fn is_empty(&self) -> bool
// slice 有可能为空,所以 first/last 都返回 Option
pub const fn first(&self) -> Option<&T>
pub fn first_mut(&mut self) -> Option<&mut T>
pub const fn last(&self) -> Option<&T>
pub fn last_mut(&mut self) -> Option<&mut T>
// 拆分 slice,其实是返回两个视图,所以参数可以是 &self 类型
pub const fn split_first(&self) -> Option<(&T, &[T])>
pub fn split_first_mut(&mut self) -> Option<(&mut T, &mut [T])>
pub const fn split_last(&self) -> Option<(&T, &[T])>
pub fn split_last_mut(&mut self) -> Option<(&mut T, &mut [T])>
// x 是 &[i32; 3] 类型,但是可以被 unsized coerce 到 &[i32] 类型,所以可以调用 slice [T] 的方法。
let x = &[0, 1, 2];
if let Some((first, elements)) = x.split_first() {
assert_eq!(first, &0);
assert_eq!(elements, &[1, 2]);
}
// 返回第一个 N 个元素的数组,如果元素少于 N 则返回 None
//
// 由于数组长度必须是编译时常量,所以 N 是通过常量泛型参数传入或则由编译器推导(如根据结果赋值的类型)。
pub const fn first_chunk<const N: usize>(&self) -> Option<&[T; N]>
pub fn first_chunk_mut<const N: usize>(&mut self) -> Option<&mut [T; N]>
pub fn last_chunk<const N: usize>(&self) -> Option<&[T; N]>
pub fn last_chunk_mut<const N: usize>(&mut self) -> Option<&mut [T; N]>
let u = [10, 40, 30];
assert_eq!(Some(&[10, 40]), u.first_chunk::<2>()); // 指定泛型常量的值为 2
let v: &[i32] = &[10];
assert_eq!(None, v.first_chunk::<2>());
let w: &[i32] = &[];
assert_eq!(Some(&[]), w.first_chunk::<0>());
// 返回第一个或最后一个 chunk 数组和剩下的 slice,如果元素少于 N 则返回 None
pub const fn split_first_chunk<const N: usize>(&self) -> Option<(&[T; N], &[T])>
pub fn split_first_chunk_mut<const N: usize>( &mut self ) -> Option<(&mut [T; N], &mut [T])>
pub const fn split_last_chunk<const N: usize>(&self) -> Option<(&[T], &[T; N])>
pub fn split_last_chunk_mut<const N: usize>( &mut self ) -> Option<(&mut [T], &mut [T; N])>
let x = &[0, 1, 2];
if let Some((first, elements)) = x.split_first_chunk::<2>() {
assert_eq!(first, &[0, 1]);
assert_eq!(elements, &[2]);
}
assert_eq!(None, x.split_first_chunk::<4>());
// 安全的返回 slice 中元素的借用(s[index] 当 index 不在范围时会 panic )
pub fn get<I>(&self, index: I) -> Option<&<I as SliceIndex<[T]>>::Output> where I: SliceIndex<[T]>
pub fn get_mut<I>( &mut self, index: I ) -> Option<&mut <I as SliceIndex<[T]>>::Output> where I: SliceIndex<[T]>
pub unsafe fn get_unchecked<I>( &self, index: I ) -> &<I as SliceIndex<[T]>>::Output where I: SliceIndex<[T]>
pub unsafe fn get_unchecked_mut<I>( &mut self, index: I ) -> &mut <I as SliceIndex<[T]>>::Output where I: SliceIndex<[T]>
let v = [10, 40, 30];
assert_eq!(Some(&40), v.get(1));
assert_eq!(Some(&[10, 40][..]), v.get(0..2));
assert_eq!(None, v.get(3));
assert_eq!(None, v.get(0..4));
// 创建裸指针
pub const fn as_ptr(&self) -> *const T
pub const fn as_mut_ptr(&mut self) -> *mut T
let x = &[1, 2, 4];
let x_ptr = x.as_ptr();
unsafe {
for i in 0..x.len() {
assert_eq!(x.get_unchecked(i), &*x_ptr.add(i));
}
}
let x = &mut [1, 2, 4];
let x_ptr = x.as_mut_ptr();
unsafe {
for i in 0..x.len() {
*x_ptr.add(i) += 2;
}
}
assert_eq!(x, &[3, 4, 6]);
// 返回包含所有元素的原始指针的区间(因为 slice 内存空间连续)
pub const fn as_ptr_range(&self) -> Range<*const T>
pub const fn as_mut_ptr_range(&mut self) -> Range<*mut T>
let a = [1, 2, 3];
let x = &a[1] as *const _;
let y = &5 as *const _;
assert!(a.as_ptr_range().contains(&x));
assert!(!a.as_ptr_range().contains(&y));
// 交换两个位置的值
pub fn swap(&mut self, a: usize, b: usize)
pub unsafe fn swap_unchecked(&mut self, a: usize, b: usize)
let mut v = ["a", "b", "c", "d", "e"];
v.swap(2, 4);
assert!(v == ["a", "b", "e", "d", "c"]);
// 反转 slice 元素
pub fn reverse(&mut self)
// 返回可迭代对象
pub fn iter(&self) -> Iter<'_, T>
pub fn iter_mut(&mut self) -> IterMut<'_, T>
// 可重叠,如果元素数量比窗口小,则返回 None
pub fn windows(&self, size: usize) -> Windows<'_, T>
let slice = ['l', 'o', 'r', 'e', 'm'];
let mut iter = slice.windows(3);
assert_eq!(iter.next().unwrap(), &['l', 'o', 'r']);
assert_eq!(iter.next().unwrap(), &['o', 'r', 'e']);
assert_eq!(iter.next().unwrap(), &['r', 'e', 'm']);
assert!(iter.next().is_none());
let slice = ['f', 'o', 'o'];
let mut iter = slice.windows(4);
assert!(iter.next().is_none());
// 不重叠的分组迭代,每次迭代返回一个切片 &[T]
pub fn chunks(&self, chunk_size: usize) -> Chunks<'_, T>
pub fn chunks_mut(&mut self, chunk_size: usize) -> ChunksMut<'_, T>
pub fn chunks_exact(&self, chunk_size: usize) -> ChunksExact<'_, T>
pub fn chunks_exact_mut(&mut self, chunk_size: usize) -> ChunksExactMut<'_, T>
pub const unsafe fn as_chunks_unchecked<const N: usize>(&self) -> &[[T; N]]
pub fn rchunks(&self, chunk_size: usize) -> RChunks<'_, T>
pub fn rchunks_mut(&mut self, chunk_size: usize) -> RChunksMut<'_, T>
pub fn rchunks_exact(&self, chunk_size: usize) -> RChunksExact<'_, T>
pub fn rchunks_exact_mut(&mut self, chunk_size: usize) -> RChunksExactMut<'_, T>
let slice = ['l', 'o', 'r', 'e', 'm'];
let mut iter = slice.chunks(2);
assert_eq!(iter.next().unwrap(), &['l', 'o']);
assert_eq!(iter.next().unwrap(), &['r', 'e']);
assert_eq!(iter.next().unwrap(), &['m']);
assert!(iter.next().is_none());
let slice = ['l', 'o', 'r', 'e', 'm'];
let mut iter = slice.chunks_exact(2);
assert_eq!(iter.next().unwrap(), &['l', 'o']);
assert_eq!(iter.next().unwrap(), &['r', 'e']);
// 如果最后一波元素少与数量,则返回 None,可以使用 remainer() 方法来获取它们
assert!(iter.next().is_none());
assert_eq!(iter.remainder(), &['m']);
// 分为 N 个元素数组的 slice 和最后剩下的元素 slice,N 是泛型参数,编译器可以自动推导。
pub const fn as_chunks<const N: usize>(&self) -> (&[[T; N]], &[T])
pub const fn as_rchunks<const N: usize>(&self) -> (&[T], &[[T; N]])
pub const unsafe fn as_chunks_unchecked_mut<const N: usize>( &mut self ) -> &mut [[T; N]]
pub const fn as_chunks_mut<const N: usize>( &mut self ) -> (&mut [[T; N]], &mut [T])
pub const fn as_rchunks_mut<const N: usize>( &mut self) -> (&mut [T], &mut [[T; N]])
#![feature(slice_as_chunks)]
let slice = ['l', 'o', 'r', 'e', 'm'];
let (chunks, remainder) = slice.as_chunks();
assert_eq!(chunks, &[['l', 'o'], ['r', 'e']]);
assert_eq!(remainder, &['m']);
let slice = ['R', 'u', 's', 't'];
let (chunks, []) = slice.as_chunks::<2>() else { // 使用 let-else 来匹配剩下元素的列表
panic!("slice didn't have even length")
};
assert_eq!(chunks, &[['R', 'u'], ['s', 't']]);
// chunks_exact 的泛型常量版本,即数组的长度是通过泛型常量参数来指定的,编译器可以自动推导。
pub fn array_chunks<const N: usize>(&self) -> ArrayChunks<'_, T, N>
pub fn array_chunks_mut<const N: usize>(&mut self) -> ArrayChunksMut<'_, T, N>
pub fn array_windows<const N: usize>(&self) -> ArrayWindows<'_, T, N>
#![feature(array_chunks)]
let slice = ['l', 'o', 'r', 'e', 'm'];
let mut iter = slice.array_chunks();
assert_eq!(iter.next().unwrap(), &['l', 'o']);
assert_eq!(iter.next().unwrap(), &['r', 'e']);
assert!(iter.next().is_none());
assert_eq!(iter.remainder(), &['m']);
//使用 pred 来分割 slice(不重合的分割),pred 返回 true 时对应连续的元素属于一个 slice
pub fn chunk_by<F>(&self, pred: F) -> ChunkBy<'_, T, F> where F: FnMut(&T, &T) -> bool
pub fn chunk_by_mut<F>(&mut self, pred: F) -> ChunkByMut<'_, T, F> where F: FnMut(&T, &T) -> pub
let slice = &[1, 1, 1, 3, 3, 2, 2, 2];
let mut iter = slice.chunk_by(|a, b| a == b);
assert_eq!(iter.next(), Some(&[1, 1, 1][..]));
assert_eq!(iter.next(), Some(&[3, 3][..]));
assert_eq!(iter.next(), Some(&[2, 2, 2][..]));
assert_eq!(iter.next(), None);
// 在指定的 index 位置拆分 slice
bool const fn split_at(&self, mid: usize) -> (&[T], &[T])
pub fn split_at_mut(&mut self, mid: usize) -> (&mut [T], &mut [T])
pub const unsafe fn split_at_unchecked(&self, mid: usize) -> (&[T], &[T])
pub unsafe fn split_at_mut_unchecked( &mut self, mid: usize ) -> (&mut [T], &mut [T])
pub fn split_at_checked(&self, mid: usize) -> Option<(&[T], &[T])>
pub fn split_at_mut_checked( &mut self, mid: usize ) -> Option<(&mut [T], &mut [T])>
let v = [1, 2, 3, 4, 5, 6];
{
let (left, right) = v.split_at(0);
assert_eq!(left, []);
assert_eq!(right, [1, 2, 3, 4, 5, 6]);
}
{
let (left, right) = v.split_at(2);
assert_eq!(left, [1, 2]);
assert_eq!(right, [3, 4, 5, 6]);
}
{
let (left, right) = v.split_at(6);
assert_eq!(left, [1, 2, 3, 4, 5, 6]);
assert_eq!(right, []);
}
// 使用指定的 pred 分割 slice,可能会导致空 slice
pub fn split<F>(&self, pred: F) -> Split<'_, T, F> where F: FnMut(&T) -> bool
pub fn split_mut<F>(&mut self, pred: F) -> SplitMut<'_, T, F> where F: FnMut(&T) -> bool
pub fn split_inclusive<F>(&self, pred: F) -> SplitInclusive<'_, T, F> where F: FnMut(&T) -> bool
pub fn split_inclusive_mut<F>(&mut self, pred: F) -> SplitInclusiveMut<'_, T, F> where F: FnMut(&T) -> bool
pub fn rsplit<F>(&self, pred: F) -> RSplit<'_, T, F> where F: FnMut(&T) -> bool
pub fn rsplit_mut<F>(&mut self, pred: F) -> RSplitMut<'_, T, F> where F: FnMut(&T) -> bool
pub fn splitn<F>(&self, n: usize, pred: F) -> SplitN<'_, T, F> where F: FnMut(&T) -> bool
pub fn splitn_mut<F>(&mut self, n: usize, pred: F) -> SplitNMut<'_, T, F> where F: FnMut(&T) -> bool
pub fn rsplitn<F>(&self, n: usize, pred: F) -> RSplitN<'_, T, F> where F: FnMut(&T) -> bool
pub fn rsplitn_mut<F>(&mut self, n: usize, pred: F) -> RSplitNMut<'_, T, F> where F: FnMut(&T) -> bool
pub fn split_once<F>(&self, pred: F) -> Option<(&[T], &[T])> where F: FnMut(&T) -> bool
pub fn rsplit_once<F>(&self, pred: F) -> Option<(&[T], &[T])> where F: FnMut(&T) -> bool
let slice = [10, 6, 33, 20];
let mut iter = slice.split(|num| num % 3 == 0);
assert_eq!(iter.next().unwrap(), &[10]);
assert_eq!(iter.next().unwrap(), &[]);
assert_eq!(iter.next().unwrap(), &[20]);
assert!(iter.next().is_none());
let slice = [10, 40, 33];
let mut iter = slice.split(|num| num % 3 == 0);
assert_eq!(iter.next().unwrap(), &[10, 40]);
assert_eq!(iter.next().unwrap(), &[]); // 结尾空 slice
assert!(iter.next().is_none());
let slice = [10, 40, 33, 20];
let mut iter = slice.split_inclusive(|num| num % 3 == 0);
assert_eq!(iter.next().unwrap(), &[10, 40, 33]);
assert_eq!(iter.next().unwrap(), &[20]);
assert!(iter.next().is_none());
let v = [10, 40, 30, 20, 60, 50];
for group in v.splitn(2, |num| *num % 3 == 0) {
println!("{group:?}");
}
#![feature(slice_split_once)]
let s = [1, 2, 3, 2, 4];
assert_eq!(s.split_once(|&x| x == 2), Some((
&[1][..],
&[3, 2, 4][..]
)));
assert_eq!(s.split_once(|&x| x == 0), None);
// 是否包含引用值
pub fn contains(&self, x: &T) -> bool where T: PartialEq
let v = [10, 40, 30];
assert!(v.contains(&30));
assert!(!v.contains(&50));
// 是否以指定 slice 开始或结尾
pub fn starts_with(&self, needle: &[T]) -> bool where T: PartialEq
pub fn ends_with(&self, needle: &[T]) -> bool where T: PartialEq
let v = [10, 40, 30];
assert!(v.starts_with(&[10]));
assert!(v.starts_with(&[10, 40]));
assert!(!v.starts_with(&[50]));
assert!(!v.starts_with(&[10, 50]));
// 删除开始或结尾的 slice
pub fn strip_prefix<P>(&self, prefix: &P) -> Option<&[T]> where P: SlicePattern<Item = T> + ?Sized, T: PartialEq
pub fn strip_suffix<P>(&self, suffix: &P) -> Option<&[T]> where P: SlicePattern<Item = T> + ?Sized, T: PartialEq
let v = &[10, 40, 30];
assert_eq!(v.strip_prefix(&[10]), Some(&[40, 30][..]));
assert_eq!(v.strip_prefix(&[10, 40]), Some(&[30][..]));
assert_eq!(v.strip_prefix(&[50]), None);
assert_eq!(v.strip_prefix(&[10, 50]), None);
let prefix : &str = "he";
assert_eq!(b"hello".strip_prefix(prefix.as_bytes()), Some(b"llo".as_ref()));
pub fn binary_search(&self, x: &T) -> Result<usize, usize> where T: Ord
pub fn binary_search_by<'a, F>(&'a self, f: F) -> Result<usize, usize> where F: FnMut(&'a T) -> Ordering
pub fn binary_search_by_key<'a, B, F>(&'a self, b: &B,f:F) -> Result<usize, usize> where F: FnMut(&'a T) -> B,B: Ord
// 对 slice 进行排序,unstable 表示不保证重复元素的顺序
pub fn sort_unstable(&mut self) where T: Ord
pub fn sort_unstable_by<F>(&mut self, compare: F) where F: FnMut(&T, &T) -> Ordering
pub fn sort_unstable_by_key<K, F>(&mut self, f: F) where F: FnMut(&T) -> K, K: Ord
pub fn select_nth_unstable( &mut self, index: usize) -> (&mut [T], &mut T, &mut [T]) where T: Ord
pub fn select_nth_unstable_by<F>( &mut self, index: usize, compare: F) -> (&mut [T], &mut T, &mut [T]) where F: FnMut(&T, &T) -> Ordering
pub fn select_nth_unstable_by_key<K, F>( &mut self, index: usize, f: F ) -> (&mut [T], &mut T, &mut [T]) where F: FnMut(&T) -> K, K: Ord
let mut v = [-5, 4, 1, -3, 2];
v.sort_unstable();
assert!(v == [-5, -3, 1, 2, 4]);
// 返回两个 slice,分别是没有重复的元素,重复的元素(没有顺序)
pub fn partition_dedup(&mut self) -> (&mut [T], &mut [T]) where T: PartialEq
pub fn partition_dedup_by<F>(&mut self, same_bucket: F) -> (&mut [T], &mut [T]) where F: FnMut(&mut T, &mut T) -> bool
pub fn partition_dedup_by_key<K, F>(&mut self, key: F) -> (&mut [T], &mut [T]) where F: FnMut(&mut T) -> K, K: PartialEq
#![feature(slice_partition_dedup)]
let mut slice = [1, 2, 2, 3, 3, 2, 1, 1];
let (dedup, duplicates) = slice.partition_dedup();
assert_eq!(dedup, [1, 2, 3, 2, 1]);
assert_eq!(duplicates, [2, 3, 1]);
// 向左或右轮转元素
pub fn rotate_left(&mut self, mid: usize)
pub fn rotate_right(&mut self, k: usize)
let mut a = ['a', 'b', 'c', 'd', 'e', 'f'];
a.rotate_left(2);
assert_eq!(a, ['c', 'd', 'e', 'f', 'a', 'b']);
// 使用指定值填充整个 slice
pub fn fill(&mut self, value: T) where T: Clone
// 使用指定函数返回值填充整个 slice
pub fn fill_with<F>(&mut self, f: F) where F: FnMut() -> T
let mut buf = vec![0; 10];
buf.fill(1);
assert_eq!(buf, vec![1; 10]);
// 从 src clone 元素到 self,src 和 self 的长度必须一致,否则 panic
pub fn clone_from_slice(&mut self, src: &[T]) where T: Clone
pub fn copy_from_slice(&mut self, src: &[T]) where T: Copy
let src = [1, 2, 3, 4];
let mut dst = [0, 0];
dst.clone_from_slice(&src[2..]); // 长度必须一致
assert_eq!(src, [1, 2, 3, 4]);
assert_eq!(dst, [3, 4]);
// 将 src 指定的 Range 范围内元素拷贝到 dest 开始的位置,两者可以有重复
pub fn copy_within<R>(&mut self, src: R, dest: usize) where R: RangeBounds<usize>, T: Copy
let mut bytes = *b"Hello, World!";
bytes.copy_within(1..5, 8);
assert_eq!(&bytes, b"Hello, Wello!");
// 交换内容,两个 slice 的长度必须一致
pub fn swap_with_slice(&mut self, other: &mut [T])
let mut slice1 = [0, 0];
let mut slice2 = [1, 2, 3, 4];
slice1.swap_with_slice(&mut slice2[2..]);
assert_eq!(slice1, [3, 4]);
assert_eq!(slice2, [1, 2, 0, 0]);
pub unsafe fn align_to<U>(&self) -> (&[T], &[U], &[T])
pub unsafe fn align_to_mut<U>(&mut self) -> (&mut [T], &mut [U], &mut [T])
pub fn is_sorted(&self) -> bool where T: PartialOrd
pub fn is_sorted_by<'a, F>(&'a self, compare: F) -> bool where F: FnMut(&'a T, &'a T) -> bool
pub fn is_sorted_by_key<'a, F, K>(&'a self, f: F) -> bool where F: FnMut(&'a T) -> K, K: PartialOrd
// 返回 pred 返回 true 的 index
pub fn partition_point<P>(&self, pred: P) -> usize where P: FnMut(&T) -> bool
let v = [1, 2, 3, 3, 5, 6, 7];
let i = v.partition_point(|&x| x < 5);
assert_eq!(i, 4);
assert!(v[..i].iter().all(|&x| x < 5));
assert!(v[i..].iter().all(|&x| !(x < 5)));
let a = [2, 4, 8];
assert_eq!(a.partition_point(|x| x < &100), a.len());
let a: [i32; 0] = [];
assert_eq!(a.partition_point(|x| x < &100), 0);
// 从 self 拿出 range 元素并返回,self 是剩下的元素
pub fn take<R, 'a>(self: &mut &'a [T], range: R) -> Option<&'a [T]> where R: OneSidedRange<usize>
pub fn take_mut<R, 'a>(self: &mut &'a mut [T], range: R) -> Option<&'a mut [T]> where R: OneSidedRange<usize>
pub fn take_first<'a>(self: &mut &'a [T]) -> Option<&'a T>
pub fn take_first_mut<'a>(self: &mut &'a mut [T]) -> Option<&'a mut T>
pub fn take_last<'a>(self: &mut &'a [T]) -> Option<&'a T>
pub fn take_last_mut<'a>(self: &mut &'a mut [T]) -> Option<&'a mut T>
#![feature(slice_take)]
let mut slice: &[_] = &['a', 'b', 'c', 'd'];
let mut first_three = slice.take(..3).unwrap();
assert_eq!(slice, &['d']);
assert_eq!(first_three, &['a', 'b', 'c']);
#![feature(slice_take)]
let mut slice: &[_] = &['a', 'b', 'c', 'd'];
let mut tail = slice.take(2..).unwrap();
assert_eq!(slice, &['a', 'b']);
assert_eq!(tail, &['c', 'd']);
#![feature(slice_take)]
let mut slice: &[_] = &['a', 'b', 'c'];
let first = slice.take_first().unwrap();
assert_eq!(slice, &['b', 'c']);
assert_eq!(first, &'a');
// 返回多个元素的引用,各元素的 index 由传入的 indices 指定。
pub unsafe fn get_many_unchecked_mut<const N: usize>( &mut self, indices: [usize; N] ) -> [&mut T; N]
pub fn get_many_mut<const N: usize>( &mut self, indices: [usize; N] ) -> Result<[&mut T; N], GetManyMutError<N>>
#![feature(get_many_mut)]
let v = &mut [1, 2, 3];
if let Ok([a, b]) = v.get_many_mut([0, 2]) {
*a = 413;
*b = 612;
}
assert_eq!(v, &[413, 2, 612]);
// 其它 [T] 方法
impl<T> [T]
pub fn sort(&mut self) where T: Ord
pub fn sort_by<F>(&mut self, compare: F) where F: FnMut(&T, &T) -> Ordering
pub fn sort_by_key<K, F>(&mut self, f: F) where F: FnMut(&T) -> K, K: Ord
pub fn sort_by_cached_key<K, F>(&mut self, f: F) where F: FnMut(&T) -> K, K: Ord
let mut v = [-5, 4, 1, -3, 2];
v.sort();
assert!(v == [-5, -3, 1, 2, 4]);
let mut v = [-5i32, 4, 1, -3, 2];
v.sort_by_key(|k| k.abs());
assert!(v == [1, 2, -3, 4, -5]);
// 从 slice clone 生成 Vec,两个对象后续是无关的。
pub fn to_vec(&self) -> Vec<T> where T: Clone
pub fn to_vec_in<A>(&self, alloc: A) -> Vec<T, A> where A: Allocator, T: Clone
let s = [10, 40, 30];
let x = s.to_vec();
// 消耗 self
pub fn into_vec<A>(self: Box<[T], A>) -> Vec<T, A> where A: Allocator
let s: Box<[i32]> = Box::new([10, 40, 30]);
let x = s.into_vec();
assert_eq!(x, vec![10, 40, 30]); // s 不能再使用
pub fn repeat(&self, n: usize) -> Vec<T> where T: Copy
assert_eq!([1, 2].repeat(3), vec![1, 2, 1, 2, 1, 2]);
// 将 slice 打平为一个值
pub fn concat<Item>(&self) -> <[T] as Concat<Item>>::Output where [T]: Concat<Item>, Item: ?Sized
assert_eq!(["hello", "world"].concat(), "helloworld");
assert_eq!([[1, 2], [3, 4]].concat(), [1, 2, 3, 4]);
// 使用指定分隔符打平 slice
pub fn join<Separator>( &self, sep: Separator) -> <[T] as Join<Separator>>::Output where [T]: Join<Separator>
assert_eq!(["hello", "world"].join(" "), "hello world");
assert_eq!([[1, 2], [3, 4]].join(&0), [1, 2, 0, 3, 4]);
assert_eq!([[1, 2], [3, 4]].join(&[0, 0][..]), [1, 2, 0, 0, 3, 4]);
tuple #
tuple 用 (T1, T2, T3) 表示,长度和大小固定,可以保存不同类型值, 非常适合于存储和传递一组异构数据,如函数返回值。
let _t0: (u8,i16) = (0, -1);
let _t1: (u8, (i16, u32)) = (0, (-1, 1));
let t: (u8, u16, i64, &str, String) = (1u8, 2u16, 3i64, "hello", String::from(", world"));
println!("Success!");
// 函数接受一个元组作为参数,并返回一个元组
fn swap(tup: (i32, f64)) -> (f64, i32) {
(tup.1, tup.0)
}
let input_tup = (123, 4.56);
let output_tup = swap(input_tup);
// 创建一个嵌套的元组结构
let nested_tup = (1, (2, 3), 4);
// 解构元组
let (a, (b, c), d) = nested_tup;
// 创建一个零元素的元组,也称为单元类型(unit type),只有一个唯一的类型和值: ();
let unit = ();
单个元素时,元素后需要加逗号,如 (T,),以免和函数参数混淆。多个元素时,最后一个元素后的逗号可选。
tuple 拥有各元素对象, 和 struct 一样, 允许部分元素被部分转移, 但是后续不能再访问被转移的元素(Array/Vec/Slice 等集合不允许元素被部分转移)。
析构 tuple/enum #
tuple 和 enum 都是在值外部而非内部匹配 &/&mut:
let (a, b ) = &(1, 2); // a 和 b 都是 &i32 类型
let &(c, d ) = &(1, 2); // c 和 d 都是 i32 类型
let (&c, d ) = &(1, 2); // 错误
// 在 c 已经是借用类型的情况下,加不加 ref 没有区别
let (ref c, d) = &(1, 2); // OK,这里 c 前面的 ref 加不加没有区别,c 和 d 都是 &i32 类型。
println!("{}", type_name_of_val(&c));
// 但是:这里有区别
let (ref c, d) = (1, 2); // c 是 &i32 类型,d 是 i32 类型
let (c, d) = (1, 2); // c 和 d 都是 i32 类型
let _ia = &23i32; // Rust 支持直接字面量借用
// 枚举类型的匹配举例:
let x: &Option<i32> = &Some(3);
// OK: y 的类型是 &i32
if let Some(y) = x {}
// OK: 在 variant 外指定 &,y 的类型是 i32
if let &Some(y) = x {}
// ERROR: expected `i32`, found `&_`
if let Some(&y) = x {}
// 另一个枚举匹配的例子
enum MyEnum {
A { name: String, x: u8 },
B { name: String },
}
fn a_to_b(e: &mut MyEnum) {
// name 和 x 都是析构后的变量名,可以在后面的 block 中使用。
// name 是 &mut String 类型。
if let MyEnum::A { name, x: 0, } = e {
*e = MyEnum::B {
// take 参数类型是 &mut T, 而 name 类型是 &mut String 故满足
name: std::mem::take(name),
}
}
// OK: name 是 String 类型
// if let &mut MyEnum::A {
// name,
// x: 0,
// } = e
}
过长的 tuple 不能被格式化输出:
fn main() {
// 最多 12 个元素才能被格式化
let too_long_tuple = (1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12);
println!("too long tuple: {:?}", too_long_tuple);
}
array 可以转换为相同长度的 tuple:
let array: [u32; 3] = [1, 2, 3];
let tuple: (u32, u32, u32) = array.into();
Vec 不能直接被析构,但是可以先通过 range slice 操作返回 sice,然后再进行析构。
指针 #
Rust 提供如下几种指针类型:
- 引用(reference):
&T 和 &mut T; - 裸指针(raw pointer):
*const T(不可变),*mut T(可变),如*const [u8]; - 智能指针(smart pointer):
Box<T>/Rc<T>/Arc<T>/RefCell<T>等;
裸指针与 C 指针相似,它们跳过了 Rust 安全检查机制,需要在 unsafe 中使用(创建时不需要)。
Rust 支持引用到裸指针的 type coercion ,故可以使用 as 运算符来进行显式转换。
fn main() {
let mut x = 10;
// 将引用转换为可变裸指针
let ptr_x = &mut x as *mut i32;
unsafe {
ptr_x += 10;
println!("x: {}", *ptr_x);
}
}
智能指针(smart pointer)实现了 Deref & DerefMut trait ,和指针一样,支持解引用操作符 *,返回内部对象本身:
fn main() {
let b = 5i32; // 在栈上分配一个 i32 值
let b = Box::new(5); // 在堆上分配一个 i32 值
println!("b: {}", b);
let rc = Rc::new(5); // 创建一个引用计数指针
let rc_clone = rc.clone(); // 增加引用计数
println!("rc: {}, rc_clone: {}", rc, rc_clone);
}
指针内存布局 #
https://doc.rust-lang.org/stable/reference/type-layout.html
Rust 的指针有 thin 指针和 fat 指针之分,前者只占用一个 usize 内容,而后者可能是 2-3 个 usize 内存空间。
- 引用和裸指针:
&T, &mut T, *const T和*mut T内存布局是一致的,占用一个 usize 大小,可以使用 as 表达式进行相互转换;
&[T]/&mut [T]/*const [T]/*mut [T]和&str:占用 2 个机器字,分别保存内存指针和元素数量;Box<T>: 取决于 T 类型:- T 是基本类型,如 i32 时,占用 1 个机器字 isize,保存内存指针;
- T 是
[T]类型时,如Box<[i32]>, 占用 2 个机器字 isize, 保存内存指针和元素数量; Box<dyn Trait>或&dyn Trait: 占用 2 个机器字 isize,保存实际对象的内存指针以及该对象实现的各种方法的vtable指针;
// as 表达式支持的转换类型:https://doc.rust-lang.org/reference/expressions/operator-expr.html#r-expr.as.pointer
// 将裸指针转换为 usize
let ptr_num_cast = ptr as *const i32 as usize;
// 将裸指针转换为借用
// 这是因为 &T, &mut T, *const T 和 *mut T 内存布局是一致的,所以可以转换。
let ptr: *mut i32 = &mut 0;
let ref_casted = unsafe { &mut *ptr };
// 将 &mut T 转换为 &mut U:
let ptr = &mut 0;
let val_casts = unsafe { &mut *(ptr as *mut i32 as *mut u32) };
let pointer_size = std::mem::size_of::<&u8>();
assert_eq!(2 * pointer_size, std::mem::size_of::<&[u8]>());
assert_eq!(2 * pointer_size, std::mem::size_of::<*const [u8]>());
assert_eq!(2 * pointer_size, std::mem::size_of::<Box<[u8]>>());
assert_eq!(2 * pointer_size, std::mem::size_of::<Rc<[u8]>>());
type coercion 类型转换 #
https://doc.rust-lang.org/stable/reference/type-coercions.html
为引用和 raw pointer 提供了隐式自动转换, 也可以使用 as 运算符来执行显式的 type coercion 转换:
&mut T转换为&T<- 可变引用可以转换为不可变引用*mut T转换为*const T<– 可变 raw pointer 可以转换为不可变 raw pointer&T转换为*const T<– 不可变引用 可以转换为 不可变 raw pointer&mut T转换为*mut T<– 可变引用 可以转换为 可变 raw pointer
创建裸指针时不需要 unsafe,但是后续使用裸指针需要 unsafe。
// [T; n] 可以 unsize type coerce 到 [T]
let arry = [1, 2, 3];
let usz: &[i32] = &arry;
// &mut T -> &T
let r: &i32 = &mut 1i32;
// 创建裸指针时不需要 unsafe,但是后续使用裸指针需要 unsafe
// &T -> *const T
let rp: *const i32 = &1i32;
// &mut T -> *const T 或 *mut T
let r: *const i32 = &mut 1i32;
let r: *mut i32 = &mut 1i32;
// *mut T -> *const T
let rp: *const i32 = &mut 1i32 as *mut i32 as *const i32;
*mut T 和 *const T 之间也可以相互转换;
// 对于裸指针, 支持 *const T 和 *mut T 之间相互转换
let mut a = 123i32;
let arp = &a as *const i32;
let arp = arp as *mut i32;
let arp = arp as *const i32;
以下是 CoerceUnsized trait 实现的 type coercion 转换, 将 T 指针转换为 U 指针, U 需要是 unsized type:
// &T -> &U
let u: &dyn std::fmt::Display = &123i32;
// &mut T -> &U
let u: &dyn std::fmt::Display = &mut 123i32;
// &mut T -> &mut U
let u: &mut dyn std::fmt::Display = &mut 123i32;
// &T -> *const U
let u: *const dyn std::fmt::Display = &123i32;
// &mut T -> *const U
let u: *const dyn std::fmt::Display = &mut 123i32;
// &mut T -> *mut U
let u: *mut dyn std::fmt::Display = &mut 123i32;
// Box<T> -> Box<U>
let b1 = Box::new(123i32); // i32 -> dyn std::fmt::Display
let b2: Box<dyn std::fmt::Display> = b1;
// Rc<T> -> Rc<U>
let r1 = Rc::new(123i32);
let r2: Rc<dyn std::fmt::Display> = r1;
struct #
struct/enum/union 是 Rust 三种自定义类型,它们的命名惯例是 CamelCase,否则编译时警告。
- struct 成员的命名惯例是 snake_case;
其它命名风格:
- trait 类型使用 CameCase 风格;
- enum 的类型名和 variant 成员名都是 CameCase 风格。
- 变量、函数名和函数参数的命名风格是 snake_case 风格。
struct 三种类型:
- unit struct: 不含任何 field;
- tuple struct: 使用 tuple 来保存值,只有一个元素时,也称为 newtype struct;
- C-like struct: 指定各 field 类型;
struct Unit;
struct Pair(i32, f32);
struct Point {
x: f32, // 各 field 成员用逗号分割
y: f32,
}
// 实例化
let _unit = Unit; // 对于 unit struct,只有唯一的同名实例;
let pair = Pair(1, 0.1); // 初始化 tuple struct 时,类似于函数调用。
let Pair(integer, decimal) = pair; // 解构 struct,前面的 Pair 不能省。
创建 struct 对象时, 必须列出每一个 field,与 field 同名的变量赋值可以使用简写形式:
// 类型名是 CameCase
struct Person {
// 字段名是 came_case
name: String,
age: u8,
hobby: String,
}
let age = 30;
// Error:missing field `hobby` in initializer of `Person`
let p = Person {
name: String::from("sunface"),
age, // 与 field 同名的变量赋值, 可以使用简写形式。
};
// 同名的 field 可以简写。
let name = String::from("Peter");
let age = 27;
let peter = Person { name, age };
newtype struct:一般用于其它类型添加方法:
struct Years(i64);
struct Days(i64);
impl Years {
pub fn to_days(&self) -> Days {
Days(self.0 * 365)
}
}
impl Days {
pub fn to_years(&self) -> Years {
Years(self.0 / 365)
}
}
fn old_enough(age: &Years) -> bool {
age.0 >= 18
}
可以使用某个 struct 对象展开来快速创建一个新的 struct 对象, 但它必须位最后一项且结尾不能有逗号。
// 使用 struct 对象初始化另一个 struct 对象。
#[derive(Debug)]
struct User {
active: bool,
username: String,
email: String,
sign_in_count: u64,
}
fn main() {
let u1 = User {
email: String::from("[email protected]"),
username: String::from("sunface"),
active: true,
sign_in_count: 1,
};
let u2 = set_email(u1);
println!("Success! {u2:?}");
}
fn set_email(u: User) -> User {
User {
email: String::from("[email protected]"),
..u // u 必须位于最后且结尾不能有逗号
}
}
impl std::clone::Clone for Number {
fn clone(&self) -> Self {
// 如果 self 没有实现 Copy 则为 move 语义,可能会失败。
Self { ..*self }
}
}
如果 struct 类型实现了 Default trait,则也可使用 ..Default::default() 来快速初始化未指定的 fields,特别适合 field 比较多的情况:
// The builder can be used to create a span directly with the tracer
let _span = tracer.build(SpanBuilder {
name: "example-span-name".into(),
span_kind: Some(SpanKind::Server),
..Default::default() // Default::default() 返回一个自身类型(编译器推导)的 struct 对象;
});
无 field 的 struct MyStruct; 等效于 struct MyStruct {}; :
struct Cookie;
let c = [Cookie, Cookie {}, Cookie, Cookie {}];
// 等效于
struct Cookie {} // 类型定义
const Cookie: Cookie = Cookie {}; // 唯一的同名常量值定义
let c = [Cookie, Cookie {}, Cookie, Cookie {}];
struct 拥有各 field 对象所有权,包含引用类型成员时需要指定 lifetime。嵌套带生命周期的 struct 时,外层 struct 也必须声明生命周期。
为了避免为 struct 指定生命周期,field 一般使用 owned 类型而非 &T/&mut T 等借用类型 ('static 除外):
// 错误:r 是引用类型,但是没有为 struct 指定 lifetime,编译失败。
struct S {
r: &i32
}
let s;
{
let x = 10;
s = S { r: &x };
}
assert_eq!(*s.r, 10); // bad: reads from dropped `x`
// 正确,所有引用类型的 field 都是 'static 时,struct 可以不指定 lifetime
struct S {
r: &'static i32
}
// 正确,明确指定 lifetime,r 引用对象的生命周期至少要比 struct S 对象长
struct S<'a> {
r: &'a i32
}
// 正确,明确指定多个 lifetime 参数
struct S<'a, 'b> {
x: &'a i32,
y: &'b i32
}
// 错误:嵌套带 lifetime 的 struct filed 时,必须为其指定 lifetime
struct D {
s: S
}
// 正确
struct D<'a> {
s: S<'a>
}
struct 的可见性是 by field 的,默认是私有的,需要为 struct 整体和各 field 设置 pub 可见性。(enum 的可见性是整体的。)
struct 默认没有实现 Copy/Clone/Debug, 可以通过 derive macro 让编译器自动实现它们。
#[derive(Debug, Clone, Copy, PartialEq, Eq, Hash, Serialize, Deserialize)]
pub struct FrameId(pub u64);
Debug 打印并加 # 修饰,如 {:#?} 则以 pretty-print 方式打印 struct(自动换行和锁进):
struct 的各 field 可以被单独被转移所有权,如果 field 类型没有实现 Copy,则可能会被部分转移, 被转移的的 field 不能再访问:
- tuple/enum 也可以被部分转移;
- 但 array/slice/vec 元素不能被部分转移, 智能整体被 move(如迭代);
fn main() {
#[derive(Debug)]
struct Person {
name: String,
age: Box<u8>,
}
let person = Person {
name: String::from("Alice"),
age: Box::new(20),
};
// struct 可以使用 pattern match 解构。
//
// name 被从 person move 出来,但是 age 是借用。(模式匹配的 ref 用来修饰匹配后的标识符,表示是借用)
// 所以 person 是部分 move。
let Person { name, ref age } = person;
// 错误:person 存在部分 move(因为 age 是借用),整体不能再使用
//println!("The person struct is {:?}", person);
// 错误:person.name 已经被 move,不能再访问
//println!("The person name is {:?}", person.name);
// OK,person.age 是被 age 借用,没有被 move,可以继续使用
println!("The person's age from person struct is {}", person.age);
}
enum #
enum 成员称为 enum variant ,可以包含数据,有三种风格:
// enum 类型名和 variant field 名都需要是 CaseCaml,否则编译器警告。
// 对比:struct 类型名需要时 CaseCaml,struct field 是 came_case;
enum Message {
Quit,
Write(String),
ChangeColor(i32, i32, i32),
Move { x: i32, y: i32 },
}
fn main() {
let msgs: [Message; 3] = [
Message::Quit,
Message::Move{x:1, y:3},
Message::ChangeColor(255,255,0)
];
for msg in msgs {
show_message(msg)
}
}
可以使用 enum::variant as i32/u32 来获得 tag 值:
enum Number {
// tag 默认在上一个基础上递增,第一个 tag 为 0。
Zero,
One,
Two,
}
enum Foo {
Bar, // 0
Baz = 123, // 123
Quux, // 124
}
enum HttpResultCode {
// 明确设置 tag 值
Ok = 200,
NotFound = 404,
Teapot = 418,
}
// 不允许多个 field 使用相同的 tag 值(但是 C 允许)
enum SharedDiscriminantError2 {
Zero, // 0
One, // 1
OneToo = 1 // 错误:1 (collision with previous!)
}
// enum variant 可以根据 tag 转换为 integer
let code = HttpResultCode::NotFound;
assert_eq!(code as i32, 404);
特殊的空 enum (无 variant) 不能作为 value 使用, 主要的使用场景是作为不可能发生错误的 Result,如标准库类型 std::convert::Infallible :
// std::convert::Infallible
// {} 不能省,但是 unit type struct 的 {} 可以省,如 struct MyStruct;
pub enum Infallible {}
// 使用场景 TryFrom 的 trait
impl<T, U> TryFrom<U> for T where U: Into<T> {
type Error = Infallible;
fn try_from(value: U) -> Result<Self, Infallible> {
Ok(U::into(value)) // Never returns `Err`
}
}
// 当 !稳定后,Infallible 也可以使用 ! 的别名来定义。
pub type Infallible = !;
trait MyTrait {}
impl MyTrait for fn() -> ! {}
impl MyTrait for fn() -> std::convert::Infallible {}
// 另一个例子
enum ZeroVariants {}
let x: ZeroVariants = panic!();
// let y: u32 = x; // mismatched type error
enum 模式匹配时需要指定所有 variant:
#[derive(Debug, Clone, PartialEq, Eq, Hash, Serialize, Deserialize)]
pub enum IframeNavigation {
/// Navigate to the given URL (already resolved against the parent base URL by the renderer).
Url(String),
/// Navigate to `about:blank` (used for missing/empty `src`).
AboutBlank,
/// Navigate to `about:srcdoc` with the provided content hash.
Srcdoc { content_hash: u64 },
}
impl IframeNavigation {
/// Returns the effective URL string used for site-key computation.
#[inline]
pub fn effective_url(&self) -> &str {
match self {
IframeNavigation::Url(url) => url.as_str(),
IframeNavigation::AboutBlank => "about:blank",
IframeNavigation::Srcdoc { .. } => "about:srcdoc", // struct 类型的 variant 使用 .. 匹配所有 field
}
}
}
// 另一个例子
enum WebEvent {
PageLoad,
PageUnload,
KeyPress(char),
Paste(String),
Click { x: i64, y: i64 },
}
fn inspect(event: WebEvent) {
match event {
WebEvent::PageLoad => println!("page loaded"),
WebEvent::PageUnload => println!("page unloaded"),
WebEvent::KeyPress(c) => println!("pressed '{}'.", c),
WebEvent::Paste(s) => println!("pasted \"{}\".", s),
WebEvent::Click { x, y } => { println!("clicked at x={}, y={}.", x, y);},
}
}
// 创建 enum variant 时需要指定各类型的 field 值
fn main() {
let pressed = WebEvent::KeyPress('x');
let pasted = WebEvent::Paste("my text".to_owned());
let click = WebEvent::Click { x: 20, y: 80 };
let load = WebEvent::PageLoad;
let unload = WebEvent::PageUnload;
inspect(pressed);
inspect(pasted);
inspect(click);
inspect(load);
inspect(unload);
}
析构 enum:在 enum variant 值外部而非内部类匹配 & 或 &mut(tuple 类似):
let x: &Option<i32> = &Some(3);
// OK: 等效为 Some(ref y), y 的类型是 &i32
if let Some(y) = x {}
// OK: 在 variant 外指定 &,y 的类型是 i32
if let &Some(y) = x {}
// ERROR: 不能在 variant 内指定 &,expected `i32`, found `&_`
if let Some(&y) = x {}
// 另一个例子
enum MyEnum {
A { name: String, x: u8 },
B { name: String },
}
// name 和 x 都是析构后的变量名,可以在后面的 block 中使用。name 是 &mut String 类型。
fn a_to_b(e: &mut MyEnum) {
if let MyEnum::A {name, x: 0, } = e {
*e = MyEnum::B {
name: std::mem::take(name), // take 参数类型是 &mut T, 而 name 类型是 &mut String 故满足
}
}
// if let &mut MyEnum::A {
// name, // OK: name 是 String 类型
// x: 0,
// } = e
}
enum variant 可以使用 use 按需或一次性导入,这样不需要每次指定 enum::variant 的 enum:: 前缀:
#![allow(dead_code)]
enum Status {
Rich,
Poor,
}
enum Work {
Civilian,
Soldier,
}
fn main() {
use crate::Status::{Poor, Rich};
use crate::Work::*; // 一次导入所有 variant
let status = Poor;
let work = Civilian;
match status {
Rich => println!("The rich have lots of money!"),
Poor => println!("The poor have no money..."),
}
}
enum 可见性:只需为 enum 整体指定 pub 可见性即可,各 variant 的可见性继承自整体。(而 struct 的可见性是整体和各 field 分别设置,需要为每个 field 单独指定可见性)。
enum 内存布局包含两部分:
- tag 字段,能容纳所有 tag 值的最小整型,如 u8,用来区分 variant;
- 能容纳所有 variant 类型值的内存块;
union #
union 是用一块内存区域来保存不同类型值的类型,也就是可以按照不同类型对这块内存进行解释。
在创建 union 对象时,必须指定某一个 field,但是后续可以按照其它 field 来使用(解释)该 union 内存值:
// f 和 i 共享同一块内存区域
union FloatOrInt {
f: f32,
i: i32,
}
let mut one = FloatOrInt { i: 1 };
assert_eq!(unsafe { one.i }, 0x00_00_00_01);
one.f = 1.0;
assert_eq!(unsafe { one.i }, 0x3F_80_00_00);
union 类型的大小取决于最大 field,比如下面 union 的大小为 64 bytes:
union SmallOrLarge {
s: bool,
l: u64
}
必须在 unsafe block 中访问 union field,这是由于 union 不像 enum 那样,它的内存模型不包含 tag,所以编译器不知道存入和访问的是哪一个 field:
let u = SmallOrLarge { l: 1337 };
println!("{}", unsafe {u.l}); // prints 1337
使用 #[repr(C)] 来设置 union 使用 C 内存布局:
#[repr(C)]
union SignExtractor {
value: i64,
bytes: [u8; 8]
}
fn sign(int: i64) -> bool {
let se = SignExtractor { value: int};
println!( "{:b} ({:?})", unsafe { se.value }, unsafe { se.bytes });
unsafe { se.bytes[7] >= 0b10000000 }
}
assert_eq!(sign(-1), true);
assert_eq!(sign(1), false);
assert_eq!(sign(i64::MAX), false);
assert_eq!(sign(i64::MIN), true);
union 用不同的方式来解释同一块内存区域,编译器不知道如何 Drop union 对象,所以各 field 类型必须都实现 Copy。
- 如果要保存 String 类型,则可以参考
std::mem::ManuallyDrop。
可以对 union 使用模式匹配,但每个 pattern 只能包含一个 field,如果只指定 filed 但是没有值则一定可以匹配成功。
unsafe {
match u {
SmallOrLarge { s: true } => { println!("boolean true"); } // 如果按照 s 来解释,能够匹配 true
SmallOrLarge { l: 2 } => { println!("integer 2"); } // 如果按照 l 来解释,能够匹配 2
_ => { println!("something else"); }
}
}
borrow uinon 某个 filed 等效于 borrow 整个 union,所以在 borrow 某个 field 后就不能再 borrow 其它 field。