SqlType trait 和 sql_type module #
SqlType trait 是一个标记 trait,可以由 #[derive(SqlType)] 自动实现, 它将内部的 IsNull 关联类型设置为 Struct diesel::sql_types::is_nullable::NotNull;
/// A marker trait for SQL types
///
/// # Deriving
///
/// This trait is automatically implemented by [`#[derive(SqlType)]`](derive@SqlType)
/// which sets `IsNull` to [`is_nullable::NotNull`]
///
pub trait SqlType: 'static {
/// Is this type nullable?
///
/// This type should always be one of the structs in the ['is_nullable`]
/// module. See the documentation of those structs for more details.
///
/// ['is_nullable`]: is_nullable
type IsNull: OneIsNullable<is_nullable::IsNullable> + OneIsNullable<is_nullable::NotNull>;
}
diesel::sql_types module 提供了实现 SqlType trait 的 DB 无关抽象类型,如 Interger, Int4, Binary, Timestamp 等, 它们在 table!() 中使用, 由各 DB Backend 转换为对应的具体数据库类型。(详细的 SqlType 列表见后文。)
/// [i32]: https://doc.rust-lang.org/nightly/std/primitive.i32.html
#[derive(Debug, Clone, Copy, Default, QueryId, SqlType)] // 实现 SqlType
#[diesel(postgres_type(oid = 23, array_oid = 1007))] // 各种 DB Backend 实现的字段类型
#[diesel(sqlite_type(name = "Integer"))]
#[diesel(mysql_type(name = "Long"))]
pub struct Integer;
pub type Int4 = Integer;
示例:
// CREATE TABLE posts (
// id INTEGER AUTO_INCREMENT PRIMARY KEY,
// title VARCHAR(255) NOT NULL,
// body TEXT NOT NULL,
// published BOOLEAN NOT NULL DEFAULT FALSE
// );
// diecel 自动生成的 src/schema.rs 文件
diesel::table! {
posts (id) {
id -> Integer,
title -> Varchar, // SQL VARCHAR(N) 类型对应 diesel 的 Varchar 类型
body -> Text, // SQL TEXT 类型对应 diesel 的 Text 类型
published -> Bool,
}
}
diesel 使用 FromSql/ToSql trait 在 diesel SqlType 和 Rust 类型之间转换:
FromSql: 将 diesel SqlType 类型转换为 Rust 类型, 如 Interger -> i32;ToSql: 从 Rust 类型转换为 diesel SqlType 类型, 如 i32 -> Interger;
diesel 为绝大部分 Rust 类型, Uuid/Json 等类型实现了这两个 trait:
// Struct diesel::sql_types::Integer
pub struct Integer;
// 每种 DB Backend 都定义了自己的 ToSql 和 FromSql 实现,用于 sql_type 和 Rust 类型类型的转换
impl ToSql<Integer, Mysql> for i32
impl ToSql<Integer, Pg> for i32
impl ToSql<Integer, Sqlite> for i32
impl FromSql<Integer, Mysql> for i32
impl FromSql<Integer, Pg> for i32
impl FromSql<Integer, Sqlite> for i32
通过这两个 trait,diesel 知道如何将 Rust 类型值(如 i32)写入数据库,以及如何将数据库字段值(raw bytes)转换为 Rust 类型值。
实现 SqlType #
通过实现 SqlType/FromSql/ToSql trait,可以可以扩展 table!() 中使用的类型。
以添加 Language 类型为例:
- 在数据库层面定义一个自定义 SQL 类型,如
Language; - diesel 自动在 schema.rs 的
sql_types module为该 SQL 类型生成一个同名的Language类型,并实现 diesel SqlType trait,后续作 table!() 中使用; - 用户需要再定一个 Rust 类型,并使用
#[diesel(sql_type = crate::schema::sql_types::Language)]将它和上面生成的 diesel sql_type 类型关联起来; - 用户需要为上面的 Rust 类型实现
FromSql/ToSql/AsExpression/FromSqlRow trait,从而实现 Rust 值到数据库字段值之间的相互转换; - 用户自定义的与
table!()对应的Queryable/Selectable struct model中使用上面自定义的 Rust 类型;
// https://github.com/diesel-rs/diesel/tree/2.2.x/examples/postgres/custom_types
// https://github.com/marvin-hansen/bazel-diesel-postgres?tab=readme-ov-file
// up.sql
// CREATE TYPE Language AS ENUM (
// 'en', 'ru', 'de'
// );
// CREATE TABLE translations (
// word_id INTEGER NOT NULL,
// translation_id INTEGER NOT NULL,
// language Language NOT NULL,
// PRIMARY KEY (word_id, translation_id)
// )
// @generated automatically by Diesel CLI.
// 自动在项目的 schema.rs 的 sql_types module 中自动生成一个名为 Language 的自定义 diesel SqlType 类型
// 1. 使用 #[derive(diesel::sql_types::SqlType)] 来为 Language 实现 SqlType trait;
pub mod sql_types {
#[derive(diesel::sql_types::SqlType)] // 使用 derive macro 实现 SqlType
#[diesel(postgres_type(name = "language"))] // 关联的 PG 字段类型名称
pub struct Language;
}
// 自动生成的 schema.rs 中 table!() 中使用该类型
diesel::table! {
use diesel::sql_types::*;
use super::sql_types::Language; // 导入自定义 diesel SqlType 类型
translations (word_id, translation_id) {
word_id -> Int4,
translation_id -> Int4,
language -> Language, // 使用该类型
}
}
use diesel::deserialize::{self, FromSql, FromSqlRow};
use diesel::expression::AsExpression;
use diesel::pg::{Pg, PgValue};
use diesel::serialize::{self, IsNull, Output, ToSql};
use std::io::Write;
// 再为 sql_types 类型绑定一个 Rust 类型,它需要实现 AsExpression、FromSqlRow、ToSql 和 FromSql
// 1. 实现 ToSql 的同时需要实现 AsExpression
// 2. 实现 FromSql 的同时需要实现 FromSqlRow
#[derive(Debug, AsExpression, FromSqlRow)]
#[diesel(sql_type = crate::schema::sql_types::Language)] // 关联 diesel SqlType 类型
pub enum Language {
En,
Ru,
De,
}
impl ToSql<crate::schema::sql_types::Language, Pg> for Language {
fn to_sql<'b>(&'b self, out: &mut Output<'b, '_, Pg>) -> serialize::Result {
match *self {
Language::En => out.write_all(b"en")?,
Language::Ru => out.write_all(b"ru")?,
Language::De => out.write_all(b"de")?,
}
Ok(IsNull::No)
}
}
impl FromSql<crate::schema::sql_types::Language, Pg> for Language {
fn from_sql(bytes: PgValue) -> deserialize::Result<Self> {
match bytes.as_bytes() {
b"en" => Ok(Language::En),
b"ru" => Ok(Language::Ru),
b"de" => Ok(Language::De),
_ => Err("Unrecognized enum variant".into()),
}
}
}
// main.rs
use self::schema::translations;
use diesel::prelude::*;
mod model;
mod schema;
#[derive(Debug, Queryable, Insertable)]
#[diesel(table_name = translations)]
pub struct Translation {
word_id: i32,
translation_id: i32,
language: model::Language, // 使用自定义类型
}
fn main() {
let database_url = std::env::var("DATABASE_URL").expect("DATABASE_URL must be set");
let conn = &mut PgConnection::establish(&database_url)
.unwrap_or_else(|e| panic!("Error connecting to {}: {}", database_url, e));
let _ = diesel::insert_into(translations::table)
.values(&Translation {
word_id: 1,
translation_id: 1,
language: model::Language::En,
})
.execute(conn);
let t = translations::table
.select((
translations::word_id,
translations::translation_id,
translations::language,
))
.get_results::<Translation>(conn)
.expect("select");
println!("{t:?}");
}
作为简化场景,可以为自定义 Rust 类型转换为 SqlType 类型:
use diesel::deserialize::{self, FromSql};
use diesel::pg::Pg;
#[derive(FromSqlRow, AsExpression)]
#[diesel(sql_type = diesel::sql_types::Text)] // 已有的 SqlType 类型,自动实现了 ToSql trait
struct Email(String);
// 但还是需要实现 FromSql trait
impl FromSql<diesel::sql_types::Text, Pg> for Email {
fn from_sql(bytes: Option<&[u8]>) -> deserialize::Result<Self> {
let s = <String as FromSql<diesel::sql_types::Text, Pg>>::from_sql(bytes)?;
if is_valid_email(&s) {
Ok(Email(s))
} else {
Err("Invalid email format".into())
}
}
}
Expression/AsExpression #
Expression 是一个包含 SqlType 关联类型的 trait:
pub trait Expression {
/// The type that this expression represents in SQL
type SqlType: TypedExpressionType; // 实际约束为实现 SqlType trait 的任意类型
}
// TypedExpressionType 是一个标记 trait
pub trait TypedExpressionType {}
// ST 最终需要实现 diesel::sql_types::SqlType
impl<ST> TypedExpressionType for ST where ST: SingleValue {}
// SingleValue 也是一个标记 trait
pub trait SingleValue: SqlType {}
table!() 为所有 table 字段自动实现 Exression trait:
diesel::table! {
posts (id) {
id -> Int4,
title -> Varchar,
body -> Text,
published -> Bool,
}
}
// 以 id 字段为例,展开 table!() 宏后,diesel 为 id 实现了 Expression
impl diesel::expression::Expression for id {
type SqlType = Int4;
}
AsExpression<T> trait 是可以将任意类型转换为 Expression<SqlType=T>:
pub trait AsExpression<T> where T: SqlType + TypedExpressionType,
{
/// The expression being returned
type Expression: Expression<SqlType = T>;
/// Perform the conversion
#[allow(clippy::wrong_self_convention)]
// That's public API we cannot change it to appease clippy
fn as_expression(self) -> Self::Expression; // 消耗 self
}
diesel 为绝大部分 Rust 类型实现了 AsExpression trait:
use crate::sql_types::{
self, BigInt, Binary, Bool, Double, Float, Integer, SingleValue, SmallInt, Text,
};
#[allow(dead_code)]
mod foreign_impls {
use super::*;
use crate::deserialize::FromSqlRow;
#[derive(AsExpression, FromSqlRow)] // 自动实现 AsExpression, FromSqlRow
#[diesel(foreign_derive)]
#[diesel(sql_type = Bool)] // 对应 SqlType 类型是 Bool
struct BoolProxy(bool);
#[derive(AsExpression)]
#[diesel(foreign_derive, not_sized)]
#[diesel(sql_type = Text)]
#[cfg_attr(feature = "sqlite", diesel(sql_type = crate::sql_types::Date))]
#[cfg_attr(feature = "sqlite", diesel(sql_type = crate::sql_types::Time))]
#[cfg_attr(feature = "sqlite", diesel(sql_type = crate::sql_types::Timestamp))]
#[cfg_attr(feature = "postgres_backend", diesel(sql_type = crate::sql_types::Citext))]
struct StrProxy(str);
//...
}
table!() 宏为所有表格字段实现了 AsExpression trait,对于自定义类型可以使用 #[derive(AsExpression)] 来实现它:
#[derive(Debug, AsExpression)]
#[diesel(sql_type = crate::schema::sql_types::Language)] // 关联 diesel SqlType 类型
pub enum Language {
En,
Ru,
De,
}
AsExpression 主要用作 trait 限界,相比 Expression,AsExpression 作为限界时可以同时传入 Rust 基本类型以及 diesel SqlType 类型。
例如 ExpressionMethods trait 的各方法的限界:
// Trait diesel::expression_methods::ExpressionMethods
pub trait ExpressionMethods: Expression + Sized {
fn eq<T>(self, other: T) -> Eq<Self, T> where Self::SqlType: SqlType, T: AsExpression<Self::SqlType>
fn ne<T>(self, other: T) -> NotEq<Self, T> where Self::SqlType: SqlType, T: AsExpression<Self::SqlType>
fn eq_any<T>(self, values: T) -> EqAny<Self, T> where Self::SqlType: SqlType, T: AsInExpression<Self::SqlType>
fn ne_all<T>(self, values: T) -> NeAny<Self, T> where Self::SqlType: SqlType, T: AsInExpression<Self::SqlType>
//...
}
// 示例: eq() 方法使用实现 AsExpression 的 Rust 基本类型 &str
users.filter(name.eq("Sean")).filter(hair_color.eq("black"))
由于 disel 为绝大部分 Rust 基本类型实现了 AsExpression trait,所以可以使用 34i32.as_expression::<Integer>() 返回一个 Expression::<Integer> 类型。
diesel 为 Expression 实现了 AsExpression,所以在需要 AsExpression 的地方也可以传入 Expression:
impl<T, ST> AsExpression<ST> for T
where
T: Expression<SqlType = ST>,
ST: SqlType + TypedExpressionType,
// 示例:
let names = users::table.select("The Amazing ".as_expression::<Text>().concat(users::name)).load(conn);
IntoSql #
IntoSql 用于将实现 AsExpression<U> 的 Rust 基本类型转换为 Expression, 如: "The Amazing ".into_sql::<Text>() 返回 Expression<Text> 类型值。
x.into_sql::<Y>()消耗 x,等效于AsExpression::<Y>::as_expression(x)x.as_sql::<Y>()不消耗 x,等效于AsExpression::<Y>::as_expression(&x)
/// Converts a type to its representation for use in Diesel's query builder.
///
/// This trait only exists to make usage of `AsExpression` more ergonomic when
/// the `SqlType` cannot be inferred. It is generally used when you need to use
/// a Rust value as the left hand side of an expression, or when you want to
/// select a constant value.
///
/// # Example
///
/// # include!("../doctest_setup.rs");
/// # use schema::users;
/// #
/// # fn main() {
/// use diesel::sql_types::Text;
/// # let conn = &mut establish_connection();
/// let names = users::table
/// .select("The Amazing ".into_sql::<Text>().concat(users::name))
/// .load(conn);
/// let expected_names = vec![
/// "The Amazing Sean".to_string(),
/// "The Amazing Tess".to_string(),
/// ];
/// assert_eq!(Ok(expected_names), names);
/// # }
///
pub trait IntoSql {
/// Convert `self` to an expression for Diesel's query builder.
///
/// There is no difference in behavior between `x.into_sql::<Y>()` and
/// `AsExpression::<Y>::as_expression(x)`.
fn into_sql<T>(self) -> AsExprOf<Self, T> where Self: AsExpression<T> + Sized, T: SqlType + TypedExpressionType,
{
self.as_expression()
}
/// Convert `&self` to an expression for Diesel's query builder.
///
/// There is no difference in behavior between `x.as_sql::<Y>()` and
/// `AsExpression::<Y>::as_expression(&x)`.
fn as_sql<'a, T>(&'a self) -> AsExprOf<&'a Self, T> where &'a Self: AsExpression<T>, T: SqlType + TypedExpressionType,
{
<&'a Self as AsExpression<T>>::as_expression(self)
}
}
// 为任意类型 T 实现 IntoSql
impl<T> IntoSql for T {}
AsExpression 和 IntoSql 都可以将 Rust 类型转换为 Expression<T> 类型值(消耗 self),但是 IntoSql trait 不包含需要推导的关联类型,所以更通用:
let names = users::table.select("The Amazing ".as_expression::<Text>().concat(users::name)).load(conn);
let names = users::table.select("The Amazing ".into_sql::<Text>().concat(users::name)).load(conn);
表达式方法 #
diesel::expression_methods::ExpressionMethods 是应用于 Expression 的方法。
// diesel 为 Expression 实现了 ExpressionMethods
impl<T> ExpressionMethods for T where T: Expression, T::SqlType: SingleValue
// table!() 为表字段 name 实现了 Expression,而 eq() 是应用于 Expression 的方法
let seans_id = users.filter(name.eq("Sean")).select(id).first(connection);
table!() 宏为表格字段实现了 ExpressionMethods trait, 同时根据字段类型,还按需实现了 expression_methods module 下的其它 trait,如 text 字段实现了 TextExpressionMethods,bool 字段实现了 BoolExpressionMethods。这样,后续对于 bool 类型字段,可以使用 and()/or() 方法,对于 text 文本类型字段,可以使用 concat()/like()/not_like() 方法。
// Trait diesel::expression_methods::ExpressionMethods
pub trait ExpressionMethods: Expression + Sized {
// 指定的值, T 需要实现 AsExpression,diesel 为 Rust 基本类型实现了改 trait,故可以传入对应的字面量
fn eq<T>(self, other: T) -> Eq<Self, T> where Self::SqlType: SqlType, T: AsExpression<Self::SqlType>
fn ne<T>(self, other: T) -> NotEq<Self, T> where Self::SqlType: SqlType, T: AsExpression<Self::SqlType>
fn eq_any<T>(self, values: T) -> EqAny<Self, T> where Self::SqlType: SqlType, T: AsInExpression<Self::SqlType>
fn ne_all<T>(self, values: T) -> NeAny<Self, T> where Self::SqlType: SqlType, T: AsInExpression<Self::SqlType>
// 是否为 null
fn is_null(self) -> IsNull<Self>
fn is_not_null(self) -> IsNotNull<Self>
// 大小
fn gt<T>(self, other: T) -> Gt<Self, T> where Self::SqlType: SqlType, T: AsExpression<Self::SqlType>
fn ge<T>(self, other: T) -> GtEq<Self, T> where Self::SqlType: SqlType, T: AsExpression<Self::SqlType>
fn lt<T>(self, other: T) -> Lt<Self, T> where Self::SqlType: SqlType, T: AsExpression<Self::SqlType>
fn le<T>(self, other: T) -> LtEq<Self, T> where Self::SqlType: SqlType, T: AsExpression<Self::SqlType>
// 范围
fn between<T, U>(self, lower: T, upper: U) -> Between<Self, T, U> where Self::SqlType: SqlType, T: AsExpression<Self::SqlType>, U: AsExpression<Self::SqlType>
fn not_between<T, U>(self, lower: T, upper: U) -> NotBetween<Self, T, U> where Self::SqlType: SqlType, T: AsExpression<Self::SqlType>, U: AsExpression<Self::SqlType>
// 排序
fn desc(self) -> Desc<Self>
fn asc(self) -> Asc<Self>
}
// Trait diesel::expression_methods::TextExpressionMethods
pub trait TextExpressionMethods: Expression + Sized {
// Provided methods
fn concat<T>(self, other: T) -> Concat<Self, T> where Self::SqlType: SqlType, T: AsExpression<Self::SqlType>
// This method is case insensitive for SQLite and MySQL. On PostgreSQL, LIKE is case
// sensitive. You may use ilike() for case insensitive comparison on PostgreSQL.
fn like<T>(self, other: T) -> Like<Self, T> where Self::SqlType: SqlType, T: AsExpression<Self::SqlType>
fn not_like<T>(self, other: T) -> NotLike<Self, T> where Self::SqlType: SqlType, T: AsExpression<Self::SqlType>
}
// Trait diesel::expression_methods::BoolExpressionMethods
pub trait BoolExpressionMethods: Expression + Sized {
// Provided methods
fn and<T, ST>(self, other: T) -> And<Self, T, ST> where Self::SqlType: SqlType, ST: SqlType + TypedExpressionType, T: AsExpression<ST>, And<Self, T::Expression>: Expression
fn or<T, ST>(self, other: T) -> Or<Self, T, ST> where Self::SqlType: SqlType, ST: SqlType + TypedExpressionType, T: AsExpression<ST>, Or<Self, T::Expression>: Expression
}
impl<T> BoolExpressionMethods for T where T: Expression, T::SqlType: BoolOrNullableBool,
impl BoolOrNullableBool for Bool
impl BoolOrNullableBool for Nullable<Bool>
// text 字段实现了 TextExpressionMethods,故可以使用 concat() 方法
let names = users::table.select( "The Amazing ".into_sql::<Text>().concat(users::name)).load(conn);
// species.eq("ferret") 返回的 Eq 类型实现了 BoolExpressionMethods,故可以使用 and() 方法
let data = animals.select((species, name))
.filter(species.eq("ferret").and(name.eq("Jack")))
.load(connection)?;
Eq/NotEq/EqAny/Gt/GtEq/Lt/LtEq/NotEq/NotLike/Between/NeAny/Bool/Nullable<bool> 实现 BoolExpressionMethods。
以 Eq 为例:
impl diesel::expression::Expression for published {
type SqlType = Bool;
}
// 这些类型都是两个参数来调用 infix_operator!() 宏,所以它们都实现了 BoolExpressionMethods
// /Users/alizj/.cargo/registry/src/index.crates.io-1949cf8c6b5b557f/diesel-2.3.3/src/expression/operators.rs
infix_operator!(Eq, " = ");
infix_operator!(And, " AND ");
infix_operator!(Or, " OR ");
infix_operator!(Escape, " ESCAPE ");
infix_operator!(Eq, " = ");
infix_operator!(Gt, " > ");
infix_operator!(GtEq, " >= ");
infix_operator!(Lt, " < ");
infix_operator!(LtEq, " <= ");
infix_operator!(NotEq, " != ");
infix_operator!(NotLike, " NOT LIKE ");
infix_operator!(Between, " BETWEEN ");
infix_operator!(NotBetween, " NOT BETWEEN ");
// /Users/alizj/.cargo/registry/src/index.crates.io-1949cf8c6b5b557f/diesel-2.3.3/src/expression/operators.rs
#[macro_export]
macro_rules! infix_operator {
($name:ident, $operator:expr) => {
$crate::infix_operator!($name, $operator, $crate::sql_types::Bool);
};
// infix_operator!(Eq, " = "); 只有两个参数,所以匹配该 branch,第三个参数默认为 Bool
($name:ident, $operator:expr, backend: $backend:ty) => {
$crate::infix_operator!($name, $operator, $crate::sql_types::Bool, backend: $backend);
};
($name:ident, $operator:expr, $($return_ty:tt)::*) => {
$crate::__diesel_infix_operator!(
name = $name,
operator = $operator,
return_ty = NullableBasedOnArgs ($($return_ty)::*),
backend_ty_params = (DB,),
backend_ty = DB,
);
};
// 再次匹配该 branch
($name:ident, $operator:expr, $($return_ty:tt)::*, backend: $backend:ty) => {
$crate::__diesel_infix_operator!(
name = $name,
operator = $operator,
return_ty = NullableBasedOnArgs ($($return_ty)::*),
backend_ty_params = (),
backend_ty = $backend,
);
};
}
// 而 __diesel_infix_operator! 最终会调用 __diesel_operator_body!() 宏,而该宏为 Eq 实现了 Expression,而且 SqlType 为 Bool,
// 所以,最终 Eq 也实现了 BoolExpressionMethods
// /Users/alizj/.cargo/registry/src/index.crates.io-1949cf8c6b5b557f/diesel-2.3.3/src/expression/operators.rs
macro_rules! __diesel_operator_body {
impl<$($ty_param,)+ $($expression_ty_params,)*> $crate::expression::Expression for $name<$($ty_param,)+> where
$($expression_bounds)*
{
type SqlType = $($return_ty)*;
}
}
ExpressionMethods 各方法的参数主要是 AsExpression 类型,所以可以传入 Rust 基本类型和 SqlType 类型,而且结果还是 Expression 类型,而 Expression 又实现了 ExpressionMethods,故可以链式调用:
// 以 eq() 返回的 Eq 为例, 它是 Grouped 类型别名, 而 Grouped 实现了 Expression trait
pub type Eq<Lhs, Rhs> = Grouped<Eq<Lhs, AsExpr<Rhs, Lhs>>>;
// https://docs.diesel.rs/2.2.x/src/diesel/expression/grouped.rs.html
#[derive(Debug, Copy, Clone, QueryId, Default, DieselNumericOps, ValidGrouping)]
pub struct Grouped<T>(pub T);
// Grouped 也实现了 Expression
impl<T: Expression> Expression for Grouped<T> {
type SqlType = T::SqlType;
}
// 示例:
// name 是 Expression,实现了 ExpressionMethods,它的 eq() 方法参数是 AsExpression,所以可以传入 Rust 基本类型。
// eq() 返回值类型 Eq 也是 Expression, 所以可以作为 filter() 的参数。
let seans_id = users.filter(name.eq("Sean")).select(id).first(connection);
// species.eq("ferret") 的结果 Eq 实现了 Expression、BoolExpressionMethods,故可以调用 .and()/or() 方法,结果还是 Expression, 所以可以作为 filter() 的参数。
let data = animals.select((species, name))
.filter(species.eq("ferret").and(name.eq("Jack")))
.load(connection)?;
let expected = vec![ (String::from("ferret"), Some(String::from("Jack"))), ];
assert_eq!(expected, data);
disel::table!() #
执行 diesel migration run 命令时,diesel cli 根据环境变量 DATABASE_URL 的数据库连接信息来生成 src/schema.rs 文件,该文件使用 diese::table!() 宏来定义匹配的数据库 schema。
- 也可以执行
diesel print-schema命令来打印table!()宏内容。
- 缺省情况下,
table!()支持最大 32 clomuns per table,可以启用64-column-tables/128-column-tables feature,来支持 64/128 列,但列数越多,编译越慢。 Struct diesel::sql_types::Nullable用于封装可以是 NULL 的类型,默认所有 table field 都是 NOT NULL。- 在 migration up.sql 中定义的表列如果没有加 NOT NULL,则表示可以是 NULL 的,这时自动生成的 schema.rs 中的字段就是
Nullable<T>, 对应的 struct model 应该是Option<U>;
- 在 migration up.sql 中定义的表列如果没有加 NOT NULL,则表示可以是 NULL 的,这时自动生成的 schema.rs 中的字段就是
table!() 宏的内容:
- 支持数组字段类型,如:
Nullable<Array<Text>>。 - 支持 JSON 数据类型,如:Jsonb。
- 主要是字段名称和字段类型,不体现缺省值;
table!() 宏中可以使用的 diesel SqlType 类型:
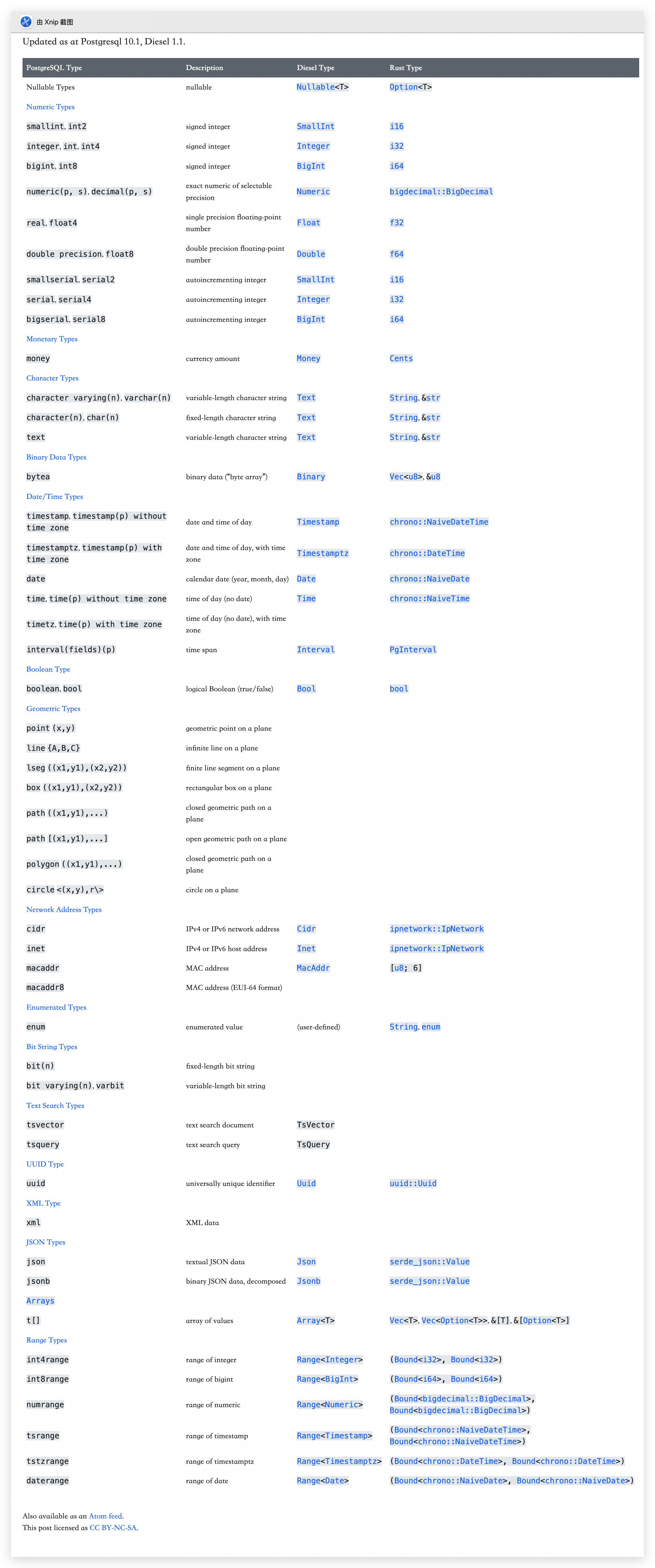
| SQL 类型 | diesel SqlType 类型 | Rust 类型 |
|---|---|---|
| text | Text | String 和 &str |
| interger | Integer | i32 |
| binary | Binary | Vec |
| timestamp(不带 TZ) | Timestamp | chrono::NaiveDateTime |
| timestamptz(带 TZ) | Timestamptz | chrono::DateTime |
| date | Date | chrono::NaiveDate |
| time(不带 TZ) | Time | chrono::NaiveTime |
| interval | Interval | PgInterval |
| boolean | Bool | bool |
| enum | user-defined | String, enum |
| uuid | Uuid | uuid::Uuid |
| json(文本) | Json | serde_json::Value |
| jsonb(二进制) | Jsonb | serde_json::Value |
| array | Array |
Vec |
注:
Mysql TIMESTAMP类型:插入时将值从 by conn 的当前时区值转为 UTC 时区值存入 db,查询时将保存的 UTC 值转换为连接对应的时区值;Mysql DATIMETIME类型:原样写入和查询,不会做任何转换;SQL TIMESTAMP类型是不带 timezone 的类型,对应 Diesle 类型 Timestamp,对应 Rust 类型可以是 chrono::NativeDateTime.
// 导入 table!() 宏使用的 SqlType
use diesel::sql_types::*;
diesel::table! {
posts (id) { // id 为默认 PK
id -> Int4,
title -> Varchar, // 字段默认是 NOT NULL
body -> Text,
published -> Bool,
}
}
diesel::table! {
users {
id -> Integer,
name -> VarChar,
favorite_color -> Nullable<VarChar>, // 使用 Nullable 来设置可以为 NULL 的字段,对应的 struct model 是 Option<T> 类型
}
}
diesel::table! {
users (non_standard_primary_key) { // 如果 PK 不是默认的字段 id,则需要手动指定
non_standard_primary_key -> Integer,
name -> VarChar,
favorite_color -> Nullable<VarChar>,
last_used_at -> Nullable<Timestamp>, // 可以使用 Json、Jsonb、Timestamp、UUID 等类型
crate_scopes -> Nullable<Array<Text>>, // 可以是数组 Array 类型,对应 struct model 是 Option<Vec<T>> 类型
}
followings (user_id, post_id) { // 手动指定组合 PK
user_id -> Integer,
post_id -> Integer,
favorited -> Bool,
}
}
// 手动为自动生成的 table 添加注释(注意是 cargo doc 注释类型,后续会保留)
diesel::table! {
/// The table containing all blog posts
posts {
/// The post's unique id
id -> Integer,
/// The post's title
title -> Text,
/// This column is named `mytype` but references the table `type` column.
#[sql_name = "type"] // table 中字段名为 type,避免 Rust 关键字冲突
mytype -> Text,
}
}
展开 table!() 后,生成一个和表同名的 module,如 mod posts,同时它包含两个子 module:posts::dsl 和 posts::columns;
posts::columns module:pub struct star:select * 返回的类型;posts::all_columns: 包含所有表列的 tuple,当未指定select()时返回的列;- 每个表字段对应一个同名的 struct 类型, 如
pub struct id;,diesel 根据字段类型来实现不同的 trait,如为 text 实现了 TextExpressionMethods trait;
posts::dsl module:- 导入了 posts::columns 中定义的 id 等各种表字段的同名类型;
- 将 table 重命名为 posts;
table!() 为每个表字段都实现了 Expression/AsExpression trait 以及相关的 ExpressionMethod trait:
#[allow(unused_imports,dead_code,unreachable_pub)]
pub mod posts {
pub use self::columns:: * ; // 导出各 field 字段对应的类型,如 id, title, body 等
// 后续一般被外部代码 use posts::dsl::* 导入使用的表字段和表类型
pub mod dsl {
pub use super::columns::id;
pub use super::columns::title;
pub use super::columns::body;
pub use super::columns::published;
pub use super::table as posts; // table 别名为 posts
}
// 查询时,如果未调用 select() 来指定字段名 tuple,则默认返回 all_columns 对应的表所有字段
pub const all_columns:(id,title,body,published,) = (id,title,body,published,);
// 固定类型 table
pub struct table;
impl table {
pub fn star(&self) -> star {
star // star 是在后续 self::columns 中定义的 pub struct star;
}
}
// all_columns 对应的字段类型
pub type SqlType = (Int4,Varchar,Text,Bool,);
pub type BoxedQuery<'a,DB,ST = SqlType>
// 为 table 实现各种 trait
impl diesel::QuerySource for table
impl <DB>diesel::query_builder::QueryFragment<DB>for table
impl diesel::query_builder::AsQuery for table
impl diesel::Table for table
impl diesel::associations::HasTable for table
impl diesel::query_builder::IntoUpdateTarget for table
impl diesel::query_source::AppearsInFromClause<table>for table
impl <T>diesel::insertable::Insertable<T>for table
#[doc = r" Contains all of the columns of this table"]
pub mod columns {
use super::table;
// start 用于 users.* 查询
pub struct star;
// star 实现了各种 trait
impl <__GB>diesel::expression::ValidGrouping<__GB> for star
impl diesel::Expression for star {
impl <DB:diesel::backend::Backend>diesel::query_builder::QueryFragment<DB> for star
impl diesel::SelectableExpression<table> for star
impl diesel::AppearsOnTable<table> for star
// 每一个 struct 成员对对应一个类型
// 这里以 id 为例:
#[allow(non_camel_case_types,dead_code)]
#[derive(Debug,Clone,Copy,diesel::query_builder::QueryId,Default)]
pub struct id;
// 每个成员类型都实现了 Expression, 在 select 中使用.
impl diesel::expression::Expression for id {
type SqlType = Int4; // 决定了 ExpressionMethods 可以使用的方法
}
impl <DB>diesel::query_builder::QueryFragment<DB>for id
impl diesel::SelectableExpression<super::table>for id
// delete/update 等的 filter() 等使用
impl <QS>diesel::AppearsOnTable<QS>for id
impl <Left,Right>diesel::SelectableExpression<diesel::internal::table_macro::Join<Left,Right,diesel::internal::table_macro::LeftOuter> , >for id
impl diesel::query_source::Column for id
// 根据 id 的类型, 自动为它实现了各种 trait
// 如为 int 类型实现了 EqAll 和 std::ops::*,为 text 类型实现 TextExpressionMethods(提供了 like、not_like 等方法)
impl <T>diesel::EqAll<T>for id
impl <Rhs> ::std::ops::Add<Rhs>for id
impl <Rhs> ::std::ops::Sub<Rhs>for id
impl <Rhs> ::std::ops::Div<Rhs>for id
impl <Rhs> ::std::ops::Mul<Rhs>for id
}
一般使用 use posts::dsl::* 的方式来导入 table!() 宏生成的表类型、表各字段类型:
- 引用表:
posts::table或posts::dsl::posts; - 引用表字段:
posts::id/title或posts::dsl::id/title;
// 不建议:
users::table.filter(users::name.eq("Sean")).filter(users::hair_color.eq("black"))
// 建议:
users.filter(name.eq("Sean")).filter(hair_color.eq("black"))
fn main() {
use self::schema::posts::dsl::posts; // 建议:导入 posts table
// ...
let post = posts
.find(post_id)
.select(Post::as_select())
.first(connection)
.optional(); // This allows for returning an Option<Post>, otherwise it will throw an error
// ...
}
// 如果要使用 star, 则可以调用 users 的 star() 方法。
#[derive()] 宏和表 model
#
参考文档: https://github.com/diesel-rs/diesel/blob/2.2.x/guide_drafts/trait_derives.md
在进行 select/insert/update/delete 时可以传入 struct 类型值,但是这些 struct 类型一般需要实现如下 derive 宏:
AsChangeset:
diesel::insert(table).on_conflict().set(changeset):set() 方法参数类型是 AsChangeset;Eq/Grouped<Eq<Left, Right>>/Tuple均实现了该 trait, 对于自定义类型 struct 实现该 trait 后, 可以传入自定义类型;
Associations:
- 用于关联表场景,在 child 表(含有外键的表)上定义。
- 同时使用的还有
#[diesel(belongs_to(Book, foreign_key = book_id))]来指定关联表和外键字段。
Identifiable:
- Identifiable 实现了
IntoUpdateTarget trait,可以作为diesel::delete()/update()的参数;
Insertable:
- 为 struct 类型实现 Insertable,可以作为
diesel::insert_into(table).values()的参数;
对于 select 返回,insert/update 的 returning clause 子句返回的记录,可以转换为 Queryable 或 Selectable。
Queryable: 用于将 SQL 查询结果转换为表对应的 struct (不需要覆盖表的全部字段)
- 可以作为
diesel::prelude::RunQueryDsl的各方法返回值类型,如first::<User>();
QueryableByName: 将 untyped SQL 查询,如 sql_query() 返回的结果,转换为 struct。
Selectable: 用于将 SQL 查询结果转换为 struct,需要 table 字段一一对应。
一般需要根据自动生成的 table!() 的表定义创建如下几个 struct model 类型:
- 和 table!() schema 一一匹配的 Queryable, Selectable 的 struct;
- insert() 时指定要插入的部分字段 struct,需要实现 Insertable,未列出的字段插入缺省值;也可以传入 AsChangeset;
- update 的 set() 时传入的 struct, 以及 delete() 传入的 struct,需要实现 Identifiable ,只会 update 这个 struct 中列出的字段;
对于 struct model:
- Struct 默认都是
NOT NULL字段; - 如果数据库字段有
DEFAULT值,则需要使用Option<T>类型,当传入 None 时使用 T 的缺省值; - 如果数据库字段有
DEFAULT值,且是可以为NULL的,需要使用Option<Option<T>>类型;
use diesel::prelude::*;
#[derive(Queryable, Selectable)]
// table_name 是 Selectable 所需要的,默认为 struct 全小写名称加 s。
// check_for_backend 用于编译时静态检查,即检查 struct 成员类型和数据库表定义是否完全一致。
#[diesel(table_name = crate::schema::posts)]
#[diesel(check_for_backend(diesel::pg::Pg))]
pub struct Post {
pub id: i32, // 默认表的 PK 是 id 字段。
pub title: String,
pub body: String,
pub published: bool,
}
// 用于 diesel::insert_into(table).values() 的参数,需要实现 Insertable,
// 如果使用 &str, 则需要为 struct 指定 lifetime
#[derive(Insertable)]
#[diesel(table_name = posts)]
pub struct NewPost<'a> {
pub title: &'a str,
pub body: &'a str,
}
let new_post = NewPost { title, body };
diesel::insert_into(posts::table)
.values(&new_post)
.returning(Post::as_returning()) // Selectable 可以作为 returning() 的参数
.get_result(conn)
.expect("Error saving new post");
let post = posts
.find(post_id)
.select(Post::as_select()) // Selectable 也可以作为 select() 的参数
.first(connection)
.optional(); // This allows for returning an Option<Post>, otherwise it will throw an error
// 对于有缺省值的列,对应的数据库 schema 定义类似于 `NOT NULL DEFAULT 'Green'`.
#[derive(Insertable)]
#[diesel(table_name = brands)]
struct NewBrand {
color: Option<String>, // Option<T> 表示该字段是可选的,在传入 None 时使用缺省值。
}
let new_brand = NewBrand { color: Some("Red".into()) };
diesel::insert_into(brands)
.values(&new_brand) // values() 的参数值是 Insertable
.execute(connection)
.unwrap();
// Insert the default color
let new_brand = NewBrand { color: None }; // 对于 Option<T> 类型的字段,如果在 insert 时值为 None,则 diesel 插入该字段的缺省值。
diesel::insert_into(brands)
.values(&new_brand)
.execute(connection)
.unwrap();
use schema::{users, posts};
#[derive(Debug, PartialEq, Queryable, Selectable)]
struct User {
id: i32,
name: String,
}
#[derive(Debug, PartialEq, Queryable, Selectable)]
struct Post {
id: i32,
user_id: i32,
title: String,
}
let (first_user, first_post) = users::table
.inner_join(posts::table)
.select(<(User, Post)>::as_select()) // tuple 也实现了 Selectable
.first(connection)?;
#[derive(Debug, PartialEq, Queryable, Selectable)]
struct User {
id: i32,
name: String,
}
#[derive(Debug, PartialEq, Queryable, Selectable)]
#[diesel(table_name = posts)]
struct PostTitle {
title: String,
}
#[derive(Debug, PartialEq, Queryable, Selectable)]
struct UserPost {
#[diesel(embed)]
user: User, // 支持嵌入字段
#[diesel(embed)]
post_title: PostTitle,
}
let first_user_post = users::table
.inner_join(posts::table)
.select(UserPost::as_select())
.first(connection)?;
let expected_user_post = UserPost {
user: User {
id: 1,
name: "Sean".into(),
},
post_title: PostTitle {
title: "My first post".into(),
},
};
assert_eq!(expected_user_post, first_user_post);
// Identifiable 可以作为 update() 的参数, 需要有作为 PK 的 id 字段。
// AsChangeset 可以作为 set() 的参数,
#[derive(Queryable, Identifiable, AsChangeset)]
#[diesel(table_name = posts)]
pub struct Post {
pub id: i64,
pub title: String,
pub body: String,
pub draft: bool,
pub publish_at: SystemTime,
pub visit_count: i32,
}
diesel::update(post) // post 是上面的实现了 Identifiable 的 Post 类型值, 必须要设置 id 字段.
.set(posts::draft.eq(false))
.execute(conn)
update(post)
// 等效于
update(posts.find(post.id))
// 或
update(posts.filter(id.eq(post.id))).
#[derive(Queryable, Identifiable, Selectable, Debug, PartialEq)]
#[diesel(table_name = books)]
pub struct Book {
pub id: i32,
pub title: String,
}
// Associations 关联表
#[derive(Queryable, Selectable, Identifiable, Associations, Debug, PartialEq)]
#[diesel(belongs_to(Book, foreign_key = book_id))] // foreign_key 默认为 {table}_id 字段
#[diesel(table_name = pages)]
pub struct Page {
pub id: i32,
pub page_number: i32,
pub content: String,
pub book_id: i32, // 外键
}
SQL 表名惯例: 小写的复数形式, 用下划线分割: books, authors, books_authros;
对应的 Rust model struct 命名惯例: 大写的单数形式, Book, Author, BookAuthor;
表的主键: id
表的外键: 单数表名_id, 如: book_id, author_id;
QueryDsl #
table!() 宏为表(table)实现了 QueryDsl trait, 故可以在 table 对象上使用 QueryDsl 提供的各种方法(Query builder methods)来查询数据。
这些方法的参数可以是 Rust 基本类型、table!() 宏生成的表字段类型(它们实现了 Expression),以及 expression methods 方法返回值。
// Trait diesel::query_dsl::QueryDsl
pub trait QueryDsl: Sized {
// 唯一性
fn distinct(self) -> Distinct<Self> where Self: DistinctDsl
fn distinct_on<Expr>(self, expr: Expr) -> DistinctOn<Self, Expr> where Self: DistinctOnDsl<Expr>
// 指定查询返回的字段,可以被转换为 Queryable 或 Selectable struct
fn select<Selection>(self, selection: Selection) -> Select<Self, Selection where Selection: Expression, Self: SelectDsl<Selection>
// 计数
fn count(self) -> Select<Self, CountStar> where Self: SelectDsl<CountStar>
// join 查询
fn inner_join<Rhs>(self, rhs: Rhs) -> InnerJoin<Self, Rhs>
fn left_outer_join<Rhs>(self, rhs: Rhs) -> LeftJoin<Self, Rhs>
fn left_join<Rhs>(self, rhs: Rhs) -> LeftJoin<Self, Rhs>
// 过滤,泛型参数 Predicte 类型由 FilterDsl 来限制
fn filter<Predicate>(self, predicate: Predicate) -> Filter<Self, Predicate> where Self: FilterDsl<Predicate>
fn or_filter<Predicate>( self, predicate: Predicate, ) -> OrFilter<Self, Predicate> where Self: OrFilterDsl<Predicate>
// 使用主键值查找一条记录
fn find<PK>(self, id: PK) -> Find<Self, PK> where Self: FindDsl<PK>
// 排序字段
fn order<Expr>(self, expr: Expr) -> Order<Self, Expr> where Expr: Expression, Self: OrderDsl<Expr>
fn order_by<Expr>(self, expr: Expr) -> OrderBy<Self, Expr> where Expr: Expression, Self: OrderDsl<Expr>
fn then_order_by<Order>(self, order: Order) -> ThenOrderBy<Self, Order> where Self: ThenOrderDsl<Order>
// 限制返回条数
fn limit(self, limit: i64) -> Limit<Self> where Self: LimitDsl
fn offset(self, offset: i64) -> Offset<Self> where Self: OffsetDsl
// 聚合
fn group_by<GB>(self, group_by: GB) -> GroupBy<Self, GB> where GB: Expression, Self: GroupByDsl<GB>
// 聚合过滤
fn having<Predicate>(self, predicate: Predicate) -> Having<Self, Predicate> where Self: HavingDsl<Predicate>
fn for_update(self) -> ForUpdate<Self> where Self: LockingDsl<ForUpdate>
fn for_no_key_update(self) -> ForNoKeyUpdate<Self> where Self: LockingDsl<ForNoKeyUpdate>
fn for_share(self) -> ForShare<Self> where Self: LockingDsl<ForShare>
fn for_key_share(self) -> ForKeyShare<Self> where Self: LockingDsl<ForKeyShare>
fn skip_locked(self) -> SkipLocked<Self> where Self: ModifyLockDsl<SkipLocked>
fn no_wait(self) -> NoWait<Self> where Self: ModifyLockDsl<NoWait>
fn into_boxed<'a, DB>(self) -> IntoBoxed<'a, Self, DB> where DB: Backend, Self: BoxedDsl<'a, DB>
fn single_value(self) -> SingleValue<Self> where Self: SingleValueDsl
fn nullable(self) -> NullableSelect<Self> where Self: SelectNullableDsl
}
// Table 和 SelectStatement 都实现了 QueryDsl
impl<'a, ST, QS, DB, GB> QueryDsl for BoxedSelectStatement<'a, ST, QS, DB, GB>
impl<F, S, D, W, O, LOf, G, H, LC> QueryDsl for SelectStatement<F, S, D, W, O, LOf, G, H, LC>
impl<S: AliasSource> QueryDsl for Alias<S>
impl<T: Table> QueryDsl for T // Table 实现了 QueryDsl
以 select<Selection>() 泛型方法为例:table 实现了 QueryDsl 和 SelectDsl,故可以调用该方法,返回的 Select 其实是 Struct SelectStatement 类型:
// 分析 select():
pub trait QueryDsl: Sized {
// ...
fn select<Selection>(self, selection: Selection) -> Select<Self, Selection> where Selection: Expression, Self: SelectDsl<Selection> { ... }
// ..
}
// Select 是 SelectDsl 的 Output 类型
pub type Select<Source, Selection> = <Source as SelectDsl<Selection>>::Output;
// SelectDsl trait 定义
pub trait SelectDsl<Selection: Expression> {
type Output;
// Required method
fn select(self, selection: Selection) -> Self::Output;
}
// table 实现了 SelectDsl:https://docs.diesel.rs/2.2.x/src/diesel/query_dsl/select_dsl.rs.html#22-33
impl<T, Selection> SelectDsl<Selection> for T where Selection: Expression, T: Table, T::Query: SelectDsl<Selection>,
{
type Output = <T::Query as SelectDsl<Selection>>::Output;
fn select(self, selection: Selection) -> Self::Output {
// 返回的是 Table 实现的 AsQuery trait 对象的 select() 方法返回值类型,实际是 SelectStatement 类型
self.as_query().select(selection)
}
}
// table!() 宏展开后,为 table 实现 AsQuery trait,as_query() 返回的 Self::Query 类型是 SelectStatement struct 类型
impl diesel::query_builder::AsQuery for table {
type SqlType = SqlType;
type Query = diesel::internal::table_macro::SelectStatement<diesel::internal::table_macro::FromClause<Self>> ;
fn as_query(self) -> Self::Query {
diesel::internal::table_macro::SelectStatement::simple(self)
}
}
distinct() 返回类型其实还是 Struct SelectStatement 类型:
pub trait QueryDsl: Sized {
fn distinct(self) -> Distinct<Self> where Self: DistinctDsl
// ...
}
// Distinct<Self> 是 DistinctDsl::Output 类型
pub type Distinct<Source> = <Source as DistinctDsl>::Output;
pub trait DistinctDsl {
/// The type returned by `.distinct`
type Output;
/// See the trait documentation.
fn distinct(self) -> dsl::Distinct<Self>;
}
// table 实现的 DistinctDsl 的 Output 类型是 SelectStatement 类型
// https://docs.diesel.rs/2.2.x/src/diesel/query_dsl/distinct_dsl.rs.html#26
impl<T> DistinctDsl for T
where
T: Table + AsQuery<Query = SelectStatement<FromClause<T>>>,
T::DefaultSelection: Expression<SqlType = T::SqlType> + ValidGrouping<()>,
T::SqlType: TypedExpressionType,
{
type Output = dsl::Distinct<SelectStatement<FromClause<T>>>;
fn distinct(self) -> dsl::Distinct<SelectStatement<FromClause<T>>> {
self.as_query().distinct()
}
}
https://img.opsnull.com/blog/20251126195931977.png
其它 QueryDsl 方法返回值类型也都类似,最终都是 SelectStatement 类型,所以:
- 这些
QueryDsl的方法可以链式调用; - 由于
SelectStatement又实现了Expression,所以方法调用结果也可以作为QueryDsl方法的参数。
diesel 查询的结果用 tuple 表示,可以通过 select() 来指定查询返回的字段 tuple,如果未调用该方法,则默认返回表的所有字段 tuple(由 table!() 宏自动为表生成的 all_columns 常量)。diesele 自动将该 tuple 转换为 Queryable 或 Selectable struct(前者不需要和表字段一一对应,但是后者和表字段&顺序一一对应)。这种转换是根据 tuple 和 struct 的字段顺序,而非名称或类型,来一一映射的。
// table users 实现了 QueryDsl,各方法返回的对象实现了 SelectStatement,而 SelectStatement 又实现了 QueryDsl trait, 故可以链式调用
let complex_query = users
.filter(name.like("%Doe%")) // 参数是 Expression,可以是 table!() 宏生成的表字段,以及对齐应用 expression methods 的结果。
.filter(age.between(18, 30))
.order(age.desc())
.limit(5)
.load<User>(&connection)?; // 查询结果本质为 tuple,这里由于没有调用 select(),所以返回所有字段的 tuple,进而可以转换为 Selecable User
let data = users::table
.inner_join(posts::table)
.select((users::name, posts::title))
.filter(posts::published.eq(true))
.load<(&str, &str)>(&connection)?; // 通过 select() 设置查询结果为 tuple,这里返回该 tuple 类型,还可以被自动转换为对应 Queryable struct
// https://docs.diesel.rs/main/diesel/deserialize/trait.Queryable.html#single-field
table! {
animals {
id -> Integer,
species -> VarChar,
legs -> Integer,
name -> Nullable<VarChar>,
}
}
// Queryable 对应表的部分字段
#[derive(Queryable, PartialEq, Debug)]
struct Animal {
id: i32,
name: Option<String>, // Nullable 字段对应 Option
}
// 将 select() 返回的表部分字段转换为 Queryable struct
let all_animals = animals.select((id, name)).order_by(id).load(connection)?;
let expected = vec![
Animal {
id: 1,
name: Some("Jack".to_owned()),
},
Animal { id: 2, name: None },
];
assert_eq!(expected, all_animals);
query_dsl::methods #
QueryDsl 的各方法是由 diesel::query_dsl::methods module 下的各种 xxDSL trait 定义的,如 DistinctDsl 定义了 distinct() 方法。
Struct SelectStatement 实现了这些 xxDSL,故可以链式调用。
- BoxedDsl: The into_boxed method
- DistinctDsl: The distinct method
- DistinctOnDsl: The distinct_on method
- ExecuteDsl: The execute method
- FilterDsl: The filter method
- FindDsl: The find method
- GroupByDsl: The group_by method
- HavingDsl: The having method
- JoinOnDsl: The on method
- LimitDsl: The limit method
- LoadQuery: The load method
- LockingDsl: Methods related to locking select statements
- ModifyLockDsl: Methods related to modifiers on locking select statements
- OffsetDsl: The offset method
- OrFilterDsl: The or_filter method
- OrderDsl: The order method
- SelectDsl: The
selectmethod, 指定要返回的字段 tuple 或实现 Selectable 的 struct - SelectNullableDsl: The nullable method
- SingleValueDsl: The single_value method
- ThenOrderDsl: The then_order_by method
// table users 实现了 QueryDsl,各方法返回的对象实现了 SelectStatement,而 SelectStatement 又实现了 QueryDsl trait, 故可以链式调用
let complex_query = users
.filter(name.like("%Doe%")) // 参数是 Expression,可以是 table!() 宏生成的表字段,以及对齐应用 expression methods 的结果。
.filter(age.between(18, 30))
.order(age.desc())
.limit(5)
.load<User>(&connection)?; // 查询结果本质为 tuple,这里由于没有调用 select(),所以返回所有字段的 tuple,进而可以转换为 Selecable User
let data = users::table
.inner_join(posts::table)
.select((users::name, posts::title))
.filter(posts::published.eq(true))
.load<(&str, &str)>(&connection)?; // 通过 select() 设置查询结果为 tuple,这里返回该 tuple 类型,还可以被自动转换为对应 Queryable struct
对于 filter()/having() 方法,泛型参数 Predict 的类型:
-
对于 SelectStatement 实现的 FilterDSL 的 Predicate 需要实现 Expression,而且返回值类型是 BoolOrNullableBool;
Eq/NotEq/EqAny/Gt/GtEq/Lt/LtEq/NotEq/NotLike/Between/NeAny/Bool/Nullable<bool>实现BoolExpressionMethods,见前文的分析。
-
对于 DeleteStatement、UpdateStatement 实现的 FilterDSL 的 Predicate 需要实现
AppearsOnTable,它用于约束传入的字段必须是表的字段之一,防止传入非法的字段;
table!() 为每个表字段实现了 Expression trait 和 AppearsOnTable trait,故表字段类型可以用于这些方法的参数:
fn filter<Predicate>(self, predicate: Predicate) -> Filter<Self, Predicate> where Self: FilterDsl<Predicate>
// 聚合过滤
fn having<Predicate>(self, predicate: Predicate) -> Having<Self, Predicate> where Self: HavingDsl<Predicate>
pub trait FilterDsl<Predicate> {
type Output;
// Required method
fn filter(self, predicate: Predicate) -> Self::Output;
}
// SelectStatement 实现的 FilterDsl 的 Predicate 需要是 Expression,而且结果是 BoolOrNullableBool
impl<F, S, D, W, O, LOf, G, H, LC, Predicate> FilterDsl<Predicate> for SelectStatement<F, S, D, W, O, LOf, G, H, LC>
where
Predicate: Expression + NonAggregate,
Predicate::SqlType: BoolOrNullableBool,
W: WhereAnd<Predicate>,
type Output = SelectStatement<F, S, D, <W as WhereAnd<Predicate>>::Output, O, LOf, G, H, LC>
impl<T, U, Ret, Predicate> FilterDsl<Predicate> for DeleteStatement<T, U, Ret>
where
U: WhereAnd<Predicate>,
Predicate: AppearsOnTable<T>,
T: QuerySource,
type Output = DeleteStatement<T, <U as WhereAnd<Predicate>>::Output, Ret>
impl<T, U, V, Ret, Predicate> FilterDsl<Predicate> for UpdateStatement<T, U, V, Ret>
where
T: QuerySource,
U: WhereAnd<Predicate>,
Predicate: AppearsOnTable<T>,
type Output = UpdateStatement<T, <U as WhereAnd<Predicate>>::Output, V, Ret>
// SelectStatement 的 filter 方法需要实现 Expression, table!() 为每个表字段实现了 Expression 和 AppearsOnTable trait;
let complex_query = users
.filter(name.like("%Doe%"))
.filter(age.between(18, 30))
.order(age.desc())
.limit(5)
.load<User>(&connection)?;
// DeleteStatement 的 filter 方法需要实现 AppearsOnTable, table!() 为每个表字段实现了 Expression 和 AppearsOnTable trait;
let deleted_rows = diesel::delete(users) // 传入实现 IntoUpdateTarget 的 table
.filter(name.eq("Sean")) // filter() 的参数必须实现 AppearsOnTable,也即传入的 name 必须是 users 表的合法字段。
.execute(connection);
assert_eq!(Ok(1), deleted_rows);
SelectStatement 和 select() #
QueryDsl 和 SelectDsl 的 select<Selection>(selection: Selection) 泛型方法返回的是 Struct SelectStatement 类型。
而 SelectStatement 实现的 SelectDsl<Selection> trait 的 Selection 限界是 SelectableExpression:
impl<S, D, W, O, LOf, G, H, LC, Selection> SelectDsl<Selection> for SelectStatement<NoFromClause, S, D, W, O, LOf, G, H, LC>
where
G: ValidGroupByClause,
Selection: SelectableExpression<NoFromClause> + ValidGrouping<G::Expressions>,
SelectStatement<NoFromClause, SelectClause<Selection>, D, W, O, LOf, G, H, LC>: SelectQuery,
D: ValidDistinctForGroupBy<Selection, G::Expressions>,
type Output = SelectStatement<NoFromClause, SelectClause<Selection>, D, W, O, LOf, G, H, LC>
fn select(self, selection: Selection) -> Self::Output
diesel 为如下类型实现了 SelectableExpression(T 需要实现 SelectableExpression)
- &T
- Box
- (T, T1..T30) 《== 关键!
pub trait SelectableExpression<QS: ?Sized>: AppearsOnTable<QS> { }
impl<'a, T, QS> SelectableExpression<QS> for &'a T where T: SelectableExpression<QS> + ?Sized, &'a T: AppearsOnTable<QS>
impl<T, QS> SelectableExpression<QS> for Box<T> where T: SelectableExpression<QS> + ?Sized, Box<T>: AppearsOnTable<QS>
// tuple 组合,T1..T30
impl<T, T1, QS> SelectableExpression<QS> for (T, T1) where T: SelectableExpression<QS>, T1: SelectableExpression<QS>, (T, T1): AppearsOnTable<QS>
table!() 宏为各表字段实现了 SelectableExpression,所以 表字段的 tuple 组合也实现了 SelectableExpression:
impl diesel::SelectableExpression<super::table>for id {}
通过 #[derive(Selectable)] 宏修饰的 struct 类型,实现了 Selectable 和 SelectableHelper trait,它的 as_select() 方法返回值类型 SelectBy 也实现了该 SelectableExpression:
#[derive(Selectable)]
struct User {
id: i32,
name: String,
}
// 等效于为 User 实现 Selectable,其中 SelectExpression = (users::r#id, users::r#name); 所以,这个 tuple 也实现了 SelectableExpression
const _: () = {
use diesel;
use diesel::expression::Selectable;
impl<__DB: diesel::backend::Backend> Selectable<__DB> for User {
type SelectExpression = (users::r#id, users::r#name);
fn construct_selection() -> Self::SelectExpression {
(users::r#id, users::r#name)
}
}
};
// diesel 为 Selectable 实现了 SelectableHelper
pub trait SelectableHelper<DB: Backend>: Selectable<DB> + Sized {
// Required method
fn as_select() -> AsSelect<Self, DB>;
// Provided method
fn as_returning() -> AsSelect<Self, DB> { ... }
}
impl<T, DB> SelectableHelper<DB> for T where T: Selectable<DB>, DB: Backend,
// as_select()/as_returning() 返回的 AsSelect 实现了 SelectableExpression,对应值其实是 tuple (users::r#id, users::r#name);
/// Represents the return type of [`.as_select()`](crate::prelude::SelectableHelper::as_select)
pub type AsSelect<Source, DB> = SelectBy<Source, DB>;
// https://docs.diesel.rs/main/src/diesel/expression/select_by.rs.html#110
impl<T, QS, DB> SelectableExpression<QS> for SelectBy<T, DB>
where
DB: Backend,
T: Selectable<DB>,
T::SelectExpression: SelectableExpression<QS>,
Self: AppearsOnTable<QS>,
综上,select<Selection>(selection: Selection) 的 Selection 需要是实现 SelectableExpression 的类型,包括如下情况:
table!()为所有表字段实现了SelectableExpression;- 实现
SelectableExpression的tuple、Box<T>, &T类型,也实现了SelectableExpression; #[derive(Selectable)]宏修饰的 struct 类型的as_select()方法返回值类型SelectBy也实现了该SelectableExpression;
diesel 的 select/insert/update 语句本质上通过 select()/returning() 返回实现 SelectableExpression 的 tuple,然后自动转换为对应的 Queryable/Selectable 类型。
示例:
let mut query = posts::table
.order(posts::published_at.desc())
.filter(posts::published_at.is_not_null())
.inner_join(users::table)
// posts::all_columns 是 table!() 自动生成的,包含所有列的 tuple,它实现了 SelectableExpression
.select((posts::all_columns, (users::id, users::username))) // 整个 tuple 实现了 SelectableExpression
.paginate(page);
// Queryable 类型的值可以由 tuple 转换而来
#[derive(Queryable, Identifiable, Debug, PartialEq, Eq)]
pub struct User {
pub id: i32,
pub username: String,
}
fn register_user(conn: &mut PgConnection, username: &str, password: &str, ) -> Result<User, AuthenticationError> {
let salt = SaltString::from_b64(SALT_STRING)?;
let argon2 = Argon2::default();
let hashed_password = argon2
.hash_password(password.as_bytes(), &salt)?
.to_string();
insert_into(users::table)
.values((
users::username.eq(username),
users::hashed_password.eq(hashed_password),
))
.returning((users::id, users::username)) // 返回一个 tuple
.get_result(conn) // 返回 (i32, String) 类型,被自动转换为实现 Queryable 的 User 类型
.map_err(AuthenticationError::DatabaseError)
}
// https://github.com/diesel-rs/diesel/blob/2.2.x/examples/postgres/advanced-blog-cli/src/auth.rs
#[derive(Queryable, Identifiable, Debug, PartialEq, Eq)]
pub struct User {
pub id: i32,
pub username: String,
}
#[derive(Queryable)]
pub struct UserWithPassword {
user: User, // 嵌入式字段
password: String,
}
fn find_user(conn: &mut PgConnection, username: &str, password: &str,) -> Result<Option<User>, AuthenticationError> {
let user_and_password = users::table
.filter(users::username.eq(username))
// 返回一个 tuple,其中第一个元素为 tuple,展开后与 UserWithPassword 一一对应,所以可以自动转换为 UserWithPassword
.select(((users::id, users::username), users::hashed_password))
.first::<UserWithPassword>(conn)
.optional()
.map_err(AuthenticationError::DatabaseError)?;
if let Some(user_and_password) = user_and_password {
let parsed_hash = PasswordHash::new(&user_and_password.password)?;
Argon2::default()
.verify_password(password.as_bytes(), &parsed_hash)
.map_err(|e| match e {
argon2::password_hash::Error::Password => IncorrectPassword,
_ => AuthenticationError::Argon2Error(e),
})?;
Ok(Some(user_and_password.user))
} else {
Ok(None)
}
}
Selectable/SelectableHelper #
derive 宏 Selectable 实现了 SelectableHelper trait, 该 trait 提供了 as_returning() 和 as_select() 方法,这两个方法返回的 AsSelect(SelectBy 的别名)实现了 SelectableExpression trait。
as_returning()方法:用作DeleteStatement/SelectStatement/UpdateStatement的retuning()方法的参数, 指定返回值类型(见后文);as_select()方法:用作SelectStatement的select()方法(QueryDsl 的各方法,如 select/find/filter 等均返回 SelectStatement)的参数, 指定返回值类型;
Selectable 宏修饰的 struct 必须和 table 字段名称和顺序一致,可以使用 #[diesel(table_name)] 和 #[diesel(check_for_backend()] 来开启编译时静态检查。
- 但是 Queryable 宏修饰的 struct 可以和 table 不完全一致,只需要和 select()/returning() 指定的字段(一般为 tuple)一致即可。
如果在 select() 中使用 Selectable struct,则必须调用它的 as_select() 方法返回值对象。如果在 returing() 中使用 Selectable struct,则必须调用它的 as_returning() 方法返回值对象。
- 但是 select() 和 returing() 还可以传入 tuple,而不是 Selectable, 这时不能调用
as_select()/as_returning()方法。
let user_and_password = users::table
.filter(users::username.eq(username))
// 返回一个 tuple,其中第一个元素为 tuple,展开后与 UserWithPassword 一一对应,所以可以自动转换为 UserWithPassword
.select(((users::id, users::username), users::hashed_password)) // tuple 不需要调用 `as_select()`/`as_returning()` 方法
.first::<UserWithPassword>(conn)
.optional()
.map_err(AuthenticationError::DatabaseError)?;
// https://docs.diesel.rs/main/diesel/expression/derive.Selectable.html
#[derive(Queryable, Selectable)]
// table_name 是 Selectable 所需要的,默认为 struct 全小写名称加 s。
// check_for_backend 用于编译时静态检查,即检查 struct 成员类型和数据库表定义是否完全一致。
#[diesel(table_name = crate::schema::posts)]
#[diesel(check_for_backend(diesel::pg::Pg))]
pub struct Post {
pub id: i32, // 默认表的 PK 是 id 字段。
pub title: String,
pub body: String,
pub published: bool,
}
// update/insert_into 使用 returning() 来指定返回值列,它依赖数据库的 `RETURNING clause` 能力
let new_post = NewPost { title, body };
diesel::insert_into(posts::table)
.values(&new_post)
.returning(Post::as_returning()) // Selectable 可以作为 returning() 的参数
.get_result(conn)
.expect("Error saving new post");
// QueryDsl 的 select/find/inner_join 等使用 select() 来指定返回值类型
let post = posts
.find(post_id)
.select(Post::as_select()) // Selectable 可以作为 select() 的参数
.first(connection)
.optional(); // This allows for returning an Option<Post>, otherwise it will throw an error
let data = users::table
.inner_join(posts::table)
.select((users::name, posts::title))
.filter(posts::published.eq(true))
.load<(&str, &str)>(&connection)?; // RunQueryDsl 的返回值类型需要与 select() 的参数类型匹配
如果 struct A 和 B 都实现了 Selectable,则它们的 tuple 类型 (A, B) 也实现了 SelectableHelper,可以调用它们的 as_select() 方法的返回值作为 select() 的参数:
use schema::{users, posts};
#[derive(Debug, PartialEq, Queryable, Selectable)]
struct User {
id: i32,
name: String,
}
#[derive(Debug, PartialEq, Queryable, Selectable)]
struct Post {
id: i32,
user_id: i32,
title: String,
}
let (first_user, first_post) = users::table
.inner_join(posts::table)
.select(<(User, Post)>::as_select())
.first(connection)?;
let expected_user = User { id: 1, name: "Sean".into() };
assert_eq!(expected_user, first_user);
let expected_post = Post { id: 1, user_id: 1, title: "My first post".into() };
assert_eq!(expected_post, first_post);
Queryable 的 struct 可以匹配部分 table field,但是 Selectable 需要严格完整匹配:
use schema::{users, posts};
#[derive(Debug, PartialEq, Queryable, Selectable)]
struct User {
id: i32,
name: String,
}
#[derive(Debug, PartialEq, Queryable, Selectable)]
#[diesel(table_name = posts)]
struct PostTitle {
title: String, // posts 表的部分字段,但是没有开启 #[diesel(check_for_backend()] 检查,所以 Selectable 不会报错
}
let (first_user, first_post_title) = users::table
.inner_join(posts::table)
.select(<(User, PostTitle)>::as_select())
.first(connection)?;
let expected_user = User { id: 1, name: "Sean".into() };
assert_eq!(expected_user, first_user);
let expected_post_title = PostTitle { title: "My first post".into() };
assert_eq!(expected_post_title, first_post_title);
在 Selectable 内部,可以使用 #[diesel(embed)] 来嵌入 struct:
- 但是在 Queryable 内部,也可以嵌入 struct,但是不需要使用
#[diesel(embed)]修饰。
use schema::{users, posts};
#[derive(Debug, PartialEq, Queryable, Selectable)]
struct User {
id: i32,
name: String,
}
#[derive(Debug, PartialEq, Queryable, Selectable)]
#[diesel(table_name = posts)]
struct PostTitle {
title: String,
}
#[derive(Debug, PartialEq, Queryable, Selectable)]
struct UserPost {
#[diesel(embed)]
user: User,
#[diesel(embed)]
post_title: PostTitle,
}
let first_user_post = users::table
.inner_join(posts::table)
.select(UserPost::as_select())
.first(connection)?;
let expected_user_post = UserPost {
user: User {
id: 1,
name: "Sean".into(),
},
post_title: PostTitle {
title: "My first post".into(),
},
};
assert_eq!(expected_user_post, first_user_post);
通过使用 #[diesel(select_expression)], #[diesel(select_expression_type)] 和 #[dsl::auto_type] 宏,可以为自定义 struct 灵活指定查询规则:
- 一般用于多表 join,确定结果 struct 字段来源于那个表的字段;
- select_expression、select_expression_type 用于指定来源的表字段;
use schema::{users, posts};
use diesel::dsl;
#[derive(Debug, PartialEq, Queryable, Selectable)]
struct User {
id: i32,
name: String,
}
#[derive(Debug, PartialEq, Queryable, Selectable)]
#[diesel(table_name = posts)]
struct PostTitle {
title: String,
}
#[derive(Debug, PartialEq, Queryable, Selectable)]
struct UserPost {
#[diesel(select_expression = users::columns::id)]
#[diesel(select_expression_type = users::columns::id)]
id: i32, // 该字段由 users 表的 id 字段赋值
#[diesel(select_expression = users::columns::name)]
name: String,
#[diesel(select_expression = complex_fragment_for_title())]
title: String,
#[diesel(select_expression = diesel::dsl::now)]
access_time: chrono::NaiveDateTime,
#[diesel(select_expression = users::columns::id.eq({let id: i32 = FOO; id}))]
user_id_is_foo: bool,
}
const FOO: i32 = 42;
#[dsl::auto_type]
fn complex_fragment_for_title() -> _ {
// See the `#[dsl::auto_type]` documentation for examples of more complex usage
posts::columns::title
}
let first_user_post = users::table
.inner_join(posts::table)
.select(UserPost::as_select())
.first(connection)?;
let expected_user_post = UserPost {
id: 1,
name: "Sean".into(),
title: "My first post".into(),
access_time: first_user_post.access_time,
user_id_is_foo: false,
};
assert_eq!(expected_user_post, first_user_post);
returning() #
QueryDsl 各方法,如 find/filter/inner_join() 的返回值是 SelectStatement 类型,它实现了 SelectDsl,故可以使用 select() 来指定返回值类型。
但 DeleteStatement/UpdateStatement 并没有实现 SelectDsl,对于这两种语句,需要使用 returning() 来指定返回值类型。
select()/returning() 的参数类型相同,都是 SelectableExpression(见前文):
// DeleteStatement 提供的 returning 的方法的泛型参数 E 需要实现 SelectableExpression
impl<T: QuerySource, U> DeleteStatement<T, U, NoReturningClause>
pub fn returning<E>(
self,
returns: E,
) -> DeleteStatement<T, U, ReturningClause<E>>
where
E: SelectableExpression<T>,
DeleteStatement<T, U, ReturningClause<E>>: Query,
// 示例
let deleted_name = diesel::delete(users.filter(name.eq("Sean")))
.returning(name)
.get_result(connection); // 对于返回单个类型,不需要为 get_result() 指定类型
assert_eq!(Ok("Sean".to_string()), deleted_name);
get_result/get_results() 和 Queryable #
对于支持 RETURNING clause 的数据库, 如 PostgreSQL 和 SQLite, 可以调用 get_result()/get_results() 来获取 insert/update 的记录:
- 对于 select() 语句,本来就返回记录,所以不依赖于
RETURNING clause的get_result()/get_results(),而是使用first()/load()/load_iter()来返回结果。
let first_user: User = users.order_by(id).first(connection)?; // 查询语句,使用 first() 来返回一条记录
let inserted_users = insert_into(users)
.values(&vec![
(id.eq(1), name.eq("Sean")),
(id.eq(2), name.eq("Tess")),
])
.get_results(conn)?; // 没有调用 returning() ,默认返回所有列。
// 等效于:
// INSERT INTO "users" ("id", "name") VALUES ($1, $2), ($3, $4)
// RETURNING "users"."id", "users"."name", "users"."hair_color",
// "users"."created_at", "users"."updated_at"
// -- binds: [1, "Sean", 2, "Tess"]
let expected_users = vec![
User {
id: 1,
name: "Sean".into(),
hair_color: None,
created_at: now,
updated_at: now,
},
User {
id: 2,
name: "Tess".into(),
hair_color: None,
created_at: now,
updated_at: now,
},
];
assert_eq!(expected_users, inserted_users);
get_result/get_results() 默认然会所有列, 但可以和 returning() 联用,来指定要返回的列:
returning()返回一个类型时, get_result() 不需要指定泛型类型;returning()返回一个 tuple 类型时,get_result() 需要指定对应的 Rust tuple 类型;
use schema::users::dsl::*;
insert_into(users)
.values(name.eq("Ruby"))
.returning(id)
.get_result(conn)
// 等效于:
// INSERT INTO "users" ("name") VALUES ($1)
// RETURNING "users"."id"
// -- binds: ["Ruby"]
// returning Selectable struct
let deleted_name = diesel::delete(users.filter(name.eq("Sean")))
// users table 的 name 字段类型实现了 SelectableExpression,如果要返回多个字段,则需要使用
// tuple 类型。然后在 get_result::<(Type1, Type2)>(connection) 中指定返回值类型。
.returning(name)
.get_result(connection);
assert_eq!(Ok("Sean".to_string()), deleted_name);
// returning() 的参数也可以是 tuple
let inserted_user = insert_into(users)
.values(new_users)
.returning((name, hair_color))
.get_result::<(String, Option<String>)>(connection)
.unwrap();
let expected_user = ("Sean".to_string(), Some("Black".to_string()));
Queryable #
get_result/get_results()/first() 可以使用 Queryable 来指定返回值类型:
pub trait Queryable<ST, DB>: Sized where DB: Backend
type Row: FromStaticSqlRow<ST, DB>;
// Required method
fn build(row: Self::Row) -> Result<Self>;
}
Diesel 使用 tuple 来表示一个 SQL 查询,Queryable 可用于将这个 tuple 反序列化为对应的 struct。
Queryable 代表一个 SQL 查询结果,与 Selectable 相比,Queryable 不一定代表一个数据库表或表的全部字段,可以只指定部分表格字段(一般用 select()/returning() 方法的 tuple 参数)。
- 但是 tuple 参数的字段顺序和类型必须和对应的 Queryable 一致。
使用 #[derive(Queryable)] 宏来实现 Queryable:
// https://docs.diesel.rs/main/diesel/deserialize/trait.Queryable.html#single-field
table! {
animals {
id -> Integer,
species -> VarChar,
legs -> Integer,
name -> Nullable<VarChar>,
}
}
// Queryable 对应表的部分字段
#[derive(Queryable, PartialEq, Debug)]
struct Animal {
id: i32,
name: Option<String>, // Nullable 字段对应 Option
}
// 将 select() 返回的表部分字段转换为 Queryable struct
let all_animals = animals.select((id, name)).order_by(id).load(connection)?;
let expected = vec![
Animal {
id: 1,
name: Some("Jack".to_owned()),
},
Animal { id: 2, name: None },
];
assert_eq!(expected, all_animals);
Queryable 还可以用于自定义类型的字段:
// https://docs.diesel.rs/main/diesel/deserialize/trait.Queryable.html#multiple-fields
#[derive(Queryable, PartialEq, Debug)]
struct UserWithPost {
id: i32,
post: Option<Post>, // 使用自定义类型 Post,注意这里不能使用 Selectable 专用的 #[diesel(embed)]
}
#[derive(Queryable, PartialEq, Debug)]
struct Post {
id: i32,
title: String,
}
let all_posts = users::table
.left_join(posts::table)
// 嵌套 tuple 转换为 Queryable struct 类型,注意使用 .nullable() 方法返回 Option
.select((users::id, (posts::id, posts::title).nullable()))
.order_by((users::id, posts::id))
.load(connection)?;
let expected = vec![
UserWithPost {
id: 1,
post: Some(Post {
id: 1,
title: "My first post".to_owned(),
}),
},
UserWithPost {
id: 1,
post: Some(Post {
id: 2,
title: "About Rust".to_owned(),
}),
},
UserWithPost {
id: 2,
post: Some(Post {
id: 3,
title: "My first post too".to_owned(),
}),
},
UserWithPost { id: 3, post: None },
];
assert_eq!(expected, all_posts);
diesel 为 Selectable 通过 #[derive(Selectable)] + #[diesel(check_for_backend(YourBackendType))] 实现了编译时字段检查,但是 Queryable 不支持该特性。
所以在遇到 Queryable 相关的错误时,可以转换为 Selectable 类型,从而让编译器报错更准确和容易排查。
RunQueryDsl #
Trait diesel::prelude::RunQueryDsl 根据传入的 Connection 执行实际的 SQL 操作:
execute():返回实际影响的条数 usize;load()/load_iter()/get_result/get_results()/first()返回插入/更新后的值类型<U>:get_result()返回 0 个记录时出错。如果要返回 0 或 1 个记录需要使用get_result(...).optional();first()返回一个结果记录;
SelectStatement/SqlQuery/Alias/SqlLiteral/Table/DeleteStatement/InsertStatement/UpdateStatement 均实现了 RunQueryDsl,用于执行实际的 SQL 操作。
- 对于 QueryDsl,如果没有调用 select(),则返回所有字段。
- 对于
get_result()/get_results(),如果前序没有调用returning()则返回表所有字段。
对于支持 RETURNING clause 的数据库, 如 PostgreSQL 和 SQLite, 可以调用 get_result()/get_results() 来获取 insert/update 的记录:
- 对于 select() 语句,本来就返回记录,所以不依赖于
RETURNING clause的get_result()/get_results(),而是使用first()/load()/load_iter()来返回结果。
pub trait RunQueryDsl<Conn>: Sized {
// 返回受影响的记录数量
fn execute(self, conn: &mut Conn) -> QueryResult<usize> where Conn: Connection, Self: ExecuteDsl<Conn>
// 返回多条记录的 Vec
fn load<'query, U>(self, conn: &mut Conn) -> QueryResult<Vec<U>> where Self: LoadQuery<'query, Conn, U>
// 返回多条记录的迭代器
fn load_iter<'conn, 'query: 'conn, U, B>( self, conn: &'conn mut Conn, ) -> QueryResult<Self::RowIter<'conn>> where U: 'conn, Self: LoadQuery<'query, Conn, U, B> + 'conn
// 返回单条记录
fn get_result<'query, U>(self, conn: &mut Conn) -> QueryResult<U> where Self: LoadQuery<'query, Conn, U>
// 返回多条记录的 Vec, 和 load() 行为一致
fn get_results<'query, U>(self, conn: &mut Conn) -> QueryResult<Vec<U>> where Self: LoadQuery<'query, Conn, U>
// 返回单条记录
fn first<'query, U>(self, conn: &mut Conn) -> QueryResult<U> where Self: LimitDsl, Limit<Self>: LoadQuery<'query, Conn, U> { ... }
}
get_result()/get_results()/first() 方法返回结果可以保存到实现了 Selectable/Queryable trait 的 struct 类型,或 table 字段,或 tuple 中:
#[derive(Queryable, PartialEq, Debug)]
struct User {
id: i32,
name: String,
}
let first_user: User = users.order_by(id).first(connection)?;
#[derive(Identifiable, Queryable, Selectable, Clone, Eq, Hash, PartialEq, Serialize, Deserialize, Debug)]
// 编译时检查,确保 struct 成员和数据库中 table 定义顺序一致
#[diesel(table_name = organization)]
#[diesel(check_for_backend(diesel::pg::Pg))]
pub struct Organization {
pub id: Uuid,
pub name: String,
pub created_at: i64,
pub updated_at: Option<i64>,
pub products: Vec<Product>,
}
use schema::{users, posts};
#[derive(Debug, PartialEq, Queryable, Selectable)]
struct User {
id: i32,
name: String,
}
#[derive(Debug, PartialEq, Queryable, Selectable)]
#[diesel(table_name = posts)]
struct PostTitle {
title: String,
}
let (first_user, first_post_title) = users::table
.inner_join(posts::table)
// User 和 PostTitle 实现了 Selectable,它们的 tuple 的 as_select() 返回值实现了 SelectableExpression
.select(<(User, PostTitle)>::as_select())
.first(connection)?;
let expected_user = User { id: 1, name: "Sean".into() };
assert_eq!(expected_user, first_user);
let expected_post_title = PostTitle { title: "My first post".into() };
assert_eq!(expected_post_title, first_post_title);
// load 方法返回多条记录到 Vec<U>
let inserted_posts = posts::table
.select(posts::title)
.load::<String>(conn)?;
let expected = vec!["Sean's First Post", "Tess's First Post"];
assert_eq!(expected, inserted_posts);
// first() 方法返回单条记录
let old_count = users.count().first::<i64>(connection);
如果类型实现了 #[derive(AsChangeset)] 和 #[derive(Identifiable)], 则可以使用该类型的 save_changes() 方法:
foo.save_changes(&conn)
// 等效于
diesel::update(&foo).set(&foo).get_result(&conn).
子查询:
let subquery = users.select(id).filter(name.eq("Alice"));
let posts_by_alice = posts.filter(user_id.eq_any(subquery));
associations/join #
module diesel::associations 提供了表之间 1-N 的关联关系宏和函数。
在 Child struct 上使用 #[derive(Associations)] 和 #[diesel(belongs_to(Parent))] 来定义与 Parent Struct 之间的关联关系:
- 父表和子表都要实现
#[derive(Identifiable)],子表要实现#[derive(Associations)]和添加#[diesel(belongs_to(父表 Struct))宏; #[derive(Associations)]宏为自定义 struct 实现了BelongsTo<Parent>宏,后者提供ForeiginKey信息;Belonging<Parent>实现了BelongingToDsl trait,后者提供了belonging_to()方法;
use schema::{posts, users};
#[derive(Identifiable, Queryable, PartialEq, Debug)]
#[diesel(table_name = users)]
pub struct User {
id: i32,
name: String,
}
#[derive(Identifiable, Queryable, Associations, PartialEq, Debug)]
#[diesel(belongs_to(User))]
#[diesel(table_name = posts)]
pub struct Post {
id: i32,
user_id: i32, // Foreigin Key 惯例: table_name_id
title: String,
}
let user = users.find(2).get_result::<User>(connection)?;
// #[derive(Associations)] 为 Post 实现了 BelongsTo trait,进而实现了 BelongingToDsl trait,所以具有 belonging_to() 方法,
// 而它返回的类型实现了 FilterDsl trait,所以可以继续使用 QueryDsl 的其它方法,如 select()/filter() 等。
let users_post = Post::belonging_to(&user).first(connection)?;
let expected = Post { id: 3, user_id: 2, title: "My first post too".into() };
assert_eq!(expected, users_post);
Child struct 的 belonging_to(parent) 方法来查询一个或多个关联到传入的 parent 的 Child 记录:
belonging_to()是一个没有显式使用 join 方法,如join/inner_join/left_join()的联合查询,它的参数可以是&Parent或&[Parent], 返回关联这些 Parent 的 Child 列表。belonging_to()返回的对象实现了FilterDsl::Output, 可以继续使用 QueryDsl 的其它方法,如select()/filter()/inner_join()/left_join()等。
let sean = users.filter(name.eq("Sean")).first::<User>(connection)?;
let tess = users.filter(name.eq("Tess")).first::<User>(connection)?;
let seans_posts = Post::belonging_to(&sean) // 返回匹配 sean 的 Post 记录列表
.select(title) // 只返回 Post 的 title 字段
.load::<String>(connection)?;
assert_eq!(vec!["My first post", "About Rust"], seans_posts);
let more_posts = Post::belonging_to(&vec![sean, tess])
.select(title)
.load::<String>(connection)?;
assert_eq!(vec!["My first post", "About Rust", "My first post too"], more_posts);
// 对于多对多的查询,可以对 beloing_to() 返回的结果再使用 inner_join()/left_join() 等查询方法
let books = BookAuthor::belonging_to(&astrid_lindgren) // 返回 FilterDsl
.inner_join(books::table) // 继续调用 QueryDsl 的 inner_join()/left_join() 等方法
.select(Book::as_select());
println!("---> m_to_n_relations: {}\n", debug_query::<Pg, _>(&books).to_string());
// ---> m_to_n_relations: SELECT "books"."id", "books"."title" FROM ("books_authors" INNER JOIN "books" ON ("books_authors"."book_id" = "books"."id")) WHERE ("books_authors"."author_id" = $1) -- binds: [2]
let books = books.load(conn)?;
println!("Asgrid Lindgren books: {books:?}");
diesel 为所有实现 IntoIterator<Item = Child> 的类型(如 Vec<Child>)实现了 diesel::associations::GroupedBy trait,该 trait 提供 grouped_by() 方法:
fn grouped_by(self, parents: &'a [Parent]) -> Vec<Vec<Self::Item>>;
由于查询结果类型 Vec<Child> 实现了 GroupedBy trait,所以需要先调用 load() 方法获得结果,再调用 grouped_by() ,它的的参数是 &[Parent], 返回的是按 Parent 聚合后的 Vec<Vec<Child>>,长度和顺序与 &[Parent] 一致,所以后续可以用 zip(&[Parent]) 来迭代:
- 外层 Vec 按照
&[Parent]中每一个 Parent 排列; - 内层
Vec<Child>可能为空 Vec;
let users = users::table.load::<User>(connection)?;
// 需要先调用 load() 方法,对返回结果 Vec<Post> 使用 grouped_by()
let posts = Post::belonging_to(&users)
.load::<Post>(connection)? // 返回属于 users 的 Post 记录列表 Vec<Post>
.grouped_by(&users); // 对 Vec<Post> 按照 users 分组,结果是 Vec<Vec<Post>> 类型
// posts 是 Vec<Vec<Post>> 类型,长度和顺序与 users 相同,故可以 zip 迭代
let data = users.into_iter().zip(posts).collect::<Vec<_>>();
let expected_data = vec![
(
User { id: 1, name: "Sean".into() },
vec![
Post { id: 1, user_id: 1, title: "My first post".into() },
Post { id: 2, user_id: 1, title: "About Rust".into() },
],
),
(
User { id: 2, name: "Tess".into() },
vec![
Post { id: 3, user_id: 2, title: "My first post too".into() },
],
),
];
assert_eq!(expected_data, data);
1-N:belong to #
1-N 即 belong to 关系。
创建两个表的 migration:
diesel migration generate create_books
diesel migration generate create_pages
up 语句:
CREATE TABLE books (
id SERIAL PRIMARY KEY,
title VARCHAR NOT NULL
);
CREATE TABLE pages (
id SERIAL PRIMARY KEY,
page_number INT NOT NULL,
content TEXT NOT NULL,
book_id INTEGER NOT NULL REFERENCES books(id)
);
执行 migration:
diesel migration run
diesel::joinable!() 的参数为: child_table -> parent_table (foreign_key), 只适用于一个 foreign_key 的情况。
对于其它情况,如 composite foreign key,在查询时需要通过 ON clause 来指定。
// @generated automatically by Diesel CLI.
// 下面这些宏位于:https://docs.diesel.rs/master/diesel/prelude/index.html
diesel::table! {
books (id) {
id -> Int4,
title -> Varchar,
}
}
diesel::table! {
pages (id) {
id -> Int4,
page_number -> Int4,
content -> Text,
book_id -> Int4,
}
}
diesel::joinable!(pages -> books (book_id));
diesel::allow_tables_to_appear_in_same_query!(
books,
pages,
);
diesel::joinable!() 可以消除在关联查询时使用 ON cluase 的情况:
On clause由diesel::query_dsl::JoinOnDsl提供的on()方法来实现。
use schema::*;
// Parent table: users
// Child table: posts
// Foreign key: user_id (in child table: posts)
joinable!(posts -> users (user_id));
allow_tables_to_appear_in_same_query!(posts, users);
// 消除 ON clause
let implicit_on_clause = users::table.inner_join(posts::table);
let implicit_on_clause_sql = diesel::debug_query::<DB, _>(&implicit_on_clause).to_string();
// 显式使用 ON clause
let explicit_on_clause = users::table
.inner_join(posts::table.on(posts::user_id.eq(users::id)));
let explicit_on_clause_sql = diesel::debug_query::<DB, _>(&explicit_on_clause).to_string();
// 两者是等价的
assert_eq!(implicit_on_clause_sql, explicit_on_clause_sql);
// posts JOIN users ON posts.user_id = users.id
数据模型 src/model.rs:
use diesel::prelude::*;
use crate::schema::{books, pages};
#[derive(Queryable, Identifiable, Selectable, Debug, PartialEq)]
#[diesel(table_name = books)]
pub struct Book {
pub id: i32,
pub title: String,
}
// Child 表添加 Associations
#[derive(Queryable, Selectable, Identifiable, Associations, Debug, PartialEq)]
// belongs_to 指定 Parent table, foreign_key 默认为 {Parent}_id, 也可以明确指定。
#[diesel(belongs_to(Book, foreign_key = book_id))]
#[diesel(table_name = pages)]
pub struct Page {
pub id: i32,
pub page_number: i32,
pub content: String,
pub book_id: i32,
}
读数据:
let momo = books::table
.filter(books::title.eq("Momo"))
.select(Book::as_select())
.get_result(conn)?;
// belonging_to() 是 1-N 关联查询, 传入的可以是单个 Parent 或多个 Parent.
let pages = Page::belonging_to(&momo)
.select(Page::as_select())
.load(conn)?; // 使用 load() 而非 execute()/get_results(), 故后续可以添加额外的 clause
//指定的语句: SELECT * FROM pages WHERE book_id IN(…)
println!("Pages for \"Momo\": \n {pages:?}\n");
// 查询所有的 books
let all_books = books::table.select(Book::as_select()).load(conn)?;
// 查询所有 book 的所有 page
let pages = Page::belonging_to(&all_books) // bool slice
.select(Page::as_select())
.load(conn)?; // 不实际查询, 故后续可以添加额外的 clause
// group the pages per book
let pages_per_book = pages
.grouped_by(&all_books)
.into_iter()
.zip(all_books)
.map(|(pages, book)| (book, pages)) // 返回一个 tuple
.collect::<Vec<(Book, Vec<Page>)>>();
println!("Pages per book: \n {pages_per_book:?}\n");
反序列化结果到自定义类型:
// [{
// "id": 1,
// "title": "Momo",
// "pages": […],
// }]
#[derive(Serialize)] // serde 提供的 Serialize macro
struct BookWithPages {
#[serde(flatten)] // 将 book 字段内容打平到结果类型中(默认是位于 book 字段中)
book: Book,
pages: Vec<Page>,
}
// group the pages per book
let pages_per_book = pages
.grouped_by(&all_books)
.into_iter()
.zip(all_books)
.map(|(pages, book)| BookWithPages { book, pages })
.collect::<Vec<BookWithPages>>();
join #
对于非 1-N 的关联关系,diesel 需要使用 SQL JOIN 来解决。
diesel 提供了两种 join 类型:INNER JOIN 和 LEFT JOIN。
QueryDsl::inner_join():
let page_with_book = pages::table
.inner_join(books::table)
.filter(books::title.eq("Momo"))
.select((Page::as_select(), Book::as_select()))
.load::<(Page, Book)>(conn)?;
println!("Page-Book pairs: {page_with_book:?}");
// 两种不同的 inner_join() 类型:
users::table.inner_join(posts::table.inner_join(comments::table));
// Results in the following SQL
// SELECT * FROM users
// INNER JOIN posts ON users.id = posts.user_id
// INNER JOIN comments ON post.id = comments.post_id
users::table.inner_join(posts::table).inner_join(comments::table);
// Results in the following SQL
// SELECT * FROM users
// INNER JOIN posts ON users.id = posts.user_id
// INNER JOIN comments ON users.id = comments.user_id
QueryDsl::left_join(): 返回的结果类型:(Book, Option<Page>)
let book_without_pages = books::table
.left_join(pages::table)
.select((Book::as_select(), Option::<Page>::as_select()))
.load::<(Book, Option<Page>)>(conn)?;
println!("Book-Page pairs (including empty books): {book_without_pages:?}");
left_join/right_join() 返回的记录中,另一半不一定能查到值,所以需要使用 Option<T>。
默认使用 joinable!() 来隐式构建 ON 语句,也可以使用 JoinOnDsl::on() 来自定义 join 规则:
pub trait JoinOnDsl: Sized {
// Provided method
fn on<On>(self, on: On) -> On<Self, On> { ... }
}
let data = users::table
.left_join(posts::table.on(
users::id.eq(posts::user_id).and(
posts::title.eq("My first post"))
))
.select((users::name, posts::title.nullable()))
.load(connection);
let expected = vec![
("Sean".to_string(), Some("My first post".to_string())),
("Tess".to_string(), None),
];
assert_eq!(Ok(expected), data);
M-N #
Many-to-Many 需要使用 Join Table 来实现,它 belongs_to 所有关联的 table。
创建 migration:
diesel migration generate create_authors
diesel migration generate create_books_authors // 创建 join table
join table 的定义中要使用 FK 来引用关联的表记录:
CREATE TABLE authors (
id SERIAL PRIMARY KEY,
name VARCHAR NOT NULL
);
CREATE TABLE books_authors (
book_id INTEGER REFERENCES books(id),
author_id INTEGER REFERENCES authors(id),
PRIMARY KEY(book_id, author_id)
);
执行迁移:diesel migration run
创建 model:核心是 join table 要 belongs_to 到所有的关联的表;
use diesel::prelude::*;
use crate::schema::{books, pages, authors, books_authors};
#[derive(Queryable, Selectable, Identifiable, PartialEq, Debug)]
#[diesel(table_name = authors)]
pub struct Author {
pub id: i32,
pub name: String,
}
#[derive(Identifiable, Selectable, Queryable, Associations, Debug)]
#[diesel(belongs_to(Book))]
#[diesel(belongs_to(Author))]
#[diesel(table_name = books_authors)]
#[diesel(primary_key(book_id, author_id))]
pub struct BookAuthor {
pub book_id: i32,
pub author_id: i32,
}
读数据:先使用 belonging_to() 进行 1-N join,然后再使用 inner_join();
let astrid_lindgren = authors::table
.filter(authors::name.eq("Astrid Lindgren"))
.select(Author::as_select())
.get_result(conn)?;
// 多对多的查询: 对 beloing_to() 返回的结果再使用 inner_join()/left_join() 等查询
let books = BookAuthor::belonging_to(&astrid_lindgren) // 返回 FilterDsl
.inner_join(books::table) // 继续调用 QueryDsl 的 inner_join()/left_join() 等方法
.select(Book::as_select());
println!("---> m_to_n_relations: {}\n", debug_query::<Pg, _>(&books).to_string());
// ---> m_to_n_relations: SELECT "books"."id", "books"."title" FROM ("books_authors" INNER JOIN "books" ON ("books_authors"."book_id" = "books"."id")) WHERE ("books_authors"."author_id" = $1) -- binds: [2]
let books = books.load(conn)?;
println!("Asgrid Lindgren books: {books:?}");
关联查询示例 #
SQL 表名惯例: 小写的复数形式, 用下划线分割: books, authors, books_authros;
对应的 Rust model struct 命名惯例: 大写的单数形式, Book, Author, BookAuthor;
表的主键: id
表的外键: 单数表名_id, 如: book_id, author_id;
// https://github.com/diesel-rs/diesel/tree/2.2.x/examples/postgres/relations
// CREATE TABLE books (
// id SERIAL PRIMARY KEY,
// title VARCHAR NOT NULL
// );
// CREATE TABLE pages (
// id SERIAL PRIMARY KEY,
// page_number INT NOT NULL,
// content TEXT NOT NULL,
// book_id INTEGER NOT NULL REFERENCES books(id)
// );
// CREATE TABLE authors (
// id SERIAL PRIMARY KEY,
// name VARCHAR NOT NULL
// );
// CREATE TABLE books_authors (
// book_id INTEGER REFERENCES books(id),
// author_id INTEGER REFERENCES authors(id),
// PRIMARY KEY(book_id, author_id)
// );
// @generated automatically by Diesel CLI.
diesel::table! {
authors (id) { // table_name (primary_key_column)
id -> Int4,
name -> Varchar,
}
}
diesel::table! {
books (id) {
id -> Int4,
title -> Varchar,
}
}
diesel::table! {
books_authors (book_id, author_id) {
book_id -> Int4, // 只是表字段, 没有体现外键引用关系
author_id -> Int4,
}
}
diesel::table! {
pages (id) {
id -> Int4,
page_number -> Int4,
content -> Text,
book_id -> Int4,
}
}
// 定义表之间的外键引用关系,格式:子表 -> 父表 (子表中引用父表的外键)
diesel::joinable!(books_authors -> authors (author_id));
diesel::joinable!(books_authors -> books (book_id));
diesel::joinable!(pages -> books (book_id));
diesel::allow_tables_to_appear_in_same_query!(authors, books, books_authors, pages,);
// https://github.com/diesel-rs/diesel/blob/2.2.x/examples/postgres/relations/src/model.rs
#[derive(Queryable, Selectable, Identifiable, PartialEq, Debug, Clone)]
#[diesel(table_name = authors)] // table_name 一般用复数, struct 用单数.
pub struct Author {
pub id: i32,
pub name: String,
}
// 子表(带外键) 需要:
// 1. 实现 Associations 宏;
// 2. 添加 belongs_to(父表 Struct) 的属性宏
// 3. 父表和子表都需要实现 Identifiable
#[derive(Identifiable, Selectable, Queryable, Associations, Debug, Clone)]
#[diesel(belongs_to(Book))] // 参数是父表 Struct 名称
#[diesel(belongs_to(Author))]
#[diesel(table_name = books_authors)]
#[diesel(primary_key(book_id, author_id))] // 使用非默认的主键(id), 需要明确指定, 这里为联合主键.
pub struct BookAuthor {
pub book_id: i32,
pub author_id: i32,
}
#[derive(Queryable, Identifiable, Selectable, Debug, PartialEq, Clone)]
#[diesel(table_name = books)]
pub struct Book {
pub id: i32,
pub title: String,
}
#[derive(Queryable, Selectable, Identifiable, Associations, Debug, PartialEq)]
#[diesel(belongs_to(Book))]
#[diesel(table_name = pages)]
pub struct Page {
pub id: i32,
pub page_number: i32,
pub content: String,
pub book_id: i32,
}
fn new_author(conn: &mut PgConnection, name: &str) -> Result<Author, Box<dyn Error + Send + Sync>> {
let author1 = diesel::insert_into(authors::table)
.values(authors::name.eq(name))
.returning(Author::as_returning()); // insert/update 使用 returning() 来返回值类型
println!("---> new_author: {}", debug_query::<Pg, _>(&author1).to_string());
// ---> new_author: INSERT INTO "authors" ("name") VALUES ($1) RETURNING "authors"."id", "authors"."name" -- binds: ["Michael Ende"]
// ---> new_author: INSERT INTO "authors" ("name") VALUES ($1) RETURNING "authors"."id", "authors"."name" -- binds: ["Astrid Lindgren"]
let author = author1.get_result(conn)?;
Ok(author)
}
fn new_book(conn: &mut PgConnection, title: &str) -> Result<Book, Box<dyn Error + Send + Sync>> {
let book = diesel::insert_into(books::table)
.values(books::title.eq(title))
.returning(Book::as_returning())
.get_result(conn)?;
Ok(book)
}
fn new_books_author( conn: &mut PgConnection, book_id: i32, author_id: i32, ) -> Result<BookAuthor, Box<dyn Error + Send + Sync>> {
// 对于关联表, 需要插入两个 id
let book_author = diesel::insert_into(books_authors::table)
.values(( // 一个 tuple 对应一个记录的多个字段
books_authors::book_id.eq(book_id),
books_authors::author_id.eq(author_id),
))
.returning(BookAuthor::as_returning());
println!("---> new_books_author: {}", debug_query::<Pg, _>(&book_author).to_string());
// ---> new_books_author: INSERT INTO "books_authors" ("book_id", "author_id") VALUES ($1, $2) RETURNING "books_authors"."book_id", "books_authors"."author_id" -- binds: [17, 12]
// ---> new_books_author: INSERT INTO "books_authors" ("book_id", "author_id") VALUES ($1, $2) RETURNING "books_authors"."book_id", "books_authors"."author_id" -- binds: [18, 12]
// ---> new_books_author: INSERT INTO "books_authors" ("book_id", "author_id") VALUES ($1, $2) RETURNING "books_authors"."book_id", "books_authors"."author_id" -- binds: [18, 11]
let book_author = book_author.get_result(conn)?;
Ok(book_author)
}
fn new_page( conn: &mut PgConnection, page_number: i32, content: &str, book_id: i32, ) -> Result<Page, Box<dyn Error + Send + Sync>> {
let page = diesel::insert_into(pages::table)
.values((
pages::page_number.eq(page_number),
pages::content.eq(content),
pages::book_id.eq(book_id),
))
.returning(Page::as_returning())
.get_result(conn)?;
Ok(page)
}
fn joins(conn: &mut PgConnection) -> Result<(), Box<dyn Error + Send + Sync>> {
// inner_join 查询: 查询所有页
let page_with_book = pages::table
.inner_join(books::table) // inner_join 返回两个表匹配的交集,所以返回的记录中肯定同时有 Page 和 Book
.filter(books::title.eq("Momo"))
.select((Page::as_select(), Book::as_select()));
println!("---> joins: {}", debug_query::<Pg, _>(&page_with_book).to_string());
// ---> joins: SELECT "pages"."id", "pages"."page_number", "pages"."content", "pages"."book_id", "books"."id", "books"."title" FROM ("pages" INNER JOIN "books" ON ("pages"."book_id" = "books"."id")) WHERE ("books"."title" = $1) -- binds: ["Momo"]
let page_with_book = page_with_book .load::<(Page, Book)>(conn)?;
println!("Page-Book pairs: {page_with_book:?}");
let book_without_pages = books::table
.left_join(pages::table)
.select((Book::as_select(), Option::<Page>::as_select())) // left_join/right_join() 返回的记录中,另一半不一定能查到值,所以需要使用 Option<T>。
.load::<(Book, Option<Page>)>(conn)?;
println!("Book-Page pairs (including empty books): {book_without_pages:?}");
Ok(())
}
fn one_to_n_relations(conn: &mut PgConnection) -> Result<(), Box<dyn Error + Send + Sync>> {
let momo = books::table
.filter(books::title.eq("Momo"))
.select(Book::as_select())
.get_result(conn)?;
// get pages for the book "Momo"
let pages = Page::belonging_to(&momo)
.select(Page::as_select());
println!("---> one_to_n_relations: {}\n", debug_query::<Pg, _>(&pages).to_string());
// ---> one_to_n_relations: SELECT "pages"."id", "pages"."page_number", "pages"."content", "pages"."book_id" FROM "pages" WHERE ("pages"."book_id" = $1) -- binds: [1]
let pages = pages .load(conn)?;
println!("Pages for \"Momo\": \n {pages:?}\n");
let mut all_books = books::table.select(Book::as_select()).load(conn)?;
// get all pages for all books
let pages = Page::belonging_to(&all_books) // 一次 select ANY 查询:从 all_books 提取主键列表,然后使用 Page 的外键来 ANY 查询。
.select(Page::as_select());
println!("---> one_to_n_relations2: {}\n", debug_query::<Pg, _>(&pages).to_string());
// ---> one_to_n_relations2: SELECT "pages"."id", "pages"."page_number", "pages"."content", "pages"."book_id" FROM "pages" WHERE ("pages"."book_id" = ANY($1)) -- binds: [[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27]]
let pages = pages .load(conn)?;
println!("---> pages: {:?}", pages);
// ---> pages: [Page { id: 1, page_number: 1, content: "In alten, alten Zeiten ...", book_id: 1 }, Page { id: 2, page_number: 2, content: "den prachtvollen Theatern...", book_id: 1 }, Page { id: 3, page_number: 1, content: "In alten, alten Zeiten ...", book_id: 4 }, Page { id: 4, page_number: 2, content: "den prachtvollen Theatern...", book_id: 4 }, Page { id: 5, page_number: 1, content: "In alten, alten Zeiten ...", book_id: 7 }, Page { id: 6, page_number: 2, content: "den prachtvollen Theatern...", book_id: 7 }, Page { id: 7, page_number: 1, content: "In alten, alten Zeiten ...", book_id: 10 }, Page { id: 8, page_number: 2, content: "den prachtvollen Theatern...", book_id: 10 }, Page { id: 9, page_number: 1, content: "In alten, alten Zeiten ...", book_id: 13 }, Page { id: 10, page_number: 2, content: "den prachtvollen Theatern...", book_id: 13 }, Page { id: 11, page_number: 1, content: "In alten, alten Zeiten ...", book_id: 16 }, Page { id: 12, page_number: 2, content: "den prachtvollen Theatern...", book_id: 16 }, Page { id: 13, page_number: 1, content: "In alten, alten Zeiten ...", book_id: 19 }, Page { id: 14, page_number: 2, content: "den prachtvollen Theatern...", book_id: 19 }, Page { id: 15, page_number: 1, content: "In alten, alten Zeiten ...", book_id: 22 }, Page { id: 16, page_number: 2, content: "den prachtvollen Theatern...", book_id: 22 }, Page { id: 17, page_number: 1, content: "In alten, alten Zeiten ...", book_id: 25 }, Page { id: 18, page_number: 2, content: "den prachtvollen Theatern...", book_id: 25 }, Page { id: 19, page_number: 1, content: "In alten, alten Zeiten ...", book_id: 28 }, Page { id: 20, page_number: 2, content: "den prachtvollen Theatern...", book_id: 28 }]
// 抛出异常:no entry found for key
// all_books = vec![Book{id: 333, title: "abcd".into()}];
// 故意加一个不存在的 book
all_books.push(Book{id: 333, title: "abcd".into()});
let pages_per_book = pages
.grouped_by(&all_books) // 返回的 Vec 长度和 all_books 一致,Vec 的元素类型为 Vec<Page>(可能为空)
.into_iter()
.collect::<Vec<_>>();
println!("Pages per book: \n {pages_per_book:?}\n");
// 注意: 返回的 Vec 类型是 Vec<Vec<Page>>, 长度和 all_books 一致, 外层的 Vec 元素按照 book_id 排序, 如果 book_id 对应的 Page 不存在, 则内层的 Vec<Page> 为空 [];
// Pages per book:
// [[Page { id: 1, page_number: 1, content: "In alten, alten Zeiten ...", book_id: 1 }, Page { id: 2, page_number: 2, content: "den prachtvollen Theatern...", book_id: 1 }], [], [], [Page { id: 3, page_number: 1, content: "In alten, alten Zeiten ...", book_id: 4 }, Page { id: 4, page_number: 2, content: "den prachtvollen Theatern...", book_id: 4 }], [], [], [Page { id: 5, page_number: 1, content: "In alten, alten Zeiten ...", book_id: 7 }, Page { id: 6, page_number: 2, content: "den prachtvollen Theatern...", book_id: 7 }], [], [], [Page { id: 7, page_number: 1, content: "In alten, alten Zeiten ...", book_id: 10 }, Page { id: 8, page_number: 2, content: "den prachtvollen Theatern...", book_id: 10 }], [], [], [Page { id: 9, page_number: 1, content: "In alten, alten Zeiten ...", book_id: 13 }, Page { id: 10, page_number: 2, content: "den prachtvollen Theatern...", book_id: 13 }], [], [], [Page { id: 11, page_number: 1, content: "In alten, alten Zeiten ...", book_id: 16 }, Page { id: 12, page_number: 2, content: "den prachtvollen Theatern...", book_id: 16 }], [], [], [Page { id: 13, page_number: 1, content: "In alten, alten Zeiten ...", book_id: 19 }, Page { id: 14, page_number: 2, content: "den prachtvollen Theatern...", book_id: 19 }], [], [], [Page { id: 15, page_number: 1, content: "In alten, alten Zeiten ...", book_id: 22 }, Page { id: 16, page_number: 2, content: "den prachtvollen Theatern...", book_id: 22 }], [], [], [Page { id: 17, page_number: 1, content: "In alten, alten Zeiten ...", book_id: 25 }, Page { id: 18, page_number: 2, content: "den prachtvollen Theatern...", book_id: 25 }], [], [], [Page { id: 19, page_number: 1, content: "In alten, alten Zeiten ...", book_id: 28 }, Page { id: 20, page_number: 2, content: "den prachtvollen Theatern...", book_id: 28 }], [], [], [Page { id: 21, page_number: 1, content: "In alten, alten Zeiten ...", book_id: 31 }, Page { id: 22, page_number: 2, content: "den prachtvollen Theatern...", book_id: 31 }], [], [], [Page { id: 23, page_number: 1, content: "In alten, alten Zeiten ...", book_id: 34 }, Page { id: 24, page_number: 2, content: "den prachtvollen Theatern...", book_id: 34 }], [], [], [Page { id: 25, page_number: 1, content: "In alten, alten Zeiten ...", book_id: 37 }, Page { id: 26, page_number: 2, content: "den prachtvollen Theatern...", book_id: 37 }], [], [], [Page { id: 27, page_number: 1, content: "In alten, alten Zeiten ...", book_id: 40 }, Page { id: 28, page_number: 2, content: "den prachtvollen Theatern...", book_id: 40 }], [], [], [Page { id: 29, page_number: 1, content: "In alten, alten Zeiten ...", book_id: 43 }, Page { id: 30, page_number: 2, content: "den prachtvollen Theatern...", book_id: 43 }], [], [], []]
// group the pages per book
// let pages_per_book = pages
// .grouped_by(&all_books) // 返回的 Vec 长度和 all_books 一致,Vec 的元素类型为 Vec<Page>(可能为空)
// .into_iter()
// .zip(all_books) // 由于 grouped_by() 返回的长度和 all_books 一致,所以可以 zip(all_books)
// .map(|(pages, book)| (book, pages))
// .collect::<Vec<(Book, Vec<Page>)>>();
// println!("Pages per book: \n {pages_per_book:?}\n");
// 注意: 返回所有 all_books 中的 Book, 但是 Vec<Page> 可能为空列表,如上面 id 为 333 的 Book
// [(Book { id: 1, title: "Momo" }, [Page { id: 1, page_number: 1, content: "In alten, alten Zeiten ...", book_id: 1 }, Page { id: 2, page_number: 2, content: "den prachtvollen Theatern...", book_id: 1 }]), (Book { id: 2, title: "Pippi Långstrump" }, []), (Book { id: 3, title: "Pippi and Momo" }, []), (Book { id: 4, title: "Momo" }, [Page { id: 3, page_number: 1, content: "In alten, alten Zeiten ...", book_id: 4 }, Page { id: 4, page_number: 2, content: "den prachtvollen Theatern...", book_id: 4 }]), (Book { id: 5, title: "Pippi Långstrump" }, []), (Book { id: 6, title: "Pippi and Momo" }, []), (Book { id: 7, title: "Momo" }, [Page { id: 5, page_number: 1, content: "In alten, alten Zeiten ...", book_id: 7 }, Page { id: 6, page_number: 2, content: "den prachtvollen Theatern...", book_id: 7 }]), (Book { id: 8, title: "Pippi Långstrump" }, []), (Book { id: 9, title: "Pippi and Momo" }, []), (Book { id: 10, title: "Momo" }, [Page { id: 7, page_number: 1, content: "In alten, alten Zeiten ...", book_id: 10 }, Page { id: 8, page_number: 2, content: "den prachtvollen Theatern...", book_id: 10 }]), (Book { id: 11, title: "Pippi Långstrump" }, []), (Book { id: 12, title: "Pippi and Momo" }, []), (Book { id: 13, title: "Momo" }, [Page { id: 9, page_number: 1, content: "In alten, alten Zeiten ...", book_id: 13 }, Page { id: 10, page_number: 2, content: "den prachtvollen Theatern...", book_id: 13 }]), (Book { id: 14, title: "Pippi Långstrump" }, []), (Book { id: 15, title: "Pippi and Momo" }, []), (Book { id: 16, title: "Momo" }, [Page { id: 11, page_number: 1, content: "In alten, alten Zeiten ...", book_id: 16 }, Page { id: 12, page_number: 2, content: "den prachtvollen Theatern...", book_id: 16 }]), (Book { id: 17, title: "Pippi Långstrump" }, []), (Book { id: 18, title: "Pippi and Momo" }, []), (Book { id: 19, title: "Momo" }, [Page { id: 13, page_number: 1, content: "In alten, alten Zeiten ...", book_id: 19 }, Page { id: 14, page_number: 2, content: "den prachtvollen Theatern...", book_id: 19 }]), (Book { id: 20, title: "Pippi Långstrump" }, []), (Book { id: 21, title: "Pippi and Momo" }, []), (Book { id: 22, title: "Momo" }, [Page { id: 15, page_number: 1, content: "In alten, alten Zeiten ...", book_id: 22 }, Page { id: 16, page_number: 2, content: "den prachtvollen Theatern...", book_id: 22 }]), (Book { id: 23, title: "Pippi Långstrump" }, []), (Book { id: 24, title: "Pippi and Momo" }, []), (Book { id: 25, title: "Momo" }, [Page { id: 17, page_number: 1, content: "In alten, alten Zeiten ...", book_id: 25 }, Page { id: 18, page_number: 2, content: "den prachtvollen Theatern...", book_id: 25 }]), (Book { id: 26, title: "Pippi Långstrump" }, []), (Book { id: 27, title: "Pippi and Momo" }, []), (Book { id: 28, title: "Momo" }, [Page { id: 19, page_number: 1, content: "In alten, alten Zeiten ...", book_id: 28 }, Page { id: 20, page_number: 2, content: "den prachtvollen Theatern...", book_id: 28 }]), (Book { id: 29, title: "Pippi Långstrump" }, []), (Book { id: 30, title: "Pippi and Momo" }, []), (Book { id: 31, title: "Momo" }, [Page { id: 21, page_number: 1, content: "In alten, alten Zeiten ...", book_id: 31 }, Page { id: 22, page_number: 2, content: "den prachtvollen Theatern...", book_id: 31 }]), (Book { id: 32, title: "Pippi Långstrump" }, []), (Book { id: 33, title: "Pippi and Momo" }, []), (Book { id: 34, title: "Momo" }, [Page { id: 23, page_number: 1, content: "In alten, alten Zeiten ...", book_id: 34 }, Page { id: 24, page_number: 2, content: "den prachtvollen Theatern...", book_id: 34 }]), (Book { id: 35, title: "Pippi Långstrump" }, []), (Book { id: 36, title: "Pippi and Momo" }, []), (Book { id: 37, title: "Momo" }, [Page { id: 25, page_number: 1, content: "In alten, alten Zeiten ...", book_id: 37 }, Page { id: 26, page_number: 2, content: "den prachtvollen Theatern...", book_id: 37 }]), (Book { id: 38, title: "Pippi Långstrump" }, []), (Book { id: 39, title: "Pippi and Momo" }, []), (Book { id: 40, title: "Momo" }, [Page { id: 27, page_number: 1, content: "In alten, alten Zeiten ...", book_id: 40 }, Page { id: 28, page_number: 2, content: "den prachtvollen Theatern...", book_id: 40 }]), (Book { id: 41, title: "Pippi Långstrump" }, []), (Book { id: 42, title: "Pippi and Momo" }, []), (Book { id: 333, title: "abcd" }, [])]
Ok(())
}
// 基于关联表的查询
// 1. 关联表的 belonging_to(父表记录) 方法返回附表记录关联的所有关联表记录
// 2. inner_join(books::table) 返回属于 astrid_lindgren 的 Book 记录
fn m_to_n_relations(conn: &mut PgConnection) -> Result<(), Box<dyn Error + Send + Sync>> {
let astrid_lindgren = authors::table
.filter(authors::name.eq("Astrid Lindgren"))
.select(Author::as_select())
.get_result(conn)?;
// get all of Astrid Lindgren's books
let books = BookAuthor::belonging_to(&astrid_lindgren)
.inner_join(books::table)
.select(Book::as_select());
println!("---> m_to_n_relations: {}\n", debug_query::<Pg, _>(&books).to_string());
// ---> m_to_n_relations: SELECT "books"."id", "books"."title" FROM ("books_authors" INNER JOIN "books" ON ("books_authors"."book_id" = "books"."id")) WHERE ("books_authors"."author_id" = $1) -- binds: [2]
let books = books
.load(conn)?;
println!("Asgrid Lindgren books: {books:?}");
let collaboration = books::table
.filter(books::title.eq("Pippi and Momo"))
.select(Book::as_select())
.get_result(conn)?;
// get authors for the collaboration
let authors = BookAuthor::belonging_to(&collaboration)
.inner_join(authors::table)
.select(Author::as_select())
.load(conn)?;
println!("Authors for \"Pipi and Momo\": {authors:?}");
// get a list of authors with all their books
let all_authors = authors::table.select(Author::as_select()).load(conn)?;
let books = BookAuthor::belonging_to(&authors)
.inner_join(books::table)
.select((BookAuthor::as_select(), Book::as_select()));
println!("---> m_to_n_relations2: {}\n", debug_query::<Pg, _>(&books).to_string());
// ---> m_to_n_relations2: SELECT "books_authors"."book_id", "books_authors"."author_id", "books"."id", "books"."title" FROM ("books_authors" INNER JOIN "books" ON ("books_authors"."book_id" = "books"."id")) WHERE ("books_authors"."author_id" = ANY($1)) -- binds: [[2, 1]]
let books = books
.load(conn)?;
let books_per_author: Vec<(Author, Vec<Book>)> = books
.grouped_by(&all_authors)
.into_iter()
.zip(authors)
.map(|(b, author)| (author, b.into_iter().map(|(_, book)| book).collect()))
.collect();
println!("All authors including their books: {books_per_author:?}");
Ok(())
}
diesel::dsl 函数(bare functions, delete/insert/update) #
对于非 select 查询类型, 不是直接在 table 对象上调用, 需要调用 module diesel::dsl 提供的对应函数(Bare functions):
let inserted_posts = posts::table // 可以在 table 上直接调用的 select 查询
.select(posts::title)
.load::<String>(conn)?;
let expected = vec!["Sean's First Post", "Tess's First Post"];
assert_eq!(expected, inserted_posts);
// update: 不能在 table 类型对象上调用该函数,而是直接调用 diesel::update()
let updated_row = diesel::update(users.filter(id.eq(1)))
.set((name.eq("James"), surname.eq("Bond")))
.get_result(connection);
assert_eq!(Ok((1, "James".to_string(), "Bond".to_string())), updated_row);
- avg: Represents a SQL AVG function. This function can only take types which are Foldable.
- case_when: Creates a SQL CASE WHEN … END expression
- copy_from: Creates a COPY FROM statement
- copy_to: Creates a COPY TO statement
- count: Creates a SQL COUNT expression
- count_distinct: Creates a SQL COUNT(DISTINCT …) expression
- count_star: Creates a SQL COUNT(*) expression
- date: Represents the SQL DATE function. The argument should be a Timestamp expression, and the return value will be an expression of type Date.
delete: Creates a DELETE statement.- exists: Creates a SQL EXISTS expression.
insert_into: Creates an INSERT statement for the target table.- insert_or_ignore_into: Creates an INSERT [OR] IGNORE statement.
- max: Represents a SQL MAX function. This function can only take types which are ordered.
- min: Represents a SQL MIN function. This function can only take types which are ordered.
- not: Creates a SQL NOT expression
- replace_into: Creates a REPLACE statement.
select: Creates a bare select statement, with no from clause. Primarily used for testing diesel itself, but likely useful for third party crates as well. The given expressions must be selectable from anywhere.- sql: Use literal SQL in the query builder.
- sql_query: Construct a full SQL query using raw SQL.
- sum: Represents a SQL SUM function. This function can only take types which are Foldable.
update: Creates an UPDATE statement.
有些函数在 diesel crate 中直接导出, 如 diesel::update/insert_into():
// update: 注意: 不是在 table 类型对象上调用该函数.
let updated_row = diesel::update(users.filter(id.eq(1)))
.set((name.eq("James"), surname.eq("Bond")))
.get_result(connection);
assert_eq!(Ok((1, "James".to_string(), "Bond".to_string())), updated_row);
// delete
let old_count = users.count().first::<i64>(connection);
diesel::delete(users.filter(id.eq(1))).execute(connection)?;
assert_eq!(old_count.map(|count| count - 1), users.count().first(connection));
// insert_into
let rows_inserted = diesel::insert_into(users)
.values(&name.eq("Sean"))
.execute(connection);
assert_eq!(Ok(1), rows_inserted);
// select (很少用,一般调用 table 的 select() 方法)
use diesel::dsl::exists;
use diesel::dsl::select;
// exists() 返回 Exists 类型实现了 Expression, 故可以作为 select() 的参数
let sean_exists = select(exists(users.filter(name.eq("Sean")))).get_result(connection);
let jim_exists = select(exists(users.filter(name.eq("Jim")))).get_result(connection);
assert_eq!(Ok(true), sean_exists);
assert_eq!(Ok(false), jim_exists);
和 table 实现的 QueryDsl 的 select() 返回的 Select 是 SelectStatement 类型类似, diesel::dsl::select()/diesel::select() 函数也返回的是 SelectStatement 类型:
// select() 创建一个 select statement
pub fn select<T>(expression: T) -> select<T> where T: Expression, select<T>: AsQuery
// 返回的 select<T> 其实是 SelectStatement 的类型别名
pub type select<Selection> = SelectStatement<NoFromClause, SelectClause<Selection>>;
debug_query() #
函数 diesel::debug_query() 用于将 QueryFragment 查询表达式打印出来(实现了 fmt::Display/fmt::Debug), 常用于显示 diesel 语句调试。
pub fn debug_query<DB, T>(query: &T) -> DebugQuery<'_, T, DB>
let sql = debug_query::<DB, _>(&users.count()).to_string();
assert_eq!(sql, "SELECT COUNT(*) FROM `users` -- binds: []");
let query = users.find(1);
let debug = debug_query::<DB, _>(&query);
assert_eq!(debug.to_string(), "SELECT `users`.`id`, `users`.`name` FROM `users` \
WHERE (`users`.`id` = ?) -- binds: [1]");
let debug = format!("{:?}", debug);
let expected = "Query { \
sql: \"SELECT `users`.`id`, `users`.`name` FROM `users` WHERE \
(`users`.`id` = ?)\", \
binds: [1] \
}";
assert_eq!(debug, expected);let sql = debug_query::<DB, _>(&users.count()).to_string();
assert_eq!(sql, "SELECT COUNT(*) FROM `users` -- binds: []");
let query = users.find(1);
let debug = debug_query::<DB, _>(&query);
assert_eq!(debug.to_string(), "SELECT `users`.`id`, `users`.`name` FROM `users` \
WHERE (`users`.`id` = ?) -- binds: [1]");
let debug = format!("{:?}", debug);
let expected = "Query { \
sql: \"SELECT `users`.`id`, `users`.`name` FROM `users` WHERE \
(`users`.`id` = ?)\", \
binds: [1] \
}";
assert_eq!(debug, expected);
delete() #
diesel::delete() 返回 DeleteStatement, 传入的参数类型是 IntoUpdateTarget:
- Identifiable/table/SelectStatement 均实现了 IntoUpdateTarget,所以 tables 和 tables 调用的各种 QueryDsl 方法可以为传给 delete()
- 当传入 Identifiable/table 时,删除整个 table 记录。可以传入 SelectStatement 或调用 DeleteStatement 的 filter方法来限制删除的记录范围。
- Identifiable 可以通过 derive macro 为自定义 struct 类型来实现,这样可以 delete() 可以传入自定义类型。
// Function diesel::dsl::delete
pub fn delete<T: IntoUpdateTarget>( source: T, ) -> DeleteStatement<T::Table, T::WhereClause>
// A type which can be passed to update or delete.
pub trait IntoUpdateTarget: HasTable {
type WhereClause;
// Required method
fn into_update_target(self) -> UpdateTarget<Self::Table, Self::WhereClause>;
}
// Struct diesel::query_builder::UpdateTarget
pub struct UpdateTarget<Table, WhereClause> {
pub table: Table,
pub where_clause: WhereClause,
}
// 1. Identifiable 实现了 IntoUpdateTarget,故可以传入实现了 Identifiable 的自定义 struct 类型
impl<T, Tab, V> IntoUpdateTarget for T
where
T: Identifiable<Table = Tab>,
Tab: Table + FindDsl<T::Id>,
Find<Tab, T::Id>: IntoUpdateTarget<Table = Tab, WhereClause = V>
// 2. table 实现了 IntoUpdateTarget
impl IntoUpdateTarget for table
// 3. SelectStatement 也实现了 IntoUpdateTarget (但是奇怪的是,生成的 docs 并没有显示)
// https://docs.diesel.rs/2.2.x/src/diesel/query_builder/select_statement/dsl_impls.rs.html#540
impl<F, W> IntoUpdateTarget
for SelectStatement<FromClause<F>, DefaultSelectClause<FromClause<F>>, NoDistinctClause, W>
where F: QuerySource, Self: HasTable, W: ValidWhereClause<F>,
{
type WhereClause = W;
fn into_update_target(self) -> UpdateTarget<Self::Table, Self::WhereClause> {
UpdateTarget {
table: Self::table(),
where_clause: self.where_clause,
}
}
}
// 示例
let deleted_rows = diesel::delete(users) // 传入实现 IntoUpdateTarget 的 table
.filter(name.eq("Sean"))
.execute(connection);
assert_eq!(Ok(1), deleted_rows);
let old_count = users.count().first::<i64>(connection);
diesel::delete(users.filter(id.eq(1))) // 传入实现 IntoUpdateTarget 的 SelectStatement
.execute(connection)?;
assert_eq!(old_count.map(|count| count - 1), users.count().first(connection));
// 删除单个记录
let old_count = users.count().first::<i64>(connection);
diesel::delete(users.filter(id.eq(1))).execute(connection)?;
assert_eq!(old_count.map(|count| count - 1), users.count().first(connection));
// 删除整个表
diesel::delete(users).execute(connection)?;
assert_eq!(Ok(0), users.count().first::<i64>(connection));
DeleteStatement #
Struct diesel::query_builder::DeleteStatement:
- DeleteStatement 实现了 filter/or_filter/returning() 方法;
- returning() 的参数 SelectableExpression,table field 和它的各种 tuple 组合类型实现了该 trait。
pub struct DeleteStatement<T: QuerySource, U, Ret = NoReturningClause> { /* private fields */ }
// DeleteStatement 实现了 filter/or_filter/returning 方法
impl<T: QuerySource, U> DeleteStatement<T, U, NoReturningClause>
pub fn filter<Predicate>(self, predicate: Predicate) -> Filter<Self, Predicate>
where Self: FilterDsl<Predicate>
// Calling foo.filter(bar).or_filter(baz) is identical to foo.filter(bar.or(baz)).
pub fn or_filter<Predicate>( self, predicate: Predicate, ) -> OrFilter<Self, Predicate>
where Self: OrFilterDsl<Predicate>,
// table!() 宏生成的 filed 字段类型都实现了 SelectableExpression,可以用作 returning 的参数。
//
// 如果要返回多个字段,则需要使用 tuple 类型。
pub fn returning<E>( self, returns: E, ) -> DeleteStatement<T, U, ReturningClause<E>>
where E: SelectableExpression<T>, DeleteStatement<T, U, ReturningClause<E>>: Query,
// 示例
let deleted_name = diesel::delete(users.filter(name.eq("Sean")))
.returning(name) // delete 也通过 returing 返回字段列表
.get_result(connection);
assert_eq!(Ok("Sean".to_string()), deleted_name);
let deleted_rows = diesel::delete(users)
.filter(name.eq("Sean"))
.execute(connection);
assert_eq!(Ok(1), deleted_rows);
let expected_names = vec!["Tess".to_string()];
let names = users.select(name).load(connection);
assert_eq!(Ok(expected_names), names);
let deleted_rows = diesel::delete(users)
.filter(name.eq("Sean"))
.or_filter(name.eq("Tess"))
.execute(connection);
assert_eq!(Ok(2), deleted_rows);
let num_users = users.count().first(connection);
assert_eq!(Ok(0), num_users);
insert_into() #
diesel::insert_into() 或 diesel::dsl::insert_into() 函数:
- 返回的对象实现了 default_values() 和 values() 方法。
- values() 方法的参数是 Insertable, table/Eq/Grouped/Vec/Option/[T;N] 均实现了它。
// target 参数类型是 table
pub fn insert_into<T: Table>(target: T) -> IncompleteInsertStatement<T>
// IncompleteInsertStatement 实现了 default_values() 和 values() 方法:
pub fn default_values(self) -> InsertStatement<T, DefaultValues, Op>
pub fn values<U>(self, records: U) -> InsertStatement<T, U::Values, Op> where U: Insertable<T>,
// table/Eq/Grouped/Vec/Option/[T;N] 均实现了 Insertable,也可以作为 values() 的参数,实现一次插入多条记录。
impl<'a, F, S, D, W, O, LOf, G, H, LC, Tab> Insertable<Tab> for &'a SelectStatement
impl<T> Insertable<T> for table
impl<T, Tab> Insertable<Tab> for Vec<T>
impl<T, Tab, V> Insertable<Tab> for Option<T>
impl<T, Tab, const N: usize> Insertable<Tab> for [T; N]
impl<T, Tab, const N: usize> Insertable<Tab> for Box<[T; N]>
如果表格所有字段都有缺省值,可以调用 default_values() 方法:
- 如果 SQL 字段可以为 NULL(没有加 NOT NULL)但没有设置 DEFAULT,则默认插入 NULL;
use schema::users::dsl::*;
insert_into(users).default_values().execute(conn)
// 等效于: INSERT INTO "users" DEFAULT VALUES -- binds: []
diesel::sql_query("CREATE TABLE users (
name VARCHAR(255) NOT NULL DEFAULT 'Sean',
hair_color VARCHAR(255) NOT NULL DEFAULT 'Green'
)").execute(connection)?;
insert_into(users) // users 是 Table
.default_values()
.execute(connection)
.unwrap();
let inserted_user = users.first(connection)?;
let expected_data = (String::from("Sean"), String::from("Green"));
assert_eq!(expected_data, inserted_user);
如果要插入指定的值, 使用 values() 方法:
- values() 方法的参数类型是
Insertable:table/&Eq/&Grouped/Vec/&[T]/tuple均实现了它,也可以使用 derive macro 来为自定义 struct 实现它。 - 插入单条记录:使用 tuple 来指定多个字段;
- 插入多条记录:使用 Vec
或 &[T], 其中 T 也可以是 tuple。 #[derive(Insertable)]修饰的 struct 类型也实现了它,所以可以传入自定义 struct 类型;
let rows_inserted = diesel::insert_into(users) // users 是 Table
.values(&name.eq("Sean")) // &Eq/&Grouped 实现了 Insertable, 插入单个字段的记录
.execute(connection);
assert_eq!(Ok(1), rows_inserted);
// tuple 也实现了 Insertable, 插入单个记录的多个字段
let new_user = (id.eq(1), name.eq("Sean"));
let rows_inserted = diesel::insert_into(users)
.values(&new_user)
.execute(connection);
assert_eq!(Ok(1), rows_inserted);
// Vec 也实现了 Insertable,可以一次插入多个记录,每个记录的类型可以是:
// 1. Eq/Grouped: 插入单个字段
let new_users = vec![
name.eq("Tess"),
name.eq("Jim"),
];
let rows_inserted = diesel::insert_into(users)
.values(&new_users)
.execute(connection);
assert_eq!(Ok(2), rows_inserted);
// 2. tuple:插入多个字段
let new_users = vec![
(id.eq(2), name.eq("Tess")),
(id.eq(3), name.eq("Jim")),
];
let rows_inserted = diesel::insert_into(users)
.values(&new_users)
.execute(connection);
assert_eq!(Ok(2), rows_inserted);
// Insertable struct 可以作为 values() 的参数, 实现一次更新多个字段值
#[derive(Insertable)]
#[diesel(table_name = users)]
struct NewUser<'a> {
name: &'a str,
}
// Insert one record at a time
let new_user = NewUser { name: "Ruby Rhod" };
diesel::insert_into(users)
.values(&new_user)
.execute(connection)
.unwrap();
// Insert many records
let new_users = vec![
NewUser { name: "Leeloo Multipass" },
NewUser { name: "Korben Dallas" },
];
let inserted_names = diesel::insert_into(users)
.values(&new_users)
.execute(connection)
.unwrap();
插入列的缺省值:
- SQL 字段类型没有明确设置 NOT NULL 时,生成的 table!() 字段是
Nullable<T>, 对应的 Rust struct model 字段值应该设置为Option<T>:当将它设置为 None 时,diesel 插入缺省值;- 如果 SQL schema 没有通过 DEFAULT 来设置缺省值且也没有设置 NOT NULL, 则缺省值为 NULL;
- 如果 SQL schema 设置了 DEFAULT,则使用对应的缺省值;
// The column color in brands table is NOT NULL DEFAULT 'Green'.
#[derive(Insertable)]
#[diesel(table_name = brands)]
struct NewBrand {
color: Option<String>, // 字段类型为 Option<T> 时,如果设置为 None,则 diesel 插入 T 缺省值。
}
// 插入传入的值
let new_brand = NewBrand { color: Some("Red".into()) };
// 插入缺省值
let new_brand = NewBrand { color: None }; // 设置为 None
diesel::insert_into(brands)
.values(&new_brand)
.execute(connection)
.unwrap();
对于可以为 NULL 的列插入缺省值或 NULL 值:
- 可以为 NULL 的列需要使用 Option<Option
> 类型值; - 如果插入 None,则使用缺省值;
- 如果插入 Some(None) 则使用 NULL 值;
- 如果插入 Some(Some(T)) 则插入 T 值;
#[derive(Insertable)]
#[diesel(table_name = brands)]
struct NewBrand {
accent: Option<Option<String>>,
}
// Insert `Red`
let new_brand = NewBrand { accent: Some(Some("Red".into())) };
diesel::insert_into(brands)
.values(&new_brand)
.execute(connection)
.unwrap();
// Insert the default accent
let new_brand = NewBrand { accent: None };
diesel::insert_into(brands)
.values(&new_brand)
.execute(connection)
.unwrap();
// Insert `NULL`
let new_brand = NewBrand { accent: Some(None) };
diesel::insert_into(brands)
.values(&new_brand)
.execute(connection)
.unwrap();
插入 select 的值:使用 into_columns() 来指定 select 出来的各列应该插入到表的哪些列;
let new_posts = users::table
.select((
users::name.concat("'s First Post"),
users::id,
));
diesel::insert_into(posts::table)
.values(new_posts)
.into_columns((posts::title, posts::user_id)) // values() 的列值应该插入到本表的那些列?
.execute(conn)?;
let inserted_posts = posts::table
.select(posts::title)
.load::<String>(conn)?;
let expected = vec!["Sean's First Post", "Tess's First Post"];
assert_eq!(expected, inserted_posts);
InsertStatement #
default_values()/values() 返回的类型是 Struct diesel::query_builder::InsertStatement:
- 方法:into_columns()/returning()/on_conflict_do_nothing()/on_conflict();
pub fn new(target: T, records: U, operator: Op, returning: Ret) -> Self
// 子查询插入方式
pub fn into_columns<C2>( self, columns: C2, ) -> InsertStatement
// 返回插入成功的记录的字段(如 id)
pub fn returning<E>( self, returns: E,) -> InsertStatement
// 冲突检测
pub fn on_conflict_do_nothing( self, ) -> InsertStatement
pub fn on_conflict<Target>( self, target: Target, ) -> IncompleteOnConflict
// 实现了 ExecuteDsl 和 RunQueryDsl,执行实际的 SQL 操作。
impl<V, T, QId, C, Op, O, const STATIC_QUERY_ID: bool> ExecuteDsl<C, Sqlite> for InsertStatement
impl<T: QuerySource, U, Op, Ret, Conn> RunQueryDsl<Conn> for InsertStatement
impl<T: Copy + QuerySource, U: Copy, Op: Copy, Ret: Copy> Copy for InsertStatement
on_conflict_do_nothing():
let user = User { id: 1, name: "Sean" };
let user_count = users.count().get_result::<i64>(conn)?;
assert_eq!(user_count, 0);
diesel::insert_into(users)
.values(&user)
.on_conflict_do_nothing() // 冲突时什么多不做,不实际插入
.execute(conn)?;
let user_count = users.count().get_result::<i64>(conn)?;
assert_eq!(user_count, 1);
// 插入一个 vec,可能只插入一部分记录。
let user = User { id: 1, name: "Sean" };
let inserted_row_count = diesel::insert_into(users)
.values(&vec![user, user])
.on_conflict_do_nothing()
.execute(conn)?;
let user_count = users.count().get_result::<i64>(conn)?;
assert_eq!(user_count, 1); // 1 条
on_conflict() 指定冲突检测的字段列表:
// 单列冲突:只有 sqlite 和 postgres 支持
use diesel::upsert::*;
diesel::sql_query("CREATE UNIQUE INDEX users_name ON users (name)").execute(conn).unwrap();
let user = User { id: 1, name: "Sean" };
let same_name_different_id = User { id: 2, name: "Sean" };
let same_id_different_name = User { id: 1, name: "Pascal" };
assert_eq!(Ok(1), diesel::insert_into(users).values(&user).execute(conn));
let query = diesel::insert_into(users)
.values(&same_id_different_name)
.on_conflict(id)
.do_nothing()
.execute(conn)?;
// 多列冲突: 只有 sqlite 和 postgres 支持
use diesel::upsert::*;
diesel::sql_query("CREATE UNIQUE INDEX users_name_hair_color ON users (name, hair_color)").execute(conn).unwrap();
let user = User { id: 1, name: "Sean", hair_color: "black" };
let same_name_different_hair_color = User { id: 2, name: "Sean", hair_color: "brown" };
let same_name_same_hair_color = User { id: 3, name: "Sean", hair_color: "black" };
assert_eq!(Ok(1), diesel::insert_into(users).values(&user).execute(conn));
let inserted_row_count = diesel::insert_into(users)
.values(&same_name_different_hair_color)
.on_conflict((name, hair_color))
.do_nothing()
.execute(conn);
assert_eq!(Ok(1), inserted_row_count);
let inserted_row_count = diesel::insert_into(users)
.values(&same_name_same_hair_color)
.on_conflict((name, hair_color))
.do_nothing()
.execute(conn);
assert_eq!(Ok(0), inserted_row_count);
#[cfg(feature = "mysql")]
fn main() {}
// 对于 mysql,只支持所有 KEY 的冲突,而不能指定具体的 KEY
use diesel::upsert::*;
diesel::sql_query("CREATE UNIQUE INDEX users_name ON users (name)").execute(conn).unwrap();
let user = User { id: 1, name: "Sean" };
let same_name_different_id = User { id: 2, name: "Sean" };
let same_id_different_name = User { id: 1, name: "Pascal" };
assert_eq!(Ok(1), diesel::insert_into(users).values(&user).execute(conn));
let user_names = users.select(name).load::<String>(conn)?;
assert_eq!(user_names, vec![String::from("Sean")]);
let query = diesel::insert_into(users)
.values(&same_id_different_name)
.on_conflict(diesel::dsl::DuplicatedKeys)
.do_nothing()
.execute(conn)?;
let user_names = users.select(name).load::<String>(conn)?;
assert_eq!(user_names, vec![String::from("Sean")]);
let idx_conflict_result = diesel::insert_into(users)
.values(&same_name_different_id)
.on_conflict(diesel::dsl::DuplicatedKeys)
.do_nothing()
.execute(conn)?;
let user_names = users.select(name).load::<String>(conn)?;
assert_eq!(user_names, vec![String::from("Sean")]);
#[cfg(not(feature = "mysql"))]
fn run_test() -> diesel::QueryResult<()> {Ok(())}
on_conflict() 方法返回的 IncompleteOnConflict 类型提供了 do_nothing() 和 do_update() 方法:
- do_update() 返回的对象的 set() 方法的参数是
AsChangeset类型, 可以使用 derive macro 来实现, 这样可以传入自定义 struct 类型。 - Eq/Grouped<Eq<Left,Right» 和 Tuple 也实现了 AsChangeset;
pub fn do_nothing( self, ) -> InsertStatement<T, OnConflictValues<U, Target, DoNothing<T>>, Op, Ret>
pub fn do_update(self) -> IncompleteDoUpdate<Stmt, Target>
// do_update() 返回对象 IncompleteDoUpdate 提供了 set() 方法,参数是 AsChangeset 类型
pub struct IncompleteDoUpdate<Stmt, Target> { /* private fields */ }
pub fn set<Changes>( self, changes: Changes,) -> InsertStatement
// 示例
let user = User { id: 1, name: "Pascal" };
let user2 = User { id: 1, name: "Sean" };
assert_eq!(Ok(1), diesel::insert_into(users).values(&user).execute(conn));
let insert_count = diesel::insert_into(users)
.values(&user2)
.on_conflict(id)
.do_update()
.set(name.eq("I DONT KNOW ANYMORE")) // 参数是 AsChangeset 类型, Eq 实行了该 trait
.execute(conn);
assert_eq!(Ok(1), insert_count);
assert_eq!(Ok(2), insert_count);
let users_in_db = users.load(conn);
assert_eq!(Ok(vec![(1, "I DONT KNOW ANYMORE".to_string())]), users_in_db);
insert 例子:
// https://github.com/diesel-rs/diesel/blob/2.2.x/examples/mysql/all_about_inserts/src/lib.rs
// 创建 table 时,如果为指定 NOT NULL,则默认可以为 NULL
// CREATE TABLE users (
// id INTEGER PRIMARY KEY AUTO_INCREMENT,
// name TEXT NOT NULL,
// hair_color TEXT,
// created_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
// updated_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
// );
// table!() 根据 SQL table 来创建,各字段默认是 NOT NULL,但是 Nullable<T> 是可以为 NULL
mod schema {
diesel::table! {
users {
id -> Integer,
name -> Text,
hair_color -> Nullable<Text>, // 可以插入 NULL
created_at -> Timestamp,
updated_at -> Timestamp,
}
}
}
use schema::users;
// Insertable 是可以插入到 table 的结构体,可以只是部分 table 字段。
#[derive(Deserialize, Insertable)]
#[diesel(table_name = users)]
pub struct UserForm<'a> {
name: &'a str,
hair_color: Option<&'a str>, // Option<T> 表示对应的 table 字段可以是 NULL
}
#[derive(Queryable, PartialEq, Debug)]
struct User {
id: i32,
name: String,
hair_color: Option<String>,
created_at: NaiveDateTime,
updated_at: NaiveDateTime,
}
// 插入缺省值
pub fn insert_default_values(conn: &mut MysqlConnection) -> QueryResult<usize> {
use schema::users::dsl::*;
insert_into(users).default_values().execute(conn)
}
#[test]
fn examine_sql_from_insert_default_values() {
use schema::users::dsl::*;
let query = insert_into(users).default_values();
let sql = "INSERT INTO `users` () VALUES () -- binds: []";
assert_eq!(sql, debug_query::<Mysql, _>(&query).to_string());
}
// 插入单列
pub fn insert_single_column(conn: &mut MysqlConnection) -> QueryResult<usize> {
use schema::users::dsl::*;
insert_into(users).values(name.eq("Sean")).execute(conn)
}
#[test]
fn examine_sql_from_insert_single_column() {
use schema::users::dsl::*;
let query = insert_into(users).values(name.eq("Sean"));
let sql = "INSERT INTO `users` (`name`) VALUES (?) \
-- binds: [\"Sean\"]";
assert_eq!(sql, debug_query::<Mysql, _>(&query).to_string());
}
// 插入多列,多列值用 tuple 来表示
pub fn insert_multiple_columns(conn: &mut MysqlConnection) -> QueryResult<usize> {
use schema::users::dsl::*;
insert_into(users)
.values((name.eq("Tess"), hair_color.eq("Brown")))
.execute(conn)
}
#[test]
fn examine_sql_from_insert_multiple_columns() {
use schema::users::dsl::*;
let query = insert_into(users).values((name.eq("Tess"), hair_color.eq("Brown")));
let sql = "INSERT INTO `users` (`name`, `hair_color`) VALUES (?, ?) \
-- binds: [\"Tess\", \"Brown\"]";
assert_eq!(sql, debug_query::<Mysql, _>(&query).to_string());
}
// 插入 Insertable struct 结构体值,只会插入结构体中定义的字段
pub fn insert_insertable_struct(conn: &mut MysqlConnection) -> Result<(), Box<dyn Error>> {
use schema::users::dsl::*;
let json = r#"{ "name": "Sean", "hair_color": "Black" }"#;
let user_form = serde_json::from_str::<UserForm>(json)?;
insert_into(users).values(&user_form).execute(conn)?;
Ok(())
}
#[test]
fn examine_sql_from_insertable_struct() {
use schema::users::dsl::*;
let json = r#"{ "name": "Sean", "hair_color": "Black" }"#;
let user_form = serde_json::from_str::<UserForm>(json).unwrap();
let query = insert_into(users).values(&user_form);
let sql = "INSERT INTO `users` (`name`, `hair_color`) VALUES (?, ?) \
-- binds: [\"Sean\", \"Black\"]";
assert_eq!(sql, debug_query::<Mysql, _>(&query).to_string());
}
// 对于可以为 NULL 的字段,需要为 struct 对应 Option 字段传入 Option::None 值,这时 SQL 语句的
// 对应值为 DEFAULT。
pub fn insert_insertable_struct_option(conn: &mut MysqlConnection) -> Result<(), Box<dyn Error>> {
use schema::users::dsl::*;
let json = r#"{ "name": "Ruby", "hair_color": null }"#;
let user_form = serde_json::from_str::<UserForm>(json)?;
insert_into(users).values(&user_form).execute(conn)?;
Ok(())
}
#[test]
fn examine_sql_from_insertable_struct_option() {
use schema::users::dsl::*;
let json = r#"{ "name": "Ruby", "hair_color": null }"#;
let user_form = serde_json::from_str::<UserForm>(json).unwrap();
let query = insert_into(users).values(&user_form);
let sql = "INSERT INTO `users` (`name`, `hair_color`) VALUES (?, DEFAULT) \
-- binds: [\"Ruby\"]";
assert_eq!(sql, debug_query::<Mysql, _>(&query).to_string());
}
// 批量插入值:传入 Vec,每个元素为一行,元素类型可以是 single field 或 tuple
pub fn insert_single_column_batch(conn: &mut MysqlConnection) -> QueryResult<usize> {
use schema::users::dsl::*;
insert_into(users)
.values(&vec![name.eq("Sean"), name.eq("Tess")])
.execute(conn)
}
#[test]
fn examine_sql_from_insert_single_column_batch() {
use schema::users::dsl::*;
let values = vec![name.eq("Sean"), name.eq("Tess")];
let query = insert_into(users).values(&values);
let sql = "INSERT INTO `users` (`name`) VALUES (?), (?) \
-- binds: [\"Sean\", \"Tess\"]";
assert_eq!(sql, debug_query::<Mysql, _>(&query).to_string());
}
// 批量插入值:传入 Vec,但是使用 None 来插入缺省值
pub fn insert_single_column_batch_with_default(conn: &mut MysqlConnection) -> QueryResult<usize> {
use schema::users::dsl::*;
insert_into(users)
.values(&vec![Some(name.eq("Sean")), None])
.execute(conn)
}
#[test]
fn examine_sql_from_insert_single_column_batch_with_default() {
use schema::users::dsl::*;
let values = vec![Some(name.eq("Sean")), None];
let query = insert_into(users).values(&values);
let sql = "INSERT INTO `users` (`name`) VALUES (?), (DEFAULT) \
-- binds: [\"Sean\"]";
assert_eq!(sql, debug_query::<Mysql, _>(&query).to_string());
}
// 批量插入值:传入 Vec,每个元素为一行,元素类型为 tuple,实现设置多列的匹配插入
pub fn insert_tuple_batch(conn: &mut MysqlConnection) -> QueryResult<usize> {
use schema::users::dsl::*;
insert_into(users)
.values(&vec![
(name.eq("Sean"), hair_color.eq("Black")),
(name.eq("Tess"), hair_color.eq("Brown")),
])
.execute(conn)
}
#[test]
fn examine_sql_from_insert_tuple_batch() {
use schema::users::dsl::*;
let values = vec![
(name.eq("Sean"), hair_color.eq("Black")),
(name.eq("Tess"), hair_color.eq("Brown")),
];
let query = insert_into(users).values(&values);
let sql = "INSERT INTO `users` (`name`, `hair_color`) \
VALUES (?, ?), (?, ?) \
-- binds: [\"Sean\", \"Black\", \"Tess\", \"Brown\"]";
assert_eq!(sql, debug_query::<Mysql, _>(&query).to_string());
}
// 插入多行:使用 None 来为对应列指定缺省值
pub fn insert_tuple_batch_with_default(conn: &mut MysqlConnection) -> QueryResult<usize> {
use schema::users::dsl::*;
insert_into(users)
.values(&vec![
(name.eq("Sean"), Some(hair_color.eq("Black"))),
(name.eq("Ruby"), None),
])
.execute(conn)
}
#[test]
fn examine_sql_from_insert_tuple_batch_with_default() {
use schema::users::dsl::*;
let values = vec![
(name.eq("Sean"), Some(hair_color.eq("Black"))),
(name.eq("Ruby"), None),
];
let query = insert_into(users).values(&values);
let sql = "INSERT INTO `users` (`name`, `hair_color`) \
VALUES (?, ?), (?, DEFAULT) \
-- binds: [\"Sean\", \"Black\", \"Ruby\"]";
assert_eq!(sql, debug_query::<Mysql, _>(&query).to_string());
}
// 插入多行:使用 struct
pub fn insert_insertable_struct_batch(conn: &mut MysqlConnection) -> Result<(), Box<dyn Error>> {
use schema::users::dsl::*;
let json = r#"[
{ "name": "Sean", "hair_color": "Black" },
{ "name": "Tess", "hair_color": "Brown" }
]"#;
let user_form = serde_json::from_str::<Vec<UserForm>>(json)?;
insert_into(users).values(&user_form).execute(conn)?;
Ok(())
}
#[test]
fn examine_sql_from_insertable_struct_batch() {
use schema::users::dsl::*;
let json = r#"[
{ "name": "Sean", "hair_color": "Black" },
{ "name": "Tess", "hair_color": "Brown" }
]"#;
let user_form = serde_json::from_str::<Vec<UserForm>>(json).unwrap();
let query = insert_into(users).values(&user_form);
let sql = "INSERT INTO `users` (`name`, `hair_color`) \
VALUES (?, ?), (?, ?) \
-- binds: [\"Sean\", \"Black\", \"Tess\", \"Brown\"]";
assert_eq!(sql, debug_query::<Mysql, _>(&query).to_string());
}
#[test]
fn insert_get_results_batch() {
use diesel::result::Error;
let conn = &mut establish_connection();
conn.test_transaction::<_, Error, _>(|conn| {
use diesel::select;
use schema::users::dsl::*;
// 使用 select() 函数,来返回当前时间
let now = select(diesel::dsl::now).get_result::<NaiveDateTime>(conn)?;
let inserted_users = conn.transaction::<_, Error, _>(|conn| {
// 使用 Vec + tuple 来批量插入多行
let inserted_count = insert_into(users)
.values(&vec![
(id.eq(1), name.eq("Sean")),
(id.eq(2), name.eq("Tess")),
])
.execute(conn)?; // 返回受影响的行数量 usize
Ok(users
.order(id.desc())
.limit(inserted_count as i64)
.load(conn)? // 返回后续可以继续链式调用的对象
.into_iter()
.rev()
.collect::<Vec<_>>())
})?;
let expected_users = vec![
User {
id: 1,
name: "Sean".into(),
hair_color: None,
created_at: now,
updated_at: now,
},
User {
id: 2,
name: "Tess".into(),
hair_color: None,
created_at: now,
updated_at: now,
},
];
assert_eq!(expected_users, inserted_users);
Ok(())
});
}
#[test]
fn examine_sql_from_insert_get_results_batch() {
use schema::users::dsl::*;
let values = vec![(id.eq(1), name.eq("Sean")), (id.eq(2), name.eq("Tess"))];
let insert_query = insert_into(users).values(&values);
let insert_sql = "INSERT INTO `users` (`id`, `name`) VALUES (?, ?), (?, ?) \
-- binds: [1, \"Sean\", 2, \"Tess\"]";
assert_eq!(
insert_sql,
debug_query::<Mysql, _>(&insert_query).to_string()
);
// 查询语句没有指定 select() 方法时,默认返回所有列
let load_query = users.order(id.desc());
let load_sql = "SELECT `users`.`id`, `users`.`name`, \
`users`.`hair_color`, `users`.`created_at`, \
`users`.`updated_at` \
FROM `users` \
ORDER BY `users`.`id` DESC \
-- binds: []";
assert_eq!(load_sql, debug_query::<Mysql, _>(&load_query).to_string());
}
#[test]
fn insert_get_result() {
use diesel::result::Error;
let conn = &mut establish_connection();
conn.test_transaction::<_, Error, _>(|conn| {
use diesel::select;
use schema::users::dsl::*;
let now = select(diesel::dsl::now).get_result::<NaiveDateTime>(conn)?;
let inserted_user = conn.transaction::<_, Error, _>(|conn| {
insert_into(users)
.values((id.eq(3), name.eq("Ruby")))
.execute(conn)?;
// first() 返回一条记录
users.order(id.desc()).first(conn)
})?;
let expected_user = User {
id: 3,
name: "Ruby".into(),
hair_color: None,
created_at: now,
updated_at: now,
};
assert_eq!(expected_user, inserted_user);
Ok(())
});
}
#[test]
fn examine_sql_from_insert_get_result() {
use schema::users::dsl::*;
let insert_query = insert_into(users).values((id.eq(3), name.eq("Ruby")));
let insert_sql = "INSERT INTO `users` (`id`, `name`) VALUES (?, ?) -- binds: [3, \"Ruby\"]";
assert_eq!(
insert_sql,
debug_query::<Mysql, _>(&insert_query).to_string()
);
let load_query = users.order(id.desc());
let load_sql = "SELECT `users`.`id`, `users`.`name`, \
`users`.`hair_color`, `users`.`created_at`, \
`users`.`updated_at` \
FROM `users` \
ORDER BY `users`.`id` DESC \
-- binds: []";
assert_eq!(load_sql, debug_query::<Mysql, _>(&load_query).to_string());
}
pub fn explicit_returning(conn: &mut MysqlConnection) -> QueryResult<i32> {
use diesel::result::Error;
use schema::users::dsl::*;
conn.transaction::<_, Error, _>(|conn| {
insert_into(users).values(name.eq("Ruby")).execute(conn)?;
// 使用 select() 方法指定返回的字段(默认返回所有字段),值可以是 tuple 或则实现了 Selectable、
// Queryable 的对象的 as_select() 方法。
// 注:对于查询使用 select() 来指定返回字段, 对于更新、插入等使用 returning() 来指定返回字段。
users.select(id).order(id.desc()).first(conn)
})
}
#[test]
fn examine_sql_from_explicit_returning() {
use schema::users::dsl::*;
let insert_query = insert_into(users).values(name.eq("Ruby"));
let insert_sql = "INSERT INTO `users` (`name`) VALUES (?) -- binds: [\"Ruby\"]";
assert_eq!(
insert_sql,
debug_query::<Mysql, _>(&insert_query).to_string()
);
let load_query = users.select(id).order(id.desc());
let load_sql = "SELECT `users`.`id` FROM `users` ORDER BY `users`.`id` DESC -- binds: []";
assert_eq!(load_sql, debug_query::<Mysql, _>(&load_query).to_string());
}
#[cfg(test)]
fn establish_connection() -> MysqlConnection {
let url = ::std::env::var("DATABASE_URL").unwrap();
MysqlConnection::establish(&url).unwrap()
}
// https://github.com/diesel-rs/diesel/blob/2.2.x/examples/postgres/getting_started_step_2/src/models.rs
#[derive(Queryable, Selectable)]
#[diesel(table_name = posts)]
#[diesel(check_for_backend(diesel::pg::Pg))]
pub struct Post {
pub id: i32,
pub title: String,
pub body: String,
pub published: bool,
}
#[derive(Insertable)]
#[diesel(table_name = posts)]
pub struct NewPost<'a> {
pub title: &'a str,
pub body: &'a str,
}
// insert/update 等非 select 语句, 使用 returning() 来返回 struct
diesel::insert_into(posts::table)
.values(&new_post) // new_post 对应类型需要实现 Insertable
.returning(Post::as_returning())
.get_result(conn)
.expect("Error saving new post")
update() #
diesel::update() 或 diesel::dsl::update(): 传入的是 IntoUpdateTarget 类型, Identifiable/table/SelectStatement 实现了该 trait(参考 delete 部分)
// diesel::update() 或 diesel::dsl::update() 函数:
pub fn update<T: IntoUpdateTarget>( source: T,) -> UpdateStatement<T::Table, T::WhereClause>
// update() 函数返回的 UpdateStatement 实现了 set()/filter()/returning() 方法
pub fn set<V>(self, values: V) -> UpdateStatement<T, U, V::Changeset>
where
T: Table,
V: AsChangeset<Target = T>, // 传入的 values 要实现 AsChangeset,一般是 Eq/Grouped 或自定义 struct
UpdateStatement<T, U, V::Changeset>: AsQuery
pub fn filter<Predicate>(self, predicate: Predicate) -> Filter<Self, Predicate>
where Self: FilterDsl<Predicate>,impl<T: QuerySource, U, V, Ret> UpdateStatement<T, U, V, Ret>
pub fn returning<E>(self, returns: E,) -> UpdateStatement<T, U, V, ReturningClause<E>>
where
T: Table,
UpdateStatement<T, U, V, ReturningClause<E>>: Query,
set() 的参数是 Trait diesel::query_builder::AsChangeset 类型:
- 可以被 derived macro 生成,这样可以使用自定义 struct 来作为 set() 参数;
- Eq 和 Grouped 实现了 AsChangeset;
- 如果要设置多个值,可以使用 tuple。
pub trait AsChangeset {
type Target: QuerySource;
type Changeset;
// Required method
fn as_changeset(self) -> Self::Changeset;
}
impl<T: AsChangeset> AsChangeset for Option<T>
// https://docs.diesel.rs/2.2.x/src/diesel/query_builder/update_statement/changeset.rs.html#41
//
// Eq 和 Grouped 也实现了 AsChangeset
impl<Left, Right> AsChangeset for Eq<Left, Right>
impl<Left, Right> AsChangeset for Grouped<Eq<Left, Right>>
UpdateStatement #
update 例子:
// table users 实现了 IntoUpdateTarget
let updated_rows = diesel::update(users)
.set(name.eq("Jim")) // Eq 实现了 AsChangeset
.filter(name.eq("Sean")) // 限制 update 的范围
.execute(connection);
assert_eq!(Ok(1), updated_rows);
// SelectStatement 也实现了 IntoUpdateTarget, 而且可以限制 update 范围
let updated_name = diesel::update(users.filter(id.eq(1)))
.set(name.eq("Dean")) // Eq 实现了 AsChangeset
.returning(name)
.get_result(connection);
assert_eq!(Ok("Dean".to_string()), updated_name);
let post = diesel::update(posts.find(id))
.set(published.eq(true))
.returning(Post::as_returning())
.get_result(connection)
.unwrap();
println!("Published post {}", post.title);
// Identifiable struct 也实现了 IntoUpdateTarget(可以作为 updat() 的参数),
// AsChangeset struct 可以作为 set() 方法的参数。
#[derive(Queryable, Identifiable, AsChangeset)]
#[diesel(table_name = posts)]
pub struct Post {
pub id: i64,
pub title: String,
pub body: String,
pub draft: bool,
pub publish_at: SystemTime,
pub visit_count: i32,
}
// post 是上面的实现了 Identifiable 的 Post 类型值, 必须要设置 id 字段。
// post 可以同时作为 upadate() 函数和 set() 方法的参数:
diesel::update(post)
.set(posts::draft.eq(false))
.execute(conn)
// post 是上面的实现了 Identifiable 的 Post 类型值, 必须要设置 id 字段
update(post)
// 等效于
update(posts.find(post.id))
// 或
update(posts.filter(id.eq(post.id)))
// 更新单个字段
diesel::update(posts)
.set(visit_count.eq(visit_count + 1))
.execute(conn)
// 更新单个记录的多个字段值, 可以使用 tuple
diesel::update(posts)
.set((
title.eq("[REDACTED]"),
body.eq("This post has been classified"),
))
.execute(conn)
// 通过实现 AsChangetset, 更新多个字段时, 可以传入 post struct 值类型
diesel::update(posts::table).set(post).execute(conn)
#[derive(AsChangeset)]
#[diesel(table_name = posts)]
// #[diesel(treat_none_as_null = true)] // 将 None 设置为 NULL
struct PostForm<'a> {
title: Option<&'a str>, // 可选字段
body: Option<&'a str>,
}
diesel::update(posts::table)
.set(&PostForm {
title: None, // None 表示不设置该字段
body: Some("My new post"),
})
.execute(conn)
// 等效于: UPDATE "posts" SET "body" = $1 -- binds: ["My new post"]
另一个例子:
// https://github.com/diesel-rs/diesel/blob/2.2.x/examples/postgres/all_about_updates/src/lib.rs
use std::time::SystemTime;
#[cfg(test)]
use diesel::debug_query;
#[cfg(test)]
use diesel::pg::Pg;
use diesel::prelude::*;
table! {
posts {
id -> BigInt,
title -> Text,
body -> Text,
draft -> Bool,
publish_at -> Timestamp,
visit_count -> Integer,
}
}
// 实现了 Identifiable 后,可以作为 update() 的参数值(必须指定主键 id 字段)
#[derive(Queryable, Identifiable, AsChangeset)]
pub struct Post {
pub id: i64,
pub title: String,
pub body: String,
pub draft: bool,
pub publish_at: SystemTime,
pub visit_count: i32,
}
// 实现 AsChangeset 的 struct 可以作为 set() 的参数值
#[derive(AsChangeset)]
#[diesel(table_name = posts)]
struct PostForm<'a> {
title: Option<&'a str>,
body: Option<&'a str>,
}
pub fn publish_all_posts(conn: &mut PgConnection) -> QueryResult<usize> {
use crate::posts::dsl::*;
// posts 是 table,可以作为 update() 参数值
// Eq/Grouped 实现了 Aschangeset,可以作为 set() 的参数值
diesel::update(posts).set(draft.eq(false)).execute(conn)
}
#[test]
fn examine_sql_from_publish_all_posts() {
use crate::posts::dsl::*;
assert_eq!(
"UPDATE \"posts\" SET \"draft\" = $1 -- binds: [false]",
debug_query(&diesel::update(posts).set(draft.eq(false))).to_string()
);
}
// filter() 方法对更新范围做限制,
// 也可以通过给 update() 传入 table select 来限制范围
pub fn publish_pending_posts(conn: &mut PgConnection) -> QueryResult<usize> {
use crate::posts::dsl::*;
use diesel::dsl::now;
diesel::update(posts)
.filter(publish_at.lt(now))
.set(draft.eq(false))
.execute(conn)
}
#[test]
fn examine_sql_from_publish_pending_posts() {
use crate::posts::dsl::*;
use diesel::dsl::now;
let query = diesel::update(posts)
.filter(publish_at.lt(now))
.set(draft.eq(false));
assert_eq!(
"UPDATE \"posts\" SET \"draft\" = $1 \
WHERE (\"posts\".\"publish_at\" < CURRENT_TIMESTAMP) \
-- binds: [false]",
debug_query(&query).to_string()
);
}
// post 是实现 Identifiable 的 Post 类型,可以作为 update() 参数,且必须指定主键 id 字段
pub fn publish_post(post: &Post, conn: &mut PgConnection) -> QueryResult<usize> {
diesel::update(post)
.set(posts::draft.eq(false))
.execute(conn)
}
#[test]
fn examine_sql_from_publish_post() {
let post = Post {
id: 1,
title: "".into(),
body: "".into(),
draft: false,
publish_at: SystemTime::now(),
visit_count: 0,
};
// 可见,更新过滤时只使用了 post.id 字段值。
assert_eq!(
"UPDATE \"posts\" SET \"draft\" = $1 WHERE (\"posts\".\"id\" = $2) \
-- binds: [false, 1]",
debug_query(&diesel::update(&post).set(posts::draft.eq(false))).to_string()
);
}
pub fn increment_visit_counts(conn: &mut PgConnection) -> QueryResult<usize> {
use crate::posts::dsl::*;
diesel::update(posts)
.set(visit_count.eq(visit_count + 1))
.execute(conn)
}
#[test]
fn examine_sql_from_increment_visit_counts() {
use crate::posts::dsl::*;
assert_eq!(
"UPDATE \"posts\" SET \"visit_count\" = (\"posts\".\"visit_count\" + $1) \
-- binds: [1]",
debug_query::<Pg, _>(&diesel::update(posts).set(visit_count.eq(visit_count + 1)))
.to_string()
);
}
// 一次更新多个字段值:使用 tuple
pub fn hide_everything(conn: &mut PgConnection) -> QueryResult<usize> {
use crate::posts::dsl::*;
diesel::update(posts)
.set((
title.eq("[REDACTED]"),
body.eq("This post has been classified"),
))
.execute(conn)
}
#[test]
fn examine_sql_from_hide_everything() {
use crate::posts::dsl::*;
let query = diesel::update(posts).set((
title.eq("[REDACTED]"),
body.eq("This post has been classified"),
));
assert_eq!(
"UPDATE \"posts\" SET \"title\" = $1, \"body\" = $2 \
-- binds: [\"[REDACTED]\", \"This post has been classified\"]",
debug_query::<Pg, _>(&query).to_string()
);
}
// Post 实现了 AsChangeset,故可以作为 set() 方法的参数(忽略主键 id)
pub fn update_from_post_fields(post: &Post, conn: &mut PgConnection) -> QueryResult<usize> {
diesel::update(posts::table).set(post).execute(conn)
}
// 可见 update 时忽略设置传入的 post.id
#[test]
fn examine_sql_from_update_post_fields() {
let now = SystemTime::now();
let post = Post {
id: 1,
title: "".into(),
body: "".into(),
draft: false,
publish_at: now,
visit_count: 0,
};
let sql = format!(
"UPDATE \"posts\" SET \
\"title\" = $1, \
\"body\" = $2, \
\"draft\" = $3, \
\"publish_at\" = $4, \
\"visit_count\" = $5 \
-- binds: [\
\"\", \
\"\", \
false, \
{now:?}, \
0\
]"
);
assert_eq!(
sql,
debug_query(&diesel::update(posts::table).set(&post)).to_string()
);
}
// PostForm 实现了 AsChangeset,可以作为 set() 的参数:
pub fn update_with_option(conn: &mut PgConnection) -> QueryResult<usize> {
diesel::update(posts::table)
.set(&PostForm {
title: None,
body: Some("My new post"),
})
.execute(conn)
}
#[test]
fn examine_sql_from_update_with_option() {
#[derive(AsChangeset)]
#[diesel(table_name = posts)]
struct PostForm<'a> {
title: Option<&'a str>,
body: Option<&'a str>,
}
let post_form = PostForm {
title: None,
body: Some("My new post"),
};
let query = diesel::update(posts::table).set(&post_form);
assert_eq!(
"UPDATE \"posts\" SET \"body\" = $1 \
-- binds: [\"My new post\"]",
debug_query::<Pg, _>(&query).to_string()
);
}
update:
- 对于 delete/update, 除了可以使用 table field 来过滤外, 还可以使用实现了 Identifiable 的 struct 来实现 delete 和 update.
let post = connection
.transaction(|connection| {
// first() 没有跟 optional() 表示肯定可以查到一个匹配的 id 记录
// ? 表示查询出错或查不到 id 记录
let post = posts.find(id).select(Post::as_select()).first(connection)?;
// update 使用 posts.find() 来限制更新范围
diesel::update(posts.find(id))
.set(published.eq(true))
.execute(connection)?;
Ok(post)
})
.unwrap_or_else(|_: diesel::result::Error| panic!("Unable to find post {}", id));
println!("Published post {}", post.title);
sql_query() 和 sql() #
diesel::sql_query() 或 diesel::dsl::sql_query() 使用 raw SQL 来构造完整的查询:
- 使用 SqlQuery::bind() 方法来设置占位参数值。
// 返回的 SqlQuery 对象实现了 bind()/sql() 方法:
pub fn sql_query<T: Into<String>>(query: T) -> SqlQuery
pub fn bind<ST, Value>(self, value: Value) -> UncheckedBind<Self, Value, ST>
// Appends a piece of SQL code at the end.
pub fn sql<T: AsRef<str>>(self, sql: T) -> Self
// 示例
let users = sql_query("SELECT * FROM users ORDER BY id").load(connection);
let expected_users = vec![
User { id: 1, name: "Sean".into() },
User { id: 2, name: "Tess".into() },
];
assert_eq!(Ok(expected_users), users);
let users = sql_query("SELECT * FROM users WHERE id > ? AND name <> ?");
let users = users
.bind::<Integer, _>(1) // 绑定两个位置参数
.bind::<Text, _>("Tess")
.get_results(connection);
let expected_users = vec![
User { id: 3, name: "Jim".into() },
];
assert_eq!(Ok(expected_users), users);
// sql_query 查询的结果也可以反序列化到 struct model
let complex_result = diesel::sql_query("
SELECT u.*, COUNT(p.id) as post_count
FROM users u
LEFT JOIN posts p ON u.id = p.user_id
GROUP BY u.id
HAVING COUNT(p.id) > 5
")
.load::<ComplexUserResult>(conn)?;
如果部分使用 raw SQL,则可以用 diesel::dsl::sql():
// https://github.com/atanmarko/rust-diesel-examples/blob/main/src/main.rs
// Get average mark of every student
// select s.first_name as student_name, s.last_name as student_surname,
// avg(g.grade) from public.students as s, public.grades as g
// where s.id=g.student
// group by s.first_name, s.last_name;
//
// group_by support is missing in Diesel 1.x https://github.com/diesel-rs/diesel/issues/210
let result = students
.inner_join(grades)
.select((
schema::students::columns::first_name,
schema::students::columns::last_name,
sql::<Double>("avg(grades.grade) AS grade"),
))
.filter(diesel::dsl::sql( "true group by students.first_name, students.last_name", ))
.load::<(String, String, f64)>(&conn)?;
println!("Average student mark: \n {:#?}\n\n", result);
// Use raw sql in queries
let result = students
.select((
sql::<Uuid>("id as Identification"),
sql::<Text>("first_name as Name"),
sql::<Int8>("age*2 as DoubleAge"),
))
.load::<(uuid::Uuid, String, i64)>(&conn)?;
println!("Custom sql:\n {:#?}\n\n", result);
define_sql_function!() #
https://docs.diesel.rs/master/diesel/prelude/macro.define_sql_function.html
https://diesel.rs/guides/composing-applications.html
Declare a sql function for use in your code.
Diesel only provides support for a very small number of SQL functions. This macro enables you to
add additional functions from the SQL standard, as well as any custom functions your application
might have.
The syntax for this macro is very similar to that of a normal Rust function, except the argument
and return types will be the SQL types being used. Typically, these types will come from
diesel::sql_types
This macro will generate two items. A function with the name that you’ve given, and a module with a helper type representing the return type of your function. For example, this invocation:
define_sql_function!(fn lower(x: Text) -> Text);
will generate this code:
// 同名函数
pub fn lower<X>(x: X) -> lower<X> {
...
}
// 函数返回值类型
pub type lower<X> = ...;
Most attributes given to this macro will be put on the generated function (including doc comments).
Adding Doc Comments
use diesel::sql_types::Text;
// 函数输入输出类型来源于 diesel::sql_types
define_sql_function! {
/// Represents the `canon_crate_name` SQL function, created in
/// migration ....
fn canon_crate_name(a: Text) -> Text;
}
let target_name = "diesel";
crates.filter(canon_crate_name(name).eq(canon_crate_name(target_name)));
// This will generate the following SQL
// SELECT * FROM crates WHERE canon_crate_name(crates.name) = canon_crate_name($1)
Special Attributes
There are a handful of special attributes that Diesel will recognize. They are:
-
#[aggregate]Indicates that this is an aggregate function, and that NonAggregate shouldn’t be implemented.
-
#[sql_name = "name"]The SQL to be generated is different from the Rust name of the function. This can be used to represent functions which can take many argument types, or to capitalize function names.
Functions can also be generic. Take the definition of sum, for example:
use diesel::sql_types::Foldable;
define_sql_function! {
#[aggregate]
#[sql_name = "SUM"]
fn sum<ST: Foldable>(expr: ST) -> ST::Sum;
}
crates.select(sum(id));
SQL Functions without Arguments
A common example is ordering a query using the RANDOM() sql function, which can be implemented using define_sql_function! like this:
define_sql_function!(fn random() -> Text);
crates.order(random());
Use with SQLite
On most backends, the implementation of the function is defined in a migration using CREATE FUNCTION. On SQLite, the function is implemented in Rust instead. You must call register_impl or
register_nondeterministic_impl (in the generated function’s _utils module) with every connection
before you can use the function.
These functions will only be generated if the sqlite feature is enabled, and the function is not
generic. SQLite doesn’t support generic functions and variadic functions.
use diesel::sql_types::{Integer, Double};
define_sql_function!(fn add_mul(x: Integer, y: Integer, z: Double) -> Double);
let connection = &mut SqliteConnection::establish(":memory:")?;
add_mul_utils::register_impl(connection, |x: i32, y: i32, z: f64| {
(x + y) as f64 * z
})?;
let result = select(add_mul(1, 2, 1.5)).get_result::<f64>(connection)?;
assert_eq!(4.5, result);
Panics
If an implementation of the custom function panics and unwinding is enabled, the panic is caught and the function returns to libsqlite with an error. It can’t propagate the panics due to the FFI boundary.
This is the same for custom aggregate functions.
Custom Aggregate Functions
Custom aggregate functions can be created in SQLite by adding an #[aggregate] attribute inside
define_sql_function. register_impl (in the generated function’s _utils module) needs to be called
with a type implementing the SqliteAggregateFunction trait as a type parameter as shown in the
examples below.
use diesel::sql_types::Integer;
use diesel::sqlite::SqliteAggregateFunction;
define_sql_function! {
#[aggregate]
fn my_sum(x: Integer) -> Integer;
}
#[derive(Default)]
struct MySum { sum: i32 }
impl SqliteAggregateFunction<i32> for MySum {
type Output = i32;
fn step(&mut self, expr: i32) {
self.sum += expr;
}
fn finalize(aggregator: Option<Self>) -> Self::Output {
aggregator.map(|a| a.sum).unwrap_or_default()
}
}
fn run() -> Result<(), Box<dyn (::std::error::Error)>> {
let connection = &mut SqliteConnection::establish(":memory:")?;
my_sum_utils::register_impl::<MySum, _>(connection)?;
let total_score = players.select(my_sum(score))
.get_result::<i32>(connection)?;
println!("The total score of all the players is: {}", total_score);
Ok(())
}
With multiple function arguments, the arguments are passed as a tuple to SqliteAggregateFunction
use diesel::sql_types::{Float, Nullable};
use diesel::sqlite::SqliteAggregateFunction;
define_sql_function! {
#[aggregate]
fn range_max(x0: Float, x1: Float) -> Nullable<Float>;
}
#[derive(Default)]
struct RangeMax<T> { max_value: Option<T> }
impl<T: Default + PartialOrd + Copy + Clone> SqliteAggregateFunction<(T, T)> for RangeMax<T> {
type Output = Option<T>;
fn step(&mut self, (x0, x1): (T, T)) {
// Compare self.max_value to x0 and x1
}
fn finalize(aggregator: Option<Self>) -> Self::Output {
aggregator?.max_value
}
}
fn run() -> Result<(), Box<dyn (::std::error::Error)>> {
let connection = &mut SqliteConnection::establish(":memory:")?;
range_max_utils::register_impl::<RangeMax<f32>, _, _>(connection)?;
let result = student_avgs.select(range_max(s1_avg, s2_avg))
.get_result::<Option<f32>>(connection)?;
if let Some(max_semester_avg) = result {
println!("The largest semester average is: {}", max_semester_avg);
}
Ok(())
}
r2d2 连接池 #
use diesel::pg::PgConnection;
use diesel::r2d2::{self, ConnectionManager};
type Pool = r2d2::Pool<ConnectionManager<PgConnection>>;
let manager = ConnectionManager::<PgConnection>::new(DATABASE_URL);
let pool = Pool::builder()
.max_size(15)
.build(manager)
.expect("Failed to create pool.");
事务 #
conn.transaction(|conn| {
diesel::insert_into(users)
.values(&new_user)
.execute(conn)?;
diesel::insert_into(posts)
.values(&new_post)
.execute(conn)
})
实践案例 #
- 查询场景:定义一个 struct model,它实现了 Queryable, Selectable trait,可以用于 select() 和 returning() 和 RunQueryDsl 的返回值类型:
- 实现了 Queryable 后:可以作为 RunQueryDsl 各方法 get_result/get_results/first() 的返回值类型,如 first::
(), 要求Queryable 的 struct 解构和字段顺序必须与 table 完全匹配(具体可以参考 src/schema.rs 中的table!() 宏对表的定义); - 实现了 Selectable 后: value 可以作为 select(value.as_select()) 或 returning(value.as_returning()) 的参数,用于指定要返回的值类型;
- 实现了 Queryable 后:可以作为 RunQueryDsl 各方法 get_result/get_results/first() 的返回值类型,如 first::
- 插入场景:定义一个 struct model,它实现了 Insertable trait,可以用于 insert 和 update:
// 代表可查询的结构体(Queyable 可以是部分字段,Selectable 是完整字段)
#[derive(Queryable)]
struct User {
id: i32,
name: String,
age: i32,
hair_color: Option<&'a str>, // Option<T> 代表可以是 NULL 的可选字段
}
// 代表可插入的结构体(可以是部分 table 字段)
#[derive(Insertable)]
#[table_name = "users"]
struct NewUser {
name: String,
age: i32,
}
// 插入
let new_user = NewUser {
name: "John Doe",
age: 30,
};
insert_into(users).values(&new_user).execute(&connection)?;
// 查询
let results = users.load<User>(&connection)?;
let results = users.filter(age.gt(21)).load<User>(&connection)?;
// 更新
let target = users.filter(name.eq("John Doe"));
update(target).set(name.eq("Jonathan Doe")).execute(&connection)?;
// 删除
delete(users.filter(name.eq("Jonathan Doe"))).execute(&connection)?;
// 使用 Query builder 来构建复杂查询
let complex_query = users
.filter(name.like("%Doe%"))
.filter(age.between(18, 30))
.order(age.desc())
.limit(5)
.load<User>(&connection)?;
// join 和子查询
let data = users::table
.inner_join(posts::table)
.select((users::name, posts::title))
.filter(posts::published.eq(true))
.load<(&str, &str)>(&connection)?;
// 自定义 sql function
sql_function!(fn lower(x: diesel::sql_types::Text) -> diesel::sql_types::Text);
let lower_case_names = users
.select(lower(users::name))
.load<String>(&connection)?;
// 测试
#[cfg(test)]
mod tests {
use super::*;
use diesel::prelude::*;
use diesel::connection::Connection;
fn establish_connection() -> PgConnection {
let database_url = std::env::var("TEST_DATABASE_URL")
.expect("TEST_DATABASE_URL must be set");
PgConnection::establish(&database_url)
.expect("Error connecting to test database")
}
}
#[test]
fn test_user_creation() {
let conn = establish_connection();
let new_user = NewUser { name: "Test User", age: 25 };
let result = create_user(&conn, &new_user);
assert!(result.is_ok());
}
query:
// https://github.com/diesel-rs/diesel/blob/2.2.x/examples/mysql/getting_started_step_1/src/lib.rs
#[derive(Queryable, Selectable)]
#[diesel(table_name = crate::schema::posts)]
#[diesel(check_for_backend(diesel::mysql::Mysql))]
pub struct Post {
pub id: i32,
pub title: String,
pub body: String,
pub published: bool,
}
// results 是一个 Vec<T>,T 类型是 select() 的参数类型 Post
let results = posts
.filter(published.eq(true))
.limit(5)
.select(Post::as_select()) // 使用 Selectable struct 来指定返回字段和结构类型
.load(connection)
.expect("Error loading posts");
println!("Displaying {} posts", results.len());
for post in results {
println!("{}", post.title);
println!("-----------\n");
println!("{}", post.body);
}
posts::table
.order(posts::id.desc()) // 排序
.select(Post::as_select()) // 返回值
.first(conn) // 返回一个对象
let post = posts
.find(post_id) // find 需要传入 PK 值
.select(Post::as_select())
.first(connection) // 返回 Post 类型,由于可能查不到,所以需要进一步调用 optional() 方法
.optional(); // This allows for returning an Option<Post>, otherwise it will throw an error
match post {
Ok(Some(post)) => println!("Post with id: {} has a title: {}", post.id, post.title),
Ok(None) => println!("Unable to find post {}", post_id),
Err(_) => println!("An error occurred while fetching post {}", post_id),
}