eBPF 是当今热门的底层技术,在网络、安全、可观测性、云原生等场景得到广泛应用。
本文档先介绍 Linux 内核的各种追踪技术,让大家对于各种事件源、内核各种追踪框架、用户工具等有个初步了解,然后介绍 eBPF 的发展历程、开发和执行流程、开发框架选择和 Demo 示例,希望对于想了解 Linux 内核追踪和 eBPF 技术的同学有所帮助。
1 一、基础: Linux 内核追踪技术简介 #
Linux 追踪是对运行中的内核和应用程序进行稳定性、性能分析和诊断的技术,它经历了长期的发展演进,逐渐形成了适用于不同场景的多种追踪框架。
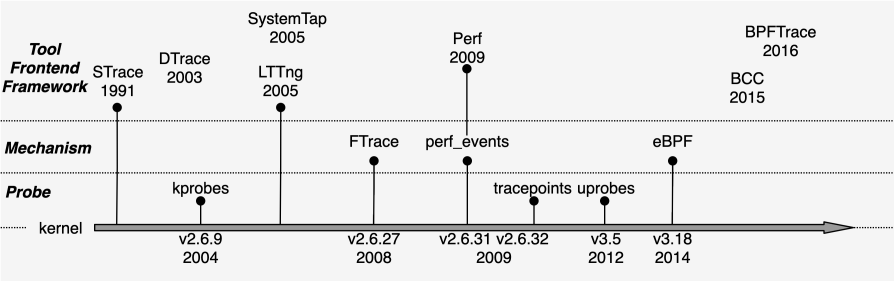
图来源:https://lawrencezx.github.io/blogs/2022-3-Linux-Dynamic-Tracing.html
内核追踪分为三个层次:
- 数据源(Event Sources):各种内核或用户程序定义的探针 (kprobe/uprobe)、追踪点(tracepoint)、硬件和软件事件(events)等;
- 追踪框架(Tracing Frameworks):从各数据源收集、加工和传递数据的内核框架,如 eBPF/SystemTap 等;
- 前端框架(Front-End Frameworks):开发用户端自定义或性能追踪工具的框架,如 bcc/bpftrace/libbpf 等;


1.1 事件源 #
事件源(Event Sources)代表了系统的可观测能力(Observability)的范围,包括由各种内核或用户程序定义的探针(kprobe/uprobe)、追踪点(tracepoint)、硬件和软件事件(events)等。
动态追踪:
- kprobes: 是内核空间函数的动态追踪技术,可以在内核函数任意位置插桩,执行用户指定的钩子函数;
- uprobes: 是用户空间函数的动态追踪技术,可以在函数入口、特定偏移处以及函数返回处进行插桩;
静态追踪:
- tracepoints: 是内核空间函数的预定义静态追踪技术,由内核开发者定义的稳定插桩点。相比 kprobes 更稳定,不会随着内核版本升级、函数名或地址的改变而失效。
- USDT(User-level Statically Defined Tracing): 是用户空间函数的预定义静态追踪技术,由用户程序开发者在程序的关键位置定义的稳定插桩点,用于对程序进行调试、性能观测等功能。
硬件事件(PMU,Performance Monitoring Unit):是 CPU 等硬件提供的性能监控单元,用于统计系统中发生的特定硬件事件,例如缓存未命中(Cache Miss)或者分支预测错误(Branch Misprediction)等。
静态追踪 tracepoint 示例:内核开发者使用 TRACE_EVENT 宏来静态定义稳定的插桩点:
/*
* Tracepoint for kernel_clone:
*/
TRACE_EVENT(sched_process_fork,
TP_PROTO(struct task_struct *parent, struct task_struct *child),
TP_ARGS(parent, child),
TP_STRUCT__entry(
__array( char, parent_comm, TASK_COMM_LEN )
__field( pid_t, parent_pid )
__array( char, child_comm, TASK_COMM_LEN )
__field( pid_t, child_pid )
),
TP_fast_assign(
memcpy(__entry->parent_comm, parent->comm, TASK_COMM_LEN);
__entry->parent_pid = parent->pid;
memcpy(__entry->child_comm, child->comm, TASK_COMM_LEN);
__entry->child_pid = child->pid;
),
TP_printk("comm=%s pid=%d child_comm=%s child_pid=%d",
__entry->parent_comm, __entry->parent_pid,
__entry->child_comm, __entry->child_pid)
);
1.2 追踪框架 #
有了数据源后,这些数据如何被传递、加工和使用,就是内核中的各种追踪框架要完成的功能。
内核追踪框架经过长期发展,逐渐形成了不同的技术体系和用户工具,它们的功能和实现存在交集,例如 eBPF 也支持 perf_events 接口,perf 也支持运行 eBPF 程序。这里引用 hatenablog Blog 的一张图来展示它们之间的关系,可见不同的追踪框架并不是完全相互替换的关系,各自有自己的适用场景。
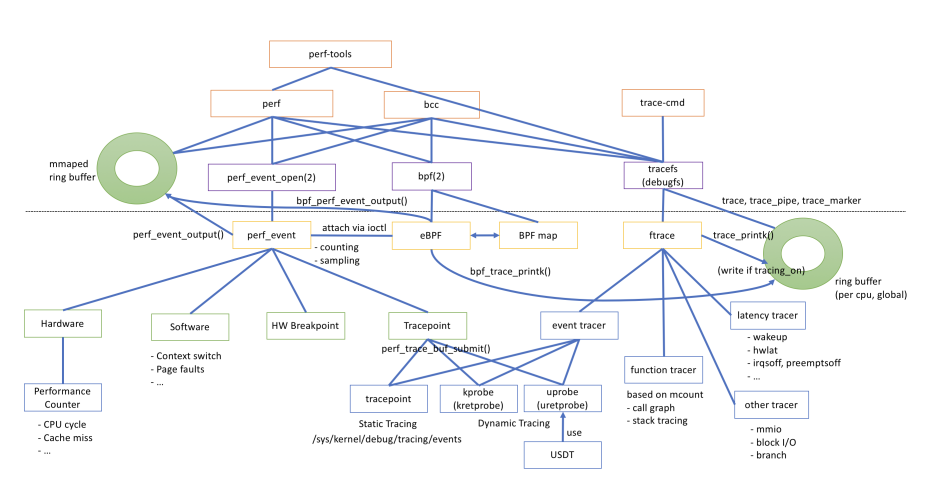
FROM:https://mmi.hatenablog.com/entry/2018/03/04/052249
总的来说,内核追踪框架分为两大类:
- 内核内置框架(In-Tree):ftrace,perf,eBPF;
- 内核外置框架(Out-Tree): SystemTap,LTTng,DTrace,sysdig;
这里重点介绍下常用的 ftrace、perf、SystemTap 和 eBPF 框架。
-
ftrace
ANKI_NOTE_HASH: a14940aabe2d4f33cbc417f11f433231 ANKI_NOTE_ID: 1703518843548ftrace(Function Tracer)是最早用于记录内核在运行时的各种函数调用信息。随着追踪功能的不断增加, ftrace 上扩展出了越来越多的 tracer 插件,从而使得 ftrace 成为一套动态追踪的框架。
ftrace包含以下几个部分:ftrace框架核心,ring buffer,debugfs,event和各种tracer。值得注意的有两点:
- ftrace 本身不是工具,而是通过 debugfs 接口与用户进行交互。原始的 ftrace 使用方式是读写 debugfs 下的对应文件以控制和观测各种 event/tracer 的打开和关闭。它有两个使用比较广的前端工具 trace-cmd 和 KernelShark。
- event 和 tracer 属于 ftrace 下的两大类 trace。event 源于 trace event,tracer 源于function tracer。他们的区别是内核里的实现方式不同:
- trace event 原来只有 tracepoint,用的是静态插桩,后来加入 kprobe 也支持动态插桩了,每个插桩点可以单独控制。
- tracer则是使用类似于 tracepoint 的静态写好在内核函数里的 void _mcount(void) 函数进行插桩,不用时为 nop 指令。它和 tracepoint区别就在于它不能单独使能,一但使能所有的(数以万计)函数都要插桩,后来为了避免开销过高的问题,引入了 filter 机制,从而可以实现只对指定的一批函数进行插桩。
使用 sysfs 文件系统接口来开启和查看
tracing/kprobe追踪结果,整体框架如下(基于 4.19 内核):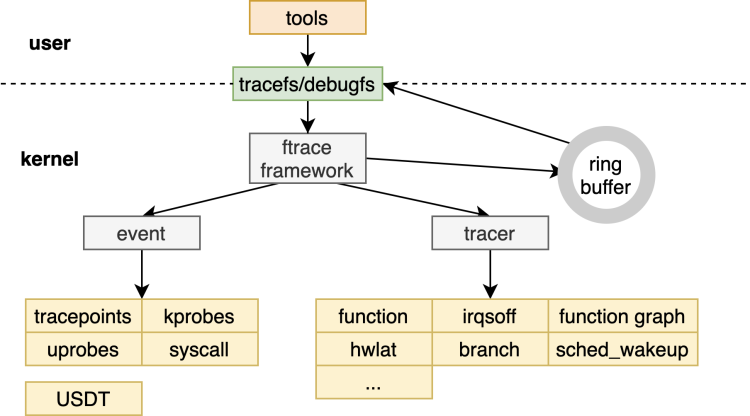
用户接口:tracefs 文件系统:
root@lima-ebpf-dev:/# ls /sys/kernel/debug/tracing/ README buffer_size_kb enabled_functions available_events buffer_total_size_kb error_log available_filter_functions current_tracer events available_tracers dyn_ftrace_total_info free_buffer buffer_percent dynamic_events function_profile_enabled可以追踪的事件:分门别类放在
/sys/kerne/debug/tracing/events目录下,例如执行execve系统调用:root@lima-ebpf-dev:/# ls /sys/kernel/debug/tracing/events/syscalls/sys_enter_execve enable filter format hist id inject trigger使用:
- 开启:
"echo 1 > enable"即可开启该 tracepoint; - 查看:查看文件
/sys/kernel/debug/tracing/trace_pipe中输出结果(结果行的格式可以参考format文件中的定义。):
root@lima-ebpf-dev:/sys/kernel/debug/tracing/events/syscalls/sys_enter_execve# echo 1 > enable root@lima-ebpf-dev:/sys/kernel/debug/tracing/events/syscalls/sys_enter_execve# cat /sys/kernel/debug/tracing/trace_pipe clear-285758 [000] ..... 687231.120698: sys_execve(filename: 559dae079f20, argv: 559dae079b20, envp: 559dae0550b0) sudo-285759 [003] ..... 687240.034196: sys_execve(filename: 55b93e3e3e00, argv: 55b93e389900, envp: 55b93e399cd0) ls-285760 [003] ..... 687243.634162: sys_execve(filename: 559dae098540, argv: 559dae098470, envp: 559dae0550b0) bash-285762 [001] ..... 687244.443490: sys_execve(filename: 5563d3de4dc8, argv: 5563d3dd69d0, envp: 5563d3de97e0) groups-285763 [002] ..... 687244.450417: sys_execve(filename: 55cc2c6a84e0, argv: 55cc2c6a9110, envp: 55cc2c6a5600) lesspipe-285764 [002] ..... 687244.456961: sys_execve(filename: 55cc2c6a7cd0, argv: 55cc2c6a6ff0, envp: 55cc2c6a5c60) basename-285765 [003] ..... 687244.458716: sys_execve(filename: 55ae91cc3a08, argv: 55ae907527c0, envp: 55ae91cc3948) dirname-285767 [001] ..... 687244.463996: sys_execve(filename: 55ae91ccf988, argv: 55ae91ccf8b0, envp: 55ae91ccf8c8) dircolors-285768 [002] ..... 687244.466723: sys_execve(filename: 55cc2c6a6270, argv: 55cc2c6ae0a0, envp: 55cc2c6a5c60) <...>-285769 [003] ..... 687247.664769: sys_execve(filename: 559dae079b00, argv: 559dae098560, envp: 559dae0550b0)除了 tracepoint 外,kprobe 等也可以基于 tracefs 文件系统来实现,以 vfs_read 为例:
ssize_t vfs_read(struct file *file, char __user *buf, size_t count, loff_t *pos);- 先切换目录到
/sys/kernel/debug/tracing下。 - 向 kprobe_events 目录按照一定格式写入 kprobe 信息:
echo "p:test_probe vfs_read file=%di" > kprobe_events - 内核会创建一个名为
events/kprobes/test_probe/的目录(一个 tracepoint 实例,目录层级和内容和 tracepoint 一致)# ls events/kprobes/test_probe/ enable filter format hist id trigger - 启用 kprobe:
echo 1 > events/kprobes/test_probe/enable - 数据将输出到 tracefs 的 ring buffer,也就是
/sys/kernel/debug/tracing/trace_pipe文件中。
# cat trace_pipe ... sshd-4854 [004] .... 5647382.743505: test_probe: (vfs_read+0x0/0x130) file=0xffffa0b0e87e7700 cat-15149 [009] .... 5647382.743515: test_probe: (vfs_read+0x0/0x130) file=0xffffa0b117fe2400 sshd-4854 [004] .... 5647382.743523: test_probe: (vfs_read+0x0/0x130) file=0xffffa0b0e87e7700 ...
-
perf
ANKI_NOTE_HASH: cb67c6434096b8190ca3fa546286e813 ANKI_NOTE_ID: 1703517832306perf 是一个强大的工具,最初用来操作性能监控单元 (PMU) 的硬件计数器,实现计数(count)和采样(sample):
- 计数:TLB miss 次数,syscall 调用次数等。
- 采样:当某个事件发生的次数达到指定值时(取决于采样频率)记录大量的信息,用于后续分析;
perf 同时也支持 tracing/kprobes/uprobes 等事件源,tracing 则复用了 ftrace 的 tracepoint 插桩点。

系统调用接口:
perf_event_open- perf_event_attr.type 字段指定各种采集类型:PERF_TYPE_HARDWARE ,PERF_TYPE_SOFTWARE, PERF_TYPE_TRACEPOINT:
int syscall(SYS_perf_event_open, struct perf_event_attr *attr, pid_t pid, int cpu, int group_fd, unsigned long flags); struct perf_event_attr { __u32 type; /* Type of event */ __u32 size; /* Size of attribute structure */ __u64 config; /* Type-specific configuration */perf 命令示例:
- perf list:查看支持的事件列表
- perf top: 实时分析 CPU 使用量;
- perf stat: 执行指定的命令,在命令执行过程中基础运行次数和软件事件,并生成这些计数的统计信息。
- perf record:统计 CPU Cycles(结果写入
perf.data文件); - perf script | ./stackcollapse-perf.pl | ./flamegraph.pl > perf-kernel.svg:制作火焰图;
[root@devops-110 ~]# perf list |& head alignment-faults [Software event] bpf-output [Software event] context-switches OR cs [Software event] cpu-clock [Software event] cpu-migrations OR migrations [Software event] dummy [Software event] emulation-faults [Software event] major-faults [Software event] minor-faults [Software event] page-faults OR faults [Software event] [root@devops-110 ~]# [root@devops-110 ~]# perf list software List of pre-defined events (to be used in -e): alignment-faults [Software event] bpf-output [Software event] context-switches OR cs [Software event] cpu-clock [Software event] cpu-migrations OR migrations [Software event] dummy [Software event] emulation-faults [Software event] major-faults [Software event] minor-faults [Software event] page-faults OR faults [Software event] task-clock [Software event] [root@devops-110 ~]# perf list tracepoint |head block:block_bio_backmerge [Tracepoint event] block:block_bio_bounce [Tracepoint event] block:block_bio_complete [Tracepoint event] block:block_bio_frontmerge [Tracepoint event] block:block_bio_queue [Tracepoint event] block:block_bio_remap [Tracepoint event] block:block_dirty_buffer [Tracepoint event] block:block_getrq [Tracepoint event] block:block_plug [Tracepoint event] block:block_rq_abort [Tracepoint event] [root@devops-110 ~]# $ perf top -e sched:sched_wakeup --stdio PerfTop: 90 irqs/sec kernel:100.0% exact: 0.0% lost: 0/0 drop: 0/0 [1Hz sched:sched_wakeup], (all, 4 CPUs) --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- 50.72% comm=perf pid=285868 prio=120 target_cpu=003 7.09% comm=containerd pid=1454 prio=120 target_cpu=000 [root@devops-110 ~]# perf stat ls Performance counter stats for 'ls': 0.69 msec task-clock # 0.734 CPUs utilized 0 context-switches # 0.000 K/sec 0 cpu-migrations # 0.000 K/sec 265 page-faults # 0.386 M/sec <not supported> cycles <not supported> instructions <not supported> branches <not supported> branch-misses 0.000934209 seconds time elapsed 0.000000000 seconds user 0.000978000 seconds sys火焰图分析:
# 记录和查看性能数据 [root@devops-110 ~]# perf record -e cycles find / [ perf record: Woken up 1 times to write data ] [ perf record: Captured and wrote 0.091 MB perf.data (2195 samples) ] [root@devops-110 ~]# perf report #制作火焰图: [root@devops-110 ~] perf script | ./stackcollapse-perf.pl | ./flamegraph.pl > perf-kernel.svg
更多参考:perf Examples
-
SystemTap
ANKI_NOTE_HASH: 662b239fff3783a8cecfef1f60881f3a ANKI_NOTE_ID: 1703555819367SystemTap 框架通过自定义开发脚本,来调查和监控内核空间中的各种内核功能、系统调用和其他事件,而不需要重新编译内核或重启系统。
SystemTap 工具将脚本即时编译为内核模块,然后加载到内核中执行。单行脚本示例:
# echo "probe timer.s(1) {exit()}" | stap -v -在 RHEL 系列发行版中,SystemTap 是主流的系统跟踪和探测工具,当前逐渐被基于 eBPF 的 bpftrace/bcc 等可编程工具取代。
-
BPF 和 eBPF
BPF 最初用于高性能网络包过滤场景,用户只能借助少数的几个用户空间程序如 tcpdump、seccomp 等使用 BPF。 BPF中很重要的一点是在内核中引入了一个专门执行 BPF 程序的虚拟机,这为后来 BPF 程序的安全性和高效率奠定了基础。
后来,eBPF 的出现扩展 BPF 原有的指令集,并提供了 bpf 系统调用用于用户空间和内核之间的交互,进一步将 BPF 程序的使用方式推广到普通用户程序。
eBPF(extended Berkeley Packet Filter) 是事件驱动的,高性能,安全的内核级虚拟机。从内核 4.4+ 版本开始支持,当前应用范围扩大到可观测性(如动态追踪 tracing、静态追踪 probe、性能分析 profiling)、高性能网络(XDP、Socker filter)、安全审计(LSM 等)等领域;
eBPF 程序的工作流程:

eBPF 当前支持的各种数据源:

eBPF 与内核的各种追踪框架,如 ftrace、perf_vents 等,具有良好的兼容性,为它们提供了基于 eBPF 字节码的可编程能力,具有高安全性、高性能,低开销、可编程性的优势。
- 方便用户编程的接口。BPF只有一个系统调用bpf,但它提供了各类event的插桩方法,包含perf ring buffer、 BPF MAP、trace ring buffer三种数据通道的交互方式。后来BCC、bpftrace的引入更进一步完善了BPF生态。
- 更安全的运行环境。所有的BPF C程序先被编译为BPF二进制码,然后在装载进内核时先通过验证器进行验证,保证正确性。在确保BPF程序安全的情况下,才会通过虚拟机或者JIT的方式得到运行。
1.3 用户前端 #
内核里的各种收集数据源数据的框架对普通用户来说不太友好,他们被进一步封装为方便用户使用的用户态前端工具或者可编程框架。这些框架各有特点,用户需要熟悉他们的特点并根据使用场景选择合适的工具。
ftrace:
- 内核虚拟文件系统:
/sys/kernel/debug/tracing; - 命令行工具:trace-cmd;
perf:
- 命令行工具集:perf-tools (也支持 ftrace)
- 参考:perf Examples:https://www.brendangregg.com/perf.html
BCC:在 BCC 之前,编写 eBPF 程序是比较复杂的。一个简单指标的采集使用纯 C 代码书写需要两部分:
- 一个BPF C程序,用于装载进内核中的插桩点进行事件处理;
- 一个用户态程序用于BPF C程序的装载和对其输出的格式化打印。
这一过程过程中的很多操作可以借助 libbpf 提供的 API 来方便实现。这种方式使用BPF程序的优点是依赖少,但是编译环境的搭建比较繁琐,而且 BPF 程序是经常会修改的,每次修改都要重新编译。
BCC 是一套用于开发 BPF 程序的高级编程框架,它使用 clang 作为编译器,支持使用 C、Python 等多种高级语言。
现代的 BCC 基于 libbcc 和 libbpf,但实际上 BCC 诞生在这两个库之前。BCC 还包含了70多个工具,这些小工具在系统的各个部分提供了观测性,这是BCC生态的重要一部分。
使用 BCC 的工具在执行时候是动态编译的,每次运行自动编译。而且每次编译,BCC 采用动态编译的方式使用 BPF C 程序在我看来至少有两个好处:(1)eBPF的filter机制;(2)BPF程序的移植问题。filter 在支持全局变量后得到解决。移植问题在 BTF 之后得到解决。
参考:BPF 可移植性和 CO-RE:http://arthurchiao.art/blog/bpf-portability-and-co-re-zh/
BCC 项目工具:

bpftrace
BCC 的使用依然不简单,我们至少需要掌握 BCC 编程接口和一门高级语言以及对内核有所了解。
bpftrace 将 BPF 的便捷性提升到极致,提供了一种类似于 awk 的种专用的高级追踪语言(high-level tracing language),很多场景需求可以通过一行脚本来搞定。但是 bpftrace 的便捷性并不能覆盖 BCC的价值,也无法覆盖纯 C 书写 BPF 程序的价值。他们有各自的特点:
- bpftrace适用于单行的命令行,用于一次性的问题查询和诊断。
- BCC适用于写带命令行的工具,或者写带有指定语言的agent。比如ebpf_exporter是一个调用BPF程序的监控,它就是使用的BCC。
- 纯C的写法在对依赖库、开销方面有追求时非常有优势。BCC和bpftrace依赖clang编译环境、libbcc、libbpf、 kernel-devel等,会给文件系统带来约100M的消耗。
参考
- A thorough introduction to bpftrace:https://www.brendangregg.com/blog/2019-08-19/bpftrace.html
- bpftrace internal:https://github.com/iovisor/bpftrace/blob/master/docs/internals_development.md
bpftrace 内部实现:

bpftrace 脚本示例:统计 read 系统调用执行时间的直方图分布:
root@lima-ebpf-dev:/Users/zhangjun/docs# cat read.bt
tracepoint:syscalls:sys_enter_read
{
@start[tid] = nsecs;
}
tracepoint:syscalls:sys_exit_read / @start[tid] /
{
@times = hist(nsecs - @start[tid]);
delete(@start[tid]);
}
root@lima-ebpf-dev:/Users/zhangjun/docs#
root@lima-ebpf-dev:/Users/zhangjun/docs# bpftrace ./read.bt
Attaching 2 probes...
^C
@start[286210]: 494881661648171
@start[1472]: 494893376210298
@start[285769]: 494898639861704
@times:
[4K, 8K) 224 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[8K, 16K) 331 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
[16K, 32K) 70 |@@@@@@@@@@ |
[32K, 64K) 17 |@@ |
[64K, 128K) 8 |@ |
[128K, 256K) 18 |@@ |
[256K, 512K) 36 |@@@@@ |
[512K, 1M) 4 | |
[1M, 2M) 13 |@@ |
[2M, 4M) 5 | |
[4M, 8M) 1 | |
[8M, 16M) 0 | |
[16M, 32M) 1 | |
[32M, 64M) 0 | |
[64M, 128M) 0 | |
[128M, 256M) 0 | |
[256M, 512M) 0 | |
[512M, 1G) 0 | |
[1G, 2G) 1 | |
[2G, 4G) 2 | |
root@lima-ebpf-dev:/Users/zhangjun/docs#
更多参考:The bpftrace One-Liner Tutorial
2 二、eBPF 发展历程 #
2.1 BPF 1992: Berkeley Packet Filter #
BPF:Berkeley Packet Filter, 即伯克利报文过滤器,源于 1992 的一篇论文:《The BSD packet filter: A New architecture for user-level packet capture》,最初在 BSD 系统实现,后来引入 Linux。

BPF 被广泛用于网络包过滤场景,如当前 tcpdump 也是基于 BPF 来实现高效包过滤的:
root@lima-ebpf-dev:~# tcpdump -d host 127.0.0.1 and port 80 # 打印根据条件生成的 BPF 字节码。
Warning: assuming Ethernet
(000) ldh [12]
(001) jeq #0x800 jt 2 jf 18
(002) ld [26]
(003) jeq #0x7f000001 jt 6 jf 4
(004) ld [30]
(005) jeq #0x7f000001 jt 6 jf 18
(006) ldb [23]
(007) jeq #0x84 jt 10 jf 8
(008) jeq #0x6 jt 10 jf 9
(009) jeq #0x11 jt 10 jf 18
(010) ldh [20]
(011) jset #0x1fff jt 18 jf 12
(012) ldxb 4*([14]&0xf)
(013) ldh [x + 14]
(014) jeq #0x50 jt 17 jf 15
(015) ldh [x + 16]
(016) jeq #0x50 jt 17 jf 18
(017) ret #262144
(018) ret #0
root@lima-ebpf-dev:~#
BPF 提供了安全、高效、灵活的执行包过滤:
- 安全:内核虚拟机执行过滤指令,不会 crash 内核;
- 高效:内核态直接操作,性能高(by user-kernel 数据拷贝、上下文切换);
- 灵活:用户可以自定义各种过滤规则;
2.2 eBPF 2013+ #
ANKI_NOTE_HASH: 1cd9e151707bc9480cbdaa0ff769f982
ANKI_NOTE_ID: 1703555858983
Extended BPF(eBPF)是 BPF 的扩展,主要体现在如下 3 方面:
-
常规扩展:

-
指令集和虚拟机扩展:

-
能力和开发框架扩展:如 BPF Map 存储机制,BPF 辅助函数、LLVM 字节码编译器等。
2.3 eBPF 2023 #
eBPF 成为通用内核执行环境,提供更加安全、高效、灵活的能力,称为新的内核全栈可编程平台(eBPF as a platform):
- 可观测:kprobe, tracepoint
- 安全:secomp
- 高性能网络:sched, XDP

用户态,内核态和 eBPF 程序对比:

3 三、eBPF 程序开发和执行 #
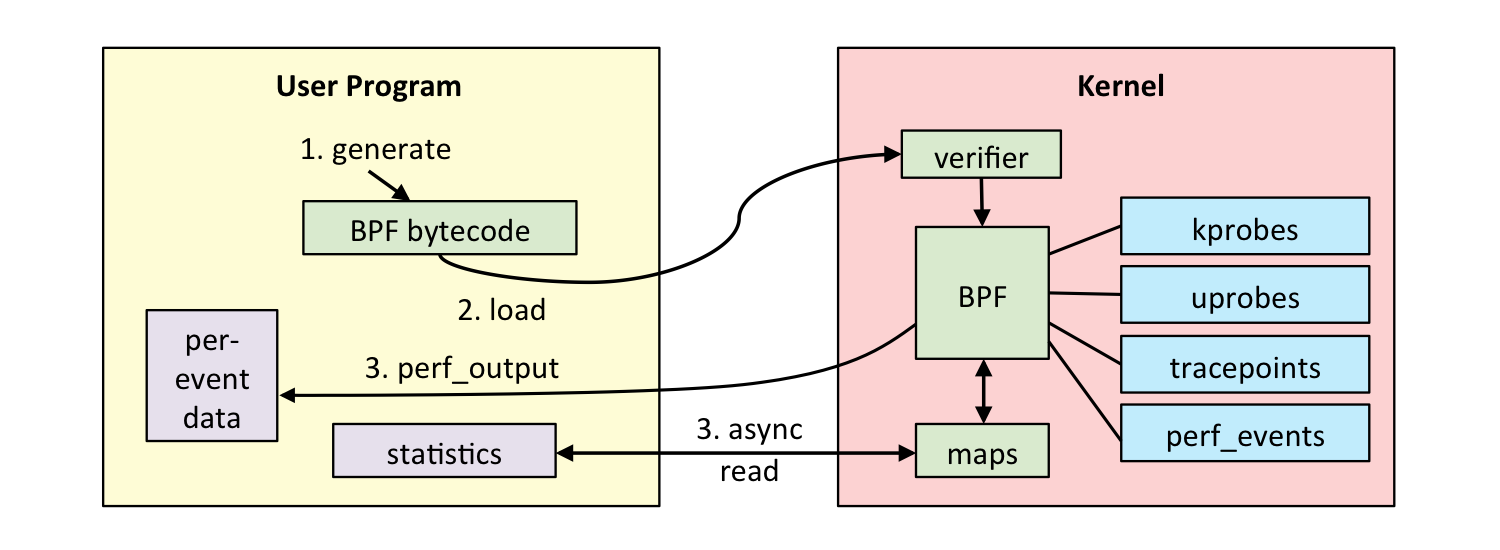
以下借用 Brendan Gregg 的一张图展示 eBPF 的工作流程:
- eBPF 程序:分为内核态和用户态 eBPF 程序:内核态一般是 C + libpbf,用户态各种语言框架(C libbpf、 Go cilium/ebpg、Rust Aya等)
- load&verify:将 eBPF 内核程序 load 进内核,内核对 eBPF 程序进行各种 verify;
- attach:将 eBPF attach 到各种数据源:kprobe/uprobe/tracepoint/USDT-probe;
- output:eBPF 内核程序将数据写入 eBPF map/ftrace/per buffer 等;
- pull:用户态 pull 写入的数据;
3.1 bfp 系统调用 #
用户空间程序使用 bpf 系统调用接口来加载 eBPF 字节码程序和创建 Maps:
- int bpf(int cmd, union bpf_attr *attr, unsigned int size);
cmd 参数指定操作类型:
- BPF_PROG_LOAD: 加载 eBPF 字节码到内核;
- BPF_MAP_CREATE: 创建 eBPF Map;

3.2 编译 #
使用 LLVM 工具链将 C 代码编译为 eBPF 字节码:

eBPF 字节码通过内核内置的 eBPF 虚拟机校验和执行,从而实现特定软件和硬件环境无关。

3.3 加载和校验 #
eBPF 字节码程序需要先通过 bpf 系统调用来加载到内核(一般通过 libbpf 提供的接口函数实现)。然后内核使用验证器(Verifier)来对 eBPF 字节码进行安全性、有效性检查,主要的流程是:先进行深度优先搜索,遍历所有可能的执行路径。具体说就是模拟每条指令的执行,观察寄存器和栈的状态变化。
为了实现安全检查,对 eBPF 程序有如下限制:
- eBPF程序不能调用任意的内核函数:
- 只限于内核模块中列出的BPF辅助函数,函数支持列表也随着内核 的演进在不断增加;
- 最新进展是支持了直接调用特定的内核函数调用
- BPF程序不允许包含无法到达的指令,防止加载无效代码,延迟程序的终止
- eBPF程序中循环次数限制且必须在有限时间内结束:
- Linux5.3在BPF中包含了对有界循环的支持,它有一个可验证的运行时间上限
- eBPF堆栈大小被限制在MAX_BPF_STACK:
- 截止到内核Linux5.8版本,被设置为512eBPF字节码大小最 初被限制为 4096 条指令,
- 截止到内核 Linux 5.8 版本, 当前已将放宽至 100 万指令 ,对于无特权的 BPF 程序,仍然保留 4096 条限制 (BPF_MAXINSNS);
- 新版本的 eBPF 也支持了多个 eBPF 程序级联调用, 可以通过组合实现更加强大的功能
例子:Verifier 报错信息:
lemon@lemon-server:~$ sudo ip link set dev lo xdp obj xdp-example.o sec xdp verbose~
libbpf: load bpf program failed: Permission denied
libbpf: -- BEGIN DUMP LOG ---
libbpf:
0: (61) r2 = *(u32 *)(r1 +0)
1: (61) r1 = *(u32 *)(r1 +4)
2: (bf) r3 = r2
3: (07) r3 += 14
4: (2d) if r3 > r1 goto pc+12
R1_w=pkt_end(id=0,off=0,imm=0) R2_w=pkt(id=0,off=0,r=14,imm=0) R3_w=pkt(id=0,off=14,r=14,imm=0) R10=fp0
5: (bf) r3 = r2
6: (07) r3 += 34
7: (2d) if r3 > r1 goto pc+9
R1_w=pkt_end(id=0,off=0,imm=0) R2_w=pkt(id=0,off=0,r=34,imm=0) R3_w=pkt(id=0,off=34,r=34,imm=0) R10=fp0
8: (71) r3 = *(u8 *)(r2 +23)
9: (55) if r3 != 0x11 goto pc+7
R1=pkt_end(id=0,off=0,imm=0) R2=pkt(id=0,off=0,r=34,imm=0) R3=inv17 R10=fp0
10: (07) r2 += 42
11: (2d) if r2 > r1 goto pc+5
R1=pkt_end(id=0,off=0,imm=0) R2_w=pkt(id=0,off=42,r=42,imm=0) R3=inv17 R10=fp0
12: (b7) r1 = 2
13: (69) r2 = *(u16 *)(r1 +0)
R1 invalid mem access 'inv'
processed 14 insns (limit 1000000) max_states_per_insn 0 total_states 1 peak_states 1 mark_read 1
libbpf: -- END LOG --
libbpf: failed to load program 'xdp_drop_the_world'
libbpf: failed to load object 'xdp-example.o'
3.4 JIT #
验证完成后,内核使用 eBPF JIT 编译器将 eBPF 字节码编译为 CPU 可执行的机器码,从而加速 eBPF 程序的执行效率,减少执行开销。

3.5 执行 #
eBPF(extended Berkeley Packet Filter) 是事件驱动的,高性能,安全的内核级虚拟机。eBPF 内核态程序都是在特定的内核事件源 Hook 点被访问时执行。
使用 libbpf 库来开发用户态 eBPF 程序时,会根据 SEC() 宏中定义的内核 hook 点,将 eBPF 挂载(attach)到该 hook 点上,当该 hook 点被访问时,内核会执行对应的 eBPF 指令。例如,当对 sendmsg、recvmsg 系统调用 hook 点 attach eBPF 程序后,当用户程序调用这两个系统调用时,会执行对应的 eBPF 程序。

4 四、eBPF 程序开发框架 #
分为内核态和用户态程序开发框架:
- eBPF 内核态程序:C 语言开发,libbpf 库;
- eBPF 用户态程序:C/Go/Rust/Python 等;
- C:libbpf
- Go:cilium/ebpf, libbpfgo
- Python:bcc
- DSL: bpftrace
- Rust: ady
libbpf 为内核态和用户态 eBPF 程序提供了一站式 C 语言开发框架。
内核代码目录 samples/bpf 中有大量示例程序可以学习参考。
$ ls ~/codes/kernel/linux-v4.19.91/samples/bpf/
Makefile map_perf_test_kern.c sockex2_user.c tcp_bufs_kern.c test_current_task_under_cgroup_kern.c trace_event_user.c tracex7_user.c xdp_redirect_map_user.c
README.rst map_perf_test_user.c sockex3_kern.c tcp_clamp_kern.c test_current_task_under_cgroup_user.c trace_output_kern.c xdp1_kern.c xdp_redirect_user.c
bpf_insn.h offwaketime_kern.c sockex3_user.c tcp_cong_kern.c test_ipip.sh* trace_output_user.c xdp1_user.c xdp_router_ipv4_kern.c
bpf_load.c offwaketime_user.c spintest_kern.c tcp_iw_kern.c test_lru_dist.c tracex1_kern.c xdp2_kern.c xdp_router_ipv4_user.c
bpf_load.h parse_ldabs.c spintest_user.c tcp_rwnd_kern.c test_lwt_bpf.c tracex1_user.c xdp2skb_meta.sh* xdp_rxq_info_kern.c
cookie_uid_helper_example.c parse_simple.c syscall_nrs.c tcp_synrto_kern.c test_lwt_bpf.sh tracex2_kern.c xdp2skb_meta_kern.c xdp_rxq_info_user.c
cpustat_kern.c parse_varlen.c syscall_tp_kern.c test_cgrp2_array_pin.c test_map_in_map_kern.c tracex2_user.c xdp_adjust_tail_kern.c xdp_sample_pkts_kern.c
cpustat_user.c run_cookie_uid_helper_example.sh* syscall_tp_user.c test_cgrp2_attach.c test_map_in_map_user.c tracex3_kern.c xdp_adjust_tail_user.c xdp_sample_pkts_user.c
fds_example.c sampleip_kern.c task_fd_query_kern.c test_cgrp2_attach2.c test_overhead_kprobe_kern.c tracex3_user.c xdp_fwd_kern.c xdp_tx_iptunnel_common.h
hash_func01.h sampleip_user.c task_fd_query_user.c test_cgrp2_sock.c test_overhead_raw_tp_kern.c tracex4_kern.c xdp_fwd_user.c xdp_tx_iptunnel_kern.c
lathist_kern.c sock_example.c tc_l2_redirect.sh* test_cgrp2_sock.sh* test_overhead_tp_kern.c tracex4_user.c xdp_monitor_kern.c xdp_tx_iptunnel_user.c
lathist_user.c sock_example.h tc_l2_redirect_kern.c test_cgrp2_sock2.c test_overhead_user.c tracex5_kern.c xdp_monitor_user.c xdpsock.h
load_sock_ops.c sock_flags_kern.c tc_l2_redirect_user.c test_cgrp2_sock2.sh* test_override_return.sh* tracex5_user.c xdp_redirect_cpu_kern.c xdpsock_kern.c
lwt_len_hist.sh sockex1_kern.c tcbpf1_kern.c test_cgrp2_tc.sh* test_probe_write_user_kern.c tracex6_kern.c xdp_redirect_cpu_user.c xdpsock_user.c
lwt_len_hist_kern.c sockex1_user.c tcp_basertt_kern.c test_cgrp2_tc_kern.c test_probe_write_user_user.c tracex6_user.c xdp_redirect_kern.c
lwt_len_hist_user.c sockex2_kern.c tcp_bpf.readme test_cls_bpf.sh* trace_event_kern.c tracex7_kern.c xdp_redirect_map_kern.c
$
5 eBPF Demo #
5.1 Demo1: 数据包过滤 #
基于 eBPF XDP 能力,实现丢弃特定网络接口的数据包。
内核 eBPF 程序(基于 libbpf 库):
#include "vmllinux.h"
#include <linux/bpf.h>
#define SEC(NAME) __attribute__((section(NAME), used))
SEC("xdp")
int xdp_drop_the_world(struct xdp_md *ctx) {
return XDP_DROP;
}
char _license[] SEC("license") = "GPL";
执行验证:
# 编译为 eBPF 字节码
root@lima-ebpf-dev:~/demo# clang -O2 -target bpf -D __TARGET_ARCH_x86 -c xdp.c -o xdp.o
# 加载执行(将 eBPF 字节码绑定了 lo 接口)
root@lima-ebpf-dev:~/demo# ip link set dev lo xdp obj xdp.o sec xdp verbose
libbpf: loading xdp.o
libbpf: elf: section(3) xdp, size 16, link 0, flags 6, type=1
libbpf: sec 'xdp': found program 'xdp_drop_the_world' at insn offset 0 (0 bytes), code size 2 insns (16 bytes)
libbpf: elf: section(4) license, size 4, link 0, flags 3, type=1
libbpf: license of xdp.o is GPL
libbpf: elf: section(6) .symtab, size 96, link 1, flags 0, type=2
libbpf: looking for externs among 4 symbols...
libbpf: collected 0 externs total
# 测试:lo 不通(因为 lo 接口绑定的 eBPF 程序丢弃了数据包)
root@lima-ebpf-dev:~/demo# ping 127.0.0.1
PING 127.0.0.1 (127.0.0.1) 56(84) bytes of data.
^C
--- 127.0.0.1 ping statistics ---
6 packets transmitted, 0 received, 100% packet loss, time 5129ms
# 测试:卸载 eBPF 字节码
root@lima-ebpf-dev:~/demo# ip link set dev lo xdp off
# 测试:lo 通
root@lima-ebpf-dev:~/demo# ping 127.0.0.1
PING 127.0.0.1 (127.0.0.1) 56(84) bytes of data.
64 bytes from 127.0.0.1: icmp_seq=1 ttl=64 time=1.41 ms
^C
--- 127.0.0.1 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 1.413/1.413/1.413/0.000 ms
5.2 Demo2: 追踪执行 write 系统调用的进程 PID #
使用 tracepoint 静态内核追踪技术,追踪执行 write 系统调用的 PID:
// 内核态 eBPF 程序
// minimal.bpf.c
#include <linux/bpf.h>
#include <bpf/bpf_helpers.h>
char LICENSE[] SEC("license") = "Dual BSD/GPL";
int my_pid = 0;
SEC("tracepoint/syscalls/sys_enter_write")
int handle_tp(void *ctx)
{
int pid = bpf_get_current_pid_tgid() >> 32;
if (pid != my_pid)
return 0;
bpf_printk("BPF triggered from PID %d.\n", pid);
return 0;
}
// 用户态程序,实现 eBPF 字节码的 load、attach 和 pull 打印。
// minimal.c
#include <stdio.h>
#include <unistd.h>
#include <sys/resource.h>
#include <bpf/libbpf.h>
#include "minimal.skel.h"
static int libbpf_print_fn(enum libbpf_print_level level, const char *format, va_list args)
{
return vfprintf(stderr, format, args);
}
int main(int argc, char **argv)
{
struct minimal_bpf *skel;
int err;
/* Set up libbpf errors and debug info callback */
libbpf_set_print(libbpf_print_fn);
/* Open BPF application */
skel = minimal_bpf__open();
if (!skel) {
fprintf(stderr, "Failed to open BPF skeleton\n");
return 1;
}
/* ensure BPF program only handles write() syscalls from our process */
skel->bss->my_pid = getpid();
/* Load & verify BPF programs */
err = minimal_bpf__load(skel);
if (err) {
fprintf(stderr, "Failed to load and verify BPF skeleton\n");
goto cleanup;
}
/* Attach tracepoint handler */
err = minimal_bpf__attach(skel);
if (err) {
fprintf(stderr, "Failed to attach BPF skeleton\n");
goto cleanup;
}
printf("Successfully started! Please run `sudo cat /sys/kernel/debug/tracing/trace_pipe` "
"to see output of the BPF programs.\n");
for (;;) {
/* trigger our BPF program */
fprintf(stderr, ".");
sleep(1);
}
cleanup:
minimal_bpf__destroy(skel);
return -err;
}
执行:
root@lima-ebpf-dev:~/demo/libbpf-bootstrap/examples/c# ./minimal
root@lima-ebpf-dev:~/demo/libbpf-bootstrap/examples/c# cat /sys/kernel/debug/tracing/trace_pipe
<...>-287833 [000] ..... 691417.240672: sys_execve(filename: 5591f151e430, argv: 5591f151e470, envp: 5591f14f80b0)
5.3 Demo3: 追踪任意内核函数 #
使用 kprobe 动态内核函数追踪技术来追踪执行任意内核函数的信息,这里以 do_unlinkat 为例,打印 pid 和 filename:
// kprobe.bpf.c
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
#include <bpf/bpf_core_read.h>
char LICENSE[] SEC("license") = "Dual BSD/GPL";
SEC("kprobe/do_unlinkat")
int BPF_KPROBE(do_unlinkat, int dfd, struct filename *name)
{
pid_t pid;
const char *filename;
pid = bpf_get_current_pid_tgid() >> 32;
filename = BPF_CORE_READ(name, name);
bpf_printk("KPROBE ENTRY pid = %d, filename = %s\n", pid, filename);
return 0;
}
SEC("kretprobe/do_unlinkat")
int BPF_KRETPROBE(do_unlinkat_exit, long ret)
{
pid_t pid;
pid = bpf_get_current_pid_tgid() >> 32;
bpf_printk("KPROBE EXIT: pid = %d, ret = %ld\n", pid, ret);
return 0;
}
// kprobe.c
#include <stdio.h>
#include <unistd.h>
#include <signal.h>
#include <string.h>
#include <errno.h>
#include <sys/resource.h>
#include <bpf/libbpf.h>
#include "kprobe.skel.h"
static int libbpf_print_fn(enum libbpf_print_level level, const char *format, va_list args)
{
return vfprintf(stderr, format, args);
}
static volatile sig_atomic_t stop;
static void sig_int(int signo)
{
stop = 1;
}
int main(int argc, char **argv)
{
struct kprobe_bpf *skel;
int err;
/* Set up libbpf errors and debug info callback */
libbpf_set_print(libbpf_print_fn);
/* Open load and verify BPF application */
skel = kprobe_bpf__open_and_load();
if (!skel) {
fprintf(stderr, "Failed to open BPF skeleton\n");
return 1;
}
/* Attach tracepoint handler */
err = kprobe_bpf__attach(skel);
if (err) {
fprintf(stderr, "Failed to attach BPF skeleton\n");
goto cleanup;
}
if (signal(SIGINT, sig_int) == SIG_ERR) {
fprintf(stderr, "can't set signal handler: %s\n", strerror(errno));
goto cleanup;
}
printf("Successfully started! Please run `sudo cat /sys/kernel/debug/tracing/trace_pipe` "
"to see output of the BPF programs.\n");
while (!stop) {
fprintf(stderr, ".");
sleep(1);
}
cleanup:
kprobe_bpf__destroy(skel);
return -err;
}
编译执行:
root@lima-ebpf-dev:~/demo/libbpf-bootstrap/examples/c# make kprobe
BPF .output/kprobe.bpf.o
GEN-SKEL .output/kprobe.skel.h
CC .output/kprobe.o
BINARY kprobe
root@lima-ebpf-dev:~/demo/libbpf-bootstrap/examples/c# ./kprobe
root@lima-ebpf-dev:~# touch test
root@lima-ebpf-dev:~# rm test
root@lima-ebpf-dev:~/demo/libbpf-bootstrap/examples/c# cat /sys/kernel/debug/tracing/trace_pipe
<...>-287909 [002] d...1 691657.455453: bpf_trace_printk: KPROBE ENTRY pid = 287909, filename = test
<...>-287909 [002] d...1 691657.455546: bpf_trace_printk: KPROBE EXIT: pid = 287909, ret = 0
6 参考 #
- Linux动态追踪技术简介
- Exploring USDT Probes on Linux: https://leezhenghui.github.io/linux/2019/03/05/exploring-usdt-on-linux.html